エンタープライズ規模のガバナンス: Hive Metastore から Unity Catalog への移行
HiveメタストアからUnity Catalogへ、データガバナンスとパフォーマンスの最適化を活用し、大規模で複雑なワークロードを中断することなく移行する方法について学びます。
によって ジョシュ・ベイ 、 ダヴァル・バガディア による投稿
- 組織はアジリティとデータ駆動型の意思決定によって成長しますが、レガシーな Hive メタストアは、アジリティとコンプライアンスを妨げるガバナンスのギャップ、サイロ化されたアクセス、運用上のボトルネックを生み出します。
- Unity Catalog に移行すると統合ガバナンスが提供され、企業はデータ分析と AI ワークロードを安全に拡張できるようになります。
- このガイドでは、移行中の複雑さを管理し、混乱を最小限に抑えるための実用的な戦略を提示します。
データランドスケープの複雑さ
ビジネスがデジタルおよびデータ関連の能力を拡大し続けるにつれてデータ基盤の複雑さは増大し、持続的な価値を創出できるかどうかは、タイムリーで信頼性が高く、アクセス可能な情報にかかっています。しかし、多くの組織ではいまだに従来のHiveメタストア(HMS)が使用されています。HMSは、単一のワークスペースの境界を越える、最新の大規模なガバナンスのニーズに合わせて設計されたものではありません。
HMSには、リネージ追跡、複数ワークスペースのガバナンス、最新のセキュリティ制御が根本的に欠けています。例えば、従来のDatabricksのワークスペースごとのHMSを利用しているユーザーは、ワークスペース環境全体でポリシーが重複し、可視性が断片化するという問題に直面します。一方、外部HMSを使用しているユーザーは、不適切に構成されたマウントによって、意図せず機密データがすべてのワークスペースユーザーに公開されるリスクを負うことになります。チームの分散化が進み、データ利用が加速するにつれて、これらの制限は俊敏性とコンプライアンスの妨げとなり、最終的にはデータ主導の意思決定に対する信頼を損ないます。
Unity Catalog(UC)は、Databricksデータインテリジェンスプラットフォーム上のすべてのデータおよびAI資産に統一されたガバナンスモデルを導入することで、これらの課題に対処します。きめ細かなアクセス制御、一元的なリネージ追跡、複数ワークスペースのサポートにより、Unity Catalogは、組織が安全に拡張し、より効率的に運用するために必要な基盤を提供します。これらはHMSアーキテクチャでは実現不可能な機能です。
なぜ今これが重要なのか
この移行ガイダンスを提供するタイミングは非常に重要です。ここ数年で、Unity Catalogへの移行に必要なことに関する私たちの理解とツールは進化しました。このブログでは、私たちの最新の手法とベストプラクティスをまとめています。これらは、さまざまな企業環境における数多くのUnity Catalog移行から得られた、現場で実証済みのテクニックと実世界での教訓を反映したものです。組織は現在、実装のリスクと複雑さを大幅に削減する、実績のあるアプローチを利用できます。
このブログでは、レガシーの Databricks ワー�クスペース単位の HMS (内部 HMS と呼ばれる) と外部 HMS (AWS Glue など) から移行するためのガイダンスを提供し、次のトピックについて説明します。
- 制御を損なうことなく自律性をサポートするガバナンスモデルを評価する
- リスクと混乱を最小限に抑える、スケーラブルなアーキテクチャを設計・実行する
- 安全なセルフサービスでのデータアクセスをサポートするためにガバナンスを運用可能にする
- データ資産を移行する前に、Unity Catalogを使用して新しいワークロードを構築する
- 移行および切り替え期間中の混乱を最小限に抑える
アーキテクチャに関する主な考慮事項
HMSからUnity Catalogへの移行は、組織がデータアーキテクチャを最新化する機会となります。しかし、Unity Catalogの価値を最大限に引き出すには、当初から慎重な設計上の選択が必要です。こうしたアーキテクチャ上の決定は、組織のイノベーションのペース、ドメイン所有権モデル、そしてチーム間のデータアクセスのニーズに合わせて行う必要があります。
全体的な原則は同じですが、メタストアの種類によっては、特定のツールや移行アプローチの動作が異なる場合があります。これらの違いがあるため、現在のアーキテクチャのコンテキストで、ツールの互換性と移行要件を評価することが不可欠です。その理解を基に、メタストアの設計を検討できます。これはUnity Catalogガバナンスモデルの基盤であり、長期的な拡張性とコンプライアンスを確保するためにカタログ、スキーマ、権限をどのように編成するかを決定する上で重要な第一歩となります。
メタストアの設計
Unity Catalogにおけるメタデータの最上位コンテナとして、メタストアはガバナンスモデルの基盤となります。これは、カタログをデータ分離の主要単位として、またビジネスドメイン全体にわたるアクセス範囲を定める中心的なメカニズムとして定義することで、アカウントのアクセス制御フレームワークの基盤となります。Unity Catalog メタストアは、Databricks コントロールプレーン内のマルチテナントサービスとしてホストされ、カタログ、スキーマ、テーブル、ビュー、権限の信頼できるレジストリとして機能します。その中心的な役割のため、メタストアの設計は重要な初期ステップであり、データガバナンスの要件、ワークロードの分離、長期的なスケーラビリティを考慮する必要があります。
このセクションでは、メタストアの設計原則に焦点を当てます。Infrastructure as Code(IaC)を使用したUnity Catalogメタストアのプロビジョニングに関する技術的な詳細は、後の「Infrastructure as Code(IaC)による自動デプロイ」で説明します。
メタストア、マネージドストレージ、アクセス制御など、Unity Catalogの概念に関する背景情報については、「Unity Catalogとは」(AWS | Azure | GCP)を参照してください。
{kind=link}
Unity Catalogはリージョンごとに1つのメタストアをサポートしますが、データドメイン間で論理的および物理的な分離を強制するための複数のメカニズムを提供します。このため、複雑な環境や高度にセグメント化された環境を持つ組織であっても、ほとんどの場合、単一メタストア戦略が有効です。
実際には、厳格な地域的分離が規制やコンプライアンスの要件でない限り、ほとんどのチームは複数のメタストアをプロビジョニングするのではなく、単一のメタストアを採用し、カタログとスキーマを使用して境界を適用します。
リージョン間またはクラウド プラットフォーム間でデータを共有するためのガイダンスについては、リージョン間およびクロスプラットフォーム共有 (AWS | Azure | GCP) をご覧ください。
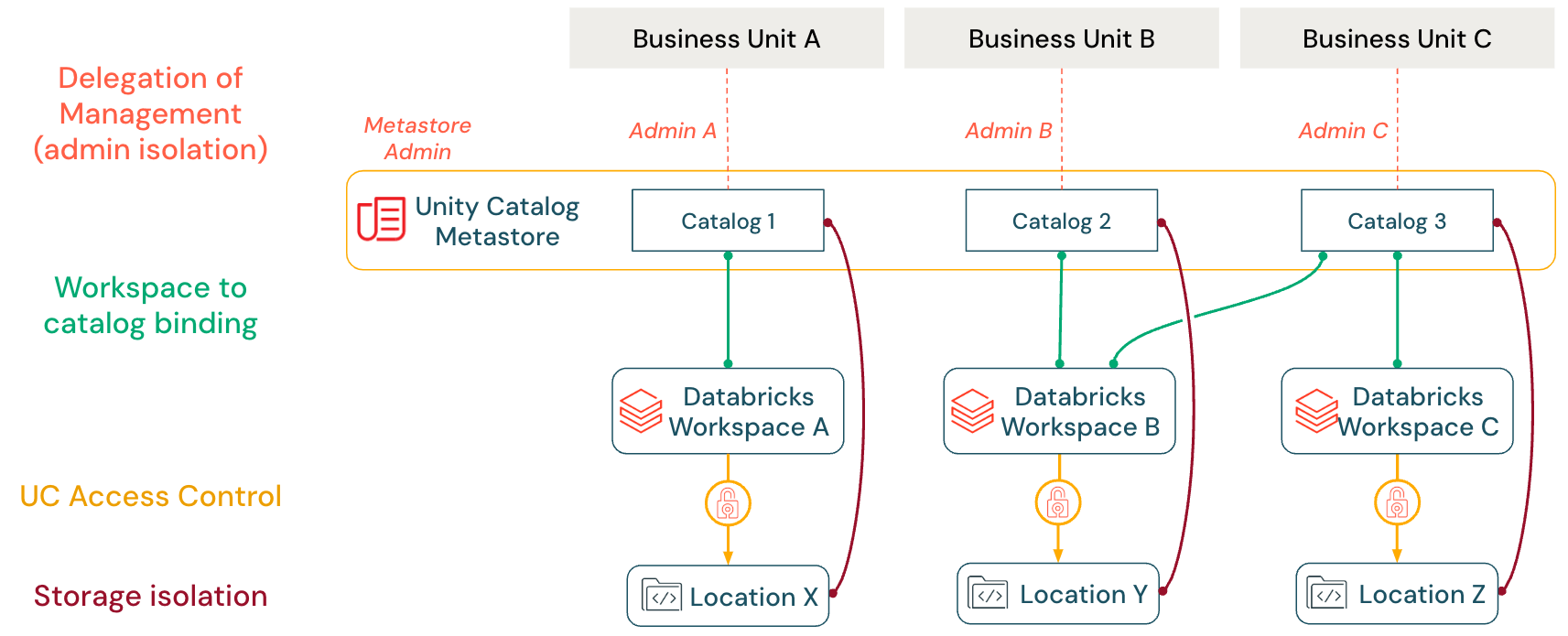
主な分離メカニズム
Unity Catalogは、単一メタストアアーキテクチャ内でデータ境界を適用し、分散型ガバナンスを可能にするために連携して機能する、4つの主要な分離メカニズムを提供します。
| 特徴量 | 目的 |
|---|---|
| 管理の委任 | Unity Catalogのオブジェクト所有権モデルを通じて、カタログ、スキーマ、テーブルの所有権と管理制御をドメイン固有のチームに移譲する |
| ワークスペースとカタログのバインディング | 特定のワークスペースへのカタログアクセスを制限し、開発ワークロードと本番ワークロード間の環境を分離する |
| きめ細かなアクセス制御 | 階層的な権限、行フィルター、列マスクを適用して、テーブルレベルおよび列レベルで厳密なデータセキュリティ要件を強制する |
| ストレージの分離 | マネージドストレージロケーションを介してカタログを専用のクラウドストレージコンテナにマッピングし、データ資産を物理的に分離する |
管理の委任(管理者の分離)
Unity Catalogのオブジェクト所有権モデルでは、各カタログ、スキーマ、テーブルに単一の所有者が割り当てられると同時に、制御された委任が可能です。オブジェクトの所有者またはメタストア管理者は、他のプリンシパル(例:ユーザー、サービスプリンシパル、またはアカウントグループ)にMANAGE権限を付与できます。これにより、SELECTやMODIFYなどのデータアクセス権限を付与するこ��となく、オブジェクトの名前の変更、削除、または権限の変更が可能になります。
この職務の分離により、分散型の管理が可能になります。チームは独自のデータ資産を管理できる一方、メタストア管理者は所有権の移管、アクセスの回復、環境全体のガバナンスの強制といった権限を保持します。継続性を確保し、管理オーバーヘッドを削減するため、所有権やMANAGE権限は個人ではなくグループに割り当てることをお勧めします。
オブジェクト所有権モデルとUC管理アセットの権限管理の詳細については、「Unity Catalogオブジェクトの所有権の管理」(AWS | Azure | GCP)を参照してください。
ワークスペースとカタログのバインディング
Unity Catalogでは、ワークスペースとカタログのバインド(AWS | Azure | GCP)を使用して、どのワークスペースがどのカタログにアクセスできるかを正確に制限できます。例えば、本番データカタログを特定のワークスペースにのみバインドすることで、ユーザーが開発者ワークスペースでデータを変更することを防ぐことができます。この例からもわかるように、ワークスペースとカタログのバインドは、他のワークスペースから特定のカタログへのすべてのアクセスを完全に防ぐわけではありません。例えば、メタストア管理者やカタログ所有者は、開発者ワークスペースのユーザーに対して本番データへの読み取り専用アクセスを指定し、必要に応じてテストを行えるようにすることができます(単一のカタログは複数のワークスペースで共有可能です)。この機能により、ユーザーレベルの権限に関係なく、データドメインのワークスペース境界が維持されます。
Unity Catalogのアクセス制御
Unity Catalogは、きめ細かく階層的なロールベースのアクセス制御(RBAC)を可能にし、管理者はユーザー、グループ、またはサービスプリンシパルに対して(メタストア、カタログ、スキーマ、またはテーブルのレベルで)正確な権限を付与できます。アクセスはSQLコマンドまたはDatabricks UIおよびCLIを介して管理されるため、データアクセスを制限し、堅牢なデータガバナンスとプライバシーを適用することが簡単になります。
Unity Catalogのアクセス制御は、連携して機能する4つの補完的なモデルで構成されています。
- ワークスペースレベルの制限:オブジェクトを特定のワークスペースにバインドすることで、ユーザーがデータにアクセスできる場所を制限します。
- 権限と所有権:保護可能な�オブジェクトに権限を付与し、オブジェクトの所有権を管理することで、誰が何にアクセスできるかを定義します。
- 属性ベースのアクセス制御(ベータ版):タグと、ユーザー、リソース、または環境の属性を動的に評価する柔軟な一元化ポリシーを使用して、ユーザーがアクセスできるデータを制御します。
- テーブルレベルのフィルタリングとマスキング:データに直接適用される行レベルのフィルターと列マスクを使用して、ユーザーがテーブル内で閲覧できるデータを制御します。
ストレージの分離
メタストアはリージョン単位の分離を提供しますが、データの分離は通常カタログレベルで実現されます。これを実現するために、Databricksでは、各カタログに独自のマネージドストレージコンテナ(例:専用のS3バケット、ADLSコンテナ、GCSバケット)を割り当てることを推奨しています。そのカタログ内の新しいマネージドテーブルまたはボリュームは、デフォルトで割り当てられたコンテナに書き込まれます。実際には、企業は各チームや環境に、個別のクラ��ウドバケットを持つ独自のカタログ(例:sales_prod、marketing_dev)を割り当てることがあります。このアプローチにより、各チームのデータは物理的に分離された状態が保たれ、同時にガバナンスが簡素化されます。暗号化やデータライフサイクル管理を組み込んだポリシーをコンテナレベルで適用することで、コンプライアンス要件を満たすことができます。
さらに、Unity Catalogは外部データアクセスを管理するために2つの主要な構成要素を使用します。
- ストレージ認証情報は、オブジェクトストレージへのアクセスに使用されるクラウドID(IAMロール、Azureサービスプリンシパル、GCPサービスアカウントなど)をカプセル化します
- 外部ロケーションは、その資格情報を特定のクラウドパスまたはコンテナに結び付けます。外部ロケーションに対する権限を付与されたユーザーのみが、そのパスのデータを読み書きできます。
これらは特定のワークスペースにバインドすることも可能で、権限のあるユーザーのみが機密データパスにアクセスできるようにします。
詳細については、「Unity Catalogを使用したクラウドオブジェクトストレージへの接続」(AWS | Azure | GCP)を参照してください。
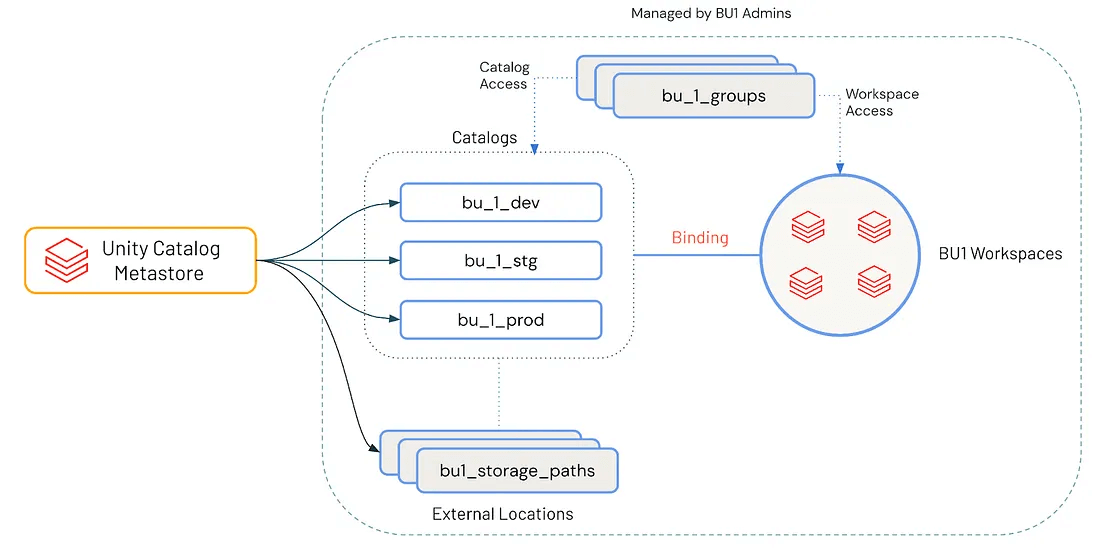
カタログの設計
適切に計画されたメタストアが整備されると、次に注目すべきはカタログの設計です。ここでは、ガバナンスに関する決定が日々のデータ利用と結びつき始めます。メタストアがグローバルなアクセス制御プレーンを確立するのに対し、カタログはデータの論理的な分離とドメインベースの所有権を実現するための主要なメカニズムとして機能します。
各カタログは通常、事業部門(BU)、機能ドメイン、またはプロジェクトの境界に対応します。このマッピングにより、チームはガバナンス基準との整合性を維持しながら、データに対する自律性を得ることができます。よく考えられたカタログ設計は、アクセスの複雑さを軽減し、ニーズの進化に応じて安全に拡張できるよう支援します。
{kind=link}
効果的なカタログ戦略は、ビジネスドメインの境界とソフトウェアのライフサイクルステージを反映したものです。広く採用されているスケーラブルなパターンは、次のとおりです。
<business unit>_<environment> → finance_dev、sales_stg、datascience_prod
この命名規則により、以下が可能になりま�す:
- 明確な所有権: 各カタログは、BUまたはドメインに対応付けられ、専門チームによって管理されます
- 環境の分離: データ製品は、管理されたステージ(開発 → ステージング → 本番)を経て、開発、検証、昇格が行われます
- ポリシーの粒度: アクセス制御、暗号化、リテンションポリシーをカタログレベルで適用できます
この構造により、チームは環境を分離したまま、データ製品の完全なライフサイクルを管理できます。開発者は、本番リリース前に、変更のテスト、ピアレビューの実施、アセットの段階的なプロモートを行うことができます。
厳格なセキュリティ要件またはコンプライアンス要件を持つ組織では、環境の分離が論理的な境界を越えて拡張されることがよくあります。このような場合、各環境は、個別のストレージコンテナ、クラウドネットワーキング(VPC/VNet)、さらには個別のDatabricksワークスペースによってサポートされることがあります。
Unity Catalog をビジネスおよび環境のセグメンテーションを反映するように調整することで、組織はガバナンスの一貫性を実現し、承認とデプロイのワークフローを合理化し、自信を持ってデータ イニシアチブを拡張できます。このアプローチは、チームの自律性と安全なイノベーション、そして一元化されたガバナンスとトレーサビリティの厳格さとのバランスを取ります。
詳細なガイダンスについては、Unity Catalogのベストプラクティス(AWS | Azure | GCP)を参照してください。
ガバナンスモデル: 集中型所有権と分散型所有権
カタログ設計がデータドメインと環境の構造的な境界を定義するのに対し、ガバナンスモデルはそれらの境界内で誰が意思決定の権限を持つかを確立します。一元化されたガバナンスモデルと分散型(またはフェデレーション型)のガバナンスモデルのどちらを選択するかによって、ポリシーの適用方法、チームの変化への対応方法、データに関する取り組みを組織全体にスケールさせる方法が決まります。
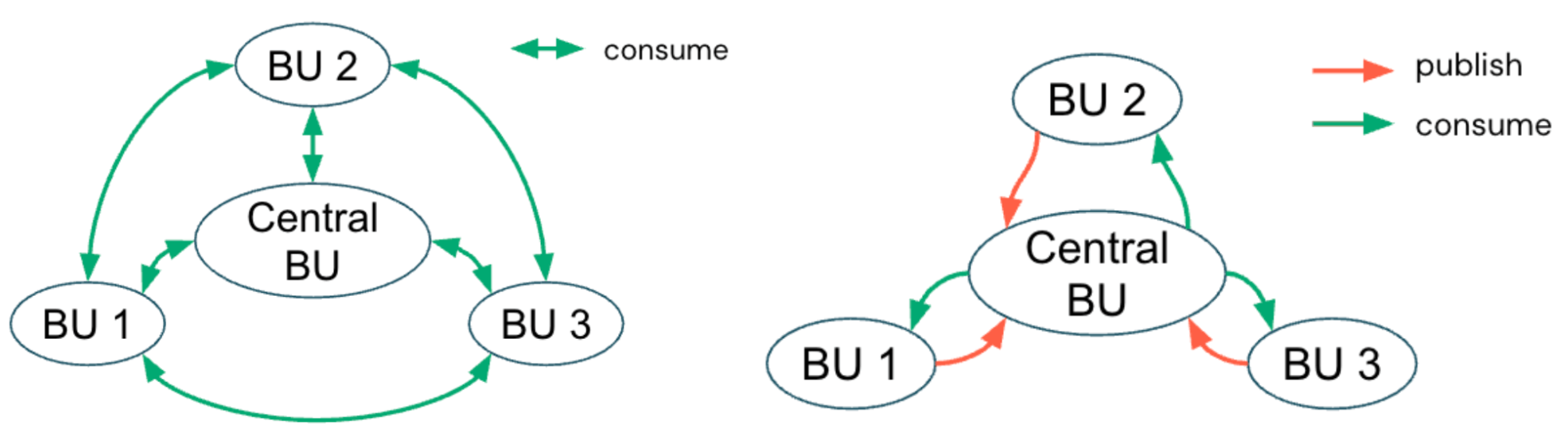
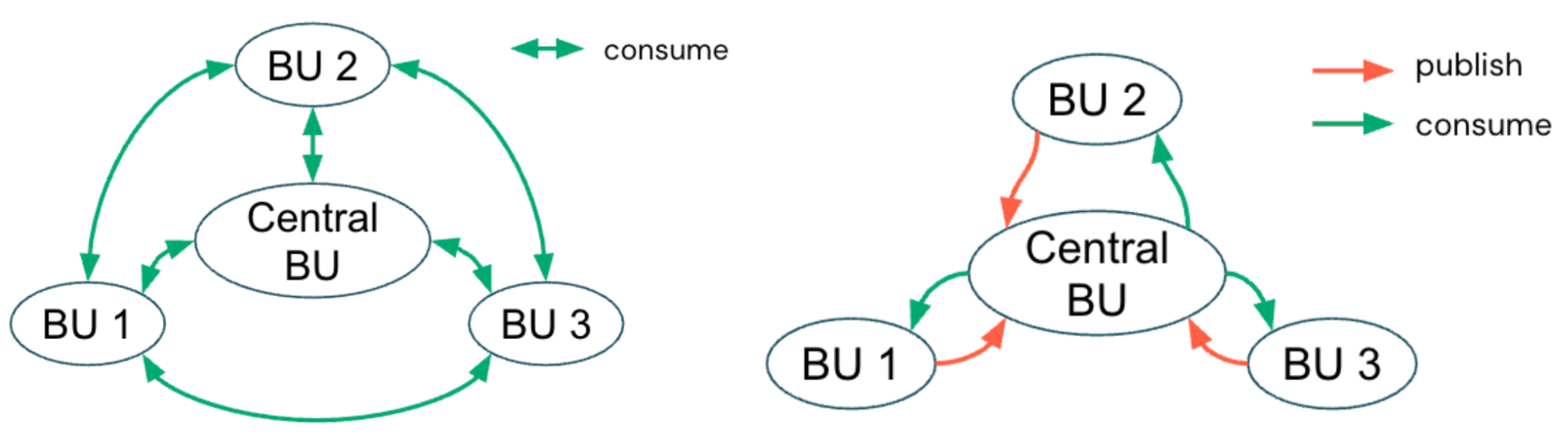
簡単に言うと、カタログはデータの所有権がどこにあるかを定義し、ガバナンスモデルはその所有権を誰がどのように管理するかを定義します。
{kind=link}
集中管理モデル
集中管理ガバナンスモデルでは、専門のプラットフォームチームまたはデータガバナンスチームがUnity Catalogメタストアを管理し、カタログを通じてアクセス境界を適用します。このチームは、カタログをBUまたはドメインに合わせたコンテナとして定義し、開発用途と本番用途を分離するためにワークスペースとカタログのバインディングを設定します。また、カタログ、スキーマ、テーブルの各レベルで、きめ細かい権限を適用します。
また、この中央チームは共有データセットのキュレーションを行い、すべてのドメインでコンプライアンス、品質、メタデータの標準を維持することで、組織全体に一貫したポリシーを適用します。このモデルはコンプライアンスと監査を効率化し、特に規制の厳しい業界や、データ環境が厳格に管理されている組織に適しています。
例えば、一元化されたガバナンスモデルを採用する一部のグローバルな製造組織は、地域間のコミュニケーションを合理化し、一貫した品質基準を適用し、サプライチェーン全体で運用コストを最適化できます。
分散管理モデル
逆に、分散型(またはフェデレーション型)ガバナンスモデルでは、個々のBUがカタログとデータ製品をエンドツーエンドで所有できるように権限を与えることで、管理を分散させます。中央のプラットフォームチームがインフラ、セキュリティのガードレール、コンプライアンスに準拠したアーキテクチャを管理する一方で、各ドメインチームは、自らのカタログ権限、データ品質、パブリッシングワークフローを独立して管理します。このモデルはドメインのアカウンタビリティとアジリティを促進し、Data Meshの原則に沿っています。Data Meshでは、データは製品として扱われ、共通のガ�バナンスフレームワーク内で自律的なチーム間のコラボレーションが行われます。
所有権が分散されているため、分散型アプローチはデータ資産の拡大に合わせてうまくスケールします。各チームは自らのデータの品質、リネージ、ドキュメントに直接責任を負うため、より強力なアカウンタビリティが育まれ、組織全体への信頼できるデータ製品の提供が加速されます。
この特定のモデルは、ローカライズされたコンプライアンスを必要とする多様な事業ポートフォリオを持つ組織や、異なる規制要件を持つ複数の地域にまたがるオペレーションを行う組織に特に適しています。
どちらを選ぶべきですか?
Unity Catalogを使用した集中管理ガバナンスモデルは、一貫したポリシー、簡素化されたコンプライアンス、すべてのデータ資産にわたる統一された監督を提供するため、ほとんどの組織ではこのモデルから始めるのが実用的です。集中管理が非現実的となる特定の制約を持つ組織では、分散管理ガバナンスモデルを検討する必要があります。たとえば、高度に自律的なBU、専門的なデータワークロード、または地域によって異なる規制要件を持つ組織は、集中管理が硬直的すぎると感じる場合があります。
最終的に、選択は組織構造、規制要件、データ成熟度、コラボレーションのニーズなどの要因によって決まります。以下に、意思決定の参考として、各アプローチの長所とトレードオフを簡単にまとめます:
| アスペクト | ガバナンスの一元化 | 分散ガバナンス |
|---|---|---|
| 制御とコンプライアンス | 強力な一元管理により、監査と規制コンプライアンスが簡素化されます。 | 明確なガードレールが必要ですが、柔軟性を提供します。中央チームはガードレールを管理し、データアクセスは管理しません。 |
| スピードとアジリティ | 承認のボトルネックと集中化されたワークフローのため、速度が遅くなります。 | BUがデータライフサイクルとアクセス管理を所有するため、イノベーションが加速します。 |
| 所有権と説明責任 | 中央チームは、データ品質とメタデータの一貫性を担当します。 | ドメインチームがデータ品質、ドキュメント、パブリッシングを所有し、アカウンタビリティを促進します。 |
| 複雑さとスケール | 最初は管理しやすいですが、大規模になるとボトルネックになる可能性があります。 | 拡大するデータ資産に合わせて適切にスケールしますが、成熟したポリシーと監視が必要です。 |
| コラボレーション | コラボレーションは、一元管理されるワークスペースとカタログのバインディングによって制御されます。 | 共有ポリシーによってコラボレーションが可能になり、チームはカタログの境界内で自律的に活動します。 |
| 最適なケース | 権威あるガバナンスの決定を行う中心的なグループを持つ組織。 | 独自のプロセスに従う自律的なドメインチームを持つ組織。 |
どのアプローチであっても、効果的なガバナンスには、所有権とカタログの明確なマッピング、堅牢なアクセス制御、透明性のあるコラボレーション��のためのメカニズムが必要です。これにより、Unity Catalog環境がスケールするにつれて、セキュリティとイノベーションを両立させることができます。
技術的ソリューションの内訳
ガバナンスとアーキテクチャの概念的基盤が確立されたことで、焦点は実際のデータ資産をUCに移行する際の実践的なエンジニアリングの取り組みに移ります。高レベルのステップ(アップグレード手順の概要 [AWS | Azure | GCP] を参照)では実行すべきことが概説されていますが、技術的な実行には、複雑な依存関係の解決、ダウンタイムの最小化、既存のワークフローへの対応などが伴うことがよくあります。実際の移行が画一的な方法で進められることはほとんどなく、その結果、チームは現在のデータ資産、運用上の制約、ビジネスの優先順位に基づいてアプローチを調整する必要があります。
これらの複雑さに対処するために、以降のセクションでは、現代のデータ組織向けの3つの重要な技術的考慮事項、すなわち、現在の資産と依存関係を理解するための移行前のデータ検出、Infrastructure as Code(IaC)を使用した自動デプロイ、そして段階的な導入を可能にするためのフェーズごとの移行戦略について詳しく説明します。
1. 移行前のデータ検出
Hive テーブルを移行してワークロードを更新する前に、チームは既存のデータ環境を理解する必要があります。この検出フェーズでは、移行範囲を定義し、リスク領域を特定して、リグレッションやサービスの中断を防ぎます。
これには、HMS 内のアクティブなテーブル、ビュー、ジョブ、権限、チームをマッピングし、Unity Catalog に変換する必要があるものを判断する作業が含まれます。複数のワークスペースと膨大なデータ量を持つ大規模な組織では、データの所有権、アクセス制御、ジョブの依存関係を手動で追跡することは、すぐに持続不可能になります。
UCX によるデータ検出
この懸念に対処するため、Databricks LabsはUCX(AWS | Azure | GCP)を開発しました。これは、データ検出、準備状況の評価、移行計画を自動化するオープンソースツールです。デプロイされると、UCXは従来のHMSワークスペースをスキャンして関連資産をインベントリ化し、移行作業の指針となる詳細なレポートを生成します。UCXによる評価レポートは、スキャンされた資産の総数に基づく「準備状況」メトリックを提供し、修正作業の優先順位付けに役立つように結果を分類します。
UCXの出力を確認する際、組織は情報に基づいた意思決定を行うために、生のカウントや準備状況スコアにとどまらず、次のような点を検討する必要があります。
- 移行範囲の縮小: 古いテーブルや冗長なテーブルを特定して除外する
- アクティビティシグナルの確認: 最終アクセス時刻や最終更新時刻などを確認して、重要なワークロードと未使用のデータを分離する
- 資産の合理化: 移行前に重複するスキーマを統合したり、命名規則を標準化したりする
- 依存関係の優先順位付け: 下流のパイプライン、BIダッシュボード、または規制要件によって、最初に移行すべきものが決まる
この自動化された検出プロセスを通じて、組織は次のような価値を得られます。
- BUs、チーム、およびそれらのデータプロダクトの全体像の把握
- ユーザー、グループ、アセット間のアクセス制御と依存関係のマッピング
- アクティブに使用されているテーブルやビューと、アーカイブ候補を特定する
- 重要なレガシーワークフローを優先し、他のワークフローは段階的に廃止する
わずか数個から数百個もの Databricks ワークスペースを管理する組織にとって、UCX は検出の自動化と移行範囲の明確化により、エンジニアリングの労力を削減します。これにより、人的エラーが最小限に抑えられ、互換性のギャップや隠れた依存関係が特定されるため、移行前にワークロードがガバナンス基準を確実に満たすようになります。
UCX の概要については、「UCX ユーティリティを使用してワークスペースを Unity Catalog にアップグレードする」(AWS | Azure | GCP) を参照してください。
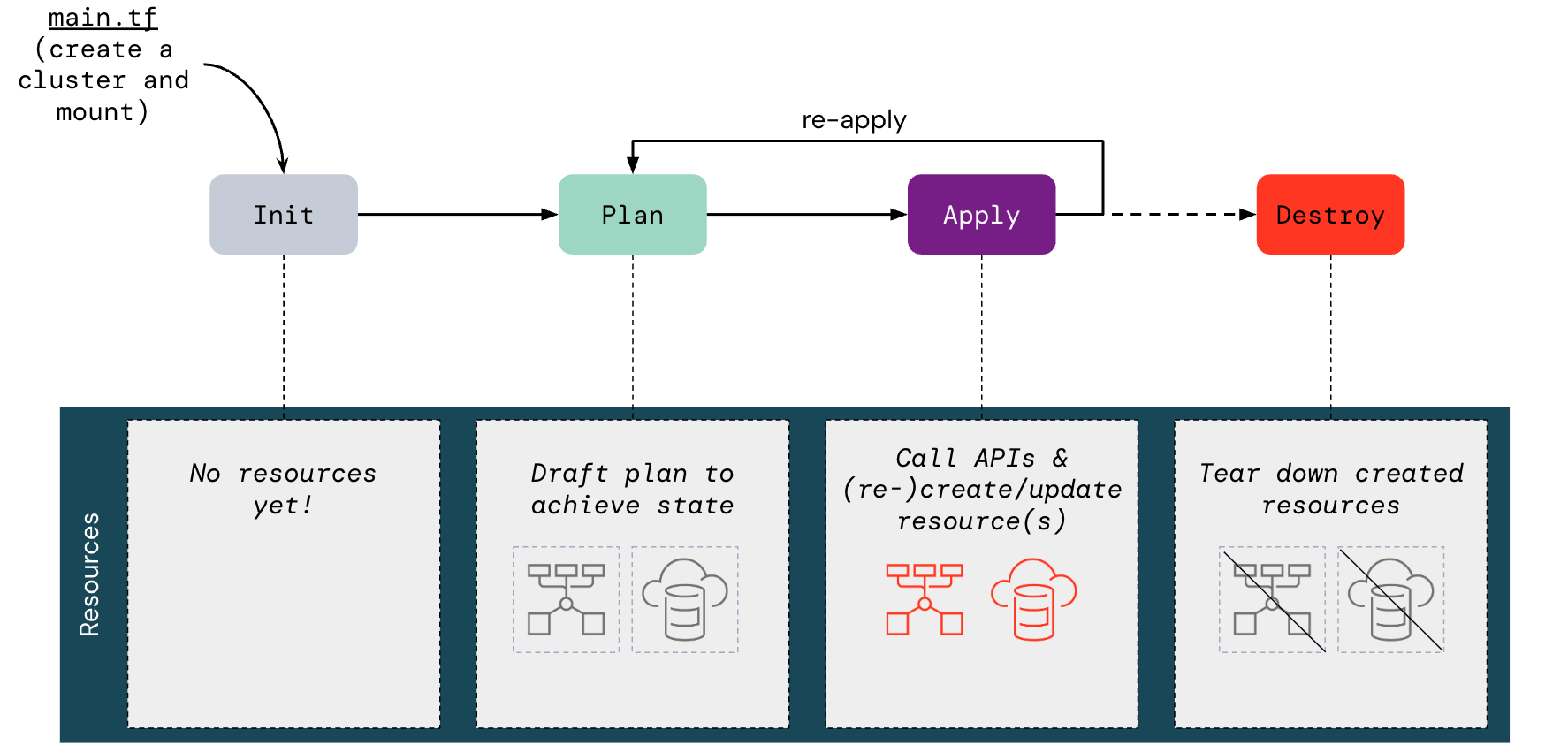
2. Infrastructure as Code(IaC)による自動デプロイ
データ検出によって既存のアセット、依存関係、アクセスパターンの全体像が明らかになったら、次の課題は、それらをサポートする Unity Catalog 環境をプロビジョニングすることです。この環境のデプロイは、(適切な管理者権限があれば)アカウントコンソールから手動で行うこともできますが、手動での設定ミスや不整合を避けるために Databricks Terraform プロバイダーを活用することを強く推奨します。
{kind=link}
Terraformを使用することで、チームはサポートされているすべてのクラウドプラットフォームでUnity Catalogリソースの作成と設定を自動化でき、移行プロセスを再現可能かつ監査可能にします。たとえば、Databricksのアカウント管理者はアカウントコンソールからUnity Catalogメタストア(AWS | Azure | GCP)を手動で作成できますが、Terraformを使用して`databricks_metastore`リソースをプログラムでプロビジョニングすることもできます。同様に、Terraformを使用してメタストア内にカタログとスキーマを定義し、マネージドストレージ構成を適用し、アクセス権限を設定できます。IaCというこのより堅牢なアプローチを使用することで、Unity Catalogのセットアップ全体をいくつかのスクリプト(例: Terraform + REST API)で完全に自動化し、組織内のすべてのBUで複製できるようテンプレート化して、手動でのプロビジョニングをゼロにすることができます。
デプロイ用のカスタムTerraformモジュールを作成するための完全なガイドについては、Terraformを使用したUnity Catalogセットアップの自動化(AWS | Azure | GCP)を参照してください。
Unity Catalog の移行において、このアプローチはチームが次のことを行えるようにするために必要なインフラストラクチャを構築する上で、特に強力であることが証明されています。
- 環境全体でガバナンス基準が一貫して適用されるようにします。
- 移行時の設定ミスのリスクを最小限に抑える
- 将来の拡張に対応するガバナンス インフラストラクチャの継続的なデリバリーを可能にする
3. 移行戦略
HMS資産の完全なインベントリとIaCを介してプロビジョニングされたUnity Catalog対応ワークスペースが準備できたところで、焦点はセットアップから、管理された低リスクのワークロード移行へと移ります。組織は、単純なパイロットプロジェクトから企業全体の変革に至るまで、その複雑さ、構造、リスク許容度に合わせた戦略を選択できます。
ほとんどの組織は段階的な導入アプローチから始めることでメリットを得られますが、初期のパイロットを超えてスケールするには、慎重な計画と構造化された実行が必要です。包括的なUnity Catalog移行を計画および実行している組織は、Databricksのアカウントチームやデリバリーソリューションアーキテクト(DSA)に相談することで、移行支援や専門的な移行方法論を利用できます。
パイロットアプローチによる段階的な導入
ほとんどの本番環境では、「ビッグバン」移行は現実的ではありません。代わりに、Databricks では、パイロット移行から始めることを推奨しています。これは、ワークロードが組織の一般的なパターンを反映し、明確なデータ境界を持ち、熱心なステークホルダーが関与している代表的な BU やチームを対象とします。このパイロット フェーズでは、管理された環境でツール、プロセス、ガバナンス コントロールを検証し、チームがエッジケースを発見したり、ロールアウトの順序を調整したり、工数の見積もりを改善したりするのに役立ちます。得られたインサイトは、その後の移行における不確実性とリスクを低減します。
そこから組織は、プラットフォームの安定性を維持し、ステークホルダーの信頼を構築し、予測可能な進捗を可能にしながら、段階的に完全導入へとスケールできます。これらは、一括でのリフトアンドシフトでは達成が困難な利点です。
Databricksでは、HMSからUnity Catalogにワークロードを移行するために、2つの異なる段階的なアプローチを推奨しています。
オプションA: パイプラインごとの移行
このアプローチでは、次のパイプラインに進む前に、関連するテーブル、ジョブ、ダッシュボード、依存関係を含めて、一度に1つのパイプラインをUnity Catalogに移行します。単一パイプラインのデータリネージ全体とコンシューマープロデューサーパスをカプセル化することで、この方法はリスクを局所化し、その後の移行のために学んだ教訓を活用します。チームは、各Unity Catalogへの切り替えを個別にテスト、検証、調整する機会を得られるため、継続的な改善とプラットフォーム全体での混乱の低減につながります。
オプションB: レイヤーごとの移行(Gold → Silver → Bronze)
メダリオンアーキテクチャに基づくレイヤーごとの戦略では、Unity Catalogへの移行を、Gold(ユーザー向けの分析出力)、Silver(クレンジングおよび重複排除されたデータセット)、Bronze(取り込まれたままの生データ)という個別のレイヤーを通じて進めることが推奨されます。一部のデータエンジニアリングプラクティスにおけるボトムアップの伝統とは対照的に、Databricksは多くの場合、ダッシュボード、BI資産、可視性の高いテーブルを含むGoldレイヤーから始めることを推奨します。これにより、分析コンシューマーの継続性を維持しながら、ビジネスへの影響を軽減し、下位レイヤーの変更による下流への影響を回避できます。
オプション B の移行手順:
- 最初にゴールドレイヤー: 最初にゴールドテーブルを Unity Catalog に移行し、次に重要なダッシュボード、BI ツール、アドホッククエリを再調整して Unity Catalog 内の代替テーブルを指すようにします。これらのアセットは多くの場合、最も可視性が高く、最初に移行することで、事業運営へのリスクを最小限に抑えることができます。
- 次にシルバーレイヤー: Unity Catalogでゴールドのコンシューマーが検証されたら、それらに供給する変換ジョブとテーブル(通常はシルバーレイヤー)を更新します。このステップには、より広範なデータクレンジングと適合性プロセスが含まれます。
- 最後にブロ��ンズレイヤー: 外部の取り込みジョブと未加工のランディングテーブルをUnity Catalogに移行して、サイクルを完了します。アップストリームの取り込みが統合されると、データスタック全体のリネージがUnity Catalogのガバナンス下に置かれます。
Databricksは、上記の移行戦略を規律ある運用プラクティスで補強することを推奨しています。たとえば、従来の HMS テーブルにアノテーションを付けて対応する Unity Catalog を参照させることで、ユーザーはスムーズに移行でき、混乱を回避できます。レガシーテーブルやジョブを廃止する前に、Unity Catalogですべての下流の依存関係を厳密にテストして、ワークフローが中断されないようにします。さらに、Unity Catalogによって管理されるようになったアセットのワークスペースアクセス制御を更新したり、ロールを再割り当てしたりする際には、関係者との一貫したコミュニケーションを維持し、調整を管理する必要があります。
次のセクションでは、段階的なアプローチを補完する2つの一般的な移行パス(ソフト対ハード)を比較します。
移行パス:「ソフト」対「ハード」
定義されたフレームワーク内には、2つの異なる移行パターンがあります。ソフト移行はHMSフェデレーションを通じて行われ、HMSをそのまま維持しながら(レガシーワークロードの中断を回避)、フェデレーションされたアセットでUnity Catalogの高度なガバナンス機能へのアクセスを可能にします。そしてハード移行は、HMSからUnity Catalogへの完全なメタデータとデータの転送を伴いますが、チームやシステム間でのより広範な計画と調整が必要です。
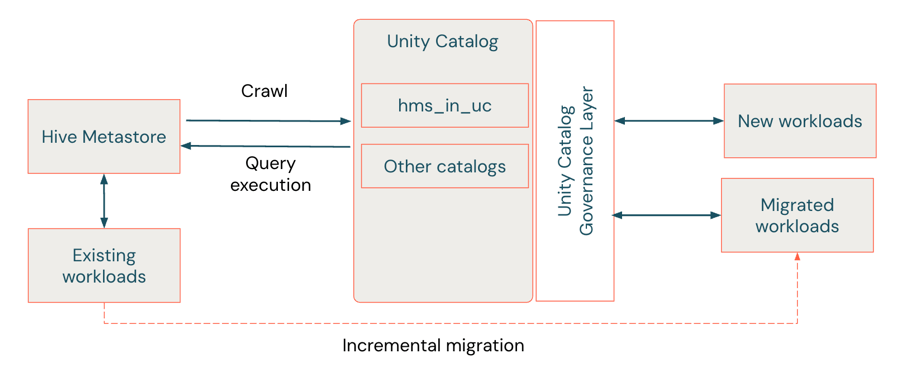
HMS フェデレーションによるソフト移行
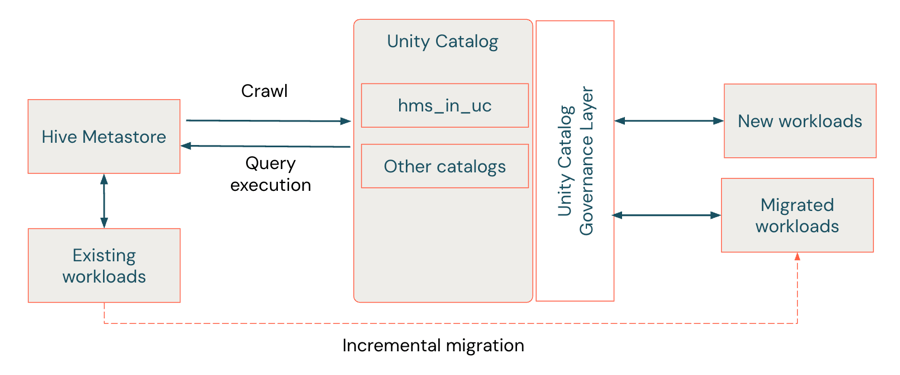{kind=link}
ソフト移行は、「移行ブリッジ」として機能するハイブリッドなアプローチと見なされており、チームはレガシーのHMSをそのまま維持しながら、Unity Catalogのガバナンス機能を導入できます。Hiveメタストアフェデレーション(AWS | Azure | GCP)は、最小限の中断で増分移行を可能にします。即時のデータ移動やコード変更は必要ありません。Unity Catalogは、HMSメタデータをミラーリングする外部カタログを作成し、ワークロードが両方のシステムで実行できるようにします。このようにして、このフェデレーションされたHMSの外部テーブルは一種の下位互換性を提供し、ワークロードがHiveのみのセマンティクス、つまりレガシーの2レベルの名前空間(schema.table)を�使い続けられるようにします。これにより、Unity Catalogのガバナンス、監査、アクセス制御の恩恵を受けながら、3レベルの名前空間(catalog.schema.table)との互換性を維持できます。
Unity Catalog でのフェデレーション データの管理方法と操作方法は、HMS が内部か外部かによって異なります。フェデレーション コネクタは、Databricks ワークスペース内の内部 HMS インスタンスにあるテーブルへの読み取りおよび書き込みアクセスをサポートしますが、外部 HMS と AWS Glue のテーブルは読み取り専用です。いずれの場合も、HMS カタログ(内部または外部)全体または AWS Glue を Unity Catalog に外部カタログとしてマウントできます。これらはネイティブ オブジェクトとして表示されます。変更が発生すると、テーブルのメタデータは HMS と自動的に同期されます。内部 HMS の場合、外部カタログで作成された新しいテーブルや更新は HMS に書き戻され、2 つの環境間のシームレスな相互運用性が維持されます。
HMSフェデレーションによるソフト移行は、Unity Catalogを導入するための低中断なパスを提供しますが、HMSを完全に廃止することを目指す組織は、最終的にフェデレーションされたアセットのハード移行を実行する必要があります。フェデレーションされたアセットのハード移行を自動化することは可能ですが、これらのアセットを読み書きするコードは、新しいUnity Catalogアセットを指すように変更する必要があります。
さらに、UCXは(テーブル移行プロセスの代替として)HMSフェデレーションを有効にするためのCLIツールを提供しています:
レガシーワークスペースのHMS、外部HMS、またはAWS Glueメタストアに対してHMSフェデレーションを設定する手順については、「Unity Catalogへの移行中にHiveメタストアフェデレーションを使用する方法」(AWS | Azure | GCP)を参照してください。
ハード移行
ハード移行は、HMSからUnity Catalogへの包括的なアップグレードであり、テーブルのメタデータ(およびマネージドテーブルのデータ)を新しいメタストアに変換します。このアプローチでは、外部テーブルには SYNC (またはアップグレードウィザード) などのツールを、マネージドテーブルには CREATE TABLE CLONE (CTAS) を組み合わせて使用します。各方法には、それぞれ要件と制限があります。
移行が必要な大量のデータを HMS に持つ組織に対して、ほとんどのテーブル移行シナリオでは、Databricks は(以下に示す手動の方法よりも)UCX の自動化されたテーブル移行ワークフローの使用を推奨します。どの UCX ワークフローを実行するかを決定し、テーブル移行に関する追加のコンテキストを取得するには、 Hive metastore データ オブジェクトの移行 を参照してください。
外部テーブルのアップグレード
外部テーブルは、SYNCコマンドまたはアップグレードウィザードを使用してアップグレードできます。これらはメタデータのみの操作を実行し、データはコピーも移動もされません。
- SYNC: テーブルのメタデータをHMSからUnity Catalogに転送し、管理プロパティをHMSテーブルに書き戻すSQLコマンドです。テーブルまたはスキーマ レベルで適用できるため、SQL を優先するチームは、何をいつ移行するかをきめ細かく制御できます。
- アップグレードウィザード: SYNC機能をビジュアルなワークフローでラップするカタログエクスプローラーのインターフェースです。一括スキーマ移行に最適で、ポイントアンドクリックのシンプルさが導入を加速させます。
HMS と Unity Catalog のテーブルは同じクラウドストレージを参照するため、移行期間中はハイブリッド設定を実行できます。スケジュールされた SYNC により、移行が完了するまで両方のシステム間でメタデータの整合性が保たれます。
マネージドテーブルのアップグレード
マネージド テーブルはマネージド ストレージの場所に格納されているため、データの移動が必要です(マネージド ストレ�ージの場所とは? を参照)。[AWS | Azure | GCP])。そのため、CREATE TABLE CLONE または CREATE TABLE AS SELECT (CTAS) を使用してアップグレードする必要があります。
- CREATE TABLE CLONE(ディープクローン): この方法は、データとメタデータをストレージレイヤーに直接コピーします。パーティショニング、フォーマット、不変条件、NULL値許容性、その他のメタデータを自動的に保持します。また、計算負荷の高い読み取り/書き込みサイクルを回避するため、CTASよりも高速に実行されます。
- CREATE TABLE AS SELECT(CTAS): マネージドHiveテーブルがクローニング要件(例:Deltaフォーマット)を満たさない場合に便利です。CTASはクエリ結果からテーブルを再構築し、プロセス中に選択的な移行や変換を可能にします。
マネージドテーブルの移行にはCLONEが強く推奨されますが、ソーステーブルに調整が必要な場合にはCTASが柔軟性を提供します。
ビューのアップグレード
参照されているすべてのテーブルが移行された後、ビューは手動で再作成する必要があります。3レベルの名前空間(catalog.schema.table��)に従って、テーブルのUnity Catalogバージョンを参照するCREATE VIEWステートメントを使用します。
テーブルとビューを移行するためのさまざまなオプションの詳細については、「Hive のテーブルとビューを Unity Catalog にアップグレードする」(AWS | Azure | GCP) を参照してください。
HMSへのアクセスを無効にする
すべてのHMSアセットがUnity Catalogに移行された後、またはHMSがUnity Catalog下のフェデレーションカタログとしてフェデレーションされた後、組織全体で一元化されたデータガバナンスを確実に導入するために、レガシーHMSへの直接アクセスを無効にすることが不可欠です。このステップにより、将来のクエリ、ワークロード、データ検出は Unity Catalog のアクセス制御のみの対象となり、並列ガバナンスフレームワークは不要になり、不正使用も防止されます。
Databricksは、均一なガバナンスを強制し、潜在的なバイパスルートを遮断するために、すべてのクラスターとワークロードに対して一度に直接HMSアクセスを無効にすることを推奨しています。段階的なロールアウトを希望する組織の場合、Spark構成を設定することで、個々のコンピュートクラスター単位で強制を適用することもでき、必要に応じて段階的なロールア�ウトが可能になります(「Databricksワークスペースで使用されるHiveメタストアへのアクセスを無効にする」[AWS | Azure | GCP]を参照)。
レガシーメタストアを無効にすることの影響を理解するには、「レガシーメタストアを無効にするとどうなりますか?」を参照してください。(AWS | Azure | GCP)。
実際の例
Databricksを大規模に運用し、数千のテーブルとノートブックを管理するあるグローバルな小売業者は、データガバナンスと部門横断的なコラボレーションにおいて大きな課題に直面していました。データは複数のレガシーストレージ環境にサイロ化されており、権限管理が複雑化し、アクセス可視性が不明瞭になり、全社的な分析の実行が困難�になっていました。事業部門(BU)はデータに対する信頼を欠いていることが多く、また、アセットの可視性が限られているため、初期の移行範囲の決定は特に困難なものでした。
このブログで概説されている基本原則に基づき、この組織はまず、一元化されたガバナンスとドメインレベルの自律性のバランスをとるように設計されたフェデレーションデータメッシュをターゲットアーキテクチャとして定義することから始めました(「ガバナンスモデル:一元化された所有権と分散された所有権」)。Databricks LabsのUCX移行ツールキットを活用して、彼らは包括的なアセットインベントリを実施し、非アクティブなワークロードやUnity Catalog互換のコンピュートで実行されていないワークロードを特定しました(「1. 移行前のデータ検出」)。この洞察により、彼らは価値の高いビジネスユースケースを優先し、パイロット&スケールの移行アプローチを採用し、下流の依存関係と影響に基づいてワークフローの順序を決定することができました(「3. 移行戦略」)。移行は段階的に実行され、外部テーブルにはSYNCを、マネージドテーブルにはDEEP CLONEが使用されました。当時は利用できなかったHMSフェデレーションの代わりに、彼らは双方向同期戦略を実装して、運用上の中断を最小限に抑えながら増分移行を可能にしました(「HMSフェデレーションによるソフト移行」)。
移行後、組織は Unity Catalog を通じて一元的なガバナンスを確立すると同時に、ビジネスドメインが独自のデータと分析を管理できる連携アーキテクチャを維持しました。組み込みの監査機能とデータリネージ�機能により透明性と信頼性が向上し、一方でレガシーコードとパターンの使用廃止により技術的負債が削減され、運用が効率化されました。物理ストレージを抽象化してアクセスを簡素化することで、組織はビジネスチームが信頼できるデータを発見、アクセス、分析できる文化を育み、よりデータとAI主導のビジネスへの変革を推進しました。
主要なポイント
- スケーラブルなガバナンスは不可欠です: データ主導の組織が成長するにつれて、HMS などのレガシーメタストアが最新のガバナンス ニーズをサポートすることは困難になります。Unity Catalog は、きめ細かいアクセス制御、リネージ追跡、マルチワークスペース サポートを備えた統合ガバナンスを提供します。これらは、複雑な分析および AI 環境全体で信頼とコンプライアンスを維持するために不可欠です。
- モジュール式ガバナンス アーキテクチャ: Unity Catalog は、集中型および分散型(フェデレーション)ガバナンスをサポートします。集中型モデルは、規制対象業界のコンプライアンスと監査を簡素化する一方、分散型モデルは BU にデータの所有権を与え、ガードレールを犠牲にすることなくイノベーションを加速させます。
- メタストアとカタログの設計は重要です: 思慮深いメタストアとカタログの設計は、スケーラブルなガバナンスの基盤を形成します。カタログベースの分離と、一貫した命名規則やストレージ境界を組み合わせた単一のメタストア戦略は、権限を簡素化し、自律性を促進して、安全なコラボレーションを実現します。
- 自動化されたリスク認識型の移行: 移行前の検出と Infrastructure as Code (IaC) を組み合わせることで、一貫性のある Unity Catalog のセットアップが保証され、手動エラーが削減され、デプロイが加速されます。代表的なパイロットから始める段階的な導入は、信頼を醸成しステークホルダーの賛同を得ながら、混乱を最小限に抑えます。
- 柔軟な移行パス: HMS フェデレーションによるソフト移行では、コードをすぐに変更することなく Unity Catalog ガバナンスを段階的に導入できます。一方、ハード移行では Unity Catalog のすべてのメリットが得られ、HMS の完全な廃止が促進されます。適切なパスの選択は、運用上のリスク許容度、依存関係、モダナイゼーションの目標によって決まります。
まとめ
HiveメタストアからUnity Catalogへの移行は、統一されたスケーラブルなガバナンスと最適化されたデータ運用を求める企業が、真のデータインテリジェンスを解き放つための必要な基礎的ステップです。成功の鍵は、ガバナンスモデルを組織の優先事項(コンプライアンスのための一元管理、またはチームレベルの俊敏性のための分散所有権)に合わせることです。自動化されたデプロイメント、徹底した移行前の検出、段階的な導入を組み合わせることで、組織はミッションクリティカルなワークロードの継続性を確保しながら、中断を最小限に抑えることができます。Unity Catalogの柔軟でモジュール式のアーキテクチャは、安全なコラボレーション、セルフサービス分析、包括的なコンプライアンスを可能にし、持続的なデジタルトランスフォーメーションとデータ駆動型の競争優位性のための基盤を確立します。
次のステップとリソース
Unity Catalogへの移行を効果的に開始するには、上記で概説した戦略を適用し、詳細で最新のガイダンスについてはDatabricksの公式ドキュメントを参照してください。
Unity Catalog移行トラッカー
このトラッカーは、Unity Catalogへの移行を管理するための構造化されたテンプレートを提供し、ドキュメントやツールへの組み込みリンク、およびマイルストーンの完了を追跡するためのステータスフィールドが含まれています。
移行トラッカー: Github
Unity Catalogの使用を開始する
Unity Catalogに関する基礎的な専門知識を構築するには、以下のインタラクティブなセルフペースのDatabricks Academyコースをご活用ください(Databricksアカウントまたはメールでのログインが必要です):
- Unity Catalog入門
- Databricksにおけるデータ管理
- Unity Catalogにおけるデータアクセス制御
- コンピュートリソースとUnity Catalog
- Unity Catalogのパターンとベストプラクティス
実際のシナリオから学ぶ
2025 Data + AI Summitで紹介される、顧客の成功事例や詳細な技術セッションから実践的な知見を得ましょう。
- Databricks主導:
- 導入事例 -
- Schiphol GroupのUnity Catalogへの変革 - Data + AI Summit 2025 | Databricks (Schiphol GroupとDatabricks)
- Unity Catalog (UC) 移行のストーリー: 7-ElevenにおけるUCXを活用した複雑なUC移行の再構築 - Data + AI Summit 2025 | Databricks (7-ElevenとDatabricks)
- エンタープライズの可能性を解き放つ: P&GによるUnity Catalog大規模展開からの主要なインサイト - Data + AI Summit 2025 | Databricks (P&G)
DSA: 専門家による移行ガイダンス
DatabricksのDelivery Solutions Architect (DSA) は、組織がUnity Catalogへの移行を進める上で、中核的な役割を果たします。戦略的アドバイザーとして、DSAは各組織に合わせた実行計画の策定を支援し、移行作業をビジネス目標と整合させ、デリバリーに影響が出る前に潜在的なリスクを特定するお手伝いをします。データエンジニアリングチーム、プラットフォームオーナー、経営層のステークホルダーと緊密に連携することで、DSAは、スコーピングとワークスペース評価からデプロイと検証に至る移行の各段階が、お客様に合わせたソリューションと価値実現までの時間短縮を中心に進められるようにします。DSAが、お客様に合わせた計画策定と専門�家による支援を通じて、お客様のUnity Catalogへの移行をどのようにサポートできるかについては、貴社のDatabricksアカウントチームまでお問い合わせください。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。