M Scienceはオルタナティブデータを実用的な洞察に変える
によって ベン・トールマン 、 スペンサー・マーシャル による投稿
機関投資家が利用できるデータセットは何千とあり、それぞれのデータセットが投資の意思決定において重要な洞察を解き明かすと期待されています。 何千ものデータセットと、それらの多くの潜在的なアプリケーション全体にわたって、多くの異なるスキーマ、バイアス、長所、欠点があります。 これらのデータセットを選択し、テストし、プロダクション化することは重要な仕事です。 最終的に投資家が求めているのは、データそのものではなく、データから得られる洞察です。
M Science社の使命は、オルタナティブ(代替)データに基づき、投資家の皆様に実用的な洞察を提供することです。 利用可能なデータを検討し、多くのデータをテストして有効性を判断し、企業のKPIを最も予測できるものを選択します。 このように厳選されたオルタナティブデータを使用し、書面調査、ダッシュボード、データフィードを通じてデータやデータ由来の製品を提供しています。
私たちは20年以上前、純粋にデータ駆動型の最初のリサーチプロバイダーとして、この使命を開始しました。 2000年代初頭、オルタナティブデータの状況は異なっており、利用可能なオルタナティブデータセットはほとんどありませんでした。 世界のデジタル化が進むにつれて、私たちのデータ資産もデジタル化してきました。 M Scienceは、匿名化された消費者取引データを使用した最初の調査会社であり、その後、デジタル購買、ウェブトラフィック、テクノグラフィック、その他さまざまな種類のデータを製品に取り入れるように進化してきました。
スケーリングによる製品の改善
タイムリーに商品をお届けすることで、お客様のパフォーマンスを向上させることができます。もしお客様がより早く洞察を得ることができれば、お客様はより早く投資仮説を立て、より早く取引を実行することができます。 M Scienceがクラウドネイティブになる前は、オンプレミスのインフラでノイジーネイバー(うるさい隣人)の問題に頻繁に遭遇していました。 データ資産がインフラよりも急速に増加していたのです。 しかし、より柔軟でスケーラブルなソリューションが必要であることは明らかでした。
私たちのクラウド移行では、クラウドインフラの管理ではなく、データからインサイトを生み出すことに集中したかったのです。 そのため、M Scienceは早くからDatabricksと提携していました(実際、私たちはDatabricksの最初の顧客の1社でした!)、 当時、Databricksは主にクラウド管理とApache Spark™実装のためのソリューションでした。 クラウド管理やSparkの実装でDatabricksを愛用していることに変わりはありませんが、Databricksの機能セットが初期の機能をはるかに超えて拡張されたことをさらに嬉しく思っています。
6年前、M Scienceのオフィスに足を踏み入れると、オンプレミスのサーバーでクエリを実行する優先順位をめぐって物々交換するチームの声が聞こえてきたかもしれません。 今日、AWSリソースをどのようにスケールダウンさせるかについて、ジョブのPhoton化を通して議論しているチームがあります。 このシフトはお客様にもメリットがあり、当社のリサーチ製品はこれまで以上にタイムリーなものとなりました。 Databricksのスケーリングにより、お客様のために製品を改善することができました。
よりシンプルなデータセット
各リサーチ製品に複数のデータセットがあることは、非常に価値があります。KPI予測に確信を持ち、新しい業界をカバーし、より多くの角度から企業を調査することができます。 しかし、一般的にデータが増えるということは、それだけ複雑になるということです。
私たちは常に、チームが複雑さを取り除き、洞察の生成に集中できるようにしたいと考えており、それがレイクハウス・アーキテクチャに移行した理由です。 Unity Catalogをレイヤー化することで、すべてのデータを一枚のガラスに収め、不要なコピーを減らし、適切なレベルのきめ細かなアクセス制御を実現しています。 この組織により、データの幅を広げつつ、俊敏性を維持することができます。
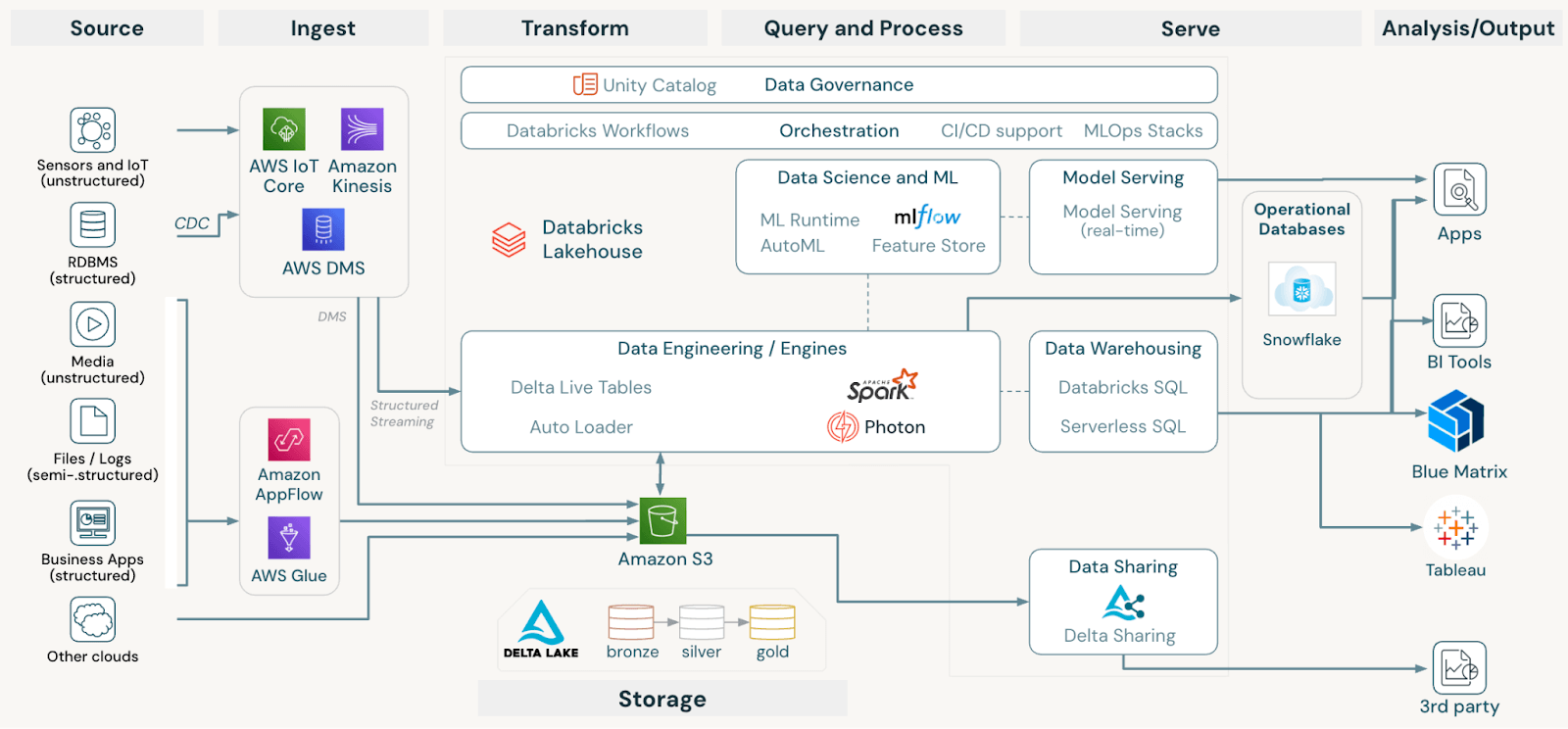
Unity Catalogは、当社の膨大な(そして増え続ける)データリソースを整理し、お客様に最高のサービスを提供するのに役立ちます。
次のステップ:Databricksのテクノロジーを活用し、お客様に最高の製品を提供する
過去20年にわたり、私たちはデータ、データ知識、データからの洞察の基盤を構築してきました。これらは、大規模な言語モデル��(LLM)を最適化する上で、M Scienceのユニークな位置づけとなっています。 私たちはDatabricksインフラストラクチャを使用して検索拡張生成(RAG)デザインパターンを展開し、ツールの微調整にDatabricksを使用しています。 Databricksの肩に立つことで、LLMベースのツールの実用性が急速に向上しています。
また、クリーンルームを含むDatabricksのガバナンスとプライバシーのツールを使って、Databricksのエコシステム全体で、企業がデータをコンプライアンスに従って収益化できるよう支援できることを非常に楽しみにしています。
私たちはデータイノベーションの最前線にいることを誇りに思っています。Databricksとの旅は、優れた頭脳が協力し合えば、可能性は無限に広がることを証明しています。 この強力なパートナーシップによるエキサイティングな最新情報にご期待ください。
Databricks Market Data Analyticsのバーチャルイベントに参加して、データ、アナリティクス、AIのためのデータ共有の障壁を減らす方法を学びましょう。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。