カオスからスケールへ: DLT-METAによるSpark宣言型パイプラインのテンプレート化
大規模に、一貫性があり、自動化され、統制されたパイプラインを構築するためのメタデータ フレームワーク
によって Ravi Gawai 、 フィービー・ワイザー による投稿
- データパイプラインをスケーリングすると、チーム間でオーバーヘッド、ドリフト、一貫性のないロジックが生じます。
- これらのギャップは、デリバリーを遅らせ、メンテナンスコストを増大させ、共有標準の適用を困難にします。
- このブログでは、メタデータ駆動のメタプログラミングがどのように重複を排除し、大規模で一貫性のある自動データパイプラインを構築するかを紹介します。
宣言的パイプラインを使用すると、チームは意図主導の方法でバッチおよびストリーミングのワークフローを構築できます。実行内容を定義すれば、システムが実行を管理します。これにより、カスタムコードが削減され、再現性のあるエンジニアリングパターンがサポートされます。
組織のデータ活用が拡大するにつれて、パイプラインも増えていきます。標準は進化し、新しいソースが追加され、より多くのチームが開発に参加するようになります。わずかなスキーマの更新でさえ、何十ものノートブックや構成に波及します。メタデータ駆動のメタプログラミングは、パイプラインのロジックを、ランタイム時に生成される構造化されたテンプレートに移行することで、これらの問題に対処します。
このアプローチは、開発の一貫性を保ち、メンテナンスを削減し、限られたエンジニアリングの労力でスケーリングします。
このブログでは、メタデータ テンプレートを適用してパイプライン作成を自動化する Databricks Labs のプロジェクトである DLT-META を使用して、Spark Declarative Pipelines 用のメタデータ駆動型パイプラインを構築する方法を学びます。
宣言的パイプラインは便利ですが、チームがソースを追加して組織全体での利用を拡大すると、そのサポートに必要な作業は急速に増加します。
手動パイプラインを大規模にメンテナンスするのが難しい理由
手動パイプラインは小規模であれば機能しますが、メンテナンスの労力はデ�ータ自体の増加よりも速く増大します。新しいソースが追加されるたびに複雑さが増し、ロジックの乖離や手戻りが発生します。チームはパイプラインを改善するのではなく、結局パッチを当てることになります。データエンジニアは一貫して、次のようなスケーリングの課題に直面しています:
- ソースごとにアーティファクトが多すぎる: 各データセットで、新しいノートブック、構成、スクリプトが必要になります。フィードが追加されるたびに、運用オーバーヘッドは急速に増大します。
- ロジックの更新が伝播しない: ビジネスルールの変更がパイプラインに適用されず、その結果、構成driftが発生し、パイプライン間で出力に不整合が生じます。
- 品質とガバナンスの不整合: チームはカスタムのチェックとリネージを構築するため、組織全体の標準を適用することが困難になり、結果に大きなばらつきが生じます。
- ドメインチームからの安全なコントリビューションが限定的: アナリストやビジネスチームはデータを追加したいと考えていますが、データエンジニアリングが依然としてロジックをレビューまたは書き直すため、デリバリーが遅くなります。
- 変更のたびにメンテナンスが増大: スキーマの単純な調整や更新は、すべての依存パイプラインにわたって大量の手作業のバックログを生み出し、プラットフォームの俊敏性を低下させます。
これらの問題は、メタデータファーストのアプローチが重要である理由を示しています。それにより、手作業が削減され、規模が拡大してもパイプラインの一貫性が保たれます。
DLT-METAによるスケールと一貫性への対応
DLT-METAは、パイプラインのスケールと一貫性の問題を解決します。これは、Spark宣言型パイプライン向けのメタデータ駆動のメタプログラミングフレームワークです。データチームはこれを使用して、パイプラインの作成を自動化し、ロジックを標準化し、最小限のコードで開発をスケールさせます。
メタプログラミングでは、パイプラインの動作は、繰り返し使用されるノートブックからではなく、構成から導出されます。これにより、チームは明確なメリットを得られます。
- 記述および保守するコードの削減
- 新しいデータソースの迅速なオンボーディング
- 本番運用ですぐに使えるパイプラインを最初から構築
- プラットフォーム全体で一貫したパターン
- リーンなチームによるスケーラブルなベストプラクティス
Spark宣言型パイプライン と DLT-META は連携して動作します。Spark宣言型パイプラインはインテントを定義し、実行を管理します。DLT-META は、パイプラインのロジックを生成および拡張する設定レイヤーを追加します。これらを組み合わせることで、手作業のコーディングは、ガバナンス、効率性、大規模な成長をサポートする再現可能なパターンに置き換えられます。
DLT-METAが実際のデータエンジニアリングのニーズにどのように対応するか
1. 集中管理およびテンプレート化された構成
DLT-METAは、共有テンプレートでパイプラインロジックを集中管理し、重複や手動のメンテナンスをなくします。チームは、JSONまたはYAMLを使用して、共有メタデータで取り込み�、変換、品質、ガバナンスのルールを定義します。新しいソースが追加されたりルールが変更されたりした場合、チームは設定を一度更新するだけです。ロジックはパイプライン全体に自動的に伝播します。
2. 瞬時のスケーラビリティと迅速なオンボーディング
メタデータ駆動型の更新により、パイプラインのスケーリングと新しいソースのオンボードが容易になります。チームはメタデータファイルを編集することで、ソースの追加やビジネスルールの調整を行います。変更は、手動の介入なしにすべてのダウンストリームワークロードに適用されます。新しいソースは、数週間ではなく数分で本番運用に移行します。
3. 強制された標準によるドメインチームの貢献
DLT-METAを使用すると、ドメインチームは構成を通じて安全に貢献できます。アナリストとドメインエキスパートはメタデータを更新して、デリバリーを迅速化します。プラットフォームチームとエンジニアリングチームは、検証、データ品質、変換、コンプライアンスルールを管理します。
4. 企業全体での一貫性とガバナンス
組織全体の標準は、すべてのパイプラインとコンシューマーに自動的に適用されます。中央構成により、すべての新しいソースに一貫したロジックが適用されます。組み込みの監査、リネージ、データ品質ルールは、大規模な規制要件と運用要件をサポートします。
チームがDLT-METAを実際にどのように使用するか
顧客はDLT-METAを使用して、取り込みと変換を一度定義し、設定を通じてそれらを適用しています。これにより、カスタムコードが削減さ�れ、オンボーディングが迅速化されます。
Cineplex はすぐに効果を実感しました。
DLT-METAを使用して、カスタムコードを最小限に抑えます。エンジニアは、単純なタスクのためにパイプラインを異なる方法で記述する必要がなくなりました。オンボーディング用のJSONファイルが一貫したフレームワークを適用し、残りの処理を担います。—Aditya Singh、データエンジニア、Cineplex
PsiQuantum は、小規模なチームが効率的にスケールする方法を示しています。
DLT-METAは、ブロンズとシルバーのワークロードを少ないメンテナンスで管理するのに役立ちます。ノートブックやソースコードを複製することなく、大容量のデータに対応します。—Arthur Valadares、PsiQuantum社プリンシパルデータエンジニア
業界を問わず、チームは同じパターンを適用しています。
- 小売: 何百ものソースから店舗データとサプライチェーンデータを一元化します
- ロジスティクスは、IoTおよびフリートデータ向けのバッチおよびストリーミングの取り込みを標準化します
- 金融サービスは、フィードのオンボーディングを迅速化しつつ、監査とコンプライアンスを徹底します
- 医療: 複雑なデータセット全体で��品質と監査可能性を維持します
- 製造および通信: 再利用可能で一元管理されたメタデータを使用してインジェストをスケーリングします
このアプローチにより、チームは複雑さを増すことなくパイプライン数を増やすことができます。
5 つの簡単なステップで DLT-META を始める方法
DLT-META を試すためにプラットフォームを再設計する必要はありません。小さく始めましょう。少数のソースを使用します。残りはメタデータに任せましょう。
1. フレームワークを取得する
DLT-META リポジトリをクローンすることから始めましょう。これにより、メタデータを使用してパイプラインを定義するために必要なテンプレート、サンプル、ツールが提供されます。
2. メタデータでパイプラインを定義する
次に、パイプラインが何をすべきかを定義します。これを行うには、少数の設定ファイルを編集します。
- 生の入力テーブルを記述するには、conf/onboarding.json を使用します。
- conf/silver_transformations.json を使用して変換を定義します。
- 任意で、データ品質ルールを適用する場合はconf/dq_rules.jsonを追加してください。
この時点では、意図を記述していることになります。パイプラインコードを記述しているのではありません。
3. プラットフォームにメタデータをオンボードする
パイプラインを実行する前に、DLT-METAはメタデータを登録する必要があります。このオンボーディングステップでは、構成がDataflowspec deltaテーブルに変換され、パイプラインがランタイムでそれを読み取ります。
オンボーディングは、ノートブック、Lakeflowジョブ、またはDLT-META CLIから実行できます。
a. ノートブックによる手動オンボーディング(例: こちら)
提供されているオンボーディングノートブックを使用して、メタデータを処理し、パイプラインアーティファクトをプロビジョニングします。
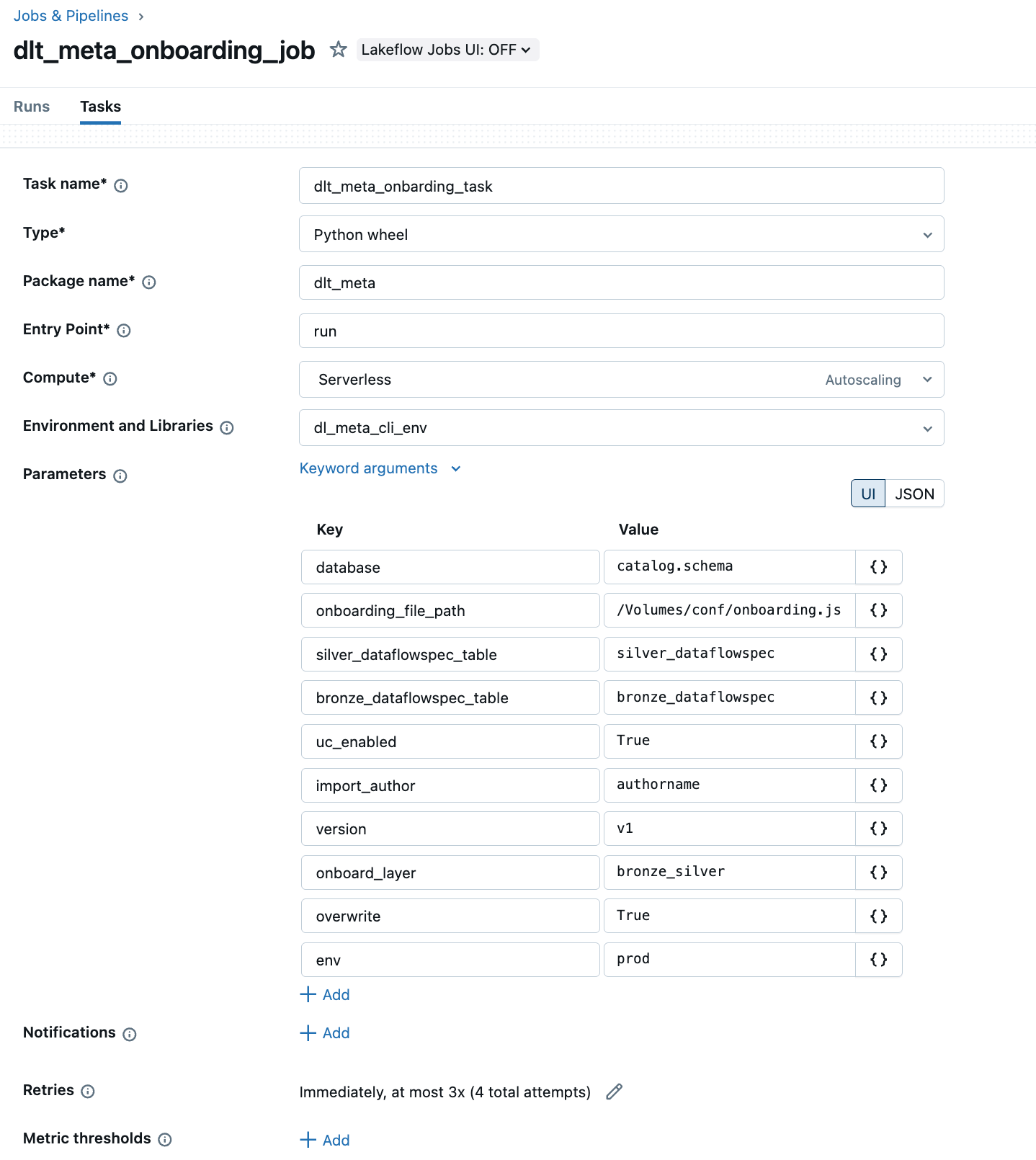
b. Python wheel を使用して、Lakeflow Jobs 経由でオンボーディングを自動化します。
以下の例では、Lakeflow Jobs UIを使用してDLT-METAパイプラインを作成し、自動化する方法を示します。
c. リポジトリに示されている DLT-META CLI コマンドを使用してオンボードします: こちら。
DLT-META CLIを使用すると、対話型Pythonターミナルでオンボードとデプロイをランできます。
4. 汎用パイプラインを作成する
メタデータを配置すると、単一の汎用パイプラインが作成されます。このパイプラインは、Dataflowspec テーブルから読み取り、ロジックを動的に生成します。
pipelines/dlt_meta_pipeline.pyをエントリポイントとして使用し、ブロンズ仕様とシルバー仕様を参照するように設定します。
ソースを追加しても、このパイプラインは変更されません。メタデータが動作を制御します。

5. トリガーしてラン
これでパイプラインを実行する準備ができました。他のSpark宣言型パイプラインと同様にトリガーします。
DLT-METAは、ランタイム時にパイプラインロジックを構築して実行します。
出力は、一貫した変換、品質ルール、およびリネージが自動的に適用された、本番運用対応の bronze テーブルと silver テーブルです。
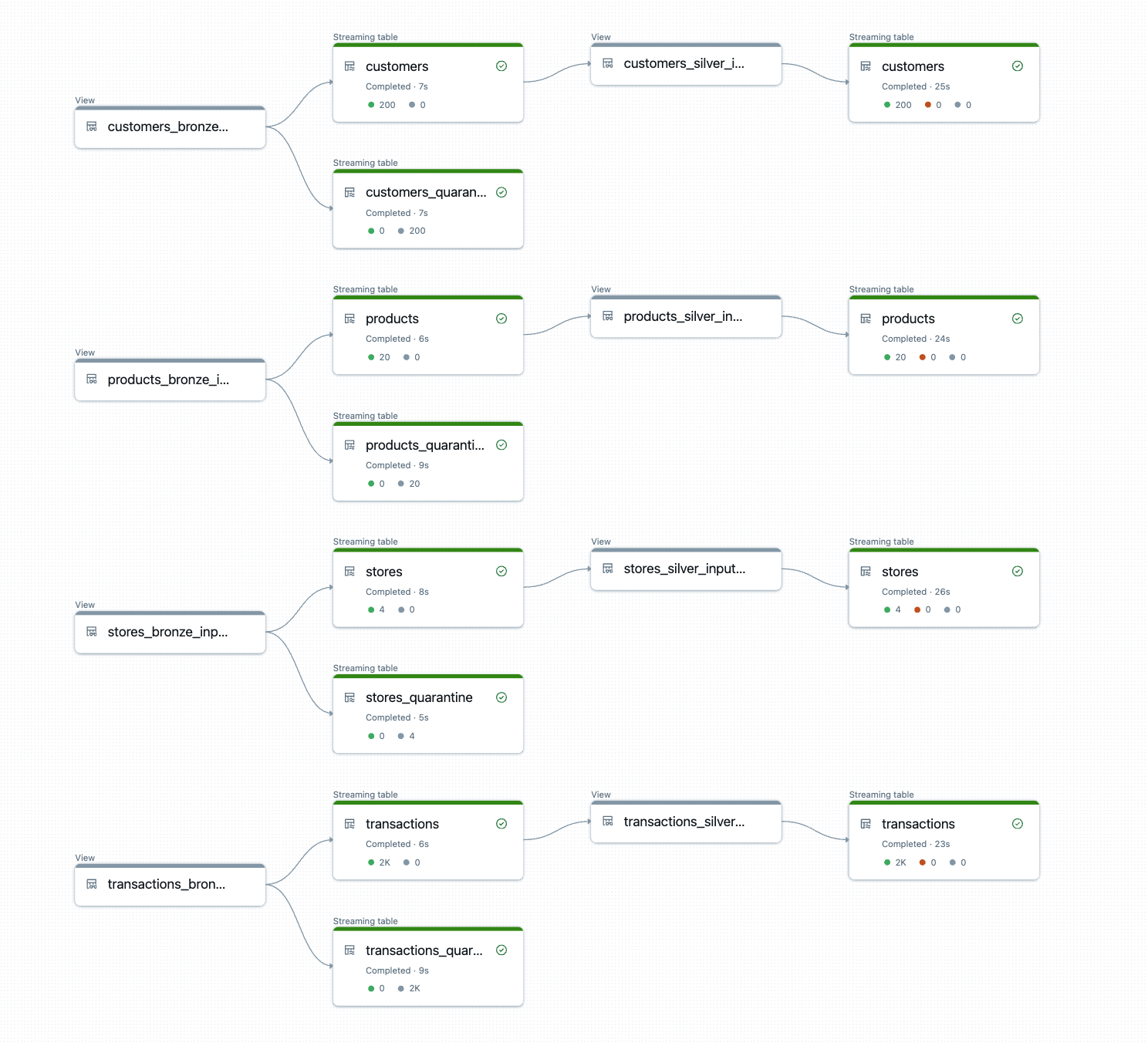
{kind=link}
今すぐお試しください
開始にあたっては、まず既存のSpark宣言型パイプラインといくつかのソースを使用して概念実証 (PoC) を開始し、パイプラインロジックをメタデータに移行して、DLT-METAに大規模なオーケストレーションを任せることをお勧めします。まずは小規模な概念実証 (PoC) から始め、メタデータ駆動のメタプログラミングによって、データエンジニアリング能力が想像をはるかに超えてスケールする様子をご覧ください。
Databricks リソース
- はじめに: https://github.com/databrickslabs/DLT-META#getting-started
- GitHub: github.com/databrickslabs/DLT-META
- GitHub ドキュメント: databrickslabs.github.io/DLT-META
- Databricks ドキュメント: https://docs.databricks.com/aws/en/dlt-ref/DLT-META
- デモ: databrickslabs.github.io/DLT-META/demo
- 最新リリース: https://github.com/databrickslabs/DLT-META/releases
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。