天の川のインジェスト:Zerobus Ingestによるペタバイトスケール
テーブルあたり12 GB/sを実現するアーキテクチャの徹底解説 — そして無限の可能性へ
によって アレクサンダー・トミッチ, ヴィクトリア・ブクタ, Nikola Obradović, Danilo Najkov, Branko Grbić 、 Milos Milovanovic による投稿
- Databricks Zerobus Ingestは、手動でのインフラ管理を行うことなく、ペタバイト規模のデータパイプラインを即座にデプロイできるサーバーレスのストリーミングAPIです。
- Zerobusのアーキテクチャは動的パーティショニングを活用してコンピュートリソースを自動的にスケーリングし、複雑なチューニングを行うことなく、予測不可能なデータ量を効率的に処理します。
- このセットアップ不要のフレームワークは大規模なワークロードを容易に処理し、24時間のベンチマークテストにおいて、単一のテーブルに対して12 GB/s以上のスループットを維持できる性能を実証しています。
テレメトリデータはあらゆる場所に存在します。工場の製造現場にあるIoTセンサー、大気をスキャンする人工衛星アレイ、毎秒数千ものイベントを記録する自動運転車などです。これらのシステムすべてに共通する根本的な課題があります。それは、クエリ可能な場所に格納する必要がある、継続的で大容量の時系列データのストリームです。高速で信頼性が高く、Kafkaベースのワークロードにありがちな、インフラのチューニングやメンテナンスにエンジニアリングチームが何週間も費やす必要がないものである必要があります。
それこそが、Zerobus Ingestが解決するために構築された課題です。Zerobusは、Databricksのフルマネージドでサーバーレスなストリーミング取り込みサービスです。任意のプロデューサーからのデータを受け入れ、Unity Catalogによって管理されるDeltaテーブルに直接書き込む、プッシュベースのAPIです。
- プロビジョニングするインフラは不要。
- 維持管理するコネクタパイプラインは不要。
- パーティションやブローカーの意思決定は不要。
代わりに、テーブルを作成してデータをプッシュするだけです。データはレイクハウスに格納され、数秒でクエリ可能な状態になります。送信先がレイクハウスであれば、パイプとしてKafkaを実行する必要はもうありません。
私たちは、11年間にわたる2,000億のデータポイントを表すNASAのNEOWISEデータセットを使用してZerobus Ingestのベンチマークを行い、事前の設定なしで、安定したレイテンシで24時間未満に1ペタバイトを取り込みました。
24時間以内に1PBを取り込むことで、単一のテーブルに対して12 GB/sの継続的なスループットを維持するZerobusの能力を実証しました。🚀
ペタバイトスケールを今すぐ実現:天の川のストリーミング(12GB/秒/テーブル)
ベンチマークをご自身で実行する方法の詳細については、Databricksコミュニティのこちらの関連ブログをお読みください。
このブログ記事では、これを可能にした3つの設計上の決定事項について説明します。
- 動的パーティショニングによって自動スケーリングするシステムの設計。
- 独自のゼロコピーprotobufデコーダーの構築。
- データがレイクハウスに公開される前に、レイテンシが最適化されたライトアヘッドログを実装。
主な設計上の決定事項
私たちの目標は、ペタバイトスケールをサポートし、変動する取り込みパターンに対応するために自動スケーリングできるストリーミングシステムを構築することでした。
従来のストリーミングアーキテクチャでは、特定のワークロードに必要なブローカーとパーティションの数を決定する必要があります。これには、ピーク時の負荷やコンシューマーの取り込み制限に関する知識だけでなく、予測やエンドツーエンドのパイプラインに対する理解も必要になります。
第一原理に立ち返ることで、データプロデューサー向けにペタバイト規模のワークロードを処理できるように「魔法のように」スケールするシステムを設計・構築しました。
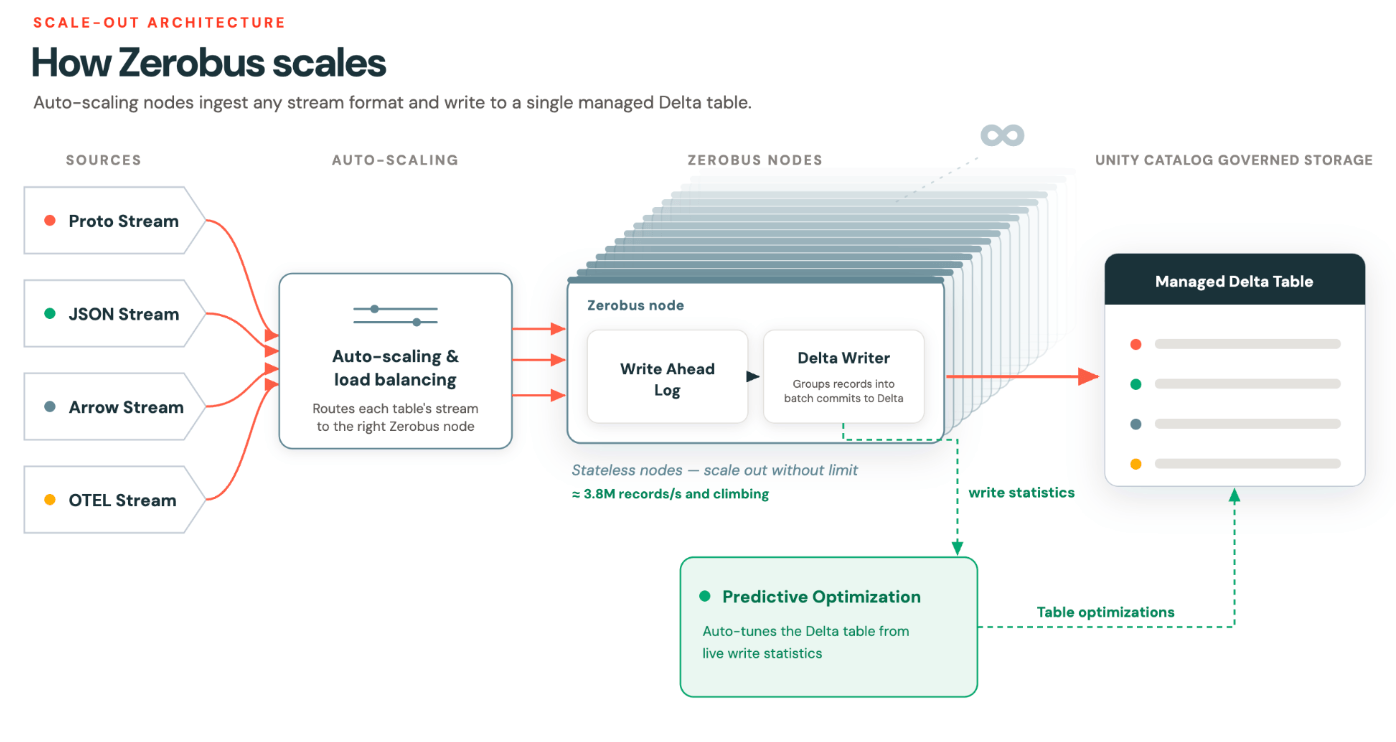
動的パーティショニングによる自動スケーリングの実現
私たちが解決しようとしていた課題は、弾力的な「制限のない」スケーリングを実現するために、いかに効率的な自動スケーリングを行うかということでした。
私たちの仮説は、静的パーティショニングから脱却し、ストリーム/接続という論理単位に移行することで、コンシューマーのワークロードにとって重要な順序保証を維持しながら、真の自動スケーリングとリバランスを実現できる��というものでした。
静的パーティショニングの課題
メッセージバスアーキテクチャにおいて、パーティションは並列処理と順序性の両方の単位です。この結合は、それに依存するコンシューマーが存在する場合、厄介な制約となります。
順序性は通常、プロデューサー単位ではなく、パーティション単位で保証されます。パーティションの数と、それらへのデータの分散状況は、コンシューマーが取り込みに追従できる能力に影響します。つまり、以下のようなことを意味します。
- パーティション数が変更されると、プロデューサーのメッセージをパーティションにマッピングするルーティング関数が、メッセージを別のパーティションに送信する可能性があります。コンシューマーはこれを調整する必要があります。
- 実際、ほとんどのチームはパーティショントポロジを不変のものとして扱います。ピーク時の負荷に合わせてプロビジョニングし、そのインフラを永続的に維持します。パーティションを追加することはできますが、通常、安全に削減することはできません。
- 標準的な回避策は、メッセージ内のフィールドから派生したパーティションルーティングキーを使用することです。これは順序の一貫性には役立ちますが、スケールダウンの課題は解決しません。
順序保証をストリーム接続に移行
従来のシステムでは、順序性はパーティションレベルの保証です。Zerobus Ingestでは、順序性はストリーム接続レベルの保証です。
プロデューサーがZerobusでストリーム(サーバーへの接続)を開くと、サービスに論理的なアイデンティティを登録することになります。その接続の存続期間中、どの「パーティション」ポッドが処理するかに関係なく、データは順序通りに到着します。
「パーティションが順序付けされている」のではなく、「ストリームが順序付けされている」。それが契約です。
ホットルーティングと真の自動スケーリング
内部的に、Zerobus Ingestはポッドのプール全体にストリームを分散します。ルーティングはヒューリスティックに基づいており、ポッドの負荷が高くなると、新しく入ってくるストリームは別のポッドにルーティングされます。プロデューサーはそれを意識することはありません。順序保証が影響を受けることもありません。
順序性はストリームレベルで維持されるため、急激な需要増に対応してポッドを追加し、需要が低下したときに削除することができます。既存のストリームは正常にドレイン(排出)され、新しいストリームはそこへのルーティングを停止します。その後プールが縮小し、コンピュート使用率を効率的に維持します。
これが真の自動スケーリングです。粒度の単位はパーティションの割り当てではなく、ストリーム接続です。
動的パーティショニングの設計により、Zerobusはコスト効率を維持しながら、テーブルに対して毎秒12GBを超えるスループットまで自動スケーリングできます。
ゼロコピーの高性能データ処理
Zerobusの主な目標は、あらゆる量のデータストリームを効率的に行単位で転送できるようにすることです。これを実現するには、クライアントがZerobusに送信する入力フォーマットから、耐久性を保証する内部フォーマット、そしてオープンなDeltaフォーマットに至るまで、不要なコピーやメモリ割り当てを完全に排除する必要がありました。
Zerobusは現在、以下のメッセージフォーマットをサポートしています。
数ある最適化の中でも、独自のprotobufデコーダーであるZeroParserを通じたゼロコピーのアプローチについて説明します。
標準的なprotobufデコーダーでは、速度か柔軟性のどちらかを選択せざるを得ません。通常、protobufデコーダーは、ビルド時のコード生成(codegen)またはランタイムのリフレクションのいずれかに依存しています。
- コード生成は高速ですが、コンパイル時に記述子が必要です。Zerobusは、任意のユーザー・スキーマから実行時に動的に記述子を受け取るため、コード生成は選択肢になりません。
- ランタイムリフレクションは柔軟性の問題を解決しますが、パフォーマンスの問題を引き起こします。動的なprotobufデコーダーは低速であり、実行時にメモリ内にオブジェクトグラフを構築する必要があるため、小さなメモリ割り当てが多数発生します。
どちらのアプローチも受け入れられませんでした。コード生成と同等のパフォーマンスプロファイルを持つ、動的な記述子のサポートが必要でした。
その結果、私たちはzeroparserを構築しました。メモリ割り当てゼロのシングルパスパースを使用することでこのギャップを埋め、動的な記述子や複雑なスキーマを使用した場合でも、CPUコアあたり約1 GB/sのprotobufパースのスループットを維持できるようにしました。
Zeroparserは、受信オブジェクトを分解することなく、ワイヤーフォーマットを直接パースできるため、メモリのコピーや割り当てが発生しません。このアプローチにより、Zerobusは、動的なprotobuf記述子の提供という完全な柔軟性を維持しながら、既存のコード生成によるprotobufパースソリューションよりも優れたパフォーマンスを実現できます。
RustのライフタイムシステムはZeroparserの設計の中核をなしています。プロトコルのパース中にコンパイル時の安全性を保証すると同時に、生のワイヤーバイトをネットワークの排他的な所有権下に置くことで、不要なデータのコピーを排除します。
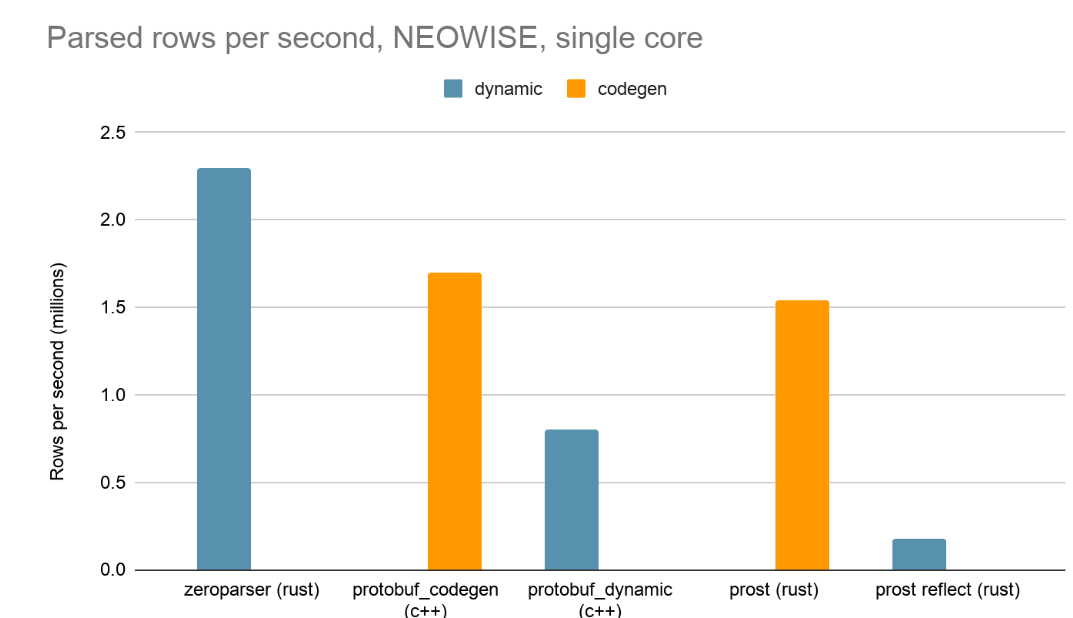
結果は、Zeroparserが動的グループに属しているにもかかわらず、業界標準である2つのコード生成ベースの実装を上回るパフォーマンスを示したことを表しています。
Zeroparserは、こちらから入手可能なZerobus SDKの一部としてオープンソース化されています。
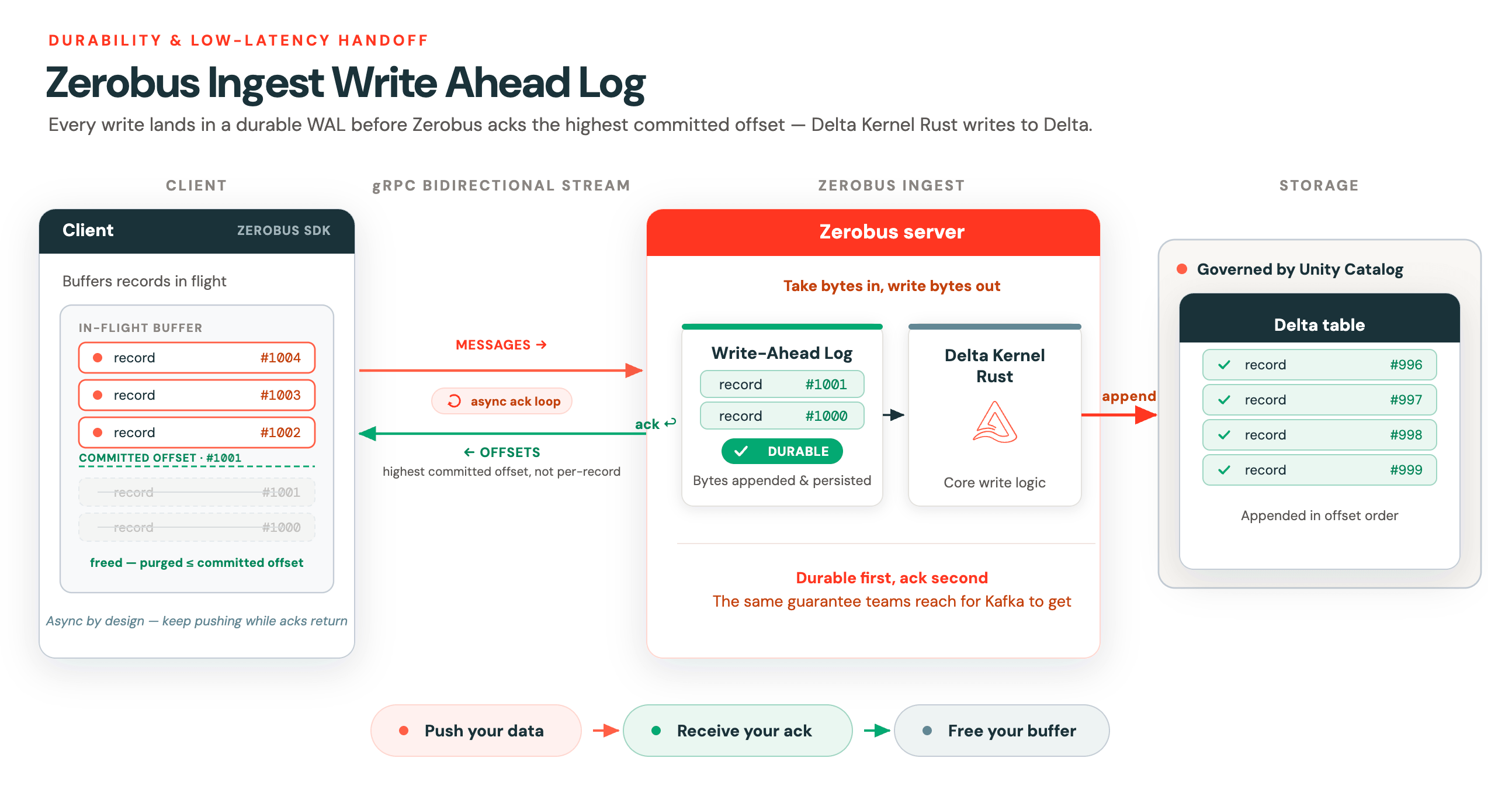
ライトアヘッドログ
ストリーミングとは、単に高スループットのワークロードを処理できることだけではありません。真のストリーミングサービスであるためには、メッセージのハンドオフを可能な限り迅速にサポートする必要もあります。このデータハンドオフの低レイテンシこそが、ストリーミングワークロードをバッチと真に区別するものです。
永続性を保証しながらこの低レイテンシのハンドオフをサポートするため、Zerobusはレイテンシが最適化されたライトアヘッドログ(WAL)を実装しています。メッセージの永続性が確保されると、Zerobusはクライアントに確認応答(ack)を返します。サーバーは、すべてのレコードを個別に確認するのではなく、ストリーム上のコミットされた最高のオフセットを返します。その結果、この非同期ackループが実現します。その後、Deltaへの書き込みのコアロジックにDelta Kernel Rustが使用されます。
この非同期�設計は、インフライトデータをバッファリングするクライアントにとって重要です。ZerobusはgRPCの双方向ストリーミングを使用しており、各Zerobusストリームには2つの通信回線があります。
- 1つはメッセージ送信用
- もう1つはオフセット確認応答の受信用
クライアントはそのオフセットを受信すると、ローカルのインフライトバッファからその時点までのすべてのデータを安全にパージできます。これはすべて、Zerobus SDKによって自動的に処理されます。
WALはクライアントを軽量に保つためのものです。データをプッシュし、ackを受信し、バッファを解放します。この低レイテンシで高耐久性のハンドオフこそが、開発チームがKafkaを採用する理由であり続けてきました。Zerobusも同様の保証を提供します。
実証:天の川銀河のインジェスト
システムのベンチマークを行う鍵は、本番環境でどのように使用されるかを理解し、その動作と使用状況をエミュレートすることにあります。そのため、Zerobus Ingestに負荷をかけるにあたり、NASAのNEOWISEデータセットを選択し、Locustを使用し��て現実世界のファンインパターンをエミュレートすることにしました。
なぜLocustなのか?ファンインの問題
Zerobus Ingestは、多数の独立したプロデューサーからのストリームを単一の宛先テーブルに集約するように構築されています。そのスループットは、同時に開いているストリームの数に応じてスケールします。つまり、単一のマシンや小規模なクラスターからでは、公平に負荷をかけることはできません。単一の強力なホストでは、当社のサービスに十分な負荷をかける前に、自身の帯域幅やCPUが飽和してしまい、Zerobusではなくプロデューサーのベンチマークになってしまいます。
現実世界のファンインパターンをシミュレートするため、Locustを使用してポッドごとに個別のストリームを開くように調整し、大規模なインジェストの負荷テストを行います。
その後、Zerobusのオートスケーリングがストリーム数とスループットに対応し、インジェストレートを処理します。
テスト構成
ベンチマークは、1つのLocustマスターと、それぞれ個別のポッドとして実行される複数のLocustワーカーを使用してKubernetes上にデプロイされました。主なパラメータは以下の通りです。
各ワーカーは、取り込むための固有のParquetファイルのリストを受け取ります。ワーカーはそのスライスをストリーミングし、行を重複して処理することはありません。
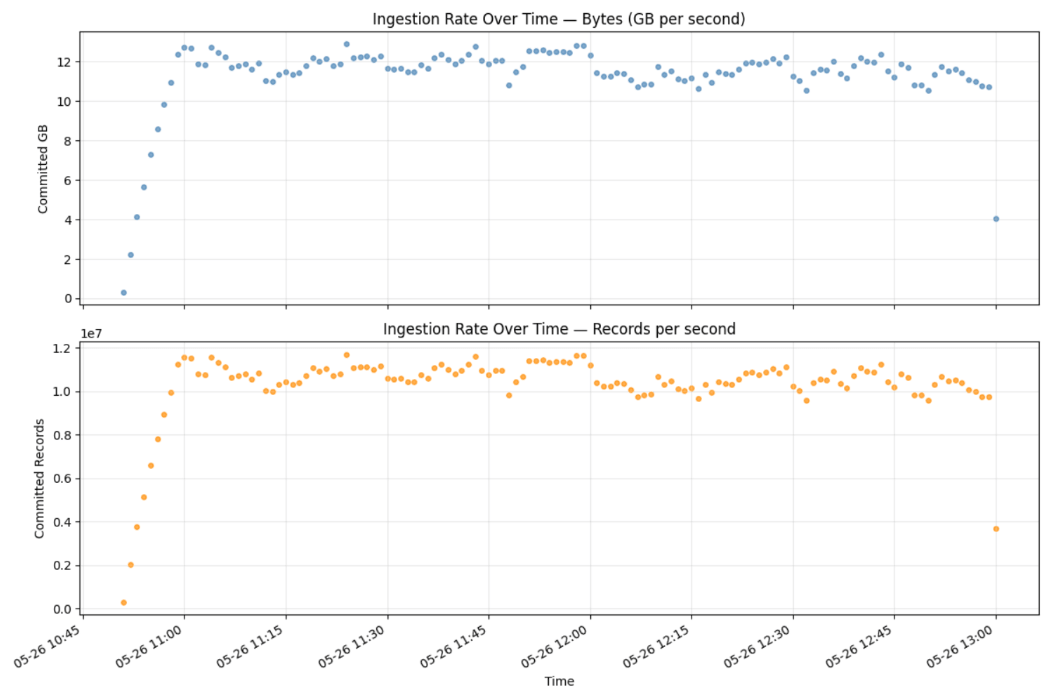
結果
テスト結果から、Zerobus Ingestは、2,048の同時実行ワーカーから単一のテーブルに対して、24時間にわたり12 GB/秒の速度を維持できることが示されました。この期間中、Zerobusは1兆を超えるレコードを取り込みました。
client_ts_ms列を5秒ごとのバケットで集計することで、コミットされた行数と受信したバイト数の、サーバーで確認された正確なビューが得られます:
このクエリは、稼働中のUnity Catalogテーブルに対して実行されます。数値は、Deltaストレージに完全にコミットされた行を反映しています。
ご自身で実行してみませんか?
データセットの準備、プロデューサーコード、および独自のZerobusエンドポイントに対して実行するための手順が含まれた、完全なベンチマークハーネスです。こちらからご確認ください。
今後の予定
Zerobus IngestがDatabricksで一般提供(GA)開始となり、すべての本番ワークロードでご利用いただけるようになりました。
テーブルへの12GB/sというパフォーマンスメトリックは、Zerobus Ingestで標準で得られるものです。クォータの拡張をご希望の場合は、アカウントチームまでお問い合わせください。
ロードマップ:
- Kafka Producer APIのサポート
- MQTT APIのサポート
- レスキュー列
- システムメタデータ列
- Avroのサポート
Zerobusの今後の展開について、皆様のご意見をお聞かせください!ストリーミングの次のフロンティアは何だと思いますか?Databricksコミュニティのブログにコメントをお寄せください。
Zerobus Ingestを始める準備ができたら、技術ドキュメントやZerobus Ingest SDKを参照するか、NeowiseベンチマークのGitHubリポジトリをご確認ください。
(このブログ記事はAI翻訳ツールを使用して翻訳されています) 原文記事
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。