ファインチューニングされたラマモデルに対するバッチ推論とDatabricksモデル提供
によって Colton Peltier 、 モハマド・アブーフール による投稿
- プロビジョニングされたスループットを使用してLlama 3.1および3.2バリアントを提供する方法を学びます
- ai_queryを使用してLLMエンドポイントでバッチ推論を実行する方法を学びます
- mlflow.evaluateを使用してLLMが生成した結果を評価する方法を学びます
序章
本番環境向け、スケーラブルでフォールトトレラントな生成型AIソリューションを構築するには、信頼性の高いLLMの利用可能性が必要です。あなたのLLMエンドポイントは、専用の計算をあなたのワークロードのために持つことで需要を満たす準備ができている必要があります。必要に応じて容量をスケーリングし、一貫したレイテンシを持ち、すべてのインタラクションをログに記録する能力、そして予測可能な価格設定を持つことが求められます。このニーズを満たすために、Databricksはプロビジョニングされたスループットエンドポイントを、各種の高性能基盤モデル(全ての主要なラマモデル、DBRX、ミストラルなど)で提供しています。しかし、最新で最も性能の高い微調整されたLlama 3.1と3.2のバリアントを提供することはどうでしょうか?NVIDIAのNemotron 70Bモデルは、Llama 3.1の微調整されたバリアントで、多様なベンチマークで競争力のあるパフォーマンスを示しています。Databricksの最近の革新により、顧客はプロビジョニングされたスループットを使用して、Llama 3.1およびLlama 3.2の多くの微調整されたバリアントを簡単にホストできるようになりました。
次のシナリオを考えてみましょう:ニュースウェブサイトが、ニュース記事の要約を生成するためにNemotronを使用して、社内で強力な結果を達成しました。彼らは、毎日の始まりにすべての新しい記事を取り込み、要約を生成する本番グレードのバッチ推論パイプラインを実装したいと考えています。ここでは、Databricks上でNemotron-70Bのためのプロビジョニングスループットエンドポイントを作成し、データセットに対してバッチ推論を実行し、MLflowを使用して結果を評価し、高品質の結果のみが公開されるようにする簡単なプロセスを説明します。
エンドポイントの準備
モデルのプロビジョニングスループットエンドポイントを作成するには、まずモデルをDatabricksに取り込む必要があります。モデルをDatabricksのMLflowに登録するのは簡単ですが、Nemotron-70Bのようなモデルをダウンロードすると大量のスペースが必要になるかもしれません。このような場合、ディスクスペースが必要になると自動的にサイズが拡大するDatabricks Volumesを使用するのが理想的です。
モデルがダウンロードされた後、それを簡単にMLflowに登録することができます。
タスクパラメータは、プロビジョニングスループットにとって重要であり、�これによりエンドポイントで利用可能なAPIが決まります。プロビジョニングされたスループットは、チャット、補完、または埋め込みタイプのエンドポイントをサポートできます。registered_model_name引数は、MLflowに新しいモデルを登録し、そのモデルのバージョンを追跡するよう指示します。プロビジョニングスループットエンドポイントを設定するためには、登録名を持つモデルが必要です。
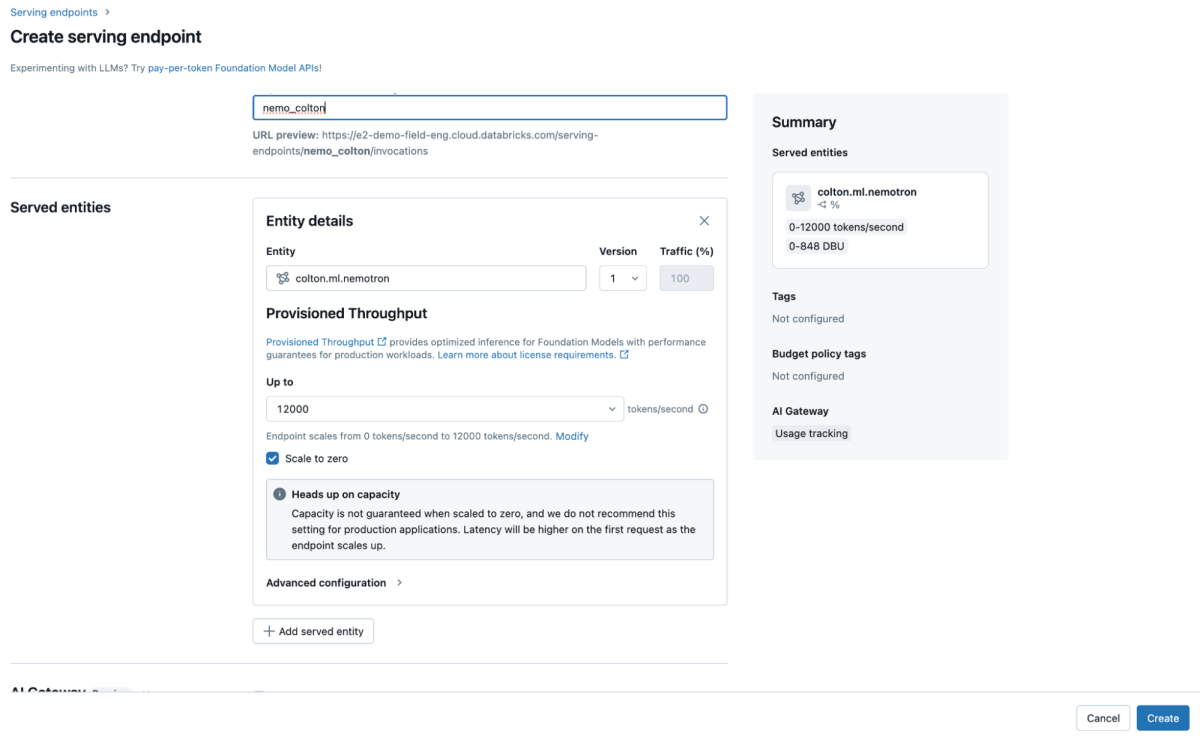
モデルがMLflowに登録完了したら、エンドポイントを作成できます。エンドポイントはUIまたはREST APIを通じて作成できます。UIを使用して新しいエンドポイントを作成するには:
ワークスペース内のServing UIに移動します。
サービングエンドポイントの作成を選択します。
- エンティティフィールドで、Unityカタログからモデルを選択してください。モデル名
“ml.your_name.nemotron”を入力します。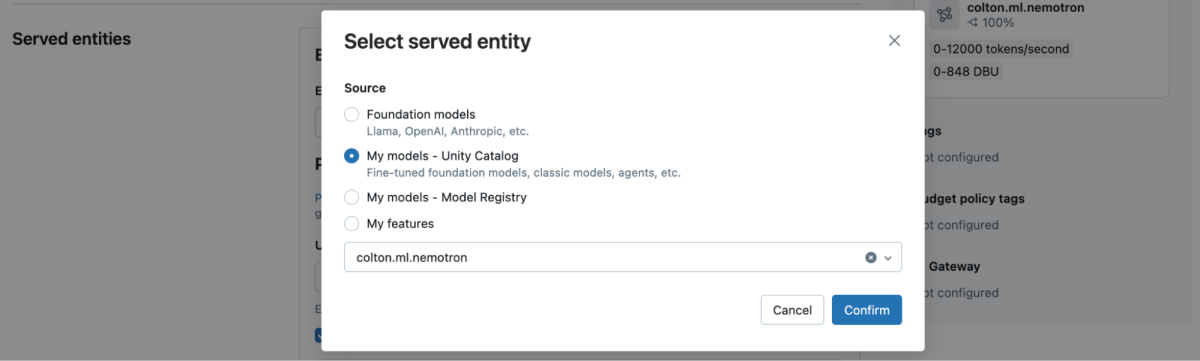
- その後、希望するスループット帯を選択できます。今のところ、これをデフォルトのままにしておきます。
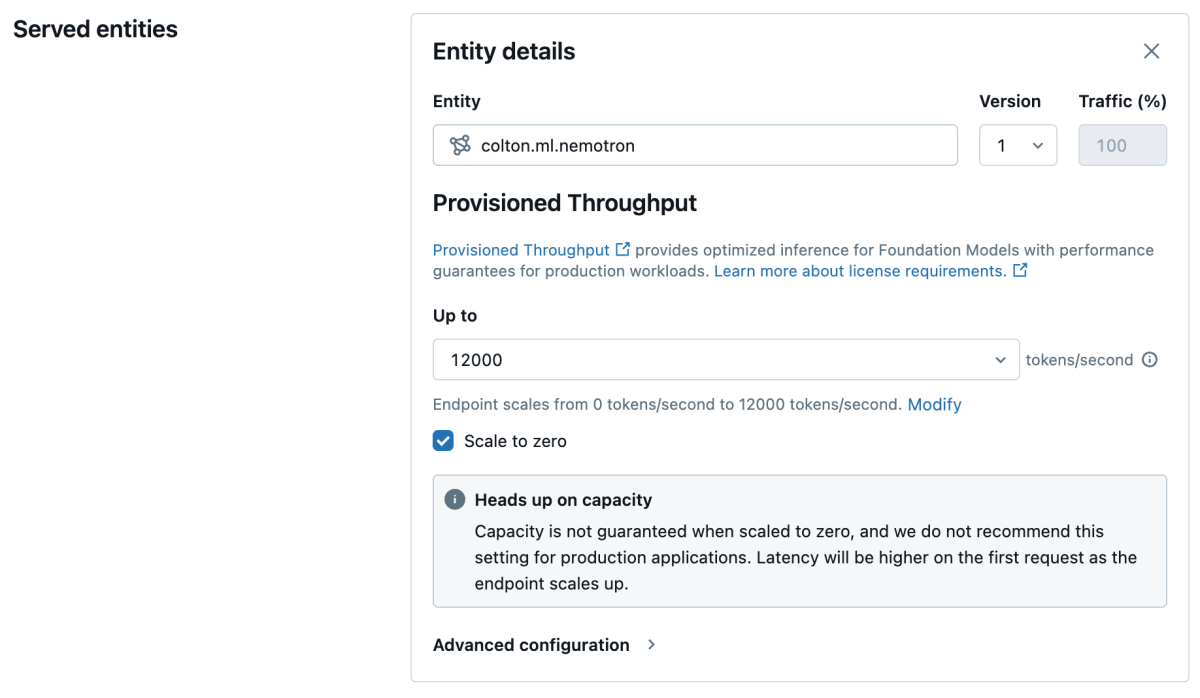
- モデルに名前(例えば「nemo_your_name」)を付け、エンドポイントを保存してください。
バッチ推論(ai_queryを使用)
これでモデルが提供され、使用準備が整いましたので、毎日のニュース記事のバッチを作成したプロンプトを使用してエンドポイントを通じて要約を取得する必要があります。バッチ推論のワークロードを最適化することは複雑な場合があります。典型的なペイロードに基づいて、新しいnemotronエンドポイントに最適な並行性は何ですか?pandas_udfを使用するか、カスタムのスレッドコードを書くべきですか?Databricksの新しいai_query機能により、複雑さから抽象化し、結果だけに焦点を当てることができます。ai_query機能は、個々またはバッチの推論をプロビジョニングされたスループットエンドポイントでシンプルで最適化されたスケーラブルな方法で処理できます。
ai_queryを使用するには、SQLクエリを作成し、最初のパラメータとしてプロビジョニングされたスループットエンドポイントの名前を含めます。プロンプトを追加し、それを適用したい列を2番目のパラメータとして連結します。||またはconcat()を使用して単純な連結を行うことができます。または、format_string()を使用して、複数の列と値でより複雑な連結を行うことができます。
ai_queryの呼び出しはPyspark SQLを通じて行われ、SQLまたはPyspark pythonコードで直接行うことができます。
同じ呼び出しはPySparkコードでも行うことができます:
それほど簡単です! 複雑なユーザー定義関数を作成したり、厄介なSpark操作を扱う必要はありません。 データがテーブルまたはビューにある限り、これを簡単に実行できます。そして、これはプロビジョニングされたスループットエンドポイントを利用しているため��、自動的に分散して並行に推論を実行し、エンドポイントの指定された容量まで処理します。これは一連の逐次的なリクエストよりもはるかに効率的です!
ai_queryは、戻り値の指定、エラーステータスの記録、および一般的なLLMリクエストで使用する追加のLLMパラメータ(max_tokens、temperatureなど)を含む追加の引数も提供します。同じクエリ内で、Unity Catalogのテーブルにレスポンスを簡単に保存することも可能です。
MLflowを使用した要約出力の評価を行います。
今、ニュース記事の要約を生成しましたが、ウェブサイトに公開する前にその品質を自動的にレビューしたいと考えています。LLMのパフォーマンス評価は、mlflow.evaluate()を通じて簡素化されています。この機能は、評価を行うモデル、評価のためのメトリクス、およびオプションで比較のための評価データセットを活用します。デフォルトのメトリクス(質問応答、テキストの要約、テキストメトリクス)を提供するとともに、独自のカスタムメトリクスを作成する能力も提供します。今回のケースでは、生成された要約の品質をLLMで評価したいので、カスタムメトリクスを定義します。次に、私たちは要約を評価し、低品質の要約を手動レビューのためにフィルタリングします。
例を見てみましょう:
MLflowを通じてカスタムメトリックを定義します。
上記で定義したカスタムメトリクスを使用して、MLflow Evaluateを実行します。
評価結果を確認しましょう!
mlflow.evaluate()からの結果は自動的に実験の実行に記録され、後で簡単にクエリを行うためにUnity Catalogのテーブルに書き込むことができます。
まとめ
このブログ記事では、ニュース組織が人気のある新しい微調整されたLlamaベースのLLMをプロビジョニングスループットで設定し、ai_queryを使用してバッチ推論により要約を生成し、mlflow.evaluateを使用してカスタムメトリックで結果を評価するという仮想的な使用例を示しました。 これらの機能により、使用するモデルの選択、専用モデルホスティングの生産信頼性、および特定のタスクに最適なサイズのモデルを選択し、使用した計算のみを支払うことによるコスト削減をバランスさせる産業級の生成AIシステムを実現できます。これらの機能はすべて、Databricks環境内の通常のPythonまたはSQLワークフローで直接利用でき、Unity Catalogでデータとモデルのガバナンスが可能です。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。