LLM推論パフォーマンスエンジニアリング:ベストプラクティス
によって メーガ・アガルワル, アスファンディヤール・クレシ, ニキル・サルダナ, リンデン・リー, ジュリアン・ケベド 、 ダヤ・クディア による投稿
In this blog post, the MosaicML engineering team shares best practices for how to capitalize on popular open source large language models (LLMs) for production usage. We also provide guidelines for deploying inference services built around these models to help users in their selection of models and deployment hardware. We have worked with multiple PyTorch-based backends in production; these guidelines are drawn from our experience with FasterTransformers, vLLM, NVIDIA's soon-to-be-released TensorRT-LLM, and others.
LLMテキスト生成の理解
大規模言語モデル(LLM)は、2段階のプロセスでテキストを生成します。「プリフィル」では、入力プロンプトのトークンが並列処理され、「デコード」では、テキストが自己回帰的に一度に1つの「トークン」ずつ生成されます。生成された各トークンは入力に追加され、モデルにフィードバックされて次のトークンが生成されます。LLMが特別なストップトークンを出力するか、ユーザー定義の条件(例:最大トークン数が生成された)が満たされると、生成は停止します。LLMがデコーダーブロックをどのように使用するかについてさらに詳しく知りたい場合は、こちらのブログ記事をご覧ください。
トークンは単語またはサブワードの場合があります。テキストをトークンに分割する正確なルールは、モデルによって異なります。たとえば、Llamaモデルがテキストをトークン化する方法とOpenAIモデルがテキストをトークン化�する方法を比較できます。LLM推論プロバイダーは、トークンベースのメトリクス(例:トークン/秒)でパフォーマンスについて話すことが多いですが、これらのバリエーションを考慮すると、これらの数値はモデルタイプ間で常に比較可能とは限りません。具体的な例として、Anyscaleのチームは、Llama 2のトークン化はChatGPTのトークン化よりも19%長い(ただし、全体的なコストははるかに低い)ことを発見しました。また、HuggingFaceの研究者も、Llama 2はGPT-4と同じ量のテキストをトレーニングするのに約20%多くのトークンを必要としたことを発見しました。
LLMサービングにおける重要なメトリクス
では、推論速度を正確にどのように考えるべきでしょうか?
私たちのチームは、LLMサービングのために4つの主要なメトリクスを使用しています。
- Time To First Token (TTFT): ユーザーがクエリを入力してから、モデルの出力を見始めるまでの速さ。リアルタイムの対話では、応答の待ち時間が短いことが不可欠ですが、オフラインワークロードではそれほど重要ではありません。このメトリクスは、プロンプトを処理し、最初の出力トークンを生成するために必要な時間によって決まります。
- Time Per Output Token (TPOT): システムにクエリを実行している各ユーザーの出力トークンを生成するのにかかる時間。このメトリクスは、各ユーザーがモデルの「速度」をどのように認識するかに対応します。たとえば、TPOTが100ミリ秒/トークの場合、ユーザーあたり毎秒10トークン、つまり約毎分450語となり、これは通常の人が読める速度よりも速いです。
- レイテンシ: モデルがユーザーの完全な応答を生成するためにかかる全体的な時間。全体の応答レイテンシは、前の2つのメトリクスを使用して計算できます:レイテンシ = (TTFT) + (TPOT) * (生成されるトークンの数)。
- スループット: 推論サーバーがすべてのユーザーとリクエスト全体で生成できる、毎秒あたりの出力トークン数。
私たちの目標は?最速のTime To First Token、最高のスループット、そして最も速いTime Per Output Tokenです。言い換えれば、モデルができるだけ多くのユーザーをサポートするために、できるだけ速くテキストを生成したいと考えています。
注目すべきは、スループットとTime Per Output Tokenの間にはトレードオフがあるということです。16人のユーザークエリを並行して処理する場合、シーケンシャルにクエリを実行する場合と比較して高いスループットが得られますが、各ユーザーの出力トークンを生成するには時間がかかります。
全体の推論レイテンシの目標がある場合、モデルを評価するための便利なヒューリスティックをいくつか紹介します。
- 出力長が全体の応答レイテンシを支配する: 平均レイテンシの場合、通常は期待される/最大出力トークン長に、モデルの平均的な出力トークンあたりの時間を掛けるだけで十分です。
- 入力長はパフォーマンスにとって重要ではないが、ハードウェア要件にとっては重要: 512の入力トークンを追加しても、MPTモデルで8つの追加出力トークンを生成するよりもレイテンシの増加は少なくなります。しかし、長い入力をサポートする必要があると、モデルのサービングが難しくなる可能性があります。たとえば、MPT-7Bを最大コンテキスト長2048トークンでサービングするには、A100-80GB(またはそれ以降)の使用を推奨します。
- 全体のレイテンシはモデルサイズに対してサブ線形にスケールする: 同じハードウェアでは、より大きなモデルは遅くなりますが、速度比は必ずしもパラメータ数比に一致するとは限りません。MPT-30BのレイテンシはMPT-7Bのレイテンシの約2.5倍です。Llama2-70BのレイテンシはLlama2-13Bのレイテンシの約2倍です。
将来の顧客から、平均推論レイテンシを提供するように求められることがよくあります。「トークンあたり20ミリ秒未満が必要」といった特定のレイテンシ目標に固執する前に、期待される入力長と希望する出力長を特徴付けるために時間を費やすことをお勧めします。
LLM推論における課題
LLM推論の最適化は、次のような一般的な技術から恩恵を受けます。
- オペレーター融合: 異なる隣接するオペレーターを組み合わせることで、レイテンシが改善されることがよくあります。
- 量子化: 活性化と重みが圧縮され、より少ないビット数を使用します。
- 圧縮: スパース性または蒸留。
- 並列化: 複数のデバイスにわたるテンソル並列処理、またはより大きなモデルのパイプライン並列処理。
これらの方法以外にも、多くの重要なTransformer固有の最適化があります。その代表的な例がKV(キーバリュー)キャッシングです。デコーダーオンリーのTransformerベースモデルのアテンションメカニズムは計算効率が悪いです。各トークンは、それまでに見られたすべてのトークンに注意を払い、新しいトークンが生成されるたびに同じ値の多くを再計算します。たとえば、N番目のトークンを生成している間、(N-1)番目のトークンは(N-2)番目、(N-3)番目…1番目のトークンに注意を払います。同様に、(N+1)番目のトークンを生成している間、N番目のトークンのアテンションは再び(N-1)番目、(N-2)番目、(N-3)番目…1番目のトークンを見る必要があります。KVキャッシング、つまりアテンションレイヤーの中間キー/バリューの保存は、後で再利用するためにそれらの結果を保持するために使用され、繰り返し計算を回避します。
メモリ帯域幅が鍵
LLMの計算は主に行列-行列乗算演算によって支配されています。次元が小さいこれらの演算は、ほとんどのハードウェアでメモリ帯域幅に制約されることがよくあります。自己回帰的にトークンを生成する場合、活性化行列の次元の1つ(バッチサイズとシーケンス内のトークン数によって定義される)は、バッチサイズが小さい場合に小さくなります。したがって、速度は、モデルパラメータをGPUメモリからローカルキャッシュ/レジスタにどれだけ速くロードできるかに依存し、ロードされたデータをど�れだけ速く計算できるかではありません。推論ハードウェアで利用可能なおよび達成されたメモリ帯域幅は、ピーク計算パフォーマンスよりもトークン生成速度のより良い予測因子です。
推論ハードウェアの利用率は、サービングコストの観点から非常に重要です。GPUは高価であり、できるだけ多くの作業を行わせる必要があります。共有推論サービスは、多くのユーザーからのワークロードを組み合わせて、個々のギャップを埋め、重複するリクエストをバッチ処理することで、コストを低く抑えることを約束します。Llama2-70Bのような大規模モデルでは、大規模なバッチサイズでのみ良好なコスト/パフォーマンスを達成できます。大規模なバッチサイズで動作できる推論サービングシステムを持つことは、コスト効率にとって不可欠です。しかし、大きなバッチはより大きなKVキャッシュサイズを意味し、それは次にモデルをサービングするために必要なGPUの数を増やします。ここには綱引きがあり、共有サービスオペレーターはコストのトレードオフを行い、システム最適化を実装する必要があります。
モデル帯域幅利用率 (MBU)
LLM推論サーバーはどの程度最適化されているのでしょうか?
前述のように、特にデコード時には、小さいバッチサイズでのLLMの推論は、モデルパラメータをデバイスメモリからコンピューティングユニットにどれだけ速くロードできるかにボトルネックが生じます。メモリ帯域幅は、データ移動がどれだけ速く発生するかを決定します。基盤となるハードウェアの利用率を測定するために、モデル帯域幅利用率(MBU)と呼ばれる新しいメトリクスを導入しま��す。MBUは、(達成されたメモリ帯域幅)/(ピークメモリ帯域幅)と定義され、達成されたメモリ帯域幅は((総モデルパラメータサイズ + KVキャッシュサイズ)/ TPOT)です。
例えば、16ビット精度で実行される7BパラメータモデルのTPOTが14msの場合、14GBのパラメータを14msで移動していることになり、これは帯域幅使用率が1TB/秒であることを意味します。マシンのピーク帯域幅が2TB/秒の場合、MBUは50%で実行されていることになります。簡単のため、この例ではKVキャッシュサイズは考慮していません。KVキャッシュサイズは、バッチサイズが小さく、シーケンス長が短い場合には小さいです。MBU値が100%に近いということは、推論システムが利用可能なメモリ帯域幅を効果的に利用していることを示唆しています。MBUは、異なる推論システム(ハードウェア+ソフトウェア)を正規化された方法で比較するためにも役立ちます。MBUは、計算バウンドな設定で重要な、モデルFLOPs利用率(MFU、PaLM論文で導入)メトリックを補完するものです。
図1は、ルーフラインプロットに似たプロットで、MBUの概念図を示しています。オレンジ色の領域の右肩上がりの実線は、メモリ帯域幅が100%で飽和した場合の最大可能なスループットを示しています。しかし、実際にはバッチサイズが小さい場合(白い点)、観測されるパフォーマンスは最大値よりも低くなります。その低さの度合いがMBUの尺度となります。バッチサイズが大きい場合(黄色��い領域)、システムは計算バウンドであり、達成されたスループットが最大可能スループットの何倍であるかは、モデルFLOPs利用率(MFU)として測定されます。
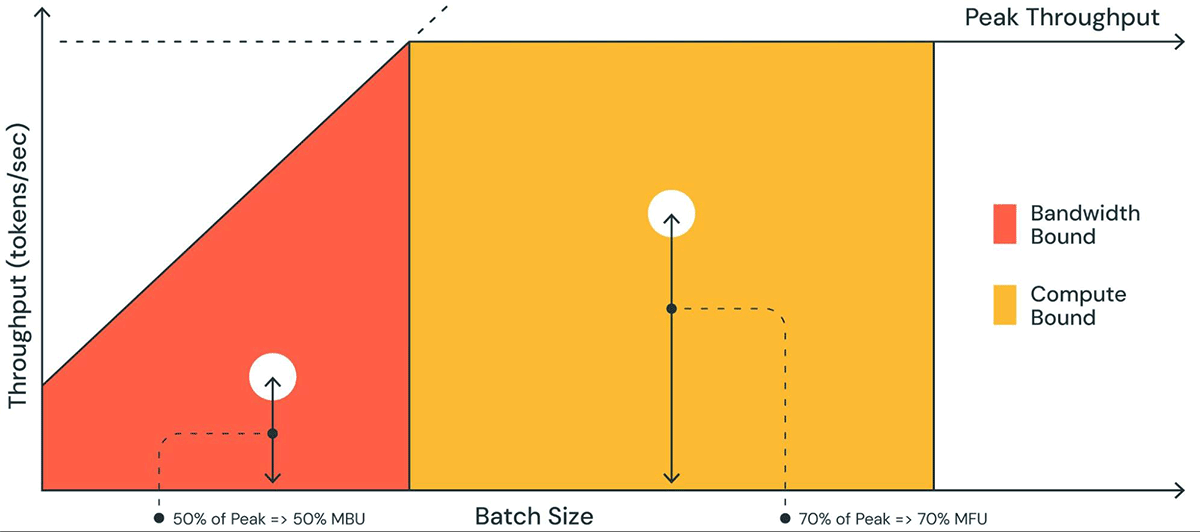
MBUとMFUは、特定のハードウェア設定で推論速度をさらに向上させるために、どれだけの余裕があるかを決定します。図2は、TensorRT-LLMベースの推論サーバーで、さまざまなテンソル並列度における測定されたMBUを示しています。ピークメモリ帯域幅利用率は、大きな連続したメモリチャンクを転送するときに達成されます。MPT-7Bのような小さなモデルを複数のGPUに分散させると、各GPUで移動するメモリチャンクが小さくなるため、MBUが低下することがわかります。
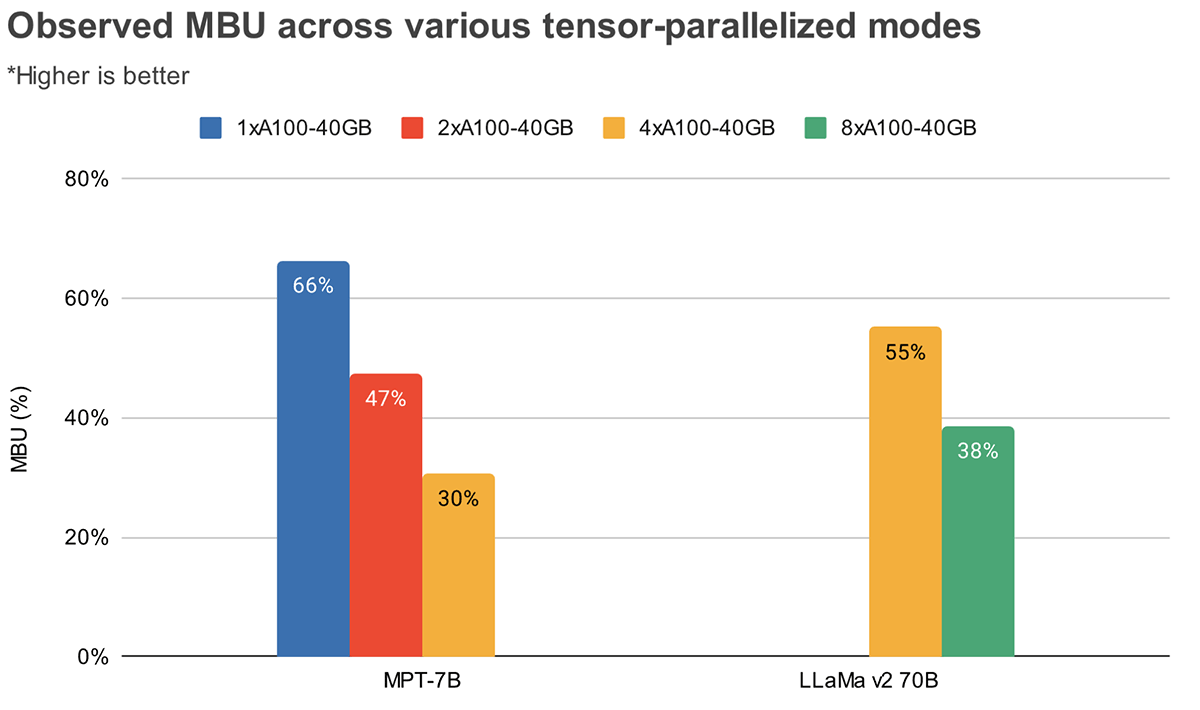
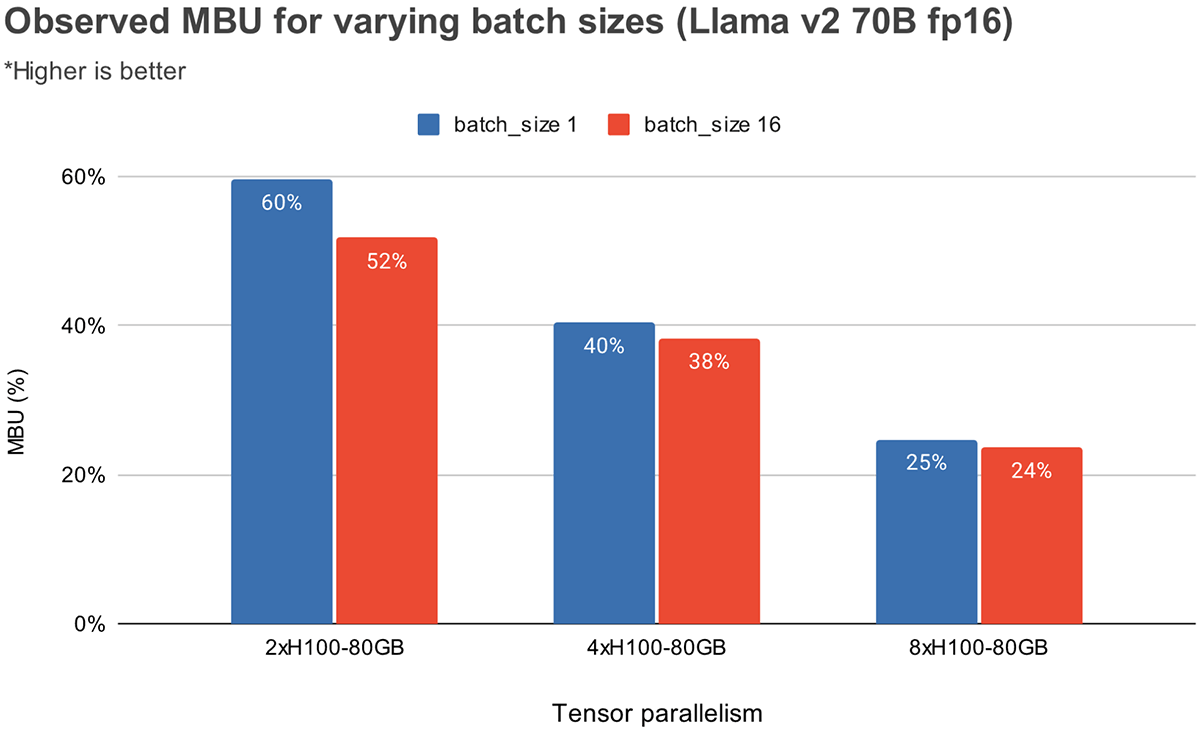
図3は、NVIDIA H100 GPUにおける、さまざまなテンソル並列度とバッチサイズにおける経験的に観測されたMBUを示しています。MBUはバッチサイズが増加すると低下します。しかし、GPUをスケールアップすると、MBUの相対的な低下はそれほど大きくありません。また、メモリ帯域幅が大きいハードウェアを選択することで、より少ないGPUでパフォーマンスを向上させることができる点も注目に値します。バッチサイズ1では、4xA100-40GB GPUでの55%と比較して、2xH100-80GB GPUで60%の高いMBUを達成できます(図2)。
ベンチマーク結果
レイテンシ
MPT-7BおよびLlama2-70Bモデルについて、さまざまなテンソル並列度における初回トークン生成時間(TTFT)と出力トークンあたりの時間(TPOT)を測定しました。入力プロンプトが長くなるにつれて、最初のトークンを生成する時間が全体のレイテンシのかなりの部分を占めるようになります。複数のGPUにまたがるテンソル並列化は、このレイテンシを削減するのに役立ちます。
モデルトレーニングとは異なり、推論レイテンシではGPU数を増やすことによる収穫逓減が大きくなります。例えば、Llama2-70BでGPU数を4倍から8倍に増やしても、小さいバッチサイズではレイテンシは0.7倍しか減少しません。この理由の1つは、並列度が高いほどMBUが低くなること(前述)、もう1つはテンソル並列化がGPUノード間の通信オーバーヘッドを導入することです。
| 初回トークン生成時間(ms) | ||||
|---|---|---|---|---|
| モデル | 1xA100-40GB | 2xA100-40GB | 4xA100-40GB | 8xA100-40GB |
| MPT-7B | 46 (1x) | 34 (0.73x) | 26 (0.56x) | - |
| Llama2-70B | 収まらない | 154 (1x) | 114 (0.74x) | |
表1: 入力リクエストがシーケンス長512トークン、バッチサイズ1の場合の初回トークン生成時間。Llama2 70Bのようなより大きなモデルは、メモリに収めるために少なくとも4xA100-40B GPUが必要です。
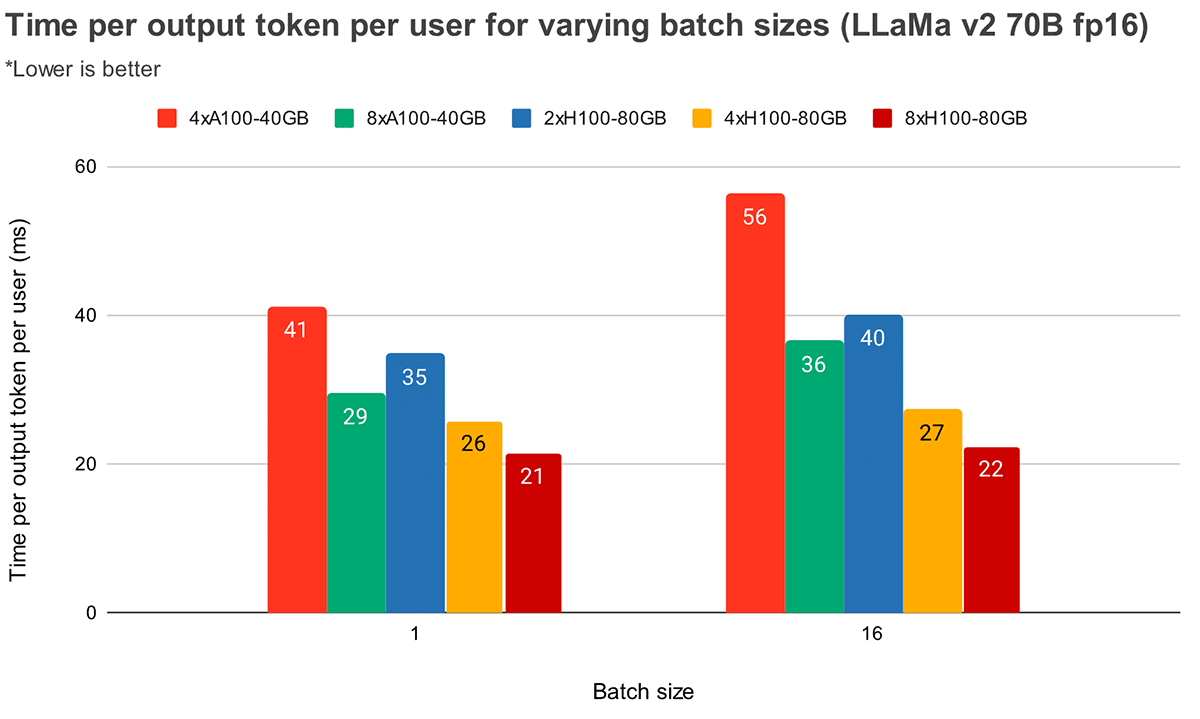
バッチサイズが大きい場合、テンソル並列度が高いほどトークンレイテンシの相対的な低下が大きくなります。図4は、MPT-7Bの出力トークンあたりの時間の変化を示しています。バッチサイズ1では、2倍から4倍にしてもトークンレイテンシは約12%しか減少しません。バッチサイズ16では、4倍でのレイテンシは2倍と比較して33%低くなります。これは、バッチサイズ16の場合、バッチサイズ1と比較して、テンソル並列度が高いほどMBUの相対的な低下が小さいという、以前の観測と一致しています。
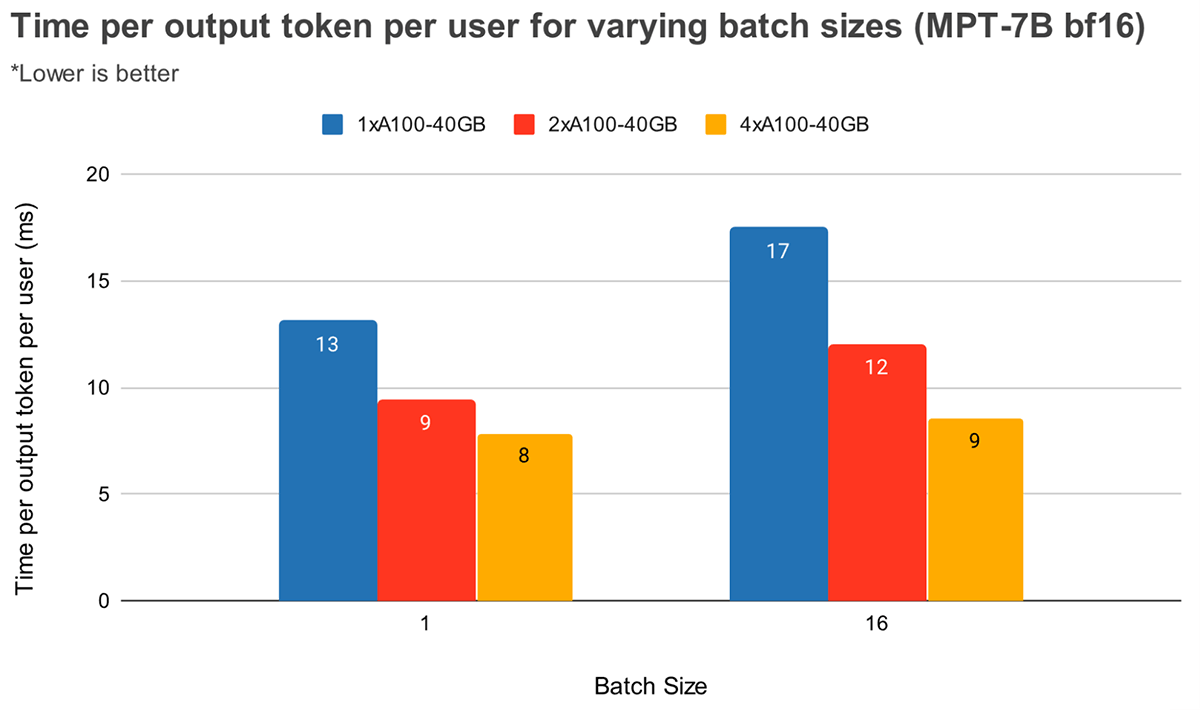
図5は、Llama2-70Bについても同様の結果を示していますが、4倍と8倍の間の相対的な改善はそれほど顕著ではありません。また、2つの異なるハードウェア間でのGPUスケーリングも比較しています。H100-80GBはA100-40GBと比較してGPUメモリ帯域幅が2.15倍であるため、バッチサイズ1ではレイテンシが36%低く、バッチサイズ16では4倍システムで52%低くなることがわかります。
スループット
リクエストをバッチ処理することで、スループットとトークンあたりの時間をトレードオフできます。GPU評価中にクエリをグループ化すると、クエリを逐次処理する場合と比較してスループットが向上しますが、各クエリの完了には時間がかかります(キューイング効果は除く)。
推論リクエストのバッチ処理には、いくつかの一般的な手法があります。
- 静的バッチ処理: クライアントが複数のプロンプトをリクエストにパックし、バッチ内のすべてのシーケンスが完了した後にレスポンスが返されます。当社の推論サーバーはこれをサポートしていますが、必須ではありません。
- 動的バッチ処理: プロンプトはサーバー内でオンザフライでバッチ処理されます。通常、この方法は静的バッチ処理よりもパフォーマンスは劣りますが、レスポンスが短いか均一な長さの場合、最適値に近づけることができます。リクエストに異なるパラメータがある場合はうまく機能しません。
- 連続バッチ処理: リクエストを到着時にまとめてバッチ処理するという考え方は、この優れた論文で紹介されており、現在SOTA(State-of-the-Art)の手法です。バッチ内のすべてのシーケンスが完了するのを待つのではなく、イテレーションレベルでシーケンスをグループ化します。動的バッチ処理よりも10倍から20倍高いスループットを達成できます。
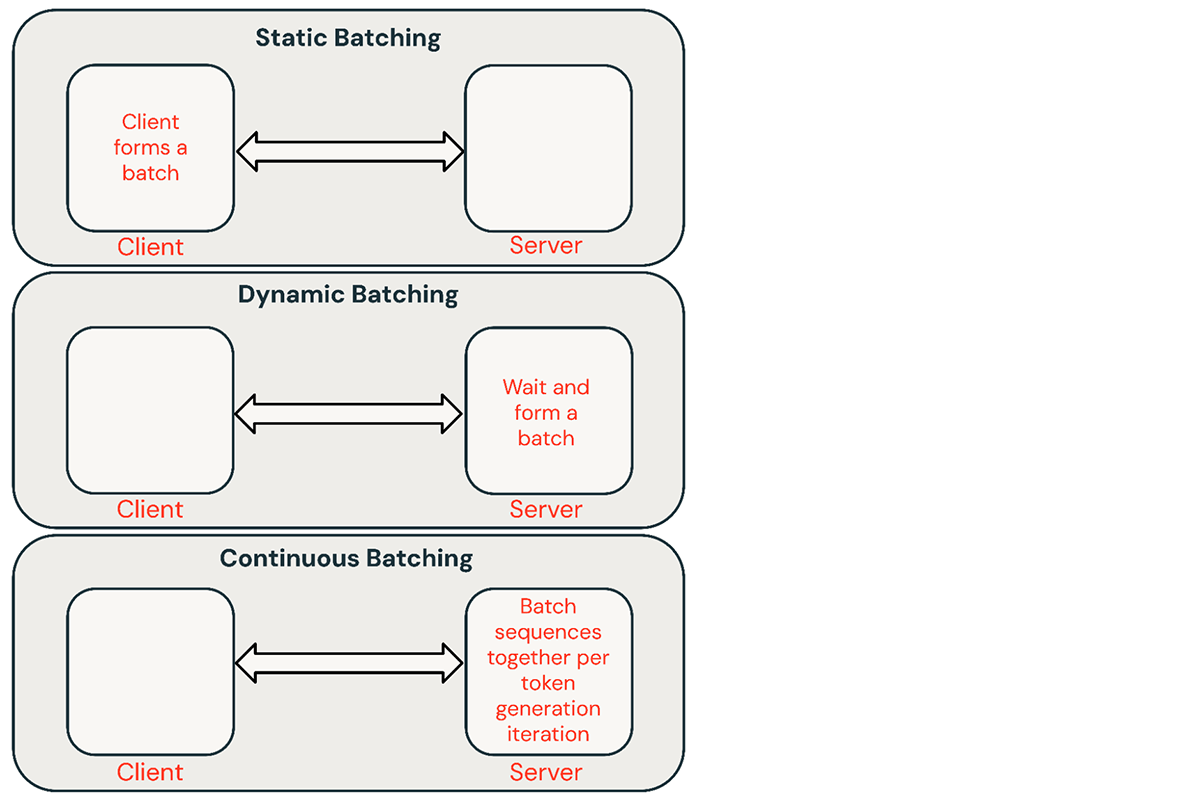
共有サービスには連続バッチ処理が通常最良のアプローチですが、他の2つの方法がより適している状況もあります。QPS(Queries Per Second)が低い環境では、動的バッチ処理が連続バッチ処理よりも優れたパフォーマンスを発揮することがあります。よりシンプルなバッチ処理フレームワークで低レベルのGPU最適化を実装する方が簡単な場合もあります。オフラインのバッチ推論ワークロードでは、静的バッチ処理が大幅なオーバーヘッドを回避し、より高いスループットを達成できます。
バッチサイズ
バッチ処理がどの程度うまく機能するかは、リクエストストリームに大きく依存します。しかし、均一なリクエストで静的バッチ処理をベンチマークすることで、そのパフォーマンスの上限を把握することができます。
| バッチサイズ | |||||||
|---|---|---|---|---|---|---|---|
| ハードウェア | 1 | 4 | 8 | 16 | 32 | 64 | 128 |
| 1 x A10 | 0.4 (1x) | 1.4 (3.5x) | 2.3 (6x) | 3.5 (9x) | OOM (Out of Memory) エラー | ||
| 2 x A10 | 0.8 | 2.5 | 4.0 | 7.0 | 8.0 | ||
| 1 x A100 | 0.9 (1x) | 3.2 (3.5x) | 5.3 (6x) | 8.0 (9x) | 10.5 (12x) | 12.5 (14x) | |
| 2 x A100 | 1.3 | 3.0 | 5.5 | 9.5 | 14.5 | 17.0 | 22.0 |
| 4 x A100 | 1.7 | 6.2 | 11.5 | 18.0 | 25.0 | 33.0 | 36.5 |
表2: FasterTransformersベースのバックエンドを使用した静的バッチ処理によるMPT-7Bのピークスループット(リクエスト/秒)。リクエスト:入力512トークン、出力64トークン。より大きな入力の場合、OOM境界はより小さいバッチサイズで発生します。
レイテンシのトレードオフ
リクエストレイテンシはバッチサイズとともに増加します。たとえば、1つのNVIDIA A100 GPUを使用する場合、バッチサイズ64でスループットを最大化すると、レイテンシは4倍に増加する一方で、スループットは14倍に増加します。共有推論サービスでは、通常、バランスの取れたバッチサイズが選択されます。独自のモデルをホストするユーザーは、アプリケーションに適したレイテンシ/スループットのトレードオフを決定する必要があります。チャットボットのような一部のアプリケーションでは、迅速な応答のための低レイテンシが最優先事項です。非構造化PDFのバッチ処理のような他のアプリケーションでは、個々のドキュメントを処理するレイテンシを犠牲にして、すべてを高速に並列処理したい場合があります。
図7は、7Bモデルのスループットとレイテンシの曲線を示しています。この曲線上の各線は、バッチサイズを1から256に増やすことで得られます。これは、さまざまなレイテンシ制約の下でバッチサイズをどれだけ大きくできるかを判断するのに役立ちます。前述のルーフラインプロットを思い出すと、これらの測定値は期待されるものと一致していることがわかります。特定のバッチサイズを超えると、つまりコンピュートバウンド領域に移行すると、バッチサイズを倍増するたびにスループットは増加せず、レイテンシが増加するだけです。
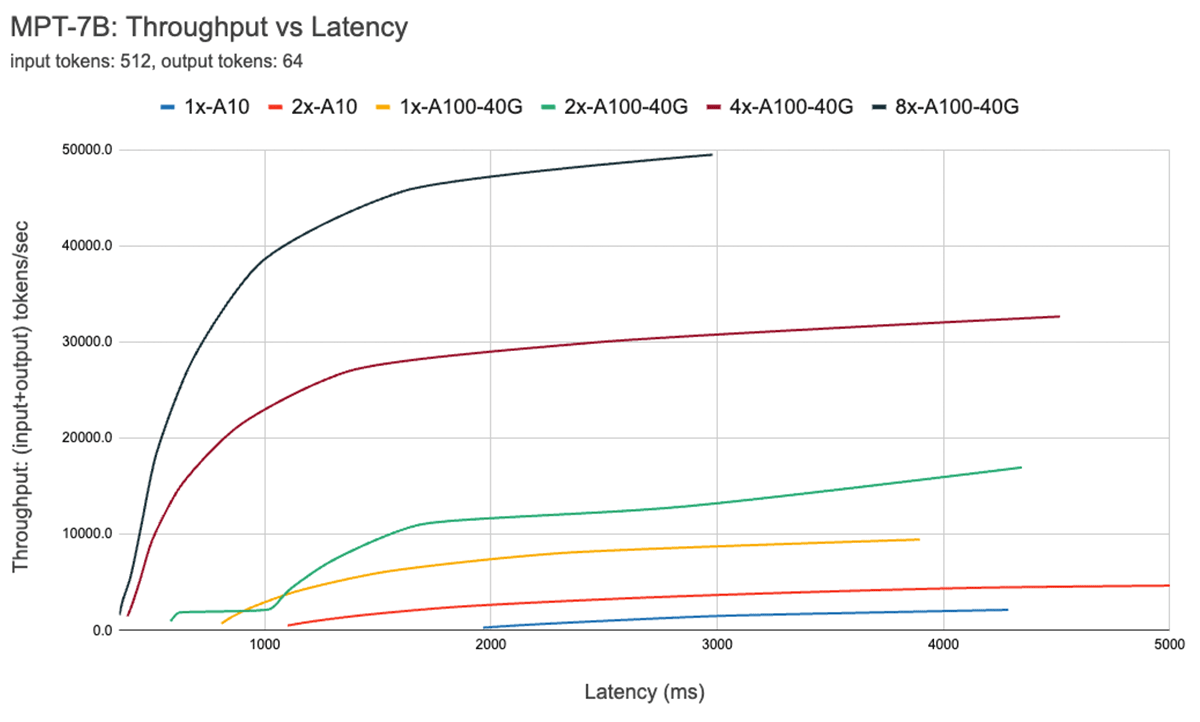
並列処理を使用する場合、低レベルのハードウェアの詳細を理解することが重要です。たとえば、す�べてのクラウドで8xA100インスタンスが同じとは限りません。一部のサーバーはすべてのGPU間に高帯域幅接続を備えていますが、他のサーバーはGPUをペアにし、ペア間の接続帯域幅が低くなっています。これによりボトルネックが発生し、実際のパフォーマンスが上記の曲線から大きく逸脱する可能性があります。
最適化ケーススタディ:量子化
量子化は、LLM推論のハードウェア要件を削減するために使用される一般的な手法です。推論中にモデルの重みとアクティベーションの精度を下げることで、ハードウェア要件を劇的に削減できます。たとえば、16ビット重みから8ビット重みに切り替えると、メモリ制約のある環境(例:A100でのLlama2-70B)で必要なGPUの数が半分になります。4ビット重みにまで下げると、コンシューマーハードウェア(例:MacbookでのLlama2-70B)で推論を実行できるようになります。
私たちの経験では、量子化は注意して実装する必要があります。単純な量子化手法は、モデルの品質を大幅に低下させる可能性があります。量子化の影響は、モデルアーキテクチャ(例:MPT対Llama)やサイズによっても異なります。これについては、今後のブログ記事でさらに詳しく説明します。
量子化のような手法を試す際には、モデル単体の品質だけでなく、推論システムの品質を評価するために、Mosaic Eval GauntletのようなLLM品質ベンチマークを使用することをお勧めします。さらに、より深いシステム最適化を探求することが重要です。特に、量子化はKVキャッシュをより効率的にする��ことができます。
前述のように、自己回帰トークン生成では、アテンションレイヤーからの過去のキー/値(KV)は、各ステップで再計算するのではなくキャッシュされます。KVキャッシュのサイズは、一度に処理されるシーケンスの数とこれらのシーケンスの長さに応じて変化します。さらに、次のトークン生成の各イテレーション中に、新しいKVアイテムが既存のキャッシュに追加され、新しいトークンが生成されるにつれて大きくなります。したがって、これらの新しい値を追加する際の効果的なKVキャッシュメモリ管理は、優れた推論パフォーマンスのために重要です。Llama2モデルは、Grouped Query Attention(GQA)と呼ばれるアテンションのバリアントを使用しています。KVヘッドの数が1の場合、GQAはMulti-Query-Attention(MQA)と同じであることに注意してください。GQAは、キー/値を共有することでKVキャッシュサイズを小さく保つのに役立ちます。KVキャッシュサイズの計算式は次のとおりです。
batch_size * seqlen * (d_model/n_heads) * n_layers * 2 (KとV) * 2 (Float16あたりのバイト数) * n_kv_heads
表3は、シーケンス長1024トークンでのさまざまなバッチサイズで計算されたGQA KVキャッシュサイズを示しています。比較のために、Llama2モデルの70Bモデルのパラメータサイズは140 GB(Float16)です。KVキャッシュの量子化は、(GQA/MQAに加えて)KVキャッシュのサイズを削減するもう1つの手法であり、生成品質への影響を積極的に評価しています。
| バッチサイズ | GQA KVキャッシュメモリ (FP16) | GQA KVキャッシュメモリ (Int8) |
|---|---|---|
| 1 | .312 GiB | .156 GiB |
| 16 | 5 GiB | 2.5 GiB |
| 32 | 10 GiB | 5 GiB |
| 64 | 20 GiB | 10 GiB |
表3: シーケンス長1024でのLlama-2-70BのKVキャッシュサイズ
前述のように、低バッチサイズでのLLMによるトークン生成はGPUメモリ帯域幅バウンドの問題です。つまり、生成速度はモデルパラメータをGPUメモリからオンチップキャッシュにどれだけ速く移動できるかに依存します。モデル重みをFP16(2バイト)からINT8(1バイト)またはINT4(0.5バイト)に変換するには、移動するデータ量が少なくなるため、トークン生成が高速化されます。ただし、量子化はモデル生成品質に悪影響を与える可能性があります。現在、Model Gauntletを使用してモデル品質への影響を評価しており、それに関するフォローアップブログ記事をまもなく公開する予定です。
結論と主な結果
上記で概説した各要因は、モデルの構築とデプロイ方法に影響を与えます。これらの結果を使用して、ハードウェアの種類、ソフトウェアスタック、モデルアーキテクチャ、および一般的な使用パターンを考慮に入れたデータ駆動型の意思決定を行います。経験から得られた推奨事項をいくつか紹介します。
最適化ターゲットを特定する:インタラクティブなパフォーマンスが重要ですか?スループットの最大化ですか?コストの最小化ですか?ここには予測可能なトレードオフがあります。
レイテンシの構成要素に注意を払う:インタラクティブなアプリケーションでは、最初のトークンまでの時間(time-to-first-token)がサービスの応答性を決定し、出力トークンあたりの時間(time-per-output-token)が応答速度を決定します。
メモリ帯域幅が鍵:最初のトークンの生成は通常コンピュートバウンドですが、後続のデコードはメモリバウンドな操作です。LLM推論はメモリバウンドな設定で動作することが多いため、MBU(Memory Bandwidth Utilization)は最適化すべき有用な指標であり、推論システムの効率を比較するために使用できます。
バッチ処理は重要です: 複数のリクエストを同時に処理することは、高いスループットを達成し、高価なGPUを効果的に活用するために不可欠です。共有オンラインサービスでは継続的なバッチ処理が不可欠ですが、オフラインバッチ推論ワークロードでは、よりシンプルなバッチ処理技術で高いスループットを達成できます。
詳細な最適化: LLMにとって、標準的な推論最適化技術(例: オペレーター融合、重み量子化)は重要ですが、特にメモリ使用率を改善するような、より深いシステム最適化を探求することが重要です。その一例がKVキャッシュ量子化です。
ハードウェア構成: デプロイメントハードウェアの決定には、モデルタイプと予想されるワークロードを使用する必要があります。例えば、複数のGPUにスケールする場合、MPT-7Bのような小さいモデルでは、Llama2-70Bのような大きいモデルよりもMBU(Model Batch Utilization)の低下がはるかに速くなります。パフォーマンスも、テンソル並列度が高いほど、サブ線形にスケールする傾向があります。とはいえ、トラフィックが多い場合や、ユーザーが追加の低レイテンシーのために追加料金を支払う意思がある場合は、小さいモデルでも高いテンソル並列度が依然として理にかなっている可能性があります。
データに基づいた意思決定: 理論を理解することは重要ですが、エンドツーエンドのサーバーパフォーマンスを常に測定することをお勧めします。推論デプロイメントが予想よりもパフォーマンスが低い理由はたくさんあります。ソフトウェアの非効率性によりMBUが予想外に低くなる可能性があります。あるいは、クラウドプロバイダー間のハードウェアの違いが予期せぬ結果につながる可能性があります(私たちは2つのクラウドプロバイダーの8xA100サーバー間で2倍のレイテンシー差を観測しました)。
LLM推論を始めるには、Databricks Model Servingをお試しください。詳細については、ドキュメントをご覧ください。
(このブログ記事はAI翻訳ツールを使用して翻訳されています) 原文記事
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。