コンテキスト内学習のための超高速LLM評価
によって ジェレミー・ドーマン による投稿
MosaicMLを使えば、LLMをコンテキスト内学習タスク(LAMBADA、HellaSwag、PIQAなど)で、他の評価ハーネスよりも何百倍も速く評価することができます。 LAMBADAは、70Bのパラメータモデルに対して、64台のA100 GPUでわずか100秒で評価でき、256台のNVIDIA A100 GPUを使用した場合、1兆2,000億のパラメータモデルの評価に12分もかかりません。
大規模言語モデル(LLM)をトレーニングする際、その性能を評価する一般的な方法は、コンテキスト内学習(ICL)タスクを使用することです。 これらのタスクでは、モデルの重みを更新することなく、LLMが文を完成させたり、自然言語で出された質問に答えたりする必要があります。 モデルは、タスクが何であるかを推測し、タスクがどのように機能するかを理解し、新しい例にどのように適用するかを決定しなければなりません。これらはすべて、プロンプトに含まれる文脈上の手がかりを使用することによって行われます。 例えば、あるモデルが次のように英語からスペイン語に翻訳するよう求められ、次の単語"perro"を予測するよう期待されるかもしれません。
LLMにとってICLの評価が厄介なのは、一般的に評価に使われる単純な損失関数とは異なる、多様な評価技術が必要になるからです。 例えば、クロスエントロピーのような伝統的なMLメトリクスは、PyTorchライブラリ関数を呼び出すだけで実行できますが、LAMBADA精度のようなICLメトリクスは、より複雑な一連のステップに依存します、継続に対応する出力ロジットインデックスのサブセットを選択し、最も可能性の高いロジットがすべてのインデックスで正しいトークンと一致することを検証することを含みます。
(PIQAやHellaSwagなどで使用されている)多肢選択精度のような他のICLメトリクスは、さらに複雑な一連のステップを必要とします:すべての質問と答えの選択肢のペアでモデル出力を計算し、答えに対応する出力インデックスのサブセットで当惑度を計算し、質問ごとにグループ化し、最も低い当惑度の答えが正しい選択肢に対応する頻度を決定します。
このブログポストでは、EleutherAI/lm-evaluation-harnessという業界標準のICL評価コードベースをベースラインとしたICL評価方法を用いて、多様なICLタスクをサポートします。 このコードベースは使いやすく便利で、膨大な種類のICLタスクをサポートしていますが、すべてのタスクに対して単一のコードパスを使用するため、効率を向上させる余地があります。また、マルチ GPU データ並列処理もFSDPモデル シャーディングもデフォルトでサポートしていません。
最新のComposerリリース(0.12.1)では、言語モデリングの効率を改善しました。 LAMBADAや質問応答(例:PIQA)のICLタスクを実行し、シングルA100 GPUで7.45倍のスピードアップを実現しました。 また、ComposerのネイティブなマルチGPU推論サポートとFSDPモデルシャーディングを使用して、GPU数に応じて実行時間をリニアにスケーリングし、1.2Tパラメータを超えるモデルサイズをサポートします。
どのようにしてこのような大幅なスピードアップを実現したのかを説明するために、3つの重要な機能を掘り下げてみました:
- まず、マルチGPU推論がデバイス数に対して線形に評価を高速化し、評価時間を数時間から数秒に短縮する方法を示します。
- 次に、Composerがトレーニング実行中にICLの評価メトリクスをライブログに記録する方法を示します。
- 最後に、ComposerのFSDPの統合によって、ユーザビリティを犠牲にすることなく、大規模なモデル(256GPUで1.2T以上のパラメータ!)を評価できるようになったことを紹介します。
Composerによる高速マルチGPU評価
私たちのComposerベースのICL評価コードは、マルチGPUアクセラレーションとFSDP(データ並列+パラメータシャーディング)ですぐに動作します。 データ並列では、GPUの数を2倍にすれば、評価の実行時間は半分になります。 また、パラメータシャーディングを使えば、1台のマシンに収まりきらないほど大きなモデルを評価することができます。
私たちの実装の性能を測定するために、GPT-Neo 125M、1.3B、および2.7Bを、一般的に使用される2つのICLベンチマーク:LAMBADAと PIQAで評価しました。 LAMBADA言語モデリングタスクは、インターネット上で独立に出版された書籍のデータセットから抽出された複数文節の最後の単語を予測するモデルを必要とします。 LAMBADAテストセットの5,153例で評価しました。
PIQAデータセットは、物理的な状況に関するモデルの直感を問う多肢選択式のテストです。 1,838問の多肢選択問題で構成され、物理的なゴールと2つの潜在的なソリューションが記述されています。 言語モデルの多肢選択問題に対する解答能力を調べるには、複数の手法があります。 私たちが採用した方法は、それぞれの質問と答えのペアをモデルを通して実行し、モデルが単語あたりの平均当惑度をより高くした答えを決定することです。
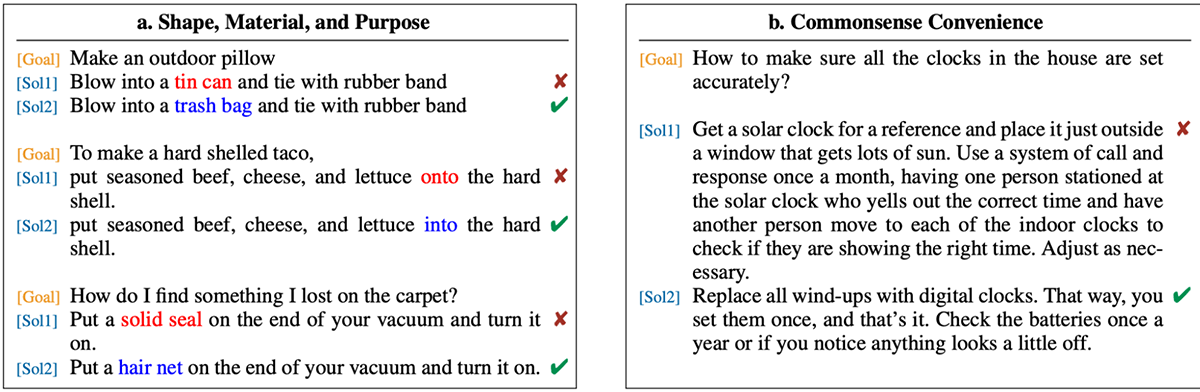
HuggingFaceからダウンロードしたGPT-Neo 125M、1.3B、および2.7Bパラメータモデルを、1、8、16、32、64、128、および256のA100-40GB GPUで事前にトレーニン��グした上で、ComposerベースのICL evalの実行時間を測定しました。 ベースラインとしてEleutherAI/lm-evaluation-harnessを使用しました。
図2を見てわかるように、LAMBADAタスクとPIQAタスクの両方で、私たちの結果はほぼ完璧な線形スケーリングを示しています。 GPUの数を2倍にすると、実行時間は半分になります。 256GPU以上では測定していませんが、ほぼ完璧な線形スケーリングは今後も続くと思われます。
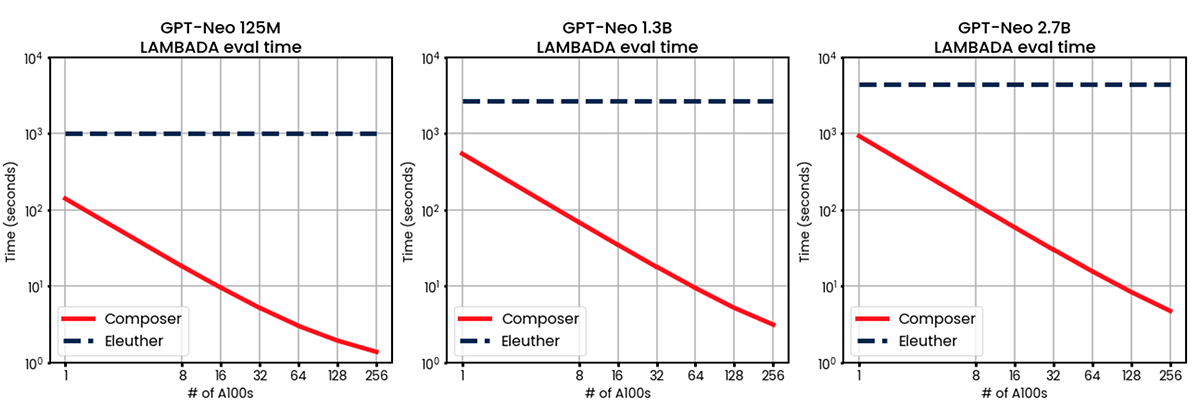
下の表では、GPT-Neo 125Mの場合、256GPUでLAMBADAの評価時間がベースラインの約16分から1.38秒に短縮されたことがわかります。これは760倍の高速化です。この高速化の一部は複数のGPUによるものであり、一部は高速なICL実装によるものです。私たちのセットアップでは、Python のリスト演算を PyTorch テンソル演算に置き換え、すべてのテンソルをオンに保つことにより、1 GPU で LAMBADA と PIQA が 7.45 倍の高速化を示しています。
トレーニング中のICLライブ測定
今日の大規模言語モデルは、通常、一度に何百ものGPUで数日から数週間かけて学習されます。 もちろん、トレーニング中に中間評価の結果が見られるとよいでしょう。 ただし、パフォーマンスは重要です。評価のためのマルチGPUサポートがなければ、1つのGPUがすべての作業を行い、残りのGPUは何分も何時間もアイドル状態になってしまいます。 シングルGPUで評価を実行している場合、最小の125Mパラメータモデルでも1評価あたり最大16分待たされる可能性があり、70Bパラメータ・モデルでは>100時間にまで膨れ上がります。
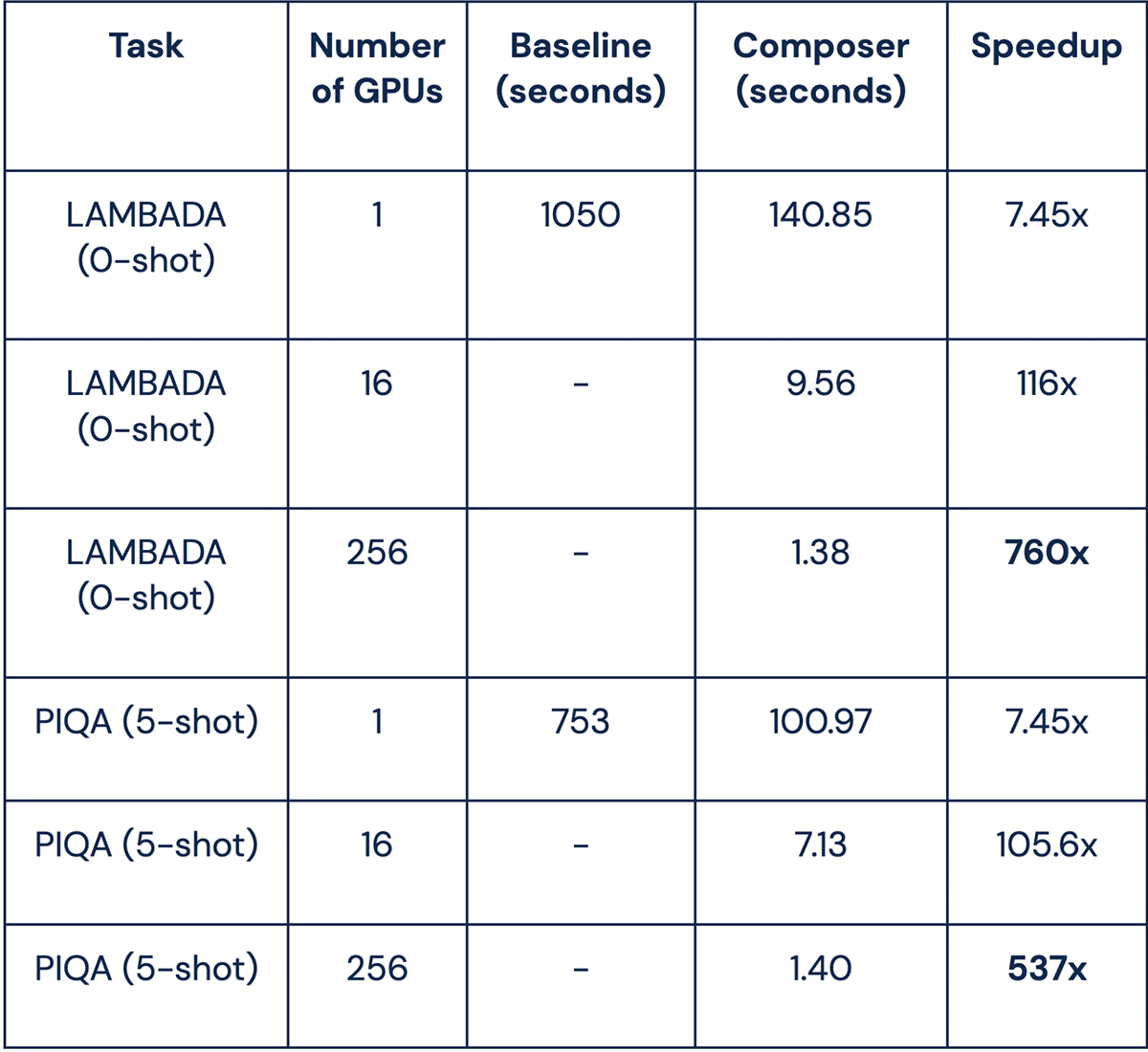
当社のComposer ICL評価器を使用することで、マルチGPUトレーニング実行中にICL評価を実行し、すべてのGPUで並列化することが可能になりました。 図Xに示すように、GPU8台でGPT-1Bパラメータモデルを学習し、最小限のオーバーヘッドで25バッチごとにモデルのLAMBADAスコアを評価することができました。 Composerでは、Weights and Biases、CometML、Tensorboardのような実験トラッカーで、このキーとなるメトリクスが時間とともにどのように進�化していくかを見ることができます。
巨大モデルの評価
上記で説明したように、マルチGPUトレーニング実行中にライブICL メトリクスを評価することが可能になり、大規模なクラスターで実行する場合、全体的な評価時間を大幅に短縮できます。 小さなモデルスケールでは、この並列化は便利ですが、1つのデバイスに収めるには大きすぎるモデルについては、ComposerのFSDPモデルシャーディングの統合を使用します。 FSDPでは、モデルの重みはすべてのデバイスでシャードされ、必要に応じてレイヤーごとに収集されます。 これにより、各デバイスのメモリではなく、クラスタの合計メモリによってのみ制限される、LLMのような大規模なモデルを評価できるようになります。
64GPUの場合、評価時間はモデルサイズに完全に比例し、70Bのパラメータで2分未満、450Bのパラメータで12分でした。 64GPUを使用することで、並列化されていないベースラインのハーネスが125Mのパラメータモデルを評価するよりも速く450Bのモデルを評価することができます。
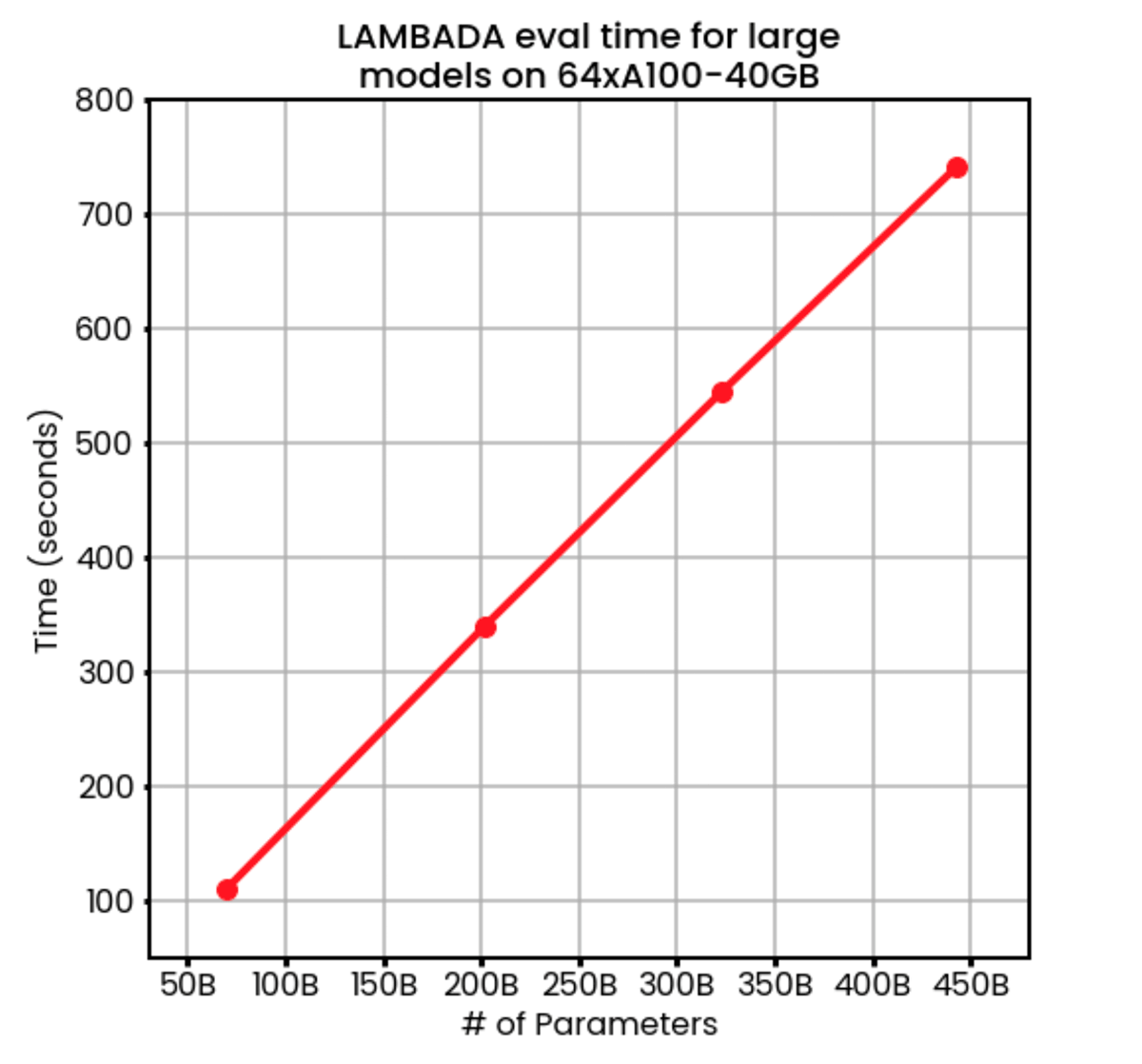
しかし、私たちはそこに留まらず、ついに256GPUの研究クラスターの限界に挑戦することにしたのです。 FSDP + Composer ICL evalにより、LAMBADAを1.2Tのパラメータモデルでわずか12分で評価することができました!
次のステップ
Composer ICL評価フレームワークがComposer v.0.12.1で利用可能になりました。 私たちのコードは、言語モデリング形式でも多肢選択テスト形式でも、ユーザーが提供するICLデータセットを受け入れるように設定されています。次にどのような機能を実装するかについてのコミュニティからのフィードバック(Slackに参加してください!)を歓迎します。
始める準備はできていますか?最新のComposerライブラリをダウンロードするか、MosaicMLプラットフォームのデモをリクエストしてください。 また、ツイッターをフォローし、ニュースレターを購読して、最新ニュースをチェックしてください。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。