DBRX のご紹介:最新鋭のオープン LLM
によって データブリックス AI 研究チーム による投稿
本日、Databricksが作成したオープンで汎用的なLLMであるDBRXを発表できることを嬉しく思います。一連の標準ベンチマークにおいて、DBRXは既存のオープンLLMの新たな最先端を確立します。さらに、オープンコミュニティや独自のLLMを構築している企業に、これまでクローズドモデルAPIに限定されていた機能を提供します。当社の測定によると、GPT-3.5を上回り、Gemini 1.0 Proに匹敵します。汎用LLMとしての強みに加え、特に優れたコードモデルであり、プログラミングにおいてはCodeLLaMA-70Bのような専門モデルを凌駕します。
この最先端の品質は、トレーニングと推論のパフォーマンスにおける顕著な改善とともに実現されます。DBRXは、そのきめ細かな混合エキスパート(MoE)アーキテクチャのおかげで、オープンモデルの中で効率性の最先端を推進します。推論はLLaMA2-70Bの最大2倍高速であり、DBRXはGrok-1の総パラメータ数とアクティブパラメータ数の両方において約40%のサイズです。Databricks Model Servingでホストされる場合、DBRXはユーザーあたり最大150トークン/秒でテキストを生成できます。お客様は、同じ最終モデル品質を得るために、MoEのトレーニングは密モデルのトレーニングよりも約2倍FLOP効率が高いことを見出すでしょう。エンドツーエンドでは、DBRXの全体的なレシピ(事前トレーニングデータ、モデルアーキテクチャ、最適化戦略を含む)は、ほぼ4倍少ないコンピューティングで、当社の前世代MPTモデルの品質に匹敵します。
ベースモデル(DBRX Base)とファインチューニング済みモデル(DBRX Instruct)の重みは、オープンライセンスの下でHugging Faceで利用可能です。本日より、DBRXはDatabricksの顧客がAPI経由で利用できるようになり、Databricksの顧客は独自のDBRXクラスのモデルをゼロから事前トレーニングしたり、当社が構築に使用したのと同じツールと科学を使用してチェックポイントのいずれかでトレーニングを継続したりできます。DBRXはすでに当社のGenAI搭載製品に統合されており、SQLなどのアプリケーションでは、初期展開��がGPT-3.5 Turboを上回り、GPT-4 Turboに挑戦しています。また、RAGタスクにおいては、オープンモデルやGPT-3.5 Turboの中でも主要なモデルです。
混合エキスパートモデルのトレーニングは困難です。DBRXクラスのモデルを効率的に繰り返しトレーニングできる十分に堅牢なパイプラインを構築するために、さまざまな科学的およびパフォーマンス上の課題を克服する必要がありました。それが完了した今、あらゆる企業がゼロから世界クラスのMoE基盤モデルをトレーニングできる独自のトレーニングスタックを持っています。この機能を顧客と共有し、コミュニティと学習した教訓を共有することを楽しみにしています。
本日、Hugging Face(DBRX Base、DBRX Instruct)からDBRXをダウンロードするか、当社のHF SpaceでDBRX Instructを試すか、GitHubのモデルリポジトリ(databricks/dbrx)をご覧ください。
DBRXとは?
DBRXは、次トークン予測を使用してトレーニングされた、Transformerベースのデコーダーオンリー大規模言語モデル(LLM)です。132Bの総パラメータを持つきめ細かな混合エキスパート(MoE)アーキテクチャを使用しており、そのうち36Bのパラメータがいずれかの入力でアクティブになります。12Tトークンのテキストおよびコードデータで事前トレーニングされました。MixtralやGrok-1のような他のオープンMoEモデルと比較して、DBRXはきめ細かいです。これは、より多くの数の小さなエキスパートを使用することを意味します。DBRXは16のエキスパートを持ち、4つを選択しますが、MixtralとGrok-1は8のエキスパートを持ち、2つを選択します。これにより、65倍の可能なエキスパートの組み合わせが得られ、モデルの品質が向上することがわかりました。DBRXは、ロータリー位置エンコーディング(RoPE)、ゲート付き線形ユニット(GLU)、およびグループ化クエリ注意(GQA)を使用します。GPT-4トークナイザーは、tiktokenリポジトリで提供されているものを使用します。これらの選択は、網羅的な評価とスケーリング実験に基づいて行われました。
DBRXは、12Tトークンの慎重にキュレーションされたデータと最大32kトークンのコンテキスト長で事前トレーニングされました。このデータは、MPTファミリーモデルを事前トレーニングするために使用したデータよりも、トークンあたり少なくとも2倍優れていると推定しています。この新しいデータセットは、データ処理のためのApache Spark™およびDatabricksノートブック、データ管理とガバナンスのためのUnity Catalog、および実験追跡のためのMLflowを含む、Databricksツールのフルスイートを使用して開発されました。事前トレーニングにはカリキュラム学習を使用し、トレーニング中にデータミックスを変更することで、モデルの品質を大幅に向上させることができました。
ベンチマークにおける品質 vs. 主要なオープンモデル
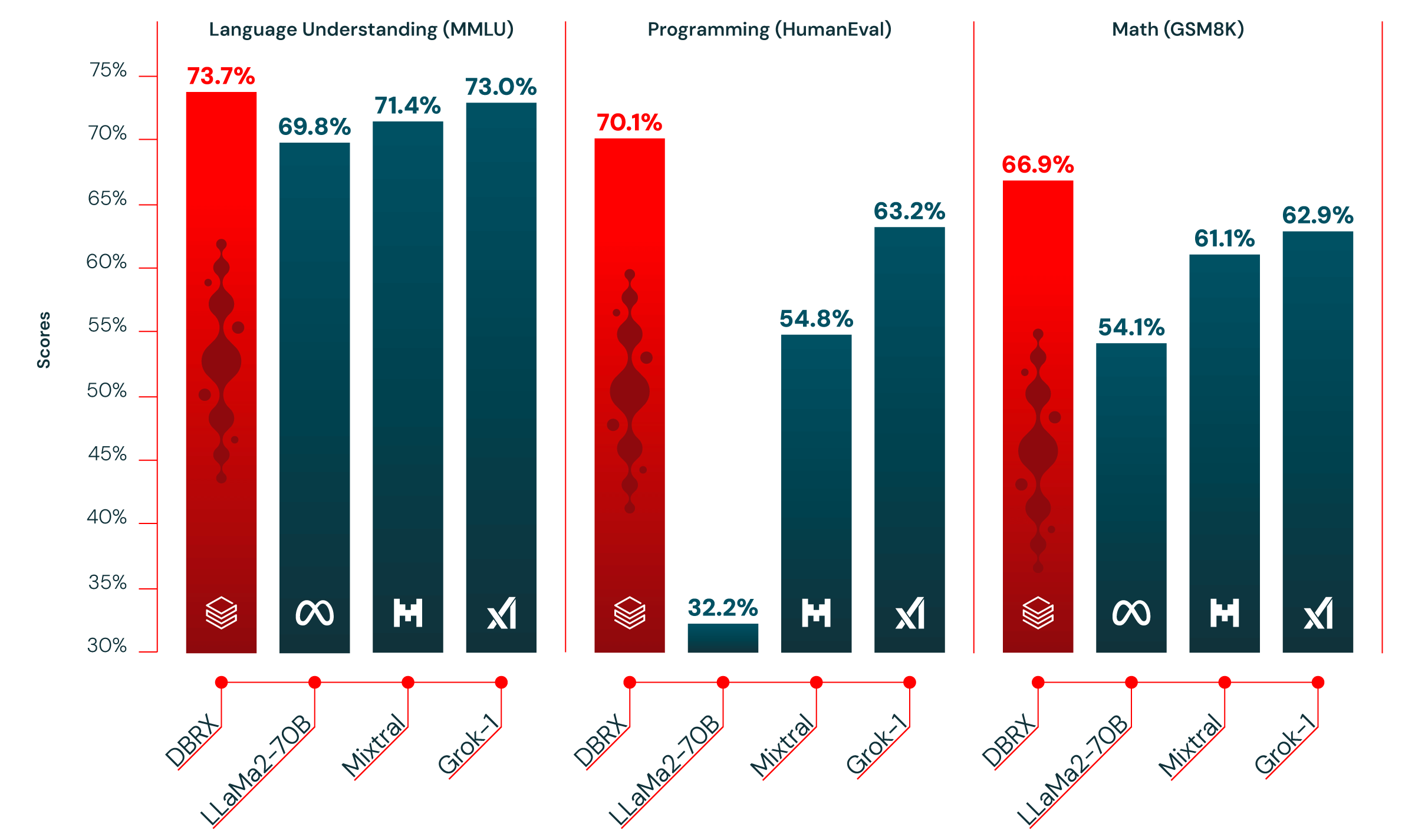
表1は、DBRX Instructと主要な既存のオープンモデルの品質を示しています。DBRX Instructは、複合ベンチマーク、プログラミングおよび数学ベンチマーク、およびMMLUで主要なモデルです。標準ベンチマークでは、すべてのチャットまたはインストラクションファインチューニング済みモデルを上回ります。
複合ベンチマーク。DBRX Instructと競合他社を2つの複合ベンチマークで評価しました。Hugging Face Open LLM Leaderboard(ARC-Challenge、HellaSwag、MMLU、TruthfulQA、WinoGrande、およびGSM8kの平均)とDatabricks Model Gauntlet(世界知識、常識推論、言語理解、読解、記号問題解決、プログラミングの6つのカテゴリにわたる30以上のタスクのスイート)です。
評価したモデルの中で、DBRX Instructは2つの複合ベンチマークで最高スコアを記録しました。Hugging Face Open LLM Leaderboard(次点のMixtral Instructの72.7%に対し74.5%)およびDatabricks Gauntlet(次点のMixtral Instructの60.7%に対し66.8%)です。
プログラミングと数学。DBRX Instructは、プログラミングと数学に特に強みがあります。HumanEval(Grok-1の63.2%、Mixtral Instructの54.8%、および最高のパフォーマンスを発揮したLLaMA2-70Bバリアントの32.2%に対し70.1%)およびGSM8k(Grok-1の62.9%、Mixtral Instructの61.1%、および最高のパフォーマンスを発揮したLLaMA2-70Bバリアントの54.1%に対し66.9%)で、評価した他のオープンモデルよりも高いスコアを獲得しました。DBRXは、Grok-1よりも優れています。Grok-1はこれらのベンチマークで次に良いモデルですが、Grok-1は2.4倍のパラメータを持っています。HumanEvalでは、DBRX Instructは、プログラミング専用に構築されたモデルであるCodeLLaMA-70B Instructさえも上回ります。DBRX Instructは汎用目的で使用するように設計されているにもかかわらず(MetaがCodeLLaMAブログで報告したHumanEvalでの70.1% vs. 67.8%)。
MMLU。DBRX Instructは、MMLUで73.7%に達し、他のすべてのモデルよりも高いスコアを獲得しました。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
表1. DBRX Instructと主要なオープンモデルの品質。収集方法の詳細については、脚注を参照してください。太字と下線付きは最高スコアです。
主要なクローズドモデルとのベンチマークにおける品質
表2は、DBRX Instructと主要なクローズドモデルの品質を示しています。各モデル作成者が報告したスコアによると、DBRX InstructはGPT-3.5(GPT-4論文で説明されている)を上回り、Gemini 1.0 ProおよびMistral Mediumと競合します。
検討したほぼすべてのベンチマークにおいて、DBRX InstructはGPT-3.5を上回るか、少なくとも同等です。DBRX Instructは、MMLU(73.7%対70.0%)で測定される一般知識と、HellaSwag(89.0%対85.5%)およびWinoGrande(81.8%対81.6%)で測定される常識推論においてGPT-3.5を上回ります。DBRX Instructは、HumanEval(70.1%対48.1%)およびGSM8k(72.8%対57.1%)で測定されるプログラミングと数学的推論で特に優れています。
DBRX Instructは、Gemini 1.0 ProおよびMistral Mediumと競合します。DBRX Instructのスコアは、Inflection Corrected MTBench、MMLU、HellaSwag、HumanEvalでGemini 1.0 Proよりも高いですが、Gemini 1.0 ProはGSM8kでより優れています。DBRX InstructとMistral MediumのスコアはHellaSwagで似ていますが、Mistral MediumはWinograndeとMMLUでより優れており、DBRX InstructはHumanEval、GSM8k、Inflection Corrected MTBenchでより優れています。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Table 2. Quality of DBRX Instruct and leading closed models. Other than Inflection Corrected MTBench (which we measured ourselves on model endpoints), numbers were as reported by the creators of these models in their respective whitepapers. See footnotes for additional details.
Quality on Long-Context Tasks and RAG
DBRX Instruct was trained with up to a 32K token context window. Table 3 compares its performance to that of Mixtral Instruct and the latest versions of the GPT-3.5 Turbo and GPT-4 Turbo APIs on a suite of long-context benchmarks (KV-Pairs from the Lost in the Middle paper and HotpotQAXL, a modified version of HotPotQA that extends the task to longer sequence lengths). GPT-4 Turbo is generally the best model at these tasks. However, with one exception, DBRX Instruct performs better than GPT-3.5 Turbo at all context lengths and all parts of the sequence. Overall performance for DBRX Instruct and Mixtral Instruct are similar.
|
|
|
|
|
|
|
|
|
|
|
% |
|
|
|
|
|
% |
|
|
|
|
|
% |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Table 3. The average performance of models on the KV-Pairs and HotpotQAXL benchmarks. Bold is the highest score. Underlined is the highest score other than GPT-4 Turbo. GPT-3.5 Turbo supports a maximum context length of 16K, so we could not evaluate it at 32K. *Averages for the beginning, middle, and end of the sequence for GPT-3.5 Turbo include only contexts up to 16K.
One of the most popular ways to leverage a model’s context is retrieval augmented generation (RAG). In RAG, content relevant to a prompt is retrieved from a database and presented alongside the prompt to give the model more information than it would otherwise have. Table 4 shows the quality of DBRX on two RAG benchmarks - Natural Questions and HotPotQA - when the model is also provided with the top 10 passages retrieved from a corpus of Wikipedia articles using the embedding model bge-large-en-v1.5. DBRX Instruct is competitive with open models like Mixtral Instruct and LLaMA2-70B Chat and the current version of GPT-3.5 Turbo.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
表3。モデル在KV-PairsおよびHotpotQAXLベンチマークでの平均パフォーマンス。太字は最高スコア。下線はGPT-4 Turbo以外の最高スコア。GPT-3.5 Turboは最大16Kのコンテキスト長をサポートしているため、32Kでの評価はできませんでした。*GPT-3.5 Turboのシーケンスの開始、中間、終了の平均には、16Kまでのコンテキストのみが含まれます。
モデルのコンテキストを活用する最も一般的な方法の1つは、Retrieval Augmented Generation(RAG)です。RAGでは、プロンプトに関連するコンテンツがデータベースから取得され、プロンプトと共に提示されることで、モデルは通常よりも多くの情報を提供されます。表4は、埋め込みモデルbge-large-en-v1.5を使用してWikipedia記事のコーパスから取得した上位10個のパッセージがモデルに提供された場合の、2つのRAGベンチマーク(Natural QuestionsおよびHotPotQA)におけるDBRXの品質を示しています。DBRX Instructは、Mixtral InstructやLLaMA2-70B Chatなどのオープンモデルや、GPT-3.5 Turboの現行バージョンと同等の競争力があります。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
表4。bge-large-en-v1.5を使用してWikipediaコーパスから取得した上位10個のパッセージを各モデルに与えた場合のモデルのパフォーマンスを測定した結果。精度は、モデルの回答内の一致によって測定されます。太字は最高スコア、下線はGPT-4 Turbo以外の最高スコアです。
トレーニング効率
モデルの品質は、モデルのトレーニングと使用の効率性と合わせて評価する必要があります。これは、Databricksがお客様が独自の基盤モデルをトレーニングするためのプロセスを確立するためにDBRXのようなモデルを構築しているため、特に重要です。
トレーニングにおける計算効率に大幅な改善をもたらすことが、Mixture-of-Expertsモデルのトレーニングで確認されました(表5)。例えば、DBRXファミリーの小型モデルであるDBRX MoE-B(合計パラメータ数23.5B、アクティブパラメータ数6.6B)のトレーニングでは、LLaMA2-13Bが43.8%に到達するために必要としたFLOPsの1.7倍少ないFLOPsで、Databricks LLM Gauntletで45.5%のスコアに到達しました。DBRX MoE-Bは、LLaMA2-13Bのアクティブパラメータ数の半分しか含んでいません。
全体として、当社のエンドツーエンドのLLM事前��トレーニングパイプラインは、過去10か月で約4倍の計算効率向上を達成しました。2023年5月5日、1Tトークンでトレーニングされた7BパラメータモデルであるMPT-7Bをリリースしました。このモデルは、Databricks LLM Gauntletで30.9%のスコアを達成しました。DBRXファミリーのメンバーであるDBRX MoE-A(合計パラメータ数7.7B、アクティブパラメータ数2.2B)は、3.7倍少ないFLOPsで30.5%のDatabricks Gauntletスコアを達成しました。この効率性は、MoEアーキテクチャの使用、ネットワークのその他のアーキテクチャ変更、より優れた最適化戦略、より優れたトークン化、そして非常に重要なこととして、より優れた事前トレーニングデータなど、数多くの改善の結果です。
単体で見ても、より質の高い事前学習データはモデルの品質に大きな影響を与えました。DBRXの事前学習データを使用して1兆トークンで7Bモデルをトレーニングしました(DBRX Dense-Aと呼びます)。このモデルはDatabricks Gauntletで39.0%を達成し、MPT-7Bの30.9%と比較して大幅に向上しました。新しい事前学習データは、MPT-7Bのトレーニングに使用されたデータと比較して、トークンあたりの性能が少なくとも2倍優れていると推定しています。つまり、同じモデル品質を達成するために必要なトークン数は半分で済むと推定しています。DBRX Dense-Aを500Bトークンでトレーニングした結果、Databricks GauntletでMPT-7Bを上回り、32.1%を達成したことで、この推定に至りました。データ品質の向上に加えて、このトークン効率の向上に寄与したもう一つの重要な要因は、GPT-4トークナイザーである可能性があります。このトークナイザーは語彙が豊富で、特にトークン効率が高いと考えられています。データ品質を向上させることに関するこれらの教訓は、お客様が独自のデータで基盤モデルをトレーニングするために使用するプラクティスやツールに直接活かされます。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
表5。DBRX MoEアーキテクチャとエンドツーエンドトレーニングパイプラインのトレーニング効率を検証するために使用した、いくつかのテスト記事の詳細
推論効率
図2は、最適化されたサービングインフラストラクチャと16ビット精度を使用してNVIDIA TensorRT-LLMでDBRXおよび類似モデルをサービングするエンドツーエンドの推論効率を示しています。このベンチマークは、複数のユーザーが同時に同じ推論サーバーにアクセスするなど、実際の使用状況を可能な限り正確に反映することを目指しています。1秒あたり1人の新しいユーザーを生成し、各ユーザーのリクエストには約2000トークンのプロンプトが含まれ、各応答は256トークンで構成されます。
一般的に、MoEモデルは、総パラメータ数よりも推論が高速です。これは、各入力に対して比較的少ないパラメータしか使用しないためです。DBRXもこの点では例外ではありません。DBRXの推論スループットは、132Bの非MoEモデルよりも2〜3倍高くなります。
推論効率とモデルの品質は通常トレードオフの関係にあります。モデルが大きくなるほど品質は高くなる傾向がありますが、モデルが小さいほど推論効率は高くなります。MoEアーキテクチャを使用すると、通常の密なモデルよりもモデルの品質と推論効率の間のより良いトレードオフを達成することが可能になります。たとえば、DBRXはLLaMA2-70Bよりも高品質であり、アクティブなパラメータ数が半分であるため、DBRXの推論スループットは最大2倍高速です(図2)。Mixtralは、MoEモデルによって達成される改善されたパレートフロンティア上の別のポイントです。DBRXよりも小さく、それに伴い品質は低いですが、より高い推論スループットを達成します。Databricks Foundation Model APIのユーザーは、最適化されたモデルサービングプラットフォームで8ビット量子化を使用して、DBRXで毎秒最大150トークンを期待できます。

DBRXの構築方法
DBRXは、3.2TbpsのInfinibandで接続された3072個のNVIDIA H100でトレーニングされました。DBRXの構築(事前トレーニング、ポストトレーニング、評価、レッドチーミング、および改良を含む)の主なプロセスは、3か月かけて行われました。これは、科学、データセットリサーチ、およびスケーリング実験の数か月にわたる継続であり、Databricksでの長年のLLM開発(MPTおよびDollyプロジェクト、およびお客様と共同で構築および本番稼働させた数千のモデルを含む)は言うまでもありません。
DBRXを構築するために、お客様が利用できるのと同じDatabricksツールスイートを活用しました。Unity Catalogを使用してトレーニングデータを管理およびガバナンスしました。新しく取得したLilac AIを使用してこのデータを探索しました。Apache Spark™およびDatabricksノートブックを使用してこのデータを処理およびクリーニングしました。オープンソーストレーニングライブラリの最適化バージョンを使用してDBRXをトレーニングしました:MegaBlocks、LLM Foundry、Composer、お��よびStreaming。Databricks Trainingサービスを使用して、数千のGPUにわたる大規模モデルトレーニングとファインチューニングを管理しました。MLflowを使用して結果を記録しました。Databricks Model ServingおよびInference Tablesを通じて、品質と安全性の向上のための人間のフィードバックを収集しました。Databricks Playgroundを使用してモデルを手動で実験しました。Databricksツールはそれぞれの目的に対してクラス最高であると判断し、それらがすべて統一された製品エクスペリエンスの一部であったという事実に恩恵を受けました。
DatabricksでDBRXを開始する
DBRXをすぐに使い始めたい場合は、Databricks Foundation Model APIを使用すると簡単です。従量課金制の価格設定ですぐに開始でき、AI Playgroundチャットインターフェイスからモデルにクエリを実行できます。本番アプリケーション向けに、パフォーマンス保証、ファインチューニング済みモデルのサポート、および追加のセキュリティとコンプライアンスを提供するために、プロビジョニングされたスループットオプションを提供しています。DBRXをプライベートにホストするには、Databricks Marketplaceからモデルをダウンロードし、Model Servingでモデルをデプロイできます。
結論
Databricksでは、すべての企業が、新興のGenAIの世界において、データと運命をコントロールできる能力を持つべきだと信じています。DBRXは、次世代のGenAI製品の中核をなすものであり、お客様がDBRXの機能とそれを構築するために使用したツールを活用する際の、エキサイティングな旅を楽しみにしています。過去1年間で、お客様と共に数千ものLLMをトレーニングしてきました。DBRXは、社内機能からお客様の野心的なユースケースまで、幅広いアプリケーションのためにDatabricksで構築されている強力で効率的なモデルのほんの一例です。
新しいモデルと同様に、DBRXとの旅は始まったばかりであり、その上に構築する企業やオープンコミュニティによって最良の仕事が行われるでしょう。これもDBRXに関する私たちの仕事の始まりにすぎず、さらに多くのことが期待できるはずです。
貢献
DBRXの開発は、MPTモデルファミリーを以前に構築したMosaicチームが主導し、Databricks全社から数十人のエンジニア、法律専門家、調達および財務スペシャリスト、プログラムマネージャー、マーケター、デザイナー、その他の貢献者と協力しました。過去数か月間の同僚、友人、家族、そしてコミュニティの忍耐とサポートに感謝します。
DBRXの作成にあたり、私たちはオープンコミュニティと学術コミュニティの偉大な功績の上に成り立っています。DBRXをオープンに公開することで、将来さらに素晴らしい技術を共に築き上げることを期待し、コミュニティに還元していきたいと考えています。そのことを念頭に、Trevor Gale氏とそのMegaBlocksプロジェクト(Trevor氏の博士課程の指導教員はDatabricksのCTOであるMatei Zaharia氏です)、PyTorchチームとFSDPプロジェクト、NVIDIAとTensorRT-LLMプロジェクト、vLLMチームとプロジェクト、EleutherAIとそのLLM evaluationプロジェクト、Lilac AIのDaniel Smilkov氏とNikhil Thorat氏、そしてAllen Institute for Artificial Intelligence (AI2) の友人たちの功績と協力に感謝いたします。
Databricksについて
Databricksは、データとAIの会社です。Comcast、Condé Nast、Grammarlyをはじめとする世界中の10,000以上の組織、およびFortune 500企業の50%以上が、Databricks Data Intelligence Platformを活用してデータ、分析、AIを統合し、民主化しています。Databricksはサンフランシスコに本社を置き、世界中にオフィスを展開しています。Lakehouse、Apache Spark™、Delta Lake、MLflowのオリジナルクリエイターによって設立されました。詳細については、LinkedIn、X、FacebookでDatabricksをフォローしてください。
1 xAIの報告による数値です。リリース時にHugging Face互換のチェックポイントがなかったため、当社の完全なベンチマークスイートでGrok-1を評価することはできませんでした。
2 DBRXは、EleutherAI Harnessを使用して当社が測定しました。その他のすべての数値は、Hugging Face Open LLM Leaderboardで報告されたものです。
3 DBRXは、Hugging Face Open LLM Leaderboardで使用されているものと同じ古いコミットを使用して、EleutherAI Harnessで当社が測定しました。その他のすべての数値は、Hugging Face Open LLM Leaderboardで報告されたものです。EleutherAI Harnessの最新コミットを使用すると、GSM8kでのDBRXの5-shotスコアは、表2に報告されているように72.8%まで上昇することに注意してください。LLaMA2-70B Chatも48.4%まで上昇します。
4 DatabricksがGauntlet v0.3.0をLLM Foundryで測定しました。
5 特に記載がない限り、Databricksによって測定されました。
6 この数値はMixtral Arxiv論文からのものです。当社が独自にモデルを評価した際の数値(36.7%)よりも高いため、この数値を報告します。
7 すべてのスコアはGPT-4論文で報告されている通りです。このバージョンのGPT-3.5は利用できなかったため、Inflection Corrected MTBenchを収集できませんでした。現在のバージョンのGPT-3.5 Turboは、Inflection Corrected MTBenchで8.58 ± 0.04のスコアを示し、DBRX Instructの8.39 +/- 0.08と比較されました。
8 すべてのスコアはGPT-4論文で報告されている通りです。このバージョンのGPT-4は利用できなかったため、Inflection Corrected MTBenchを収集できませんでした。現在のバージョンのGPT-4 Turboは、Inflection Corrected MTBenchで9.27 ± 0.10のスコアを示し、DBRX Instructの8.39 +/- 0.08と比較されました。
(このブログ記事はAI翻訳ツールを使用して翻訳されています) 原文記事
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。