Logically AIでGPU推論をターボチャージ!
によって David Fodor(Logically AI), Neeraj Bhadani(Logically AI), マーク・ド・フォンテネイ 、 マリア・ゼルヴォウ による投稿
GPU加速技術を活用することで、MLエンジニアは訓練と推論の時間を大幅に短縮し、より多くの実験、より速い反復、そして改善されたモデルのパフォーマンスを可能にします。GPUは高い需要があります。このリソースの現在の不足は、AIプロジェクトの全体的な成功のために、その利用を最適化することが重要であることを意味します。このブログでは、Logicallyがモデル推論のためのGPUリソースを最適化することで結果を改善した方法を探ります。
2017年に設立されたLogicallyは、AIを使用してクライアントのインテリジェンス能力を強化する分野のリーダーです。ウェブサイト、ソーシャルプラットフォーム、その他のデジタルソースから大量のデータを処理し分析することで、Logicallyは潜在的なリスク、新たな脅威、重要なナラティブを特定し、それらをサイバーセキュリティチーム、プロダクトマネージャー、エンゲージメントリーダーが迅速かつ戦略的に行動できるように整理します。
GPU加速はLogicallyのプラットフォームの重要な要素であり、高度に規制されたエンティティの要件を満たすためのナラティブの検出を可能にします。GPUを使用することで、Logicallyは訓練と推論の時間を大幅に短縮し、ソーシャルメディアやインターネット全体での偽情報の拡散を防ぐために必要なスケールでのデータ処理を可能にしました。現在のGPUリソースの不足も、最適なレイテンシとAIプロジェクトの全体的な成功を達成するために、その利用を最適化することが重要であることを意味します。
ロジカルには、データ量が増えるにつれて推論時間が徐々に増加していることを観察し、その結果、クラスター使用の理解と最適化の必要性が生じました。大きなGPUクラスタはモデルをより速く実行しましたが、利用率は低かった。この観察から、Sparkの分散力を最大限に活用してGPUモデルの推論を最適な方法で実行し、クラスターの全潜在能力を引き出すためには別の設定が必要かどうかを判断するというアイデアが生まれました。
エグゼキュータごとの並行タスクを調整し、GPUごとにより多くのタスクを押し出すことで、Logicallyはその主要な複雑なモデルの実行時間を最大40%削減することができました。 このブログではその方法を探ります。
使用された主要なレバーは次のとおりです:
1. 分数GPU割り当て: SparkがGPUリソースをスケジュールする際のタスクごとのGPU割り当てを制御することで、それを各エグゼキュータのタスク間で均等に分割することが可能になります。これにより、I/Oと計算が重なり、GPUの最適な利用が可能になります。
デフォルトのスパーク設定はGPUごとに1タスク、以下に示すようになっています。これは、各タスクに大量のデータがプッシュされない限り、GPUはおそらく未使用のままになる可能性が高いということです。

設定によりspark.task.resource.gpu.amountを 1以下の値に設定することで、例えば0.5や0.25など、ロジカルには各GPUをタスク間でより良く分散させることができました。この設定を試すことで最大の改善が見られました。この設定の値を減らすことで、各GPUでより多くのタスクを並行して実行でき、推論ジョブがより早く終了します。

この設定で実験することは良い初期ステップであり、最小限の調整で最大の影響を与えることがよくあります。次の設定では、Sparkの動作方法と微調整した設定について少し深く掘り下げます。
2. 並行タスクの実行: クラスタがエグゼキュータごとに複数の並行タスクを実行することを確認することで、より良い並列化��が可能になります。
スタンドアロンモードでは、もし spark.executor.cores が明示的に設定されていない場合、各エグゼキュータはワーカーノード上の利用可能な全コアを使用し、GPUリソースの均等な分配を防ぎます。
次の spark.executor.cores の設定は、 spark.task.resource.gpu.amount の設定に対応して設定することができます。 例えば、 spark.executor.cores=2 は、各エグゼキュータで2つのタスクを実行することを可能にします。GPUリソースの分割が spark.task.resource.gpu.amount=0.5であれば、これら2つの並行タスクは同じGPU上で実行されます。
Logicallyは、1つのエグゼキュータをGPUごとに実行し、コアをエグゼキュータ間で均等に分配することで最適な結果を得ました。例えば、24コアと4つのGPUを持つクラスタは、エグゼキュータごとに6コア(--conf spark.executor.cores=6)で実行されます。これにより、Sparkが一度にエグゼキュータに配置するタスクの数を制御します。

3. Coalesce:既存のパーティションをより少ない数に統合することで、大量のパーティションを管理するオーバーヘッドを減らし、各パーティションにより多くのデータを収めることができます。 coalesce()のGPUに対する関連性は、データ分布と最適化に関連しており、GPUの効率的な利用に必要です。GPUは高度に並列化されたアーキテクチャのため、大量のデータセットを処理するのに優れています。これにより、多くの操作を同時に実行することができます。GPUを効率的に利用するためには、以下のことを理解する必要があります:
- 大きなパーティションのデータは、GPUが大量の並列ワークロードを処理できるため、よく効果があります。大きなパーティションは、利用可能なGPUメモリに収まる限り、GPUメモリの利用率を向上させます。この限界を超えると、OOMに遭遇する可能性があります。
- 未使用のGPU(小さなパーティションや小さなワークロード、シンプルな読み取りのため、Sparkはパーティションサイズを128MBを目指します)は、多くのGPUコアがアイドル状態になり、効率が悪くなる可能性があります。
これらの場合、 coalesce() は パーティションの数を減らすことで助けとなり、各パーティションが より多くのデータを含むようにします。これは、GPU処理にとってよく好まれます。パーティションごとの大きなデータチャンクは、GPUがより良く利用され、その並列コアを活用して一度により多くのデータを処理することができます。
Coalesceは、既存のパーティションを結合してパーティション数を減らし、特定のシナリオでパフォーマンスとリソース利用率を向上させることができます。可能な場合、パーティションはエグゼキュータ内でローカルにマージされ、クラスタ全体でのデータの完全なシャッフルを避けます。
coalesceが均等なパーティションを保証しないことに注意が必要で、これによりデータの分布が偏る可能性があります。データに偏りが含まれていることを知っている場合、repartition()が推奨されます。これは、データをパーティション間で均等に再分配する完全なシャッフルを実行します。もしrepartition()があなたのユースケースに適している場合、設定でAdaprite Query Execution (AQE)をオフにすることを確認してください。spark.conf.set("spark.databricks.optimizer.adaptive.enabled","false)。AQEは動的にパーティションを結合することができ、これがこの演習で達成しようとしている最適なパーティションに干渉する可能性があります。
パーティションの数を制御することで、Logicallyチームは各パーティションにより多くのデータを押し込むことができました。パーティションの数を利用可能なGPUの数の倍数に設定すると、GPUの利用率が向上しました。
Logicallyはcoalesce(8)、coalesce(16)、 coalesce(32) そして coalesce(64) を試し、 coalesce(64)で最適な結果を得ました。
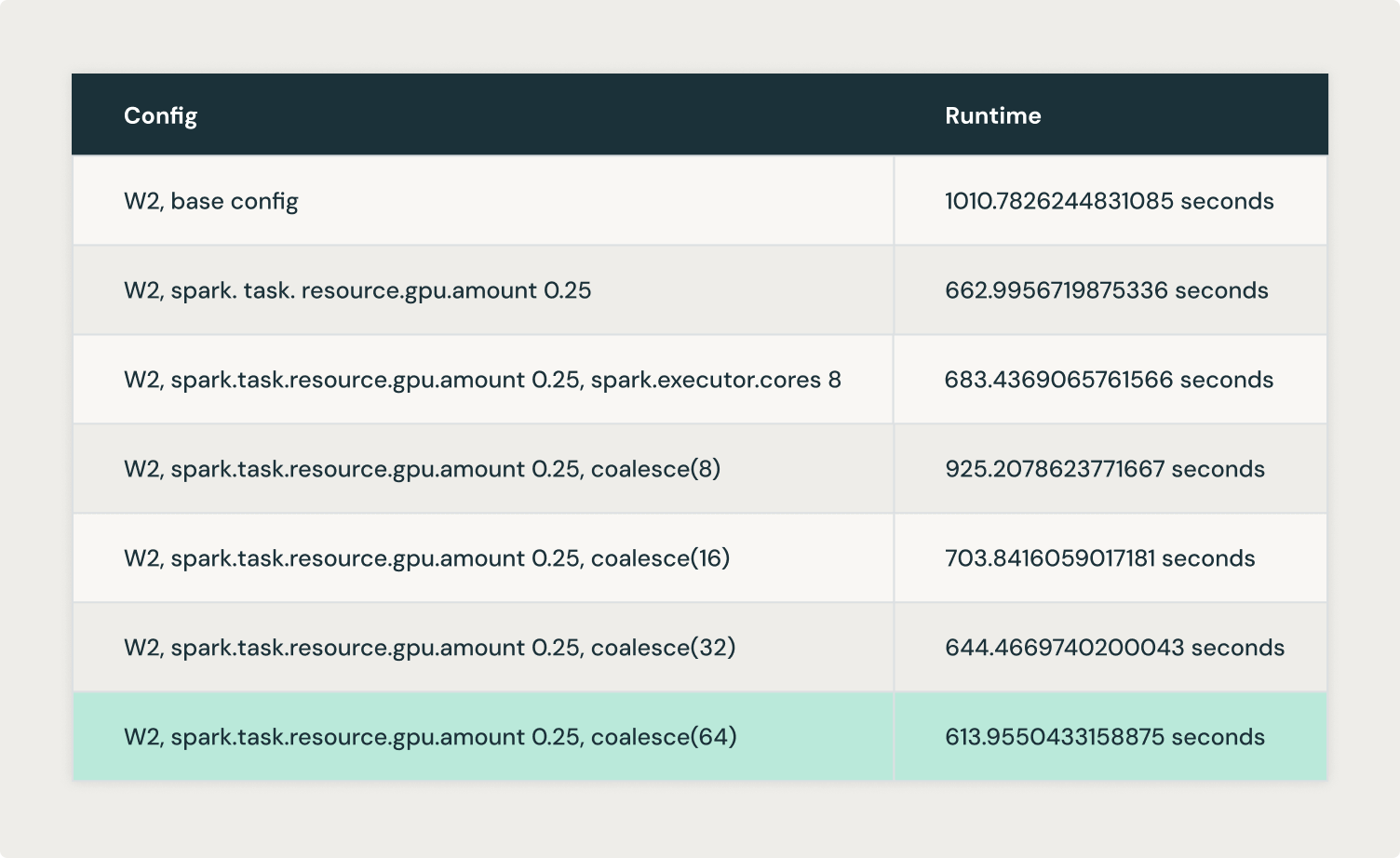
上記の実験から、GPUの利用率を向上させるために、パーティションの大きさをどの程度にするべきかというバランスがあることが理解できました。そこで、我々は maxPartitionBytes の設定をテストし、後から作成する代わりに最初から大きなパーティションを作成することを目指しました。これは、coalesce() や repartition()を使用することで実現されます。
maxPartitionBytesは、ファイルからデータが読み取られるときのメモリ内の各パーティションの最大サイズを決定するパラメータです。デフォルトでは、このパラメータは通常128MBに設定されていますが、私たちの場合は、より大きなパーティションを目指して512MBに設定しました。これにより、Sparkが実行者やGPUのメモリを圧倒する可能性のある過度に大きなパーティションを作成するのを防ぎます。目指すのは、ディスクの過度なスピルやメモリエラーによるパフォーマンスの低下を引き起こすことなく、利用可能なメモリに収まる管理可能なパーティションサイズです。

これらの実験は、Logicallyプラットフォーム全体でのさらなる最適化の道を開きました。これには、Rayを活用して分散アプリケーションを作成し、Databricksエコシステムの幅広さを活用し��ながら、データ処理と機械学習のワークフローを強化することが含まれます。例えば、Rayは、組み込みのGPUオートスケーリング機能やGPU利用率監視を通じて、GPUリソースの並列性をさらに最大化するのに役立ちます。これは、GPU加速からの価値を増加させる機会を表しており、それは有害なナラティブの拡散から機関を保護するというLogicallyの継続的なミッションにとって重要です。
詳細情報
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。