データレイクとデータウェアハウスの違いとデータレイクハウスへの進化
によって Bill Inmon 、 Mary Levins による投稿
このブログは、Forest Rim Technology(フォレスト・リム・テクノロジー社)のデータチームの寄稿によるものです。同社の創業者兼 CEO ビル・インモン氏、最高データ戦略責任者メアリー・レビンズ氏の貢献に感謝します。
最初の課題
ビッグデータを扱う人が最初に直面したデータの課題は、整合性でした。データの量が少なく、ソースのバリエーションも限られていた頃は、構造化データのテーブルで構成されたリレーショナルデータベース(RDB・関係データベース)の使用で事足りていましたが、アプリケーションが普及するようになると、複数のアプリケーションに同じデータが異なる値で現れ、データの整合性がとれないという課題が発生しました。どのデータが正しいかを判断するには、数あるアプリケーションの中から、どのバージョンのデータを使うべきかを見極めなくてはなり��ません。もしユーザーが適切なバージョンのデータを使用できなければ、判断を誤ってしまう可能性もあります。
意思決定に適切なデータを使用するために、単純なリレーショナルデータベース(RDB・関係データベース)とは異なるアーキテクチャのアプローチが必要とされていました。そこで誕生したのが、データウェアハウスです。
データウェアハウス
データウェアハウスでは、異なるアプリケーションデータが物理的に別の場所に配置されます。そのため、設計者は、データウェアハウスを中心とした新たなインフラを構築する必要がありました。
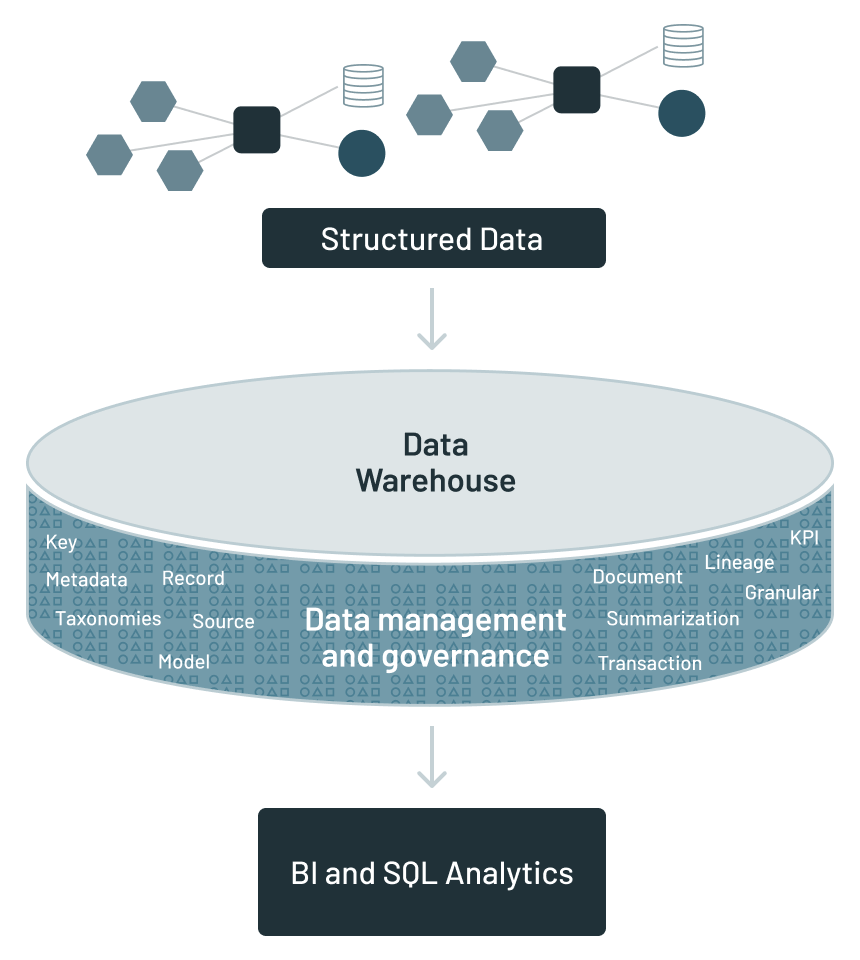
データウェアハウス周辺の分析インフラには次のようなものが含まれていました。
- メタデータ:どのデータがどこに配置されたかを示すガイド
- データモデル:データウェアハウス内で見つかったデータの抽象化
- データリネージ:データウェアハウス内のデータの発生元と変換の履歴
- サマライズ:特定のデータを生成するアルゴリズムに関する説明
- KPI:主要なパフォーマンス指標
- ETL:アプリケーションからの�データを、分析等の用途に利用しやすいように変換
しかし、企業におけるデータの多様化(テキスト、IoT、画像、音声、動画など)によって増大した非構造化データに対応するには、データウェアハウスには制限がありました。また、機械学習(ML)や AI の普及により、非リレーショナルデータベースが必要となり、SQL ベースとは異なる反復的なアルゴリズムが導入されることによって、データウェアハウスでは扱えないデータが増大しました。
企業のあらゆるデータへの対応
データウェアハウスは重要で有用なものでしたが、ほとんどの場合、構造化データが中心でした。しかし、企業には構造化データ以外も多くのタイプのデータが存在します。下の図は、企業が扱うデータをわかりやすく表したものです。

構造化データ:典型的なのはトランザクションベースのデータで、組織が日々の業務を行うために生成されます。
テキストデータ:書簡、メールや会話により生成されるデータです。
その他の非構造化データ:IoTデータ、画像、動画、アナログベースのデータなどその他のソースを持つデータです。
データレイク
データレイクは、企業に存在するさまざまな種類のデータを構造化/非構造化データを問わず全て集約します。Apache Parquet や ORC など、汎用的でオープンなファイルフォーマットでデータを保持するファイル API を備えた低コストのストレージシステムで、企業のあらゆるデータが集まる��場所となりました。オープンフォーマットを使用することで、機械学習システムなどの幅広い分析エンジンから直接データレイクのデータにアクセスできるようになりました。
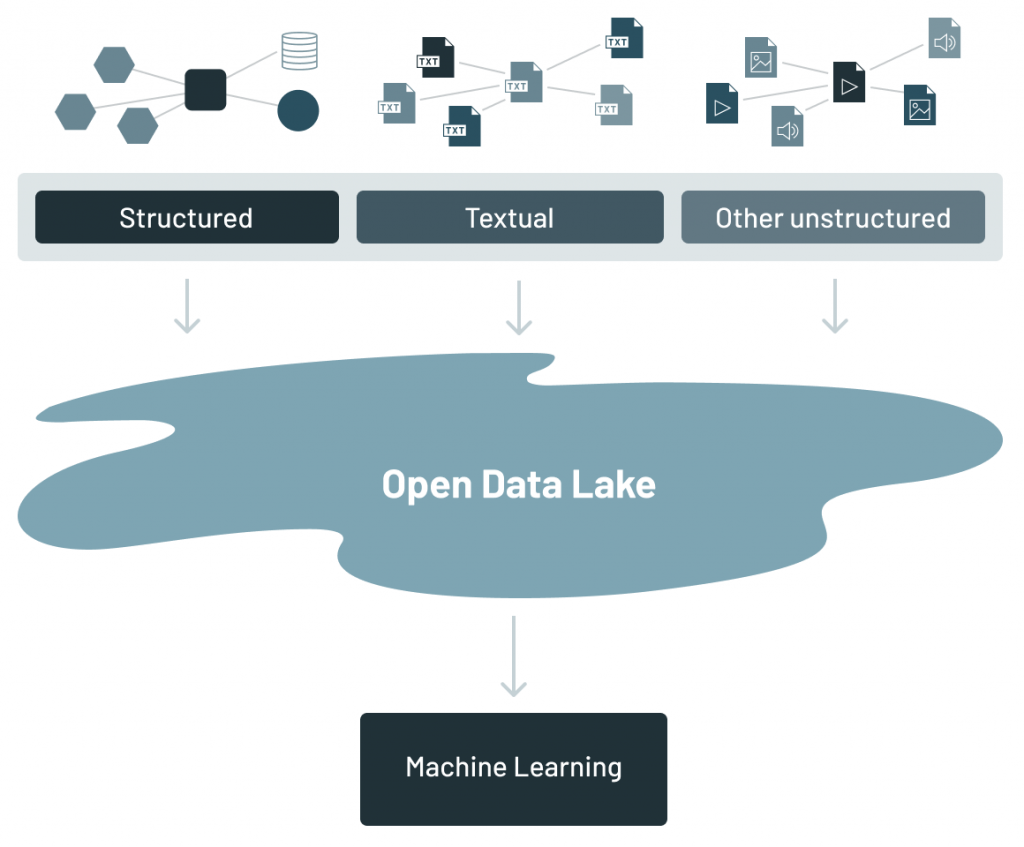
データレイクは、企業内にあるさまざまな種類のデータ全てを集約したものです。データレイクが構想された当初、データを抽出してデータレイクに格納することだけが必要であると考えられていました。データがデータレイクにあれば、エンドユーザーがそこからデータを検索し、分析を行えると考えたからです。
しかし、企業はすぐに、データをデータレイクに格納することと、そのデータを利活用できることは別の話しであることに気づきました。データレイクには、トランザクションのサポートやデータ品質の保証がなく、ガバナンスの実施や性能が最適化されていないなど、重要な機能が欠けていました。データレイクは、これらの理由から本来の目的の達成には至っておらず、データスワンプ(活用できないデータが大量に溜まっている沼のような状態)となっているのが実情です。
現在のデータアーキテクチャに関する課題
データレイクやデータウェアハウスには限界があるため、複数のシステム(データレイク、複数のデータウェアハウス、その他の特殊なシステム)を一緒に使用することが一般的なアプローチとなりましたが、その結果、次の 3 つの共通した問題が発生しま�す。
1. オープン性の欠如: データウェアハウスは、データを独自のフォーマットに固定するので、データやワークロードを他のシステムに移行するコストが増大します。また、アクセスの提供は主に SQL のみなので、非リレーショナルデータベースを構築し、機械学習システムなどの他のエンジンを実行することは困難です。そのうえ、ウェアハウスのデータに SQL で直接アクセスするのは多大なコストと時間がかかるので、他のテクノロジーとの統合が困難です。
2.限定的な機械学習のサポート:機械学習とデータ管理の融合については多くの研究がありますが、TensorFlow、PyTorch、XGBoost などの代表的な機械学習システムは、ウェアハウス上ではうまく機能していないのが実情です。少ないデータ量を抽出する BI とは異なり、機械学習システムは複雑な SQL 以外のコードを使用して大規模なデータセットを処理します。そのため、ウェアハウスのベンダーは、このデータをファイルにエクスポートして処理することを推奨しています。しかし、これでは複雑さと古いデータを増大させる結果となります。
3.データレイクとデータウェアハウスの強制的なトレードオフ:エンタープライズデータの 90% 以上がデータレイクに保存されています。これは、ファイルへのオープンな直接アクセスによる柔軟性と、安価なストレージの利用によるコスト削減のためです。そこで企業では、データレイクの性能不足と品質の課題をカバーするために、ダウンストリームのデータウェアハウスにデータレイク内の少量のデータをETL し、重要な意思決定支援と BI アプリケーション��に利用していました。このデュアルシステムアーキテクチャでは、データレイクとデータウェアハウス間で ETL データの継続的なエンジニアリングが必要になります。ETL のステップごとに、失敗やバグが発生し、データ品質の低下するリスクがあると同時に、データレイクとデータウェアハウスの整合性の維持は困難でコストがかかります。また、継続的な ETL にかかる費用とは別に、データウェアハウスにコピーしたデータのストレージコストも発生するため、ユーザーは 2倍のストレージコストを支払うことになります。
データレイクハウスの登場
データレイクハウスは、データウェアハウス(DWH)とデータレイクの両方の良い部分を継承した、新しいクラスのデータアーキテクチャです。オープンで標準化された新たなシステムデザインによって構築されており、データウェアハウスと類似のデータ構造とデータ管理機能を、データレイクに使用される低コストのストレージに直接実装しています。

データレイクハウスアーキテクチャは、前述したデータアーキテクチャが直面している課題を解決します。
- オープン性:Apache Parquet などのオープンフォーマットを使用することで、オープンなダイレクトアクセスを可能にします。
- 機械学習サポート:データサイエンスと機械学習のネイティブクラスのサポートを提供します。
- コスト:低コストのストレージでクラス最高の性能と信頼性を実現します。
次のさまざまな機能により、レイクハウスアーキテクチャの主要なメリットは実現します。
オープン性
- オープンなファイルフォーマット:Apache Parquet や ORC などのオープンで標準化されたファイルフォーマットを採用
- オープン API:効率的にデータに直接アクセスできるオープンな API を提供するため、独自のエンジンは不要で、ベンダーロックインからも解放します。
- 多言語に対応:SQL のみのアクセスではなく、機械学習や Python/R ライブラリを含む、さまざまなツールやエンジンに対応。
機械学習サポート
- 多様なデータタイプに対応:画像、動画、音声、半構造化データ、テキストなど、最近のデータアプリケーションに必要なデータフォーマットの保存、調整、分析、アクセスを可能にします。
- SQL 以外の効率的な直接読み込み:R や Python のライブラリを使用して、大規模のデータに直接アクセスして機械学習を実行。
- DataFrame API のサポート:機械学習ワークロードにおけるデータアクセスにクエリ最適化を備えた宣言型 DataFrame API が組み込まれています。これにより、 TensorFlow、PyTorch、XGBoost などの機械学習システムのデータ操作の主要な抽象化手法である DataFrame をサポートします。
- 機械学習実験のデータバージョニング:データ��サイエンスや機械学習のチームは、監査やロールバックが必要な時に、データのスナップショットを利用して、以前のデータのバージョンにアクセスして戻ったり、ML 実験を再現したりできます。
低コストでクラス最高の性能と信頼性の提供
- 性能の最適化:キャッシュ、多次元クラスタリング、データスキップなどのさまざまな最適化手法を実現し、ファイル統計とデータの圧縮を活用して、ファイルサイズを適切に調整します。
- スキーマの適用とガバナンス:スター/スノーフレークスキーマなどの DW スキーマアーキテクチャをサポートし、堅牢なガバナンスと監査メカニズムを提供します。
- トランザクションのサポート:ACID トランザクションを活用し、SQL などを利用したデータの読み取り/書き込みを複数のユーザーが同時に実行する場合でも一貫性が保たれます。
- 低コストストレージ:レイクハウスアーキテクチャは、Amazon S3、Azure Blob Storage、Google Cloud Storage などの低コストのオブジェクトストレージを使用して構築されています。
データウェアハウス(DWH)、データレイク、データレイクハウスの違いを比較
| DWH | データレイク | レイクハウス | |
| データフォーマット | クローズド、独自 | オープン | オープン |
| データのタイプ | 構造化データ(半構造化データは限定的にサポート) | 全てのタイプ:構造化/半構造化/テキスト/非構造化(生)データ | 全てのタイプ:構造化/半構造化/テキスト/非構造化(生)データ |
| データアクセス | SQL のみ。ファイルに直接アクセスできない | SQL、R、Python その他の言語でファイルへの直接アクセスを可能にするオープン API | SQL、R、Python その他の言語でファイルへの直接アクセスを可能にするオープン API |
| 信頼性 | ACID トランザクションによる高品質、高信頼性データ | 低品質、データスワンプ | ACID トランザクションによる高品質、高信頼性データ |
| ガバナンスとセキュリティ | テーブルの行/列レベルの高粒度のセキュリティとガバナンス | ファイルにセキュリティを適用する必要あり、ガバナンスが弱い | テーブルの行/列レベルの高粒度のセキュリティとガバナンス |
| 性能 | 高 | 低 | 高 |
| スケーラビリティ | スケーリングでコストは爆発的に増大 | あらゆるタイプ/量のデータを低コストでスケール | あらゆるタイプ/量のデータを低コストでスケール |
| ユースケースサポート | BI、SQL アプリと意思決定サポートに限定 | 機械学習に限定される | BI、SQL、機械学習のための単一のデータアーキテクチャ |
レイクハウスによる影響
データレイクハウスのアーキテクチャは、データウェアハウス(DWH)市場の初期に見られたものに匹敵する機会を提供するものだと考えています。オープンな環境でのデータ管理、エンター��プライズのあらゆるデータの統合、データレイクのデータサイエンスとデータウェアハウスのエンドユーザー分析を併せたユニークな機能により、データレイクハウスは企業に大きな価値をもたらします。

データレイクハウスの構築
データウェアハウスの父と称されるビル・インモン(Bill Inmon)氏が、次世代のデータアーキテクチャを解説しています。
本ブログに関連する内容については、先日開催されたデータコミュニティのグローバルイベント「データ + AI サミット」 におけるビル・インモン氏とデータブリックスのアリ・ゴディシの基調講演でも紹介されました。データと AI の業界リーダー、スペシャリストが一堂に会したイベントの主要プログラムは、オンデマンドで視聴できます。
Forest Rim Technology(フォレスト・リム・テクノロジー社)は、テキストベースの非構造化データを構造化データベースに変換し、データドリブンな意思決定を可能にする世界的リーダー企業です。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。