Unity Catalog を使用した Databricks 上のマシンラーニング:ベストプラクティス
によって Lu Wang による投稿
- Unity Catalogを使用して、データの前処理からモデルのトレーニングとデプロイまで、MLモデルをシームレスに構築しデ�プロイします。
- ロールベースのアクセス制御、グループクラスタ、ガバナンス機能を活用して、安全なコラボレーションを確保します。
- 専用グループクラスターとDelta Live Tablesを使用して計算リソースを最適化し、効率的なMLワークフローを実現します。
エンドツーエンドのAIまたはMLプラットフォームを構築するには、ストレージ、分析、ビジネスインテリジェンス(BI)ツール、MLモデルなど、データを分析しビジネス機能と学習を共有するための複数のレイヤーが必要となります。異なる箇所、異なるチームに対して一貫した効果的なガバナンスコントロールを展開することが課題です。
Unity Catalogは、データアクセス、セキュリティ、ラインエージを管理するために設計されたDatabricksの組み込み、集中化されたメタデータレイヤーです。これはまた、プラットフォーム内の検索と発見のための基盤としても機能します。Unity Catalogは、ロールベースのアクセス制御(RBAC)、監査トレイル、データマスキングなどの堅牢な機能を提供することで、チーム間の協力を促進します。これにより、生産性を阻害することなく、機密情報が保護されます。また、MLモデルのエンドツーエンドのライフサイクルをサポートします。
このガイドでは、マシンラーニングのユースケースやチーム間での計算リソースの共有において、ユニティカタログの使用方法についての包括的な概要とガイドラインを提供します。
このブログ投稿では、Databricksのユニティカタログの利点機能を活用したマシンラーニングのエンド��ツーエンドのライフサイクルをステップバイステップで説明します。
この記事の例では、米国内のCOVID-19ウイルスのケース数を日付ごとに記録したデータセットを使用し、追加の地理情報も含まれています。目標は、米国内で次の7日間にウイルスのケースがどれだけ発生するかを予測することです。
DatabricksでのMLの主要な特徴
Databricksは、Unity CatalogでのMLをより良くサポートするための複数の機能をリリースしました
- Databricks Runtime for Machine Learning(Databricks Runtime ML):最も一般的なMLとDLライブラリを含む、事前に構築された機械学習と深層学習のインフラストラクチャを持つクラスタの作成を自動化します。
- 専用グループクラスタ:専用アクセスモードを使用してグループに割り当てられたDatabricks Runtime ML計算リソースを作成します
- 微細なアクセス制御を持つ繊細なアクセスモード:専用アクセスモードでDatabricks Runtime ML上で実行されるクエリに微細なアクセス制御を可能にします。これはマテリアライズドビュー、ストリーミングテーブル、お�よび標準ビューをサポートします。
要件:
- ワークスペースはUnity Catalog用に有効化する必要があります。ワークスペースの管理者は、ドキュメントを確認して、Unity Catalog用のワークスペースを有効にする方法を確認できます。
- Databricks Runtime 15.4 LTS ML以上を使用する必要があります。
- ワークスペース管理者は、Previews UIを使用してCompute: Dedicated group clusters previewを有効にする必要があります。Databricks Previewsの管理を参照してください。
- ワークスペースがSecure Egress Gateway(SEG)を有効にしている場合、pypi.orgを許可されたドメインリストに追加する必要があります。サーバーレスの出口制御のためのネットワークポリシーの管理を参照してください。
グループを設定する
コラボレーションを有効にするためには、アカウント管理者またはワークスペース管理者がグループを設定する必要があります。
- 右上のユーザーアイコンをクリックし、設定をクリックします
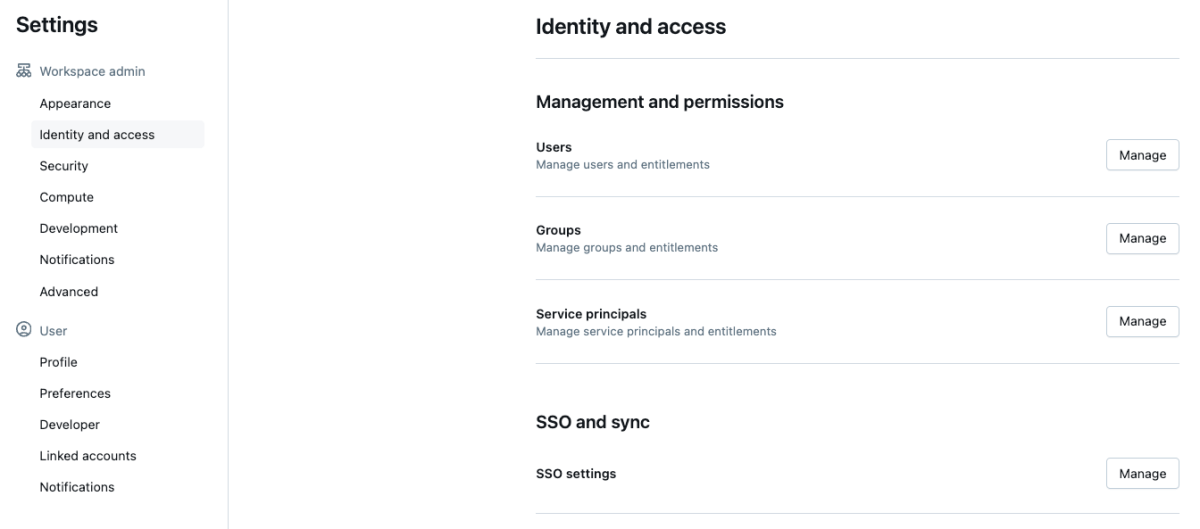
- 「ワークスペース管理」セクションで、「IDとアクセス」をクリックし、グループセクションで「管理」をクリックします
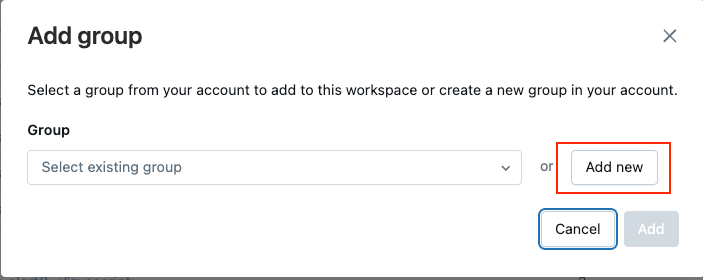
- 「グループを追加」をクリックします。

- 「新規追加」をクリックしてください
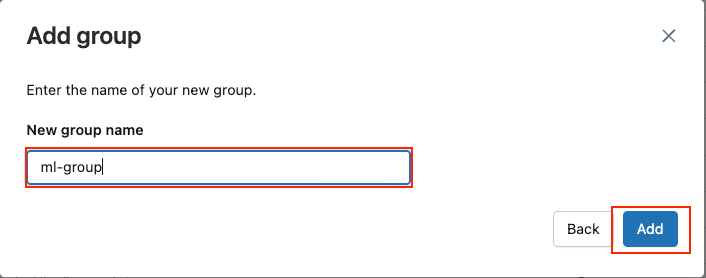
- グループ名を入力し、追加をクリックしてください
- 新しく作成したグループを検索し、ソース列が「アカウント」と表示されていることを確認してください。
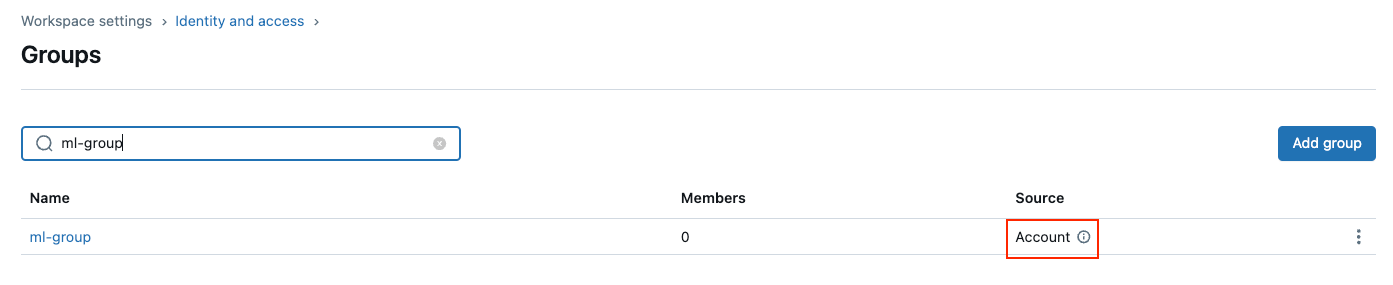
- 検索結果でグループの名前をクリックして、グループの詳細に移動します
- 「メンバー」タブをクリックし、希望のメンバーをグループに追加します
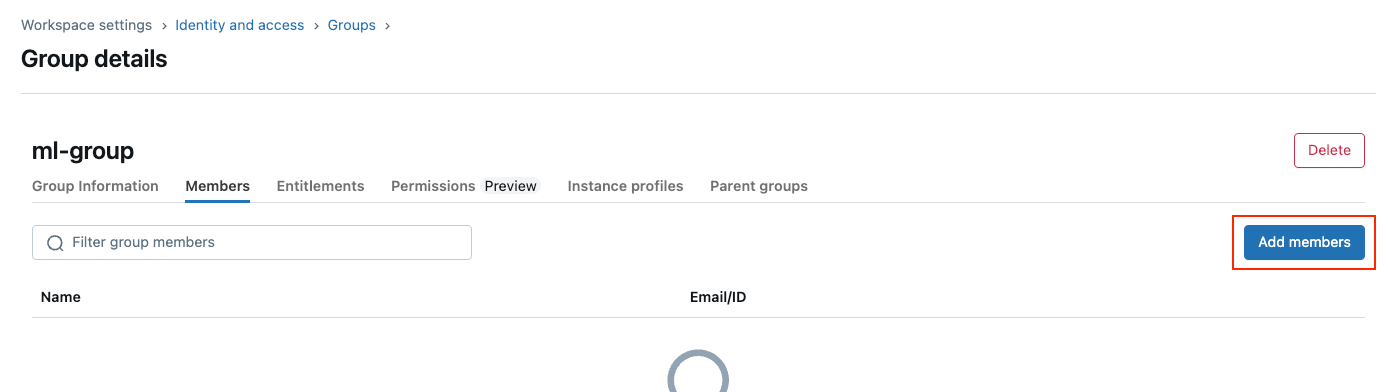
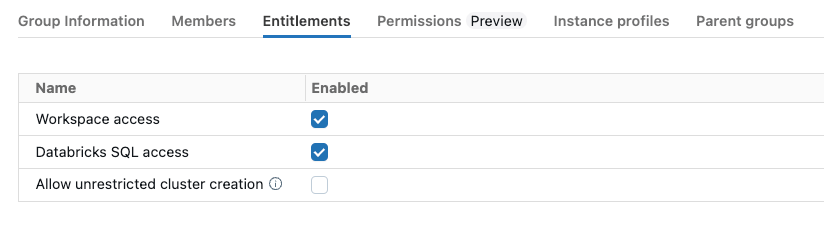
- 「権限」タブをクリックし、「ワークスペースアクセス」と「Databricks SQLアクセス」の両方の権限をチェックします
- 非管理者アカウントからグループを管理できるようにするには、「権限」タブでアカウントに「グループ:マネージャー」のアクセスを許可できます
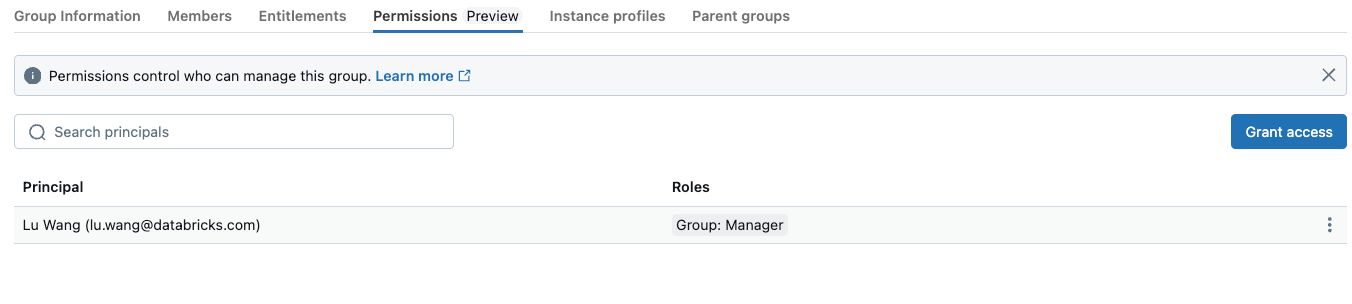
- 注意:グループクラスターを使用するには、ユーザーアカウントがグループのメンバーである必要があります - グループマネージャーであるだけでは不十分です。
専用グループクラスターを有効にする
専用グループクラスターは公開プレビュー中で、この機能を有効にするには、ワークスペースの管理者がプレビューUIを使用して機能を有効にする必要があります。
- Databricksワークスペースの上部バーでユーザー名をクリックします。
- メニューから「プレビュー」を選択します。
- Compute: Dedicated group clustersのトグルをオンにしてプレビューを有効または無効にします。

グループ計算を作成する
専用アクセスモードは、シングルユーザーアクセスモードの最新バージョンです。専用アクセスを使用すると、計算リソースを単一のユーザーまたはグループに割り当てることができ、割り当てられたユーザーのみが計算リソースを使用することができます。
MLを備えたDatabricksランタイムを作成するには
- Databricksのワークスペースで、Computeに移動し、Create computeをクリックします。

- パフォーマンスセクションで「機械学習」をチェックして、ML付きのDatabricksランタイムを選択します。Databricks Runtimeで“15.4 LTS”を選択します。必要に応じて、希望するインスタンスタイプとワーカーの数を選択します。
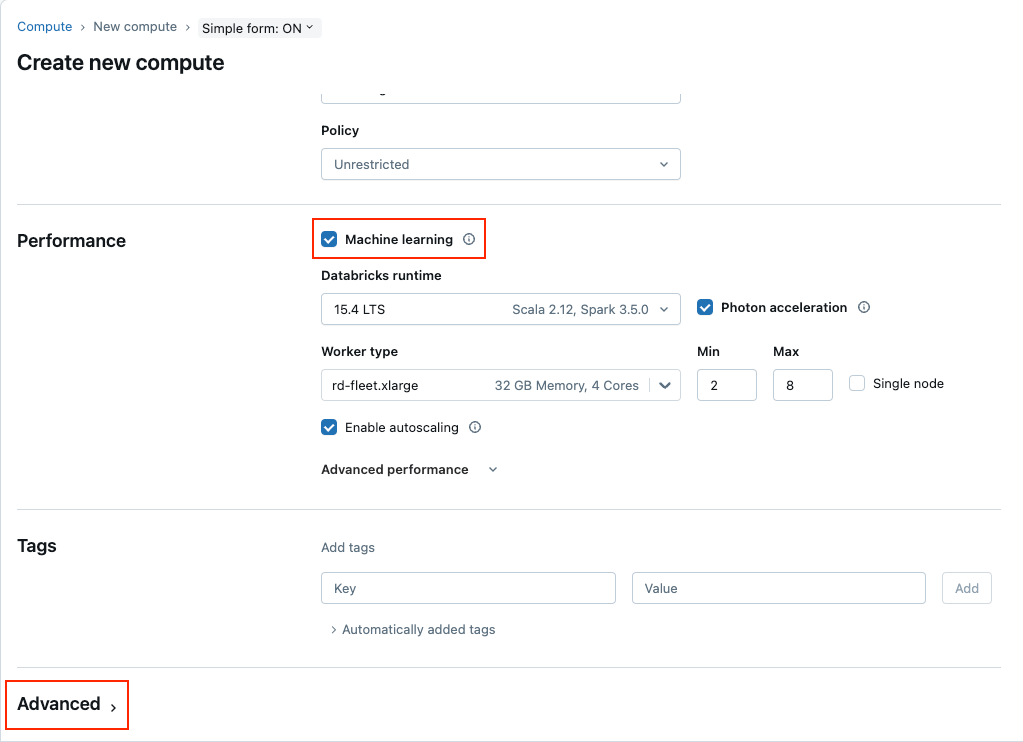
- ページの下部にあるAdvancedセクションを展開します。
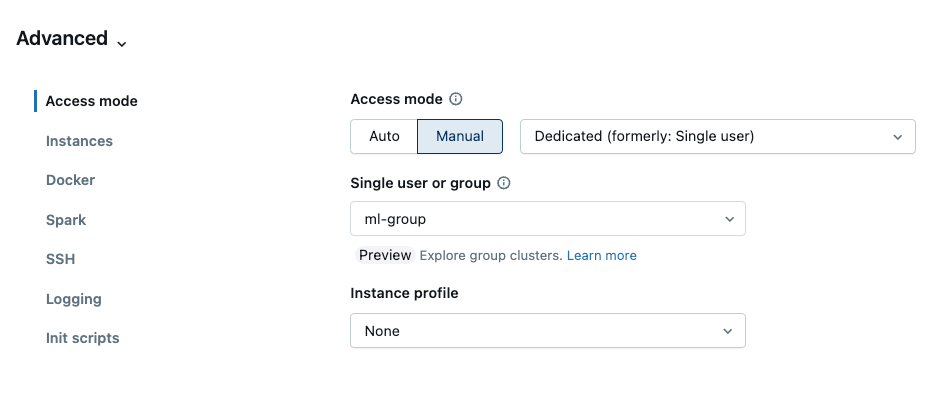
- Access modeの下で、Manualをクリックし、ドロップダウンメニューからDedicated(旧:Single-user)を選択します。
- シングルユーザーまたはグループフィールドで、このリソースに割り当てるグループを選択します。
- 必要に応じて他の計算設定を設定し、作成をクリックします。
クラスタが起動した後、グループ内のすべてのユーザーが同じクラスタを共有できます。詳細については、グループクラスタの管理に関するベストプラクティスを参照してください。
デルタライブテーブル(DLT)を介したデータ前処理
このセクションでは、私たちは
- 生のデータを読み込み、ボリュームに保存します
- インジェストテーブルからレコ�ードを読み取り、Delta Live Tablesの期待値を使用してクレンジングされたデータを含む新しいテーブルを作成します。
- クレンジングされたレコードをDelta Live Tablesのクエリの入力として使用し、派生データセットを作成します。
DLTパイプラインを設定するためには、以下の権限が必要かもしれません:
- 親カタログのためのCATALOG、BROWSEを使用します
- ターゲットスキーマに対するALL PRIVILEGESまたはUSE SCHEMA、CREATE MATERIALIZED VIEW、およびCREATE TABLEの権限
- ターゲットボリュームに対するALL PRIVILEGESまたはREAD VOLUMEおよびWRITE VOLUMEの権限
- ボリュームにデータをダウンロードする:この例では、Unity Catalogボリュームからデータをロードします。 <catalog-name>、<schema-name>、および<volume-name>をUnity Catalogボリュームのカタログ名、スキーマ名、ボリューム名に置き換えます。提供されたコードは、これらのオブジェクトが存在しない場合に指定されたスキーマとボリュームを作成しようとします。Unity Catalog内のオブジェクトを作成し、書き込むための適切な権限を持っている必要があります。要件をご覧ください。
- パイプラインを作成新しいパイプラインを設定するには、次の操作を行います:
- サイドバーで、Data EngineeringセクションのDelta Live Tablesをクリックします。
- パイプラインを作成をクリックします。

- パイプライン名に一意のパイプライン名を入力します。
- Serverlessチェックボックスを選択します。
- Destinationで、テーブルが公開されるUnity Catalogの場所を設定するには、CatalogとSchemaを選択します。
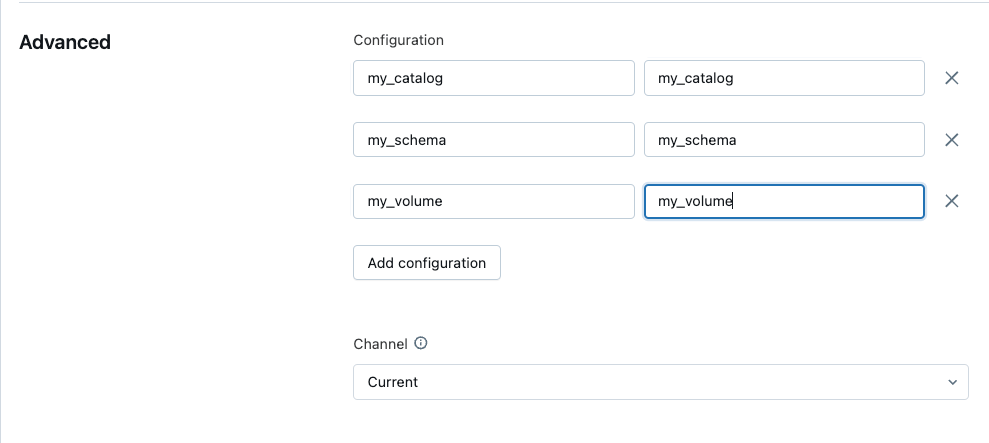
- 「詳細設定」で「設定を追加」をクリックし、次のパラメータ名を使用してカタログ、スキーマ、およびデータをダウンロードしたボリュームのパイプラインパラメータを定義します:
- my_catalog
- my_schema
- my_volume
- 「作成」をク��リックしてください。
新しいパイプラインのためのパイプラインUIが表示されます。パイプライン用のソースコードノートブックが自動的に作成され、設定されます。
- サイドバーで、Data EngineeringセクションのDelta Live Tablesをクリックします。
- マテリアライズドビューとストリーミングテーブルを宣言します。Databricksのノートブックを使用して、Delta Live Tablesパイプラインのソースコードを対話式に開発し、検証することができます。
- パイプライン詳細パネルのソースコードフィールドの下のリンクをクリックしてノートブックを開きます
- PythonまたはSQLでコードを開発します。詳細については、Pythonでパイプラインコードを開発するまたはSQLでパイプラインコードを開発するを参照してください。
- パイプライン詳細パネルのソースコードフィールドの下のリンクをクリックしてノートブックを開きます
- ノートブックの右上またはDLT UIのスタートボタンをクリックしてパイプラインの更新を開始します。DLTは、DLTが定義されたカタログとスキーマに生成されます
`<my_catalog>.<my_schema>`
DLTのマテリアライズドビューでのモデルトレーニング
DLTから生成されたマテリアライズドビュー上でサーバーレスの予測実験を開始します。
- サ��イドバーのMachine LearningセクションでExperimentsをクリックします
- 予測タイルで、トレーニングを開始を選択します
- 設定フォームに入力する
- トレーニングデータとしてマテリアライズドビューを選択します:
`<my_catalog>.<my_schema>.covid_case_by_date` - 時間列として日付を選択する
- Forecast frequencyでDaysを選択します
- ホライゾンに7を入力します
- 予測セクションのターゲット列でケースを選択します
- モデル登録を
`<my_catalog>.<my_schema>`として選択します
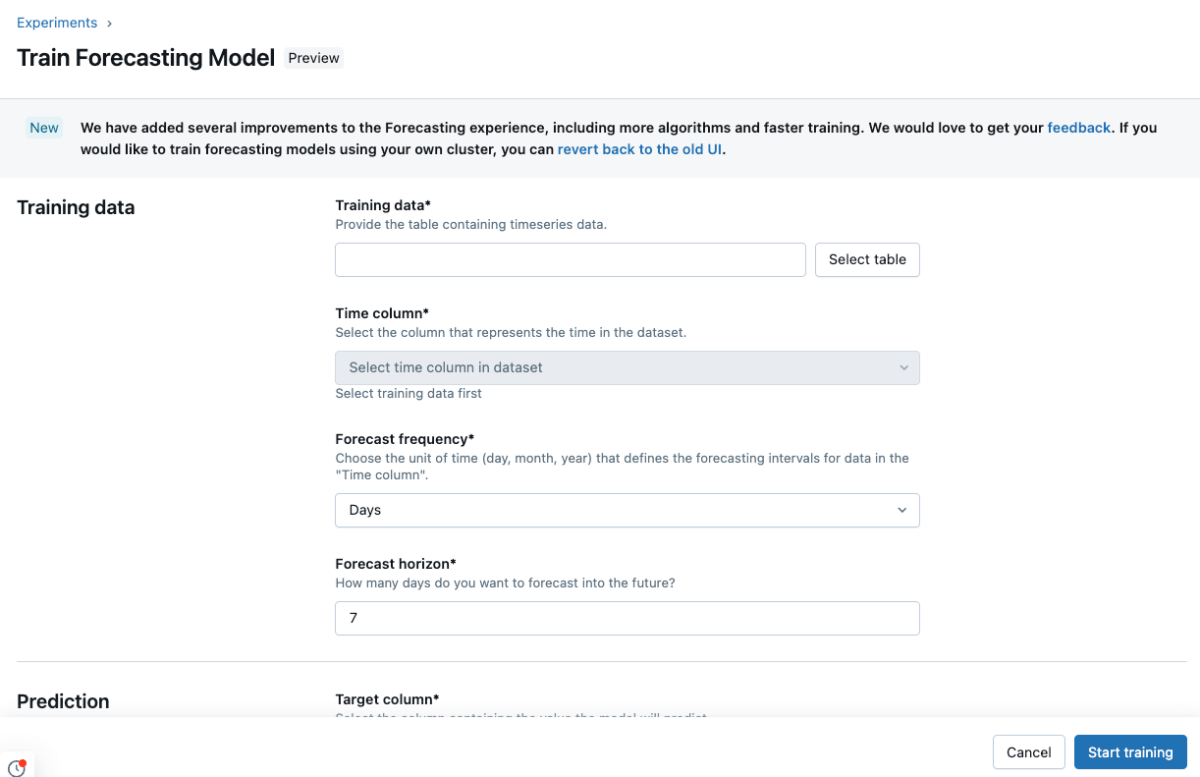
- トレーニングを開始をクリックして予測実験を開始します。
- トレーニングデータとしてマテリアライズドビューを選択します:
トレーニングが完了すると、予測結果は指定されたDeltaテーブルに保存され、最良のモデルがUnity Catalogに登録されます。
実験ページから、次のステップを選択します:
- 予測結果テーブルを見るために「View predictions」を選択します。
- Batch inference notebookを選択して、最良のモデルを使用したバッチ推論用の自動生成ノートブックを開きます。
- 最良のモデルをモデルサービングエンドポイントにデプロイするために、サービングエンドポイントを作成を選択します。
まとめ
このブログでは、データの前処理からモデルの訓練まで、Databricks上で予測モデルを設定し訓練するエンドツーエンドのプロセスを探求しました。ユニティカタログ、グループクラスタ、Delta Live Tables、AutoML予測を活用することで、モデル開発を効率化し、チーム間のコラボレーションを簡素化することができました。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。