Ray on Databricksの一般提供開始のお知らせ
最適化されたApache Spark on DatabricksとともにRayの機能とパワーを活用する
によって スティーブン・オファー, Weichen Xu, Ben Wilson, Maheswaran Venkatachalam, Puneet Jain, ��ニティン・ワグ 、 ハワード・ウー による投稿
昨年、Rayサポートのパブリックプレビューをリリースして以来、何百ものDatabricksのお客様が、マルチモデル階層予測やLLMファインチューニング、強化学習など、様々なユースケースに使用してきました 。 本日、DatabricksにおけるRayサポートの一般提供を発表できることを嬉しく思います。 Rayは、バージョン15.0以降、機械学習ランタイムの一部として含まれるようになり、Databricksでファーストクラスとして提供されるようになりました。 お客様は、追加インストールなしで Rayクラスターを開始することができ、Databricksが提供する統合された製品群(Unity Catalog、Delta Lake、MLflow、Apache Sparkなど)の中で、この強力なフレームワークの使用を開始することができます。
調和のとれた統合:Databricks上のRayとSpark
Ray on Databricksの一般提供により、Databricks上で分散ML AIワークロードを実行する選択肢が広がり、新たなPythonワークロードも登場します。 これにより、論理並列性とデータ並列性が共存共栄する、まとまりのあるエコシステムを作り出します。 Rayは、Sparkに最適化されたMLワークロードのようにデータ分割に大きく依存しないPythonコードの処理に、論理並列処理という新たなアプローチを提供することで、Databricksのサービ��スを補完します。
この統合の最もエキサイティングな側面の1つは、Spark DataFramesとの相互運用性にあります。 従来、異なる処理フレームワーク間でデータを移行することは、煩雑でリソース集約的であり、多くの場合、コストのかかる書き込み・読み取りのサイクルを伴いました。 しかし、Ray on Databricksでは、プラットフォームがSparkとRay間の直接のインメモリデータ転送を容易にし、中間ストレージや高価なデータ変換処理を不要にします。 この相互運用性により、Databricksのデータ効率と計算能力の高い環境を離れることなく、Sparkでデータを効率的に操作し、Rayにシームレスに渡すことができます。
「Marks and Spencerでは、予測がビジネスの中心であり、在庫計画や販売予測、サプライチェーン最適化などのユースケースを可能にしています。 そのためには、ユースケースを実現するための堅牢でスケーラブルなパイプラインが必要です。 M&Sでは、Ray on Databricksのパワーを活用し、モデルのチューニングやトレーニング、予測に至るまで、本番環境ですぐに使えるパイプラインを実験・提供しています。 これにより、Sparkのスケーラブルなデータ処理機能とRayのスケーラブルなMLワークロードを使用したエンドツーエンドのパイプラインを自信を持って提供できるようになりました」 - Marks and Spencer、シニアMLエンジニア、Joseph Sarsfield氏
Ray on Databricksによる新しいアプリケーションの強化
RayとDatabricksの統合は、両フレームワークのユニークな強みを生かした�無数のアプリケーションへの扉を開きます:
- 強化学習:RLlibを用いたRayの分散コンピューティングを活用し、自律走行車やロボット工学のための高度なモデルを展開します。
- 分散カスタムPythonアプリケーション:複雑な計算を必要とするタスクのために、カスタムPythonアプリケーションをクラスター全体でスケーリングします。
- ディープラーニングのトレーニング:コンピュータビジョンや言語モデルの深層学習タスクに対して、Rayの分散型特性を活用した効率的なソリューションを提供します。
- 高性能コンピューティング(HPC):ゲノミクス、物理学、金融計算のような大規模なタスクに、Rayのハイパフォーマンスコンピューティングワークロードの能力で対応します。
- Distributed TraditionalMachine Learning:scikit-learnや予測モデルのような伝統的な機械学習モデルのクラスター間での分散を強化します。
- Pythonワークフローの強化:複雑なオーケストレーションやタスク間の通信を必要とするタスクを含め、従来は単一ノードに限定されていたカスタムPython タスクを分散します。
- ハイパーパラメータ探索:ハイパーパラメータチューニングのためのHyperoptに代わる選択肢を提供し、より効率的な検索のためにRay Tuneを利用します。
- Rayエコシステムの活用:Ray内のオープンソースライブラリやツールの広範なエコシステムと統合し、開発環境を豊かにします。
- 超並列データ処理:SparkとRayを組み合わせてUDFやforeachバッチ関数を改良します��。オーディオやビデオのような非表形式データの処理に最適です。
Rayクラスターの開始
DatabricksでRayクラスターを開始するのは非常に簡単で、数行のコードで済みます。このシームレスな開始とDatabricksのスケーラブルなインフラストラクチャの組み合わせにより、Rayの計算能力とDatabricks上のSparkのデータ処理能力の両方を活用して、アプリケーションを開発から本番環境にスムーズに移行することができます。
Databricks Machine Learning Runtime 15.0以降、Rayはクラスターにプリインストールされ、完全にセットアップされています。 以下のコードを参考に、Rayクラスターを起動することができます(クラスターの設定によっては、これらの引数をクラスターで使用可能なリソー スに合わせて変更する必要があります):
このアプローチでは、高度にスケーラブルで管理されたDatabricks Sparkクラスター上で、Rayクラスターを開始します。このRayクラスターは、一旦スタートし利用可能になると、Databricksが提供する他のDatabricks機能やインフラ、ツールとシームレスに統合することができます。 また、ダイナミックオートスケーリング、オンデマンドインスタンスとスポットインスタンスを組み合わせた起動、クラスターポリシーなどのエンタープライズ機能を活用することもできます。 コードの編集中のインタラクティブなクラスターから、長時間ジョブのためのジョブクラスターに簡単に切り替えることができます。
ノートパ�ソコン上でRayを実行することから、クラウド上の何千ものノードに移行するには、直前のsetup_ray_cluster関数を使用して数行のコードを追加するだけです。 Databricksは、基盤となるSparkクラスターを通じてRayクラスターのスケーラビリティを管理します。これは、指定されたワーカー ノードの数とRayクラスター専用のリソースを変更するだけで簡単です。
「過去1年半の間、私たちはRayを幅広く活用してきました。 予期せぬエラーや問題を起こすことなく、一貫して信頼性の高いパフォーマンスを提供してくれています。 アプリケーションの速度性能に対する影響は特に顕著で、DatabricksでのRayクラスターの実装が、処理時間を少なくとも半分に短縮する上で重要な役割を果たしました。場合によっては、4倍を超える目覚ましい改善が見られました。すべて追加費用は必要ありません。 さらに、Rayダッシュボードは、各タスクのメモリ消費量を知ることができ、アプリケーションに最適化された設定を確認することができます」 - Cummins社、シニア機械学習エンジニア、Juliana Negrini de Araujo氏
Databricksでのデータサイエンスの強化:MLflowとUnity Catalogを使用したRay
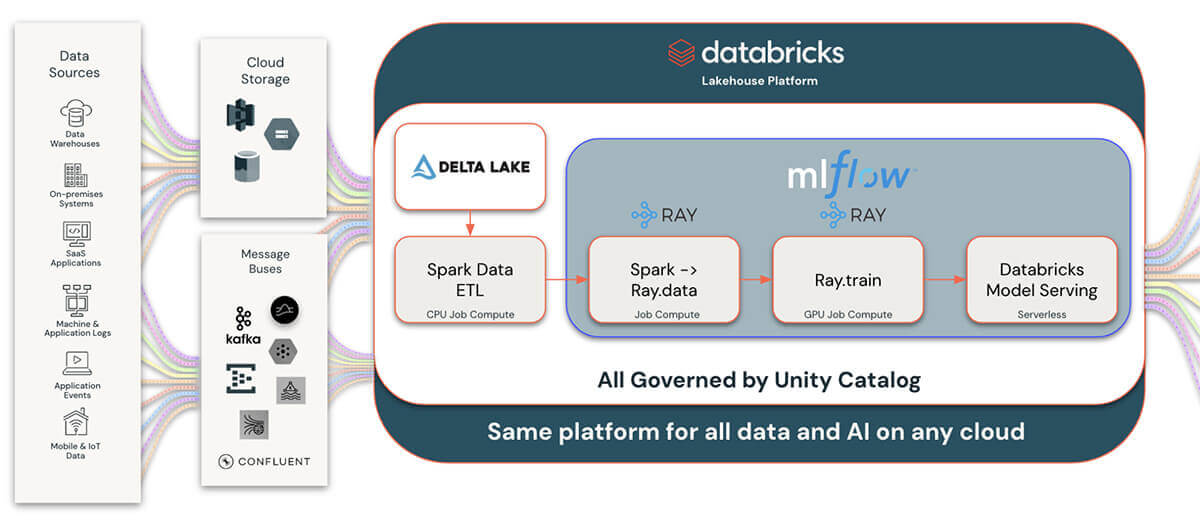
Databricksは、Rayを3つの主要なマネージドサービスと統合することで、データサイエンスのワークフローを強化します:ライフサイクル管理のMLflow、データガバナンスのUnity Catalog、そしてMLOpsのModel Servingです。 この統合により、Rayで開発された機械学習モデルの追跡、最適化、デプロイが効率化され、MLflowを活用したシームレスなモデルライフサイクル管理が可能になります。 データサイエンティストは、Databricksの統一プラットフォーム内で、実験の効率的なモニタリング、モデルのバージョン管理、生産ラインへのモデルのデプロイを行うことができます。
Unity Catalogは、堅牢なデータガバナンスを提供し、明確なリネージを可能にし、Rayで作成された機械学習アーティファクトを共有することで、このエコシステムをサポートします。 これにより、すべての資産にわたってデータの品質とコンプライアンスが保証され、安全で規制された環境での効果的なコラボレーションが促進されます。
Unity Catalogと当社のDelta Lake統合をRayと組み合わせることで、データおよびAIランドスケープの他の部分と、より広範で包括的な統合が可能になります。 これにより、Rayユーザーと開発者は、これまで以上に多くのデータソースと統合することができます。 Rayアプリケーションから生成されたデータをDelta LakeとUnity Catalogに書き込むことで、膨大なデータとビジネスインテリジェンスツールのエコシステムへの接続も可能になります。
Ray、MLflow、Unity Catalog、モデルサービングの組み合わせは、高度なデータサイエンスソリューションの展開を簡素化し加速させ、機械学習プロジェクトにおけるイノベーションとコラボレーションのための包括的で統制されたプラットフォームを提供します。
DatabricksでRayを始めましょう
RayとDatabricks のコラボレーションは単なる統合ではなく、2つのフレームワークの緊密な結合を提供します。この2つのフレームワークは、それぞれの強みに秀でているだけでなく、一緒に統合することで、AI開発のニーズにユニークで強力なソリューションを提供します。 この統合により、開発者やデータサイエンティストは、MLflow、Delta Lake、Unity Catalogを含むDatabricksのプラットフォームの膨大な機能を利用できるだけでなく、Rayの計算効率と柔軟性をシームレスに統合することができます。 詳しくは、DatabricksでのRayの使い方ガイドをご覧ください。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。