DBRXの発表:効率的なオープンソースLLMの新しい標準
あなたのユニークなデータにカスタマイズされたDBRXで高品質な生成型AIアプリケーションを構築します
によって Jonathan Frankle, Ali Ghodsi(アリ・ゴディシ), ナヴィン・ラオ, ハンリン・タン, Abhinav Venigalla 、 Matei Zaharia による投稿
Databricksのミッションは、「組織が独自のデータを理解し、使用して独自のAIシステムを構築できるようにすること」です。つまりはすべての企業にデータインテリジェンスを提供することです。
本日、このミッションの達成へと大きく踏み出すため、Databricks AI Researchチームによって構築された汎用の大規模言語モデル(LLM)であるDBRXをオープンソース化します。このモデルは、標準的なベンチマークにおいて既存のすべてのオープンソースモデルを凌駕しています。オープンソースモデルの限界を押し広げることが、すべての企業に対してカスタマイズ可能で透明性のある生成AIを可能にすると私たちは信じています。
私たちが「DBRX」に興奮するのには、3つの明確な理由があります。
まず第一に、言語理解、プログラミング、数学、論理において、LLaMA2-70B、Mixtral、Grok-1などのオープンソースモデルを圧倒しています(図1参照)。実際、私たちのオープンソースベンチマーク「Gauntlet」には、30以上の異なるstate-of-the-art (SOTA) ベンチマークが含まれており、DBRXはそれらのモデルすべてを上回る性能を示しています。これは、オープンソースモデルの品質が継続して向上していることを示しており、私たちもその事実に貢献できることを誇りに思います��。
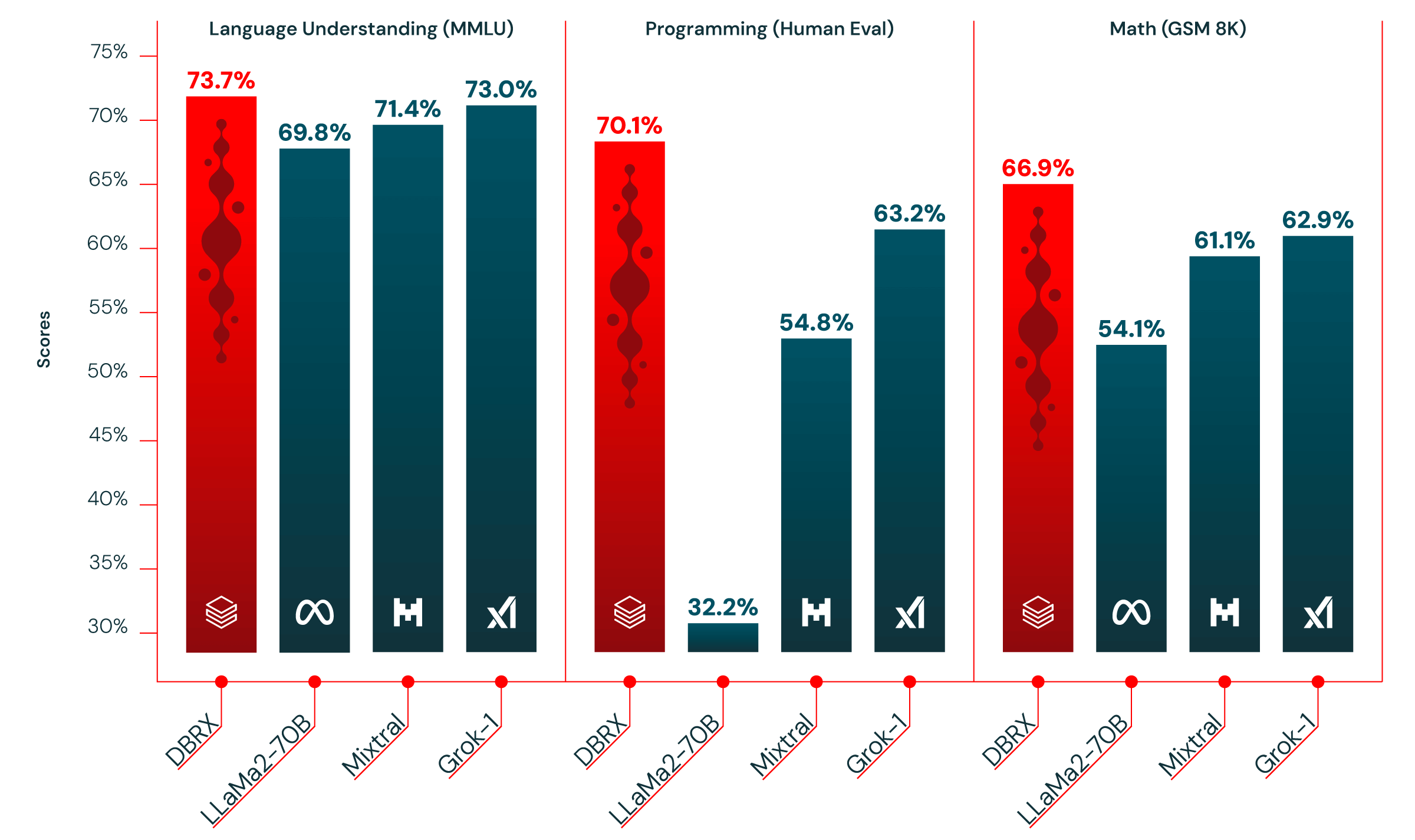
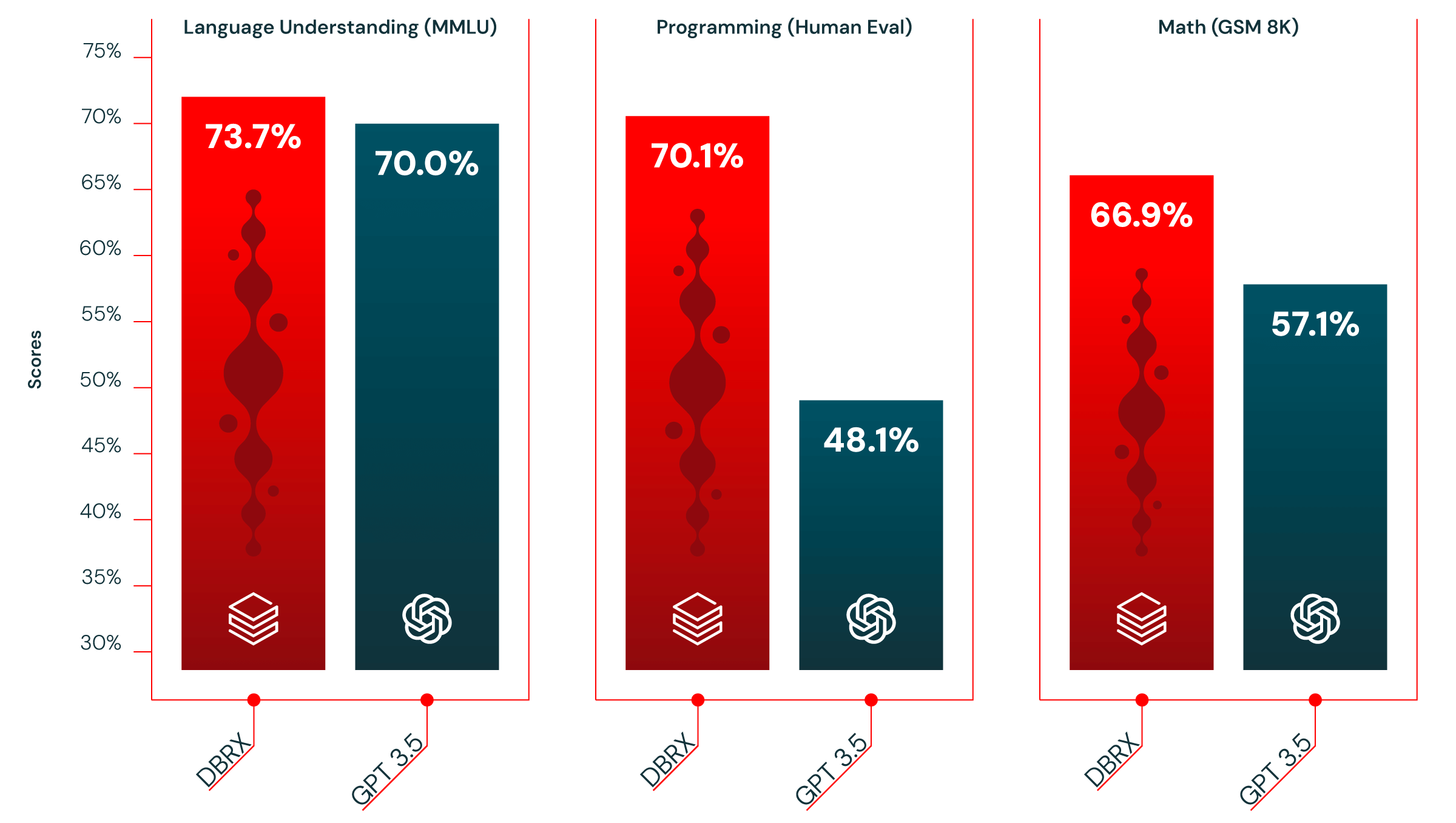
第二に、DBRXはほとんどのベンチマークでGPT-3.5を上回ります(図2を参照)。これは重要なポイントです。なぜなら、前四半期に私たちの12,000人を超える顧客基盤の中で大きな行動変化が見られたからです。企業や組織は、より優れた効率性と制御性を求めて、プロプライエタリ・モデルをオープンソース・モデルに置き換える傾向を強めています。私たちの経験では、多くの顧客は、特定のタスクにオープンソースモデルをカスタマイズすることで、プロプライエタリモデルの品質と速度を上回ることができます。DBRXによってこの傾向がさらに加速することを期待しています。
第三に、DBRXはMoE(Mixture-of-Experts)モデルであり、MegaBlocks researchとオープンソースプロジェクトに基づいて構築されています。私たちは、MoEであるオープンソースの state-of-the-art モデルが今後進むべき道を開くと信じています。これは重要です。なぜなら、MoEは本質的により大きなモデルを訓練し、それらをより高速なスループットで提供することを可能にするからです。DBRXは36Bのパラメータしか使用しません。しかし、モデル自体は132Bのパラメータをもち、速度(トークン/秒)と性能(品質)の面で両方の恩恵を得ることができます。

上記の3つの理由から、オープンソースの大規模言語モデル(LLM)は今後も勢いを増していくと信じています。
特に、企業が自社独自の知的財産(IP)としてカスタマイズできるオープンソースの大規模言語モデル(LLM)を開発し、業界での競争力を高めるために利用できるという点で、これらは非常に魅力的な可能性を秘めていると私たちは考えています。
そのため、私たちはDBRXを簡単にカスタマイズできるように設計し、企業がAIアプリケーションの品質を向上できるようにしました。本日からDatabricks Platform上で、企業はDBRXと"対話"し、RAGシステム内にもつ背景情報を活用し、自社のプライベートデータに基づいてカスタムDBRXモデルを構築できるようになります。これらのカスタマイズ機能は、商用利用可能な最も効率的なMoEトレーニングプラットフォームによって提供されます。コミュニティはgithub リポジトリとHugging Faceを通してDBRXにアクセスできます。
DBRXは完全にDatabricksの上に構築されています。つまりすべての企業が同じツールや技術を使用して、自社の高品質なモデルを作成または改善することができます。トレーニングデータはUnity Catalogで中央集権的に管理され、Apache Spark™および新たに買収したLilac AIを使用して処理され、クリーニングされました。大規模なモデルトレーニングおよびファインチューニングには、私たちのDatabricks Trainingサービスが使用されました。品質と安全性のための人間のフィードバックは、Databricks Model ServingおよびInference Tablesを通じて収集されました。JetBlue、Block、NASDAQ、Accentureなどの顧客やパートナーは、すでにこれら同じツールを使用して高品質のAIシステムを構築しています。
「ナスダックにとってデータブリックスは、最も重要なデータシステムの中のいくつかにおける重要なパートナーです。データブリックスは、データ管理とAIの活用において業界の最先端を走り続けており、私たちはDBRXのリリースを嬉しく思っています。強力なモデル性能と好ましいサービングエコノミクスの組み合わせは、ナスダックで生成AIの利用を拡大する上で、私たちがまさに求めているイノベーションです」ーー米ナスダック証券取引所 AI・データサービス部門責任者 マイク・オルーク(Mike O’Rourke)
Databricksは高品質なAIアプリケーションを構築するための唯一のエンドツーエンド・プラットフォームです。本日リリースされたDBRXはこれまでで最も高品質なオープンソースモデルであり、Databricksの可能性を表現していると言っても過言ではありません。私たちは、オープンソースコミュニティと企業のお客様がDBRXでどのようなことに挑戦するかを楽しみにしています。
さらに詳しくお知りになりたい方は、テクニカルブログをお読みいただき、モデルにアクセスし、DBRXウェビナーにご参加いただき、DatabricksでDBRXを始める方法についてのドキュメントをお読みください。 (AWS | Azure)
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。