Deep Dive:行レベル並列処理の動作原理について!
自動的な同時競合解決のためにLiquid Clusteringを使用
によって シンディ・ジャン, Christos Stavrakakis 、 モスタファ・モクタル による投稿
- Databricksの行レベル同時実行機能は、同時書き込みやメンテナンス操作が発生する環境でも、標準で同時実行性の保証を提供します。
- 従来の同時実行処理(リトライループやパーティショニングなど)は扱いが難しく、クエリ時間やコストの増加を招く可能性があります。
- Liquid Clusteringを使うことで、今日から行レベルの同時実行性のメリットを享受できます。
Liquid Clusteringは、データレイアウトに関する決定を大幅に簡素化する革新的なデータ管理技術です。あなたがするべきことは、クエリアクセスパターンに基づいてクラスタリングキーを選択するだけです。数千の顧客がLiquid Clusteringによる優れたクエリパフォーマンスを享受し、現在では月間3000人以上のアクティブな顧客が毎月200+ PBのデータをLiquid Clustringされたテーブルに書き込んでいます。
複数のライターを管理するためにパーティショニングをまだ使用している場合、Liquid Clusteringの重要な機能である行レベルの並行性を見逃しています。
このブログ投稿では、Databricksが同時変更を行うテーブルに対して即座に並行性を保証する方法を説明します。行レベルの並行性により、複雑なデータレイアウトの設計やワークロードの調整をする必要がなくなるため、ビジネスの洞察を抽出することに集中できます。これにより、コードとデータパイプラインが簡素化されます。
行レベルの並行性��は、Liquid Clusteringを使用すると自動的に有効になります。また、Databricks Runtime 14.2+を使用する際には削除ベクトルも有効化されます。もし頻繁にConcurrentAppendExceptionまたはConcurrentUpdateExceptionで失敗する同時変更がある場合、今日からテーブルにLiquid Clusteringまたは削除ベクトルを有効化して、行レベルの競合検出を行い、競合を減らしましょう。使い始めるのは簡単です:
行レベルの並行性が同じファイルを変更する並行書き込みをどのように自動的に処理するかについて、詳しく説明します。
伝統的なアプローチ:管理が難しく、エラーが発生しやすい
並行書き込みは、複数のプロセス、ジョブ、またはユーザーが同時に同じテーブルに書き込むときに発生します。これらは、複数のストリームからの連続書き込み、異なるパイプラインがテーブルにデータを取り込む、またはGDPR削除のようなバックグラウンド操作などのシナリオで一般的です。並行書き込みの管理は、メンテナンスタスクを管理する場合にさらに煩雑になります - ビジネスワークロードを考慮に入れてOPTIMIZEをスケジュールする必要があります。
Delta Lakeは、これらの操作中のデータの整合性を保証するために楽観的な同時実行制御を使用し、書き込み間でトランザクション保証を提供します。これは、2つの書き込みが競合する場合、一方が成功し、他方がコミットに失敗することを意味します。
この例を考えてみましょう:2つの異なるソースからの2人のライター、例えば、米国と英国の売上が、同時にグローバルな売上数テーブルにマージしようと試みます。これは、dateによってパーティション化されています - 大量のデータセットを管理する顧客から見られる一般的なパーティション化パターンです。米国からの売上がstreamAでテーブルに書き込まれ、一方、英国からの売上がstreamBで書き込まれると仮定します。
ここでは、streamAが最初にコミットをステージングし、streamBが同じパーティションを変更しようとすると、Delta LakeはstreamBのコミット時の書き込みを並行変更例外として拒否します、たとえ2つのストリームが実際には異なる行を変更していても。これは、パーティション化されたテーブルでは、競合はパーティションの粒度で検出されるためです。結果として、streamBからの書き込みは失われ、大量の計算が無駄になります。
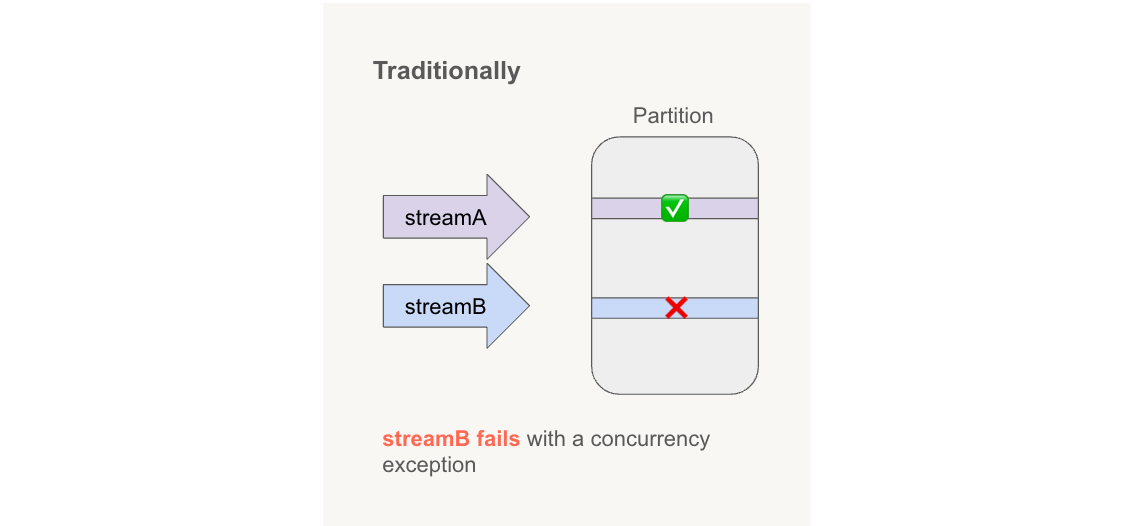
これらの競合を処理するために、顧客はリトライループを使用して作業負荷を再設計できます。これは、streamBの書き込みを再試行します。しかし、リトライロジックは、コミットが成功するまで同じ書き込みを繰り返し試行することで、ジョブの応答時間と計算コストが増加する可能性があります。適切なバランスを見つけるのは難しいです—再試行が少なすぎると失敗のリスクがあり、多すぎると非効率的でコストが高くなります。
別のアプローチはより細かいパーティショニングですが、複数のチームが同じテーブルに書き込むときに、より細かいテーブルパーティションを分離して書き込みを管理するのも難しいです。適切なパーティションキーを選択するのは難しく、すべてのデータパターンにパーティションが適用できるわけではありません。さらに、パーティショニングは柔軟性に欠けます - 進化するワークロードに適応するためにパーティショニングキーを変更するときには、テーブル全体を書き換える必要があります。
この例では、顧客はテーブルを書き換えてdateとcountryの両方でパーティションを作成することで、各ストリームが別のパーティションに書き込むことができますが、これは小さなファイルの問題を引き起こす可能性があ��ります。これは、一部の国が大量の売上データを生成し、他の国が非常に少ないデータを生成するという、非常に一般的なデータパターンの場合に発生します。
Liquid Clusteringはこれらの小さなファイルの問題をすべて回避し、行レベルの並行性は行レベルでの並行性を保証します。これは、パーティショニングよりもさらに詳細で柔軟です。行レベルの並行性がどのように機能するかを詳しく見てみましょう!
行レベルの並行性がどのように手間をかけずに自動的に並行競合を解決するか
行レベルの並行性は、Databricks Runtimeでの革新的な行レベルでの書き込み競合を検出する技術です。Liquid Clustring されたテーブルの場合、この機能はMERGE、UPDATE、DELETEなどの変更操作間の競合を自動的に解決します。ただし、これらの操作が同じ行を読み取ったり変更したりしない限りです。
さらに、削除ベクトルが有効になっているすべてのテーブル – Liquid Clustering されたテーブルを含む – では、OPTIMIZEやREORGのようなメンテナンス操作が他の書き込み操作と干渉しないことを保証します。これにより、並行書き込みワークロードの設計について心配する必要がなくなり、Databricks上でのワークロードがさらに簡単になります。
例を使って説明すると、行レベルの並行性を使用すると、両方のストリームが同じ行を変更していない限り – たとえその行が同じファイルに格納されていても – 売上データへの変更を成功裏にコミットできます。
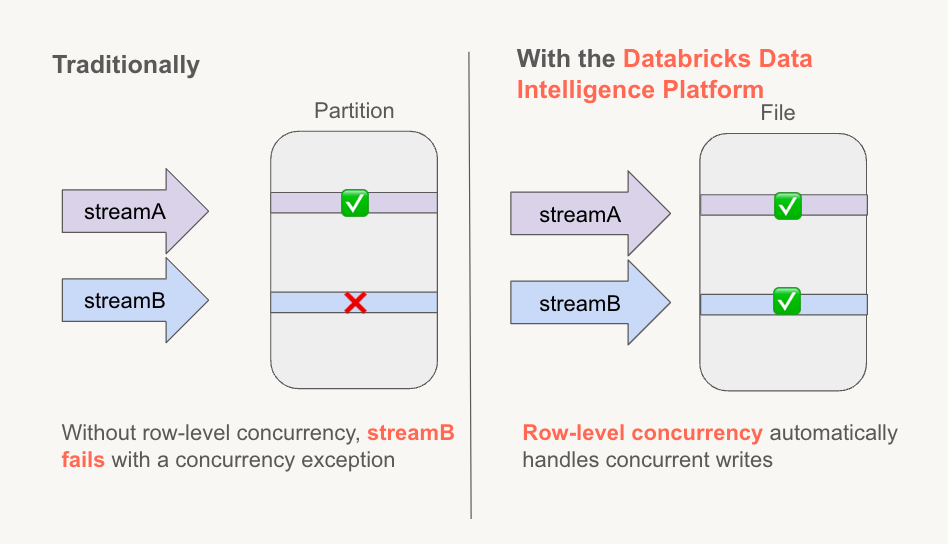
行レベルの並行性の舞台裏:その仕組み
これはどのように機能するのでしょうか?Databricks Runtimeは、コミット時に並行変更を自動的に調整します。それは、Delta Lakeの機能である削除ベクトル(DV)と行追跡を使用して、各トランザクションで行われた変更を追跡し、効率的に修正を調整します。
例を使用すると、新しい売上データがテーブルに書き込まれると、新しいデータは新しいデータファイルに挿入され、古い行は元のファイルを書き換えることなく削除ベクトルを使用して削除とマークされます。ファイルレベルにズームインして、行レベルの並行性が削除ベクトルとどのように機能するかを見てみましょう。
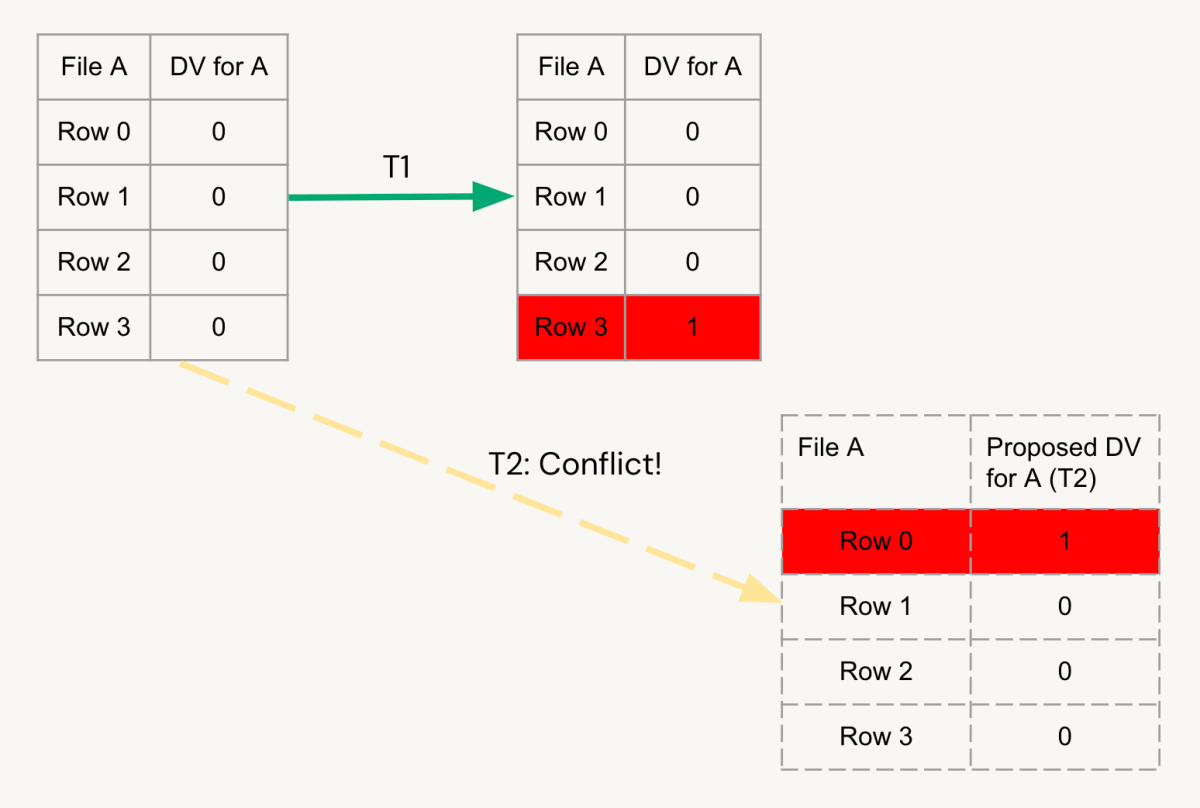
例えば、4つの行を持つfile Aがあり、row 0からrow 3までがあります。Transaction 1 (T1) がstreamAからrow 3をファイルAで削除しようと試みます。Databricks Runtimeは、file Aを書き換える代わりに、ファイルAの削除ベクトルでrow 3を削除とマークします。これは、AのDVと表記されます。

今、トランザクション2(T2)がstreamBから入ってきます。このトランザクションがrow 0を削除しようとするとしましょう。削除ベクトルを使用すると、File Aは変更されません。代わりに、DV for Aは現在、row 0が削除されたことを追跡しています。ロウレベルの並行性がなければ、これはトランザクション1と競合を引き起こす可能性があります。なぜなら、両方が同じファイルや削除ベクトルを変更しようとしているからです。
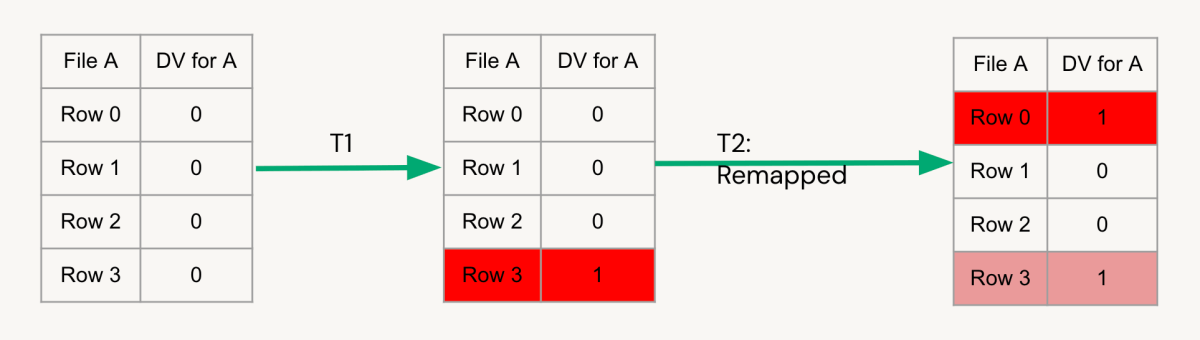
行レベルの同時性を使用すると、Databricks Runtimeの競合検出は、2つのトランザクションが異なる行に影響を与えることを識別します。論理的な競合がないため、Databricks Runtimeは、両方のトランザクションからの削除ベクトルを組み合わせることで、同じファイル内�の同時変更を調整することができます。
これらすべての革新により、DatabricksはオープンなDelta Lakeフォーマットで行レベルの並行性を提供する唯一のレイクハウスエンジンを持っています。他のエンジンは、キューイングや遅い書き込み操作を引き起こす可能性がある独自のフォーマットでロックを採用しています。また、並行書き込みのために煩雑なパーティションベースの並行性方法に頼らなければなりません。
過去1年間で、行レベルの並行性は6,500以上の顧客が110B以上の競合を自動的に解決するのに役立ち、書き込み競合を90%以上減らしました(残りの競合は同じ行を触ることによって引き起こされます)。
無料トライアル
行レベルの並行性は、Databricks Runtime 13.3+でLiquid Clusteringを使用すると自動的に有効になります!Databricks Runtime 14.2+では、削除ベクトルが有効になっているすべての非パーティション化テーブルでもデフォルトで有効になっています。
すでにLiquid Clusteringを使用しているワークロードがある場合、準備は完了し�ています!そうでない場合は、Liquid Clusteringを採用するか、パーティション化されていないテーブルに削除ベクトルを有効にして、行レベルの並行性の利点を引き出します。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。