MLOpsベストプラクティス - MLOpsジム: Crawl
再現性のあるMLワークフローの基盤作り
によって セピデ・エブラヒミ による投稿
- MLOpsはプロジェクトで��はなく旅であり、ツールや技術だけでなく、実践と組織的な行動を伴います。
- MLOpsに必要なツールには、MLflow、Unity Catalog、Feature Stores、そしてGitによるバージョン管理が含まれます。
- MLOpsのベストプラクティスには、クリーンなコードを書くこと、適切な開発環境を選択すること、AIシステムを監視することが含まれます。
はじめに
MLOpsは一度きりのプロジェクトではなく、継続的な旅です。それは、単なるツールや特定の技術スタックにとどまらず、実践と組織の行動に関わるものです。あなたのML(機械学習)チームがどのように協力し、AIシステムを構築するかは、結果の質に大きな影響を与えます。MLOpsのすべての詳細が重要です—コードの共有方法やインフラの設定、結果の説明方法に至るまで。これらの要素が、ビジネスにおけるAIシステムの効果に対する認識と、その予測を信頼する意欲を形作ります。
『The Big Book of MLOps』は、DatabricksにおけるMLOpsの高レベルな概念とアーキテクチャをカバーしています。これらの概念を実装するための実践的な詳細を提供するために、MLOps Gymシリーズを紹介しました。このシリーズでは、DatabricksでのMLOps実装に欠かせない重要なトピックを取り上げ、各トピックに対するベストプラクティスと洞察を提供します。シリーズは「Crawl(這う)」、「Walk(歩く)」、「Run(走る)」という3つのフェーズに分かれており、それぞれのフェーズは前のフェーズを基盤に構築されて�います。
『MLOps Gymの紹介:DatabricksでのMLOps実践ガイド』では、MLOps Gymシリーズの3つのフェーズ、その焦点、および具体的なコンテンツについて説明しています。
- 「Crawl」は、繰り返し可能なMLワークフローの基盤作りをカバーします。
- 「Walk」は、MLOpsプロセスにCI/CDを統合することに焦点を当てています。
- 「Run」は、MLOpsを厳密さと品質で引き上げることについて述べています。
この記事では、Crawlフェーズの記事を要約し、重要なポイントを取り上げます。たとえあなたの組織に既存のMLOpsの実践があっても、このCrawlシリーズは、MLOpsの特定の側面を改善するための詳細を提供するので役立つでしょう。
基盤を築く:ツールとフレームワーク
MLOpsは単なるツールの問題ではありませんが、選択するフレームワークはユーザー体験の質に大きな役割を果たします。私たちは、すべてのAIプロジェクトで再利用できる共通のインフラを提供することを推奨します。このセクションでは、Databricksで堅固なMLOpsのセットアップを確立するために必要なツールに関する推奨事項を共有します。
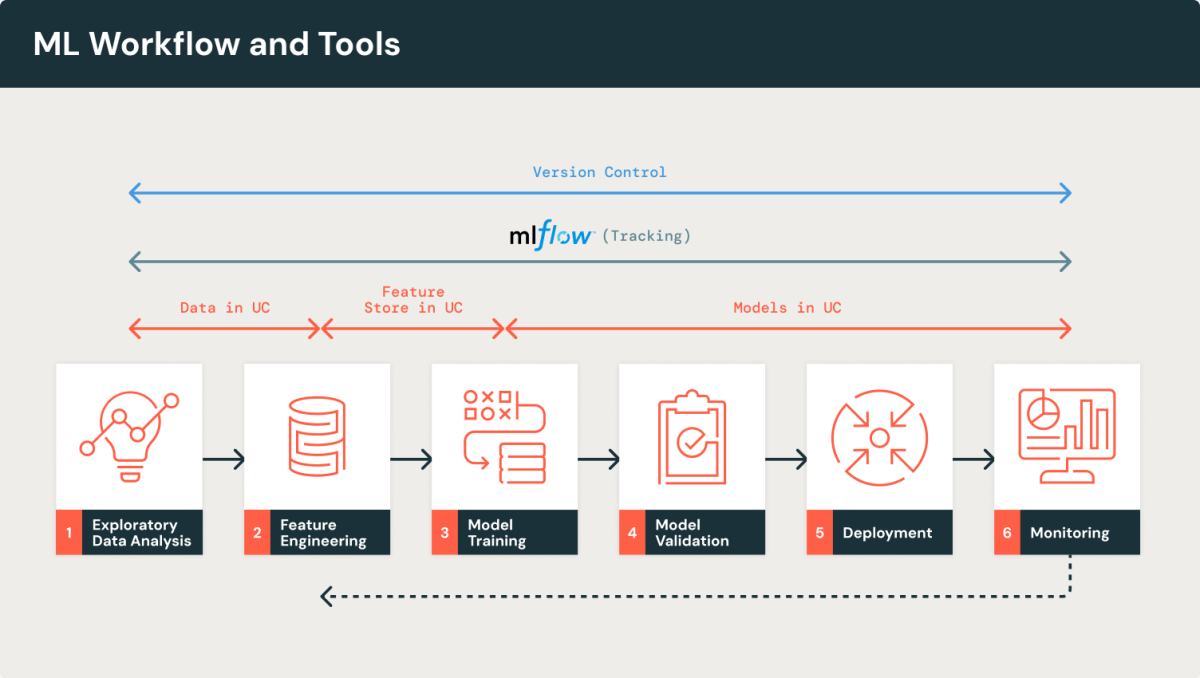
MLflow (トラッキングとUC内のモデル)
MLflowは、オープンソースのMLOpsツールとして非常に優れており、機械学習ライフサイクルへの統合を強く推奨します。その多様なコンポーネントにより、MLflowは機械学習の各段階で生産性を大幅に向上させます。『初心者向けガイド:MLflow』では、実験トラッキングのためにMLflow Trackingを使用し、モデルリポジトリ(Unity Catalog内のモデル)としてModel Registryを使用することを強く推奨しています。その後、初心者向けにMLflowを使ったステップバイステップのガイドを提供します。
Unity Catalog
Databricks Unity Catalogは、Databricks Data Intelligence Platform上でデータとML資産を管理・保護するための統一されたデータガバナンスソリューションです。MLOps用にUnity Catalogを設定すると、さまざまな組織構造や技術的環境にまたがる資産を管理するための柔軟で強力な方法を提供します。Unity Catalogの設計はさまざまなアーキテクチャに対応しており、外部ツール(例:AWS SageMakerやAzureML)からの直接的なデータアクセスを、外部テーブルやボリュームを戦略的に使用することで可能にします。これにより、チーム構造、ビジネスコンテキスト、環境の範囲に合わせてビジネス資産を組織化でき、大規模で高度に分割された組織や、隔離が最小限の小規模な組織にもスケーラブルな解決策を提供します。さらに、最小特権の原則に従い、BROWSE��権限を活用することで、ユーザーのニーズに合わせたアクセスが確実に調整され、セキュリティを高めながら発見可能性を損なうことなくアクセスを管理できます。この設定により、MLOpsワークフローが効率化され、無許可のアクセスから守られるため、Unity Catalogは現代のデータおよび機械学習操作において欠かせないツールとなります。
特徴量ストア(Feature Store)
Feature Storeは、機械学習における特徴量エンジニアリングのプロセスを効率化するための集中型リポジトリであり、データサイエンティストがチーム間で特徴量を発見、共有、再利用できるようにします。これにより、モデルのトレーニングと推論時に同じコードを使用して特徴量を計算することで一貫性が確保されます。DatabricksのFeature Storeは、Unity Catalogと統合されており、統一された権限管理、データの系統追跡、モデルのスコアリングおよび提供とのシームレスな統合といった強化機能を提供します。オンラインデータストアと同期してリアルタイム推論を行うことで、時系列やイベントベースのユースケースを含む複雑な機械学習ワークフローにも対応します。
Databricks Feature Storeのパート1では、機械学習ワークロードにおいてDatabricks Feature Storeを効果的に使用するための重要なステップを解説します。
MLOpsのためのバージョン管理
データサイエンスにおいてバージョン管理はかつて見過ごされがちでしたが、今では堅牢なデータ中心のアプリケーションを構築するチームにとっ�て不可欠なものとなっています。特にGitのようなツールを使用することで、その重要性が際立っています。
『バージョン管理の始め方』では、データサイエンスにおけるバージョン管理の進化を探り、その重要な役割—効率的なチームワークの促進、再現性の確保、コード、データ、設定、実行環境などのプロジェクト要素の監査トレイルの維持—について強調しています。この記事では、Gitの役割をメインのバージョン管理システムとして紹介し、Databricks環境でGitHubやAzure DevOpsなどのプラットフォームとどのように統合されるかを説明しています。また、Databricks Reposを使ったバージョン管理の設定方法、アカウントのリンク方法、リポジトリ作成、コード変更の管理方法についての実践的なガイドも提供します。
『バージョン管理のベストプラクティス』では、Gitのベストプラクティスを探り、"feature branch"ワークフロー、効果的なプロジェクトの組織方法、モノリポジトリとマルチリポジトリのセットアップの選択について詳しく解説しています。これらのガイドラインに従うことで、データサイエンスチームは効率的に協力し、コードベースをクリーンに保ちながらワークフローを最適化でき、最終的にはプロジェクトの堅牢性とスケーラビリティが向上します。
Apache Spark™をMLに活用するタイミング
Apache Sparkは、大規模データ処理と分析のために設計されたオープンソースの分散コンピューティングシステムであり、これは高度な分散システムエンジニアだけのものではありません。多くのML実践者が直面する、Pandasでのメモリ不足エラーなどの課題は、Sparkで簡単に解決できます。『Apache Spark™の力をデータサイエンス/機械学習のワークフローで活用する』では、データサイエンティストがApache Sparkを活用して効率的なデータサイエンスおよび機械学習ワークフローを構築する方法を探り、Sparkが得意とするシナリオ(例:大規模データセットの処理、リソース集約的な計算、高スループットアプリケーションの処理)を強調し、モデルとデータの並列化戦略を紹介し、実装に向けた実践的な例やパターンを提供しています。
良い習慣を築く:コードと開発におけるベストプラクティス
MLOpsの実践に必要な基本的なツールを把握した今、次はベストプラクティスについて探っていきましょう。このセクションでは、MLOps能力を向上させるために考慮すべき重要なトピックを取り上げます。
持続可能なプロジェクトのためのクリーンなコードを書く
多くの人は、最初にノートブックで実験を行い、アイデアを書き留めたり、コードをコピーしてその実現可能性をテストしたりします。この初期段階では、コードの品質は後回しになりがちで、冗長で不必要な、または非効率的なコードが生まれ、プロダクション環境ではうまくスケールしないこ��とがよくあります。『クリーンコードを書くための13の必須のヒント』というガイドでは、探索的なコードをどのように洗練させ、独立して実行できる状態やスケジュールされたジョブとして実行できる状態に整えるかについて実践的なアドバイスを提供します。これは、アドホックなタスクから自動化されたプロセスに移行するための重要なステップです。
適切な開発環境の選択
ML開発環境を設定する際には、いくつかの重要な決定を下す必要があります。あなたのプロジェクトに最適なクラスターはどれか?クラスターのサイズはどれくらいが適切か?ノートブックを使い続けるべきか、それともよりプロフェッショナルなアプローチとしてIDEに切り替えるべきか?このセクションでは、これらの一般的な選択肢について議論し、あなたのニーズに最適な決定を下すための推奨事項を提供します。
クラスター設定
サーバーレスコンピューティングは、Databricksでワークロードを実行する最良の方法です。速く、シンプルで信頼性が高いです。サーバーレスコンピューティングがさまざまな理由で利用できない場合、クラシックコンピューティングに戻すことができます。
『MLOpsのためのクラスター設定の初心者ガイド』では、適切なコンピューティングクラスターの選択、クラスターの作成と管理、ポリシーの設定、適切なクラスターサイズの決定、最適なランタイム環境の選択など、基本的なトピックをカバーしています。
開発目的にはインタラクティブクラスターを使用し、自動化されたタスクにはジョブクラスターを使用してコストを管理することを推奨します。また、シングルユーザー用または共有クラスター用のアクセスモードを選択する重要性を強調し、クラスターのポリシーがリソースと費用を効果的に管理する方法についても解説しています。さらに、CPU、ディスク、メモリの要件に基づいてクラスターのサイズを決定し、適切なDatabricks Runtimeを選択するための重要な要素についても説明しています。これには、StandardランタイムとMLランタイムの違いを理解し、最新のバージョンを使用することが含まれます。
IDEとノートブック
『機械学習開発でのIDE対ノートブック』では、IDEとノートブックの選択が個人の好み、ワークフロー、コラボレーションの要件、プロジェクトのニーズによって異なる理由について掘り下げます。多くの実践者は、両方を組み合わせて使用し、作業の異なる段階でそれぞれのツールの強みを活かしています。IDEはMLエンジニアリングプロジェクトに好まれ、ノートブックはデータサイエンスおよびMLコミュニティで人気があります。
運用の最適化:モニタリン�グ
AIシステムによる予測の品質への信頼を築くことは、MLOpsの初期段階でも重要です。AIシステムをモニタリングすることは、その信頼を構築するための第一歩です。
すべてのソフトウェアシステム、AIを含む、はインフラストラクチャの問題、外部依存関係、人的エラーによる障害に弱いものです。AIシステムは、データの分布の変化など、パフォーマンスに影響を与えるユニークな課題にも直面します。
『モニタリングの初心者ガイド』では、これらの変化を特定し対応するために継続的なモニタリングが重要であることを強調しています。DatabricksのLakehouse Monitoringは、統計的特性やデータの変動をモニタリングすることで、データ品質とMLモデルのパフォーマンスを追跡する手助けをします。効果的なモニタリングには、モニターの設定、メトリックのレビュー、ダッシュボードによるデータの可視化、アラートの作成が含まれます。
問題が検出された場合、モデルの再学習にはヒューマン・イン・ザ・ループアプローチを推奨しています。
実行のすすめ
もしあなたがMLOpsの旅の初期段階にいる、またはDatabricksに新しく取り組んでいて、MLOpsの実践を一から構築しようとしているのであれば、MLOps GymのCrawlフェーズからのコアな教訓は以下の通りです:
- すべてのAIプロジェクトで再利用可能な共通のインフラストラクチャを提供します。MLflowは、すべてのプロジェクトでのAI開発の追跡を標準化し、モデル管理には、Unity Catalog(Models in UC)�を使用したMLflow Model Registryが最適です。Feature Storeは、トレーニングと推論の偏りを解消し、Databricks Lakehouseプラットフォーム全体で簡単な系統管理を可能にします。さらに、コードのバックアップとチームとのコラボレーションのために、Gitを常に使用します。MLワークロードを分散する必要がある場合は、Apache Sparkがその支援を行います。
- クリーンでスケーラブルなコードを書くためのヒントを実践し、特定のMLワークロードに最適な構成を選ぶことで、最初からベストプラクティスを実装します。ノートブックを使用すべき時とIDEを活用すべき時を理解し、最も効果的な開発を行います。
- データとモデルを積極的にモニタリングすることで、AIシステムへの信頼を築きます。AIシステムのパフォーマンスを評価できることを示すことで、ビジネスユーザーに予測結果を信頼してもらえるようになります。
Crawlフェーズでの推奨事項を実践することで、アドホックなMLワークフローから再現性があり信頼性の高いジョブへと移行し、手動でのエラーの多いプロセスを排除することができます。次のMLOps Gymシリーズのフェーズ、Walkでは、CI/CDとDevOpsのベストプラクティスをMLOpsの設定に統合する方法をガイドします。これにより、個々のMLジョブではなく、完全に開発されたMLプロジェクトをDevOpsツールを使用して管理し、テストと自動化が進みます。
私たちは定期的にDatabricks Community blogでMLOps Gymの記事を公開しています。MLOps Gymコンテンツに対するフィードバックや質問が�あれば、mlopsgym@databricks.comまでメールしてください。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。