Sparkにおける任意のステートフルストリーム処理の進化
transformWithStateInPandasのユニークな利点を探る
によって Sol Ackerman, Anish Shrigondekar, エリック・マルナディ, Jing Zhan, ボー・ガオ, Jungtaek Lim 、 Karthik Ramasamy による投稿
- ステートフル処理の進化:Spark™ 4.0でのapplyInPandasWithStateとtransformWithStateInPandasの比較による柔軟性と機能性の強化。
- 新機能: transformWithStateInPandasは、複雑なストリーミングパイプラインのための複数のステートタイプ、タイマー、TTL、スキーマ進化を提供します。
- 開発の簡素化: transformWithStateInPandasは、ステートの取り扱いを簡素化し、より詳細な制御とステートデータソースリーダーとの簡単な統合により、デバッグプロセスを改善します。
イントロダクション
Apache Spark™ Structured Streamingにおけるステートフル (Stateful) 処理は、複雑なストリーミングアプリケーションの増大する要求に対応するために大きく進化しました。最初に、applyInPandasWithState APIは、開発者がストリーミングデータに対して任意のステートフル操作を行うことを可能にしました。しかし、ストリーミングアプリケーションの複雑さと洗練度が増すにつれて、より柔軟で機能豊富なAPIの必要性が明らかになりました。これらのニーズに対応するために、Sparkコミュニティは大幅に改善されたtransformWithStateInPandas APIを導入しました。これはApache Spark™ 4.0で利用可能で、既存のapplyInPandasWithStateオペレーターを完全に置き換えることができます。transformWithStateInPandasは、柔軟なデータモデリングやステート、タイマー、ステートのTTL、オペレーターチェーン、スキーマ進化を定義するための複合型など、はるかに大きな機能を提供します。
このブログでは、Pythonに焦点を当て、transformWithStateInPandasと古いapplyInPandasWithState APIを比較し、transformWithStateInPandasがapplyInPandasWithStateができることを全て、そしてそれ以上に表現できる方法をコーディングの例を用いて示します。
このブログの最後まで読むと、transformWithStateInPandasをapplyInPandasWithStateよりも使用する利点、applyInPandasWithStateパイプラインをtransformWithStateInPandasパイプラインに書き換える方法、そしてtransformWithStateInPandasがApache Spark™のステートフルストリーミングアプリケーションの開発をどのようにシンプル化するかを理解できます。
applyInPandasWithStateの概要
applyInPandasWithStateは、Apache Spark™ Structured Streamingでストリーミングデータに対する任意のステートフルな操��作を可能にする強力なAPIです。このAPIは、カスタムステート管理ロジックを必要とするアプリケーションに特に有用です。applyInPandasWithStateは、ユーザーがキーでグループ化されたストリーミングデータを操作し、各グループにステートフル操作を適用することを可能にします。
ビジネスロジックの大部分は、次のタイプシグネチャを持つ func で行われます。
例えば、次の関数は各キーの値の数を逐次的に数えます。この関数が単一責任の原則を破っていることに注意が必要です:新しいデータが到着したときと、状態がタイムアウトしたときの両方を処理する責任があります。
以下に完全な実装例を示します:
transformWithStateInPandasの概要
transformWithStateInPandasは、Apache Spark™ 4.0で導入された新しいカスタムステートフル処理オペレーターです。applyInPandasWithStateと比較して、そのAPIはよりオブジェクト指向で、柔軟性があり、機能が豊富です。その操作は、型シグネチャを持つ関数ではなく、StatefulProcessorを拡張するオブジェクトを使用して定義されます。transformWithStateInPandasは、実装する必要がある内容のより具体的な定義を提供することで、コードを理解しやすくします。
このクラスには5つの主要なメソッドがあります:
init: これは、変換のための変数などを初期化するセットアップメソッドです。handleInitialState: このオプションのステップでは、初期状態のデータでパイプラインを事前に準備することができます。handleInputRows:これは、データの行を処理するコアステージです。handleExpiredTimers:このステージでは、期限切れのタイマーを管理することができます。これは、時間ベースのイベントを追跡する必要があるステートフルな操作にとって重要です。close: このステージでは、変換が終了する前に必要なクリーンアップタスクを実行できます。
このクラスでは、同等のフルーツカウント演算子が以下に示されています。
そして、以下のようにストリーミングパイプラインで実装することができます:
ステートとの作業
ステートの数とタイプ
applyInPandasWithStateとtransformWithStateInPandasは、ステートの取り扱い能力と柔軟性の点で異なります。applyInPandasWithStateは単一のステート変数のみをサポートし、これはGroupStateとして管理されます。これにより、シンプルなステート管理が可能になりますが、ステートを単一値のデータ構造とタイプに制限します。対照的に、transformWithStateInPandasはより多機能で、異なるタイプの複数のステート変数を許可します。transformWithStateInPandasのValueStateタイプ(applyInPandasWithStateのGroupStateに相当)に加えて、ListStateとMapStateをサポートし、より大きな柔軟性を提供し、より複雑なステートフルな操作を可能にします。transformWithStateInPandasのこれら追加のステートタイプはパフォーマンスの利点ももたらします:ListStateとMapStateは、全てのステート構造を毎回シリアライズとデシリアライズすることなく部分的な更新を許可します。これは特に、大規模または複雑なステートにおいて、処理効率を大幅に向上させます。
applyInPandasWithState | transformWithStateInPandas | |
|---|---|---|
| ステートオブジェクトの数 | 1 | 多数 |
| ステートオブジェクトの種類 | GroupState(ValueStateと同様) | ValueStateListStateMapState |
CRUD操作
比較のため、applyInPandasWithStateのGroupStateとtransformWithStateInPandasのValueStateのみを比較します。なぜなら、ListStateとMapStateは同等のものがないからです。状態を扱う際の最大の違いは、applyInPandasWithStateでは状態が関数に渡されるのに対し、transformWithStateInPandasでは各状態変数をクラスで宣言し、init関数でインスタンス化する必要があることです。これにより、状態の作成/設定がより詳細になりますが、より設定可能になります。状態を扱う際の他のCRUD操作はほとんど変わりません。
GroupState (applyInPandasWithState) | ValueState(transformWithStateInPandas) | |
|---|---|---|
| 作成 | 状態の作成は暗黙的に行われます。状態はstate variableを通じて関数に渡されます。 | self._stateはクラスのインスタンス変数です。宣言とインスタンス化が必要です。 |
def func(
key: _,
pdf_iter: _,
state: GroupState
) -> Iterator[pandas.DataFrame]
| class MySP(StatefulProcessor):
def init(self, handle: StatefulProcessorHandle) -> None:
self._state= handle.getValueState("state",schema)
| |
| 読み込み | state.get #または PySparkValueErrorを引き起こす state.getOption #または Noneを返す | self._state.get()# または None を返す |
| 更新 | state.update(v) | self._state.update(v) |
| 削除 | state.remove() | self._state.clear() |
| 存在する | state.exists | self._state.exists() |
この新しいAPIが可能にするいくつかの機能について少し詳しく見てみましょう。今では可能になりました
- 1つ以上の状態オブジェクトを操作すること、そして
- 生存時間(TTL)を持つステートオブジェクトを作成します。これは、規制要件を持つユースケースに特に有用です。
applyInPandasWithState | transformWithStateInPandas | |
|---|---|---|
| 複数のステートオブジェクトを扱う | 不可能 | class MySP(StatefulProcessor):
def init(self, handle: StatefulProcessorHandle) -> None:
self._state1= handle.getValueState("state1",schema1)
self._state2= handle.getValueState("state2",schema2)
|
| TTLを持つステートオブジェクトを作成する | 不可能 | class MySP(StatefulProcessor):
def init(self, handle: StatefulProcessorHandle) -> None:
self._state= handle.getValueState(state_name="state",
schema="c LONG",
ttl_duration_ms=30 * 60 * 1000 # 30分
)
|
内部ステートの読み取り
状態を持つ操作のデバッグは、クエリの内部状態を調査するのが難しかったため、以前は困難でした。applyInPandasWithStateとtransformWithStateInPandasの両方は、ステートデータソースリーダーとシームレスに統合することでこれを容易にします。この強力な機能により、ユーザーが特定の状態変数をクエリすることを可能にし、他の多くのサポートオプションとともに、トラブルシューティングを大幅に簡単にします。
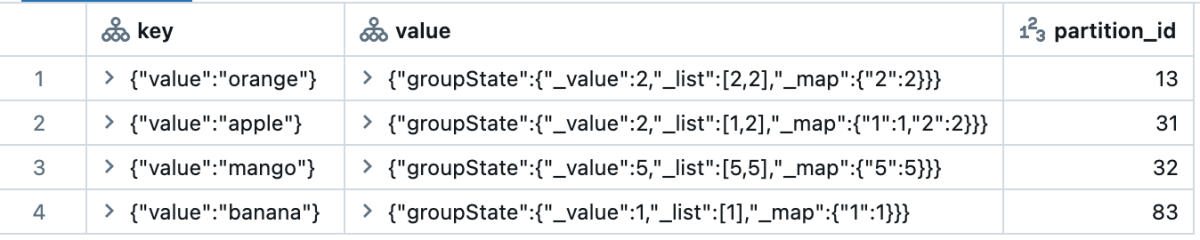
以下は、各ステートタイプがクエリされたときに表示される例です。partition_idを除くすべての列はSTRUCT型であることに注意してください。applyInPandasWithStateでは、全体の状態が一つの行としてまとめられます。したがって、ユーザーは変数を分解して展開し、わかりやすい内訳を得る必要があります。transformWithStateInPandasは、各状態変数のより良い分解を提供し、各要素はすでに簡単なデータ探索のために自身の行に展開しています。
| オペレーター | 状態ク��ラス | ステートストアを読み込む |
|---|---|---|
applyInPandasWithState | GroupState | display(
spark.read.format("statestore").load("/Volumes/foo/bar/baz")
)
 |
transformWithStateInPandas | ValueState | display(
spark.read.format("statestore").option("stateVarName","valueState")
.load("/Volumes/foo/bar/baz")
)
 |
ListState | display(
spark.read.format("statestore").option("stateVarName","listState")
.load("/Volumes/foo/bar/baz")
)
 | |
MapState | display(
spark.read.format("statestore").option("stateVarName","mapState")
.load("/Volumes/foo/bar/baz")
)
 |
初期ステートの設定
applyInPandasWithStateは、パイプラインに初期ステートをシードする方法を提供していません。これにより、新しいパイプラインがバックフィルされないため、パイプラインの移行が非常に困難になりました。一方、transformWithStateInPandasには、これを容易にするメソッドがあります。handleInitialStateクラス関数を使用すると、ユーザーは初期ステートの設定などをカスタマイズできます。例えば、ユーザーはhandleInitialStateを使用してタイマーを設定することもできます。
applyInPandasWithState | transformWithStateInPandas | |
|---|---|---|
| 初期ステートの入力 | 不可能 | .transformWithStateInPandas(
MySP(),
"fruit STRING, count LONG",
"append",
"processingtime",
grouped_df
)
|
| 初期ステートのカスタマイズ | 不可能 | class MySP(StatefulProcessor):
def init(self, handle: StatefulProcessorHandle) -> None:
self._state= handle.getValueState("countState","count LONG")
self.handle = handle
def handleInitialState(
self,
key: Tuple[str],
initialState: pd.DataFrame,
timerValues: TimerValues
) -> None:
self._state.update((initialState.at[0,"count"],))
self.handle.registerTimer(timerValues.getCurrentProcessingTimeInMs()+ 10000
)
|
したがって、applyInPandasWithStateパイプラインをtransformWithStateInPandasに移行することに興味がある場合、ステートリーダーを使用して古いパイプラインの内部ステートを新しいものに移行することが簡単にできます。
スキーマ進化:
スキーマ進化は、データ処理を中断することなくデータ構造を変更することを可能にするため、ストリーミングデータパイプラインの管理において重要な側面です。
applyInPandasWithStateでは、クエリが開始されると、ステートスキーマの変更は許可されません。applyInPandasWithStateは、保存されたスキーマとアクティブなスキーマの間の等価性を確認することでスキーマの互換性を検証します。ユーザーがスキーマを変更しようとすると、例外がスローされ、クエリが失敗します。その結果、変更はユーザーが手動で管理する必要があります。
顧客は通常、2つの回避策のいずれかを使用します:新しいチェックポイントディレクトリからクエリを開始してステートを再処理するか、JSONやAvroのような形式を使用してステートスキーマをラップし、スキーマを明示的に管理します。これらのアプローチのどちらも、実際には特に好まれていません。
一方、transformWithStateInPandasは、スキーマ進化に対してより堅牢なサポートを提供します。ユーザーは単にパイプラインを更新するだけで、スキーマの変更が互換性がある限り、Apache Spark™は自動的にデータを新しいスキーマに検出し移行します。クエリは同じチェックポイントディレクトリから続行でき、ステートを再構築し、最初からすべてのデータを再処理する必要がなくなります。APIは、新しいステート変数の定義、古いものの削除、既存のものの更新をコード変更だけで可能にします。
まとめると、transformWithStateInPandasのスキーマ進化のサポートは、長期間稼働するストリーミングパイプラインのメンテナンスを大幅に簡素化します。
| スキーマの変更 | applyInPandasWithState | transformWithStateInPandas |
|---|---|---|
| 列の追加(ネストされた列を含む) | サポートされていません | サポートされています |
| 列(ネストされた列を含む)を削除する | サポートされていません | サポートされています |
| 列の並べ替え | サポートされていません | サポートされています |
| 型の拡大(例えば、Int → Long) | サポートされていません | サポートされています |
ストリーミングデータの操作
applyInPandasWithStateは、新しいデータが到着したとき、またはタイマーが発火したときにトリガーされる単一の関数を持っています。関数の呼び出しの理由を決定するのはユーザーの責任です。新しいストリーミングデータが到着したかどうかを判断する方法は、ステートがタイムアウトしていないことを確認することです。したがって、タイムアウトを正しく処理するための別のコードブランチを含めることがベストプラクティスであり、そうしないとあなたのコードはタイムアウトと正しく動作しないリスクがあります。
対照的に、transformWithStateInPandasは、異なるイベントに対��して異なる関数を使用します:
handleInputRowsは、新しいストリーミングデータが到着したときに呼び出されます。handleExpiredTimerはタイマーがオフになったときに呼び出されます。
その結果、追加のチェックは必要ありません。APIがこれを管理します。
applyInPandasWithState | transformWithStateInPandas | |
|---|---|---|
| 新しいデータの取り扱い | def func(key, rows, state):
if not state.hasTimedOut:...
| class MySP(StatefulProcessor):
def handleInputRows(self, key, rows, timerValues):
...
|
タイマーの扱い
タイマーとタイムアウト
transformWithStateInPandasはタイマーの概念を導入し、applyInPandasWithStateのタイムアウトよりも設定や理解が容易です。
タイムアウトは、特定の時間までに新しいデータが到着しない場合にのみトリガーされます。さらに、各applyInPandasWithStateキーはタイムアウトを1つだけ持つことができ、関数が実行されるたびにタイムアウトは自動的に削除されます。
対照的に、タイマーは例外なく特定の時間にトリガーします。各transformWithStateInPandasキーに対して複数のタイマーを持つことができ、指定された時間が来ると自動的に削除されます。
タイムアウト(applyInPandasWithState) | タイマー(transformWithStateInPandas) | |
|---|---|---|
| キーごとの数 | 1 | 多数 |
| トリガーイベント | もし時間xまでに新しいデータが到着しない場合 | 時刻xで |
| イベントの削除 | すべての関数呼び出しについて | 時刻xで |
これらの違いは微妙に見えるかもしれませんが、時間との作業を大幅に簡単にします。例えば、午前9時と午後5時にアクションをトリガーしたいとします。applyInPandasWithStateを使用すると、まず9時のタイムアウトを作成し、5時のものを後で状態に保存し、新しいデータが到着するたびにタイムアウトをリセットする必要があります。transformWithStateを使用すると、これは簡単です:2つのタイマーを登録し、それで完了です。
タイマーがオフになったことを検出する
applyInPandasWithStateでは、ステートとタイムアウトがGroupStateクラスで統一されているため、両者は別々に扱われません。関数の呼び出しがタイムアウトの期限切れか新しい入力のためかを判断するには、ユーザーは明示的にstate.hasTimedOutメソッドを呼び出し、それに応じてif/elseロジックを実装する必要があります。
transformWithStateを使用すると、これらの体操はもはや必要ありません。タイマーはステートから切り離され、互いに異なるものとして扱われます。タイマーが期限切れになると、システムはタイマーイベントの処理専用の別のメソッド、handleExpiredTimerをトリガーします。これにより、state.hasTimedOutかどうかを確認する必要がなくなります - システムがあなたの代わりにそれを行います。
applyInPandasWithState | transformWithStateInPandas | |
|---|---|---|
| タイマーはオフになりましたか? | def func(key, rows, state):
if state.hasTimedOut:# はい
...
else:
# いいえ
...
| クラス MySP(StatefulProcessor):
def handleExpiredTimer(self, key, expiredTimerInfo, timerValues):
when = expiredTimerInfo.getExpiryTimeInMs()...
|
イベント時間と処理時間でのCRUD
applyInPandasWithState APIの特異性は、処理時間とイベント時間に基づいてタイムアウトを設定するための別々の方法が存在することです。GroupStateTimeout.ProcessingTimeTimeoutを使用する場合、ユーザーはsetTimeoutDurationでタイムアウトを設定します。対照的に、EventTimeTimeoutの場合、ユーザーは代わりにsetTimeoutTimestampを呼び出します。一方の方法が機能すると、他方はエラーをスローします。逆もまた然りです。さらに、イベント時間と処理時間の両方について、タイムアウトを削除する唯一の方法は、そのステートも削除することです。
対照的に、transformWithStateInPandasはタイマー操作に対してより直接的なアプローチを提供します。そのAPIはイベント時間と処理時間の両方に対して一貫性があり、タイマーを作成(registerTimer)、読み取り(listTimers)、削除(deleteTimer)する方法を提供します。transformWithStateInPandasを使用すると、同じキーに対して複数のタイマーを作成することが可能で、これにより時間の様々なポイントでデータを発行する�ために必要なコードを大幅に簡素化します。
applyInPandasWithState | transformWithStateInPandas | |
|---|---|---|
| 作成する | state.setTimeoutTimestamp(tsMilli) | self.handle.registerTimer(tsMilli) |
| 多数作成 | 不可能 | self.handle.registerTimer(tsMilli_1)self.handle.registerTimer(tsMilli_2) |
| 読み込み | state.oldTimeoutTimestamp | self.handle.listTimers() |
| 更新 | state.setTimeoutTimestamp(tsMilli) # EventTime用 state.setTimeoutDuration(durationMilli)# ProcessingTime用 | self.handle.deleteTimer(oldTsMilli)self.handle.registerTimer(newTsMilli) |
| 削除 | state.remove() #しかし、これはタイムアウトと状態を削除します | self.handle.deleteTimer(oldTsMilli) |
複数のステートフルオペレーターの操作
単一のパイプライン内でステートフルオペレーターをチェーンすることは、伝統的に課題となってきました。applyInPandasWithStateオペレーターは、ユーザーがウォーターマークと関連付ける出力列を指定することを許可しません。その結果、ステートフルオペレーターはapplyInPandasWithStateオペレーターの後に配置することができません。その結果、ユーザーはステートフルな計算を複数のパイプラインに分割する必要があり、中間ストレージとしてKafkaや他のストレージレイヤーが必要となります。これはコストと遅延を増加させます。
対照的に、transformWithStateInPandasは他の状態を�持つ演算子と安全に連鎖することができます。ユーザーは、それをパイプラインに追加するときにイベント時間の列を指定するだけでよい、以下に示すように:
このアプローチでは、ウォーターマーク情報がダウンストリームのオペレーターに通過し、新しいパイプラインと中間ストレージを設定することなく、遅延レコードのフィルタリングとステートの排出を可能にします。
まとめ
Apache Spark™ Structured Streamingの新しいtransformWithStateInPandasオペレーターは、古いapplyInPandasWithStateオペレーターに比べて大きな利点を提供します。これは、より大きな柔軟性、強化されたステート管理機能、そしてよりユーザーフレンドリーなAPIを提供します。複数のステートオブジェクト、ステート検査、カスタマイズ可能なタイマーなどの機能を備えたtransformWithStateInPandasは、複雑なステートフルストリーミングアプリケーションの開発を簡素化します。
applyInPandasWithStateは経験豊富なユーザーにとってはまだ馴染みがあるかもしれませんが、transformWithStateの改善された機能と多様性は、現代のストリーミングワークロードにとってより良い選択となります。transformWithStateInPandasを採用することで、開発者はより効率的で保守性の高いストリーミングパイプラインを作成することができます。Apache Spark™ 4.0で自分自身で試してみてください、そしてDatabricks Runtime 16.2以上。
| 特徴量 | applyInPandasWithState (State v1) | transformWithStateInPandas (State v2) |
|---|---|---|
| サポートされている言語 | Scala、Java、Python | Scala、Java、Python |
| 処理モデル | 関数ベース | オブジェクト指向 |
| 入力処理 | グルーピングキーごとの入力行の処理 | グルーピングキーごとの入力行の処理 |
| 出力処理 | 必要に応じて出力を生成できます | 必要に応じて出力を生成できます |
| サポートされている時間モード | 処理時間&イベント時間 | 処理時間&イベント時間 |
| きめ細かなステートモデリング | サポートされていません(単一の状態オブジェクトのみが渡されます) | サポートされています(ユーザーは必要に応じて任意のステート変数を作成できます) |
| 複合型 | サポートされていません | サポートされています(現在、Value、List、Mapタイプをサポートしています) |
| タイマー | サポートされていません | サポートされています |
| ステートクリーンアップ | 手動 | ステートTTLのサポートを備えた自動化 |
| ステートの初期化 | 部分的なサポート(Scalaでのみ利用可能) | すべての言語でサポートされています |
| イベントタイムモードでのオペレータのチェーン化 | サポートされていません | サポートされています |
| 状態データソースリーダーサポート | サポートされています | サポートされています |
| 状態モデルの進化 | サポートされていません | サポートされています |
| 状態スキーマ進化 | サポートされていません | サポートされています |
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。