Azure Databricks 上の Lakeflow でデータエンジニアリングプラットフォームを最新化
Azure 上の Databricks Lakeflow は、モダンでエンタープライズ対応の、信頼性の高いデータエンジニアリングソリューションを提供します。
によって Joanna Zouhour 、 ケイティ・カミスキー による投稿
- Lakeflowは、データ取り込み、変換、オーケストレーションなど、Azure Databricksで作業するデータエンジニア向けに、統合されたエンドツーエンドのソリューションを提供します
- 統合されたセキュリティとガバナンスから、組み込みの可観測性、serverlessコンピュート、ストリーミング処理、コードファーストのUIまで、Azure Databricksの実践者は、自社のAzureデータプラットフォームと組み合わせて、Lakeflowの幅広い機能からメリットを得ることができます。- Azure DatabricksでLakeflowを使用するデータエンジニアは、本番運用可能なデータパイプラインを最大25倍速く構築、デプロイし、パフォーマンスの向上を実感し、ETLコストを最大83%削減できます。
データエンジニアは、本番運用に対応したパイプラインを構築するために必要な、多数のばらばらなツールやソリューションにますます不満を募らせています。一元化されたデータインテリジェンスプラットフォームや統合されたガバナンスがないため、チームは以下のような多くの課題に直面しています。
- 非効率なパフォーマンスと長い起動時間
- ばらばらなUIと絶え間ないコンテキストの切り替え
- きめ細かいセキュリティと制御の欠如
- 複雑なCI/CD
- データリネージの可視性が限定的
- など
その結果は?チームのスピードが低下し、データへの信頼性が損なわれます。
Azure Databricks 上の Lakeflow を使用すると、すべてのデータエンジニアリング作業を単一の Azure ネイティブプラットフォームに集約することで、これらの問題を解決できます。

Azure Databricks 向けの統合データエンジニアリングソリューション
Lakeflowは、Azure上のDatabricks Data Intelligence Platform上に構築されたエンドツーエンドの最新データエンジニアリングソリューションであり、あらゆる重要なデータエンジニアリング機能を統合します。Lakeflowで実現できること:
- 組み込みのデータ取り込み、変換、オーケストレーションを 1か所で
- マネージド取り込みコネクター
- 宣言型ETLにより、より迅速でシンプルな開発を実現
- 増分およびストリーミング処理で SLA を迅速化し、より新鮮な知見を取得
- ネイティブ�なガバナンスとリネージを、Databricksの統合ガバナンスソリューションであるUnity Catalogで実現
- 組み込みのオブザーバビリティ でデータ品質とパイプラインの信頼性を実現
その他多数コーディングでもポイントアンドクリックのインターフェースでも、あらゆるユーザーのニーズに適合できる、柔軟でモジュール式のインターフェースにすべてが備わっています。
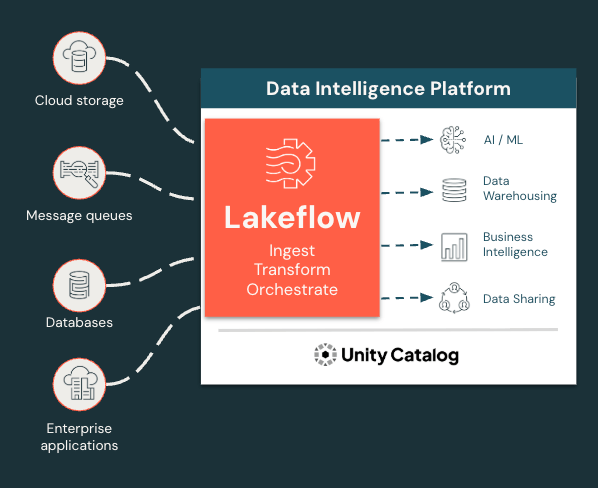
すべてのワークロードの取り込み、変換、オーケストレーションを1か所で
Lakeflow はデータエンジニアリング体験を統合し、より迅速かつ確実に開発を進めることを可能にします。
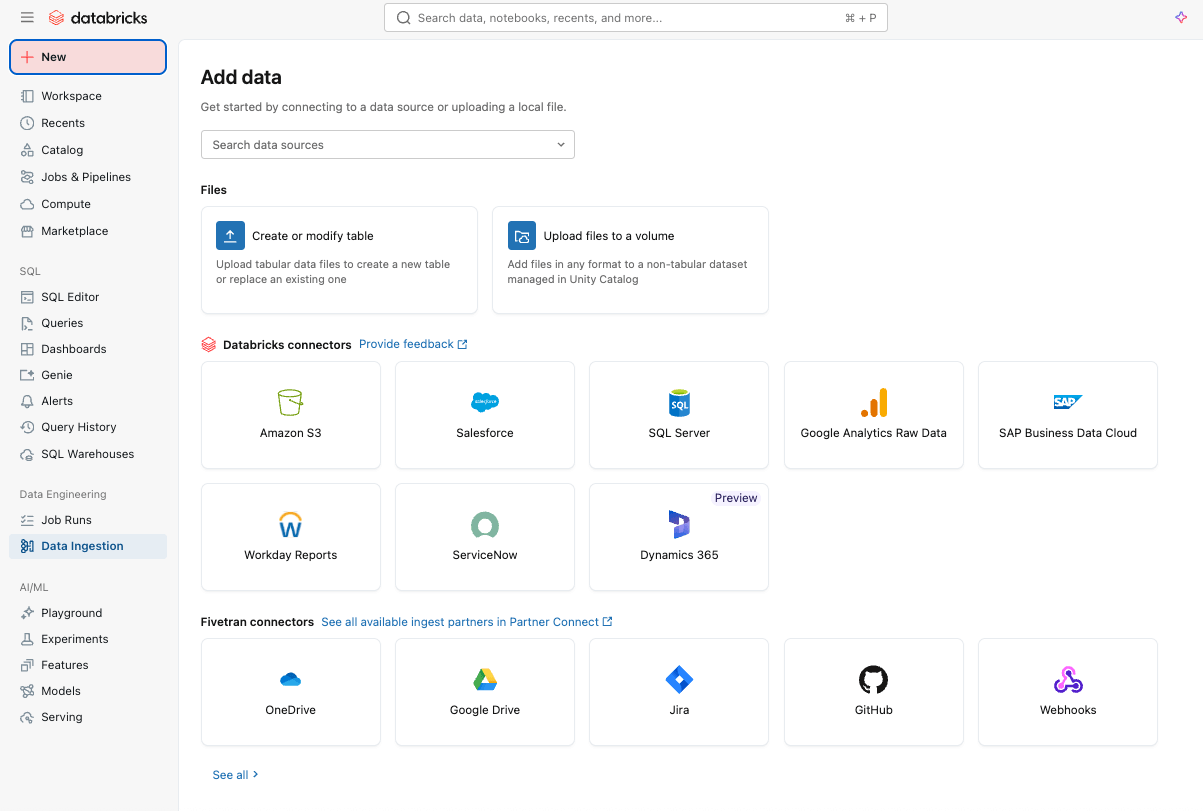
Lakeflow Connect によるシンプルで効率的なデータ取り込み
Lakeflow Connect を使用すれば、ポイント&クリックのインターフェースやシンプルなAPIを使って、プラットフォームへのデータ取り込みを簡単に始められます。
Salesforce 、 Workday 、 ServiceNow などの一般的なSaaSアプリケ�ーション、 SQL Server などのデータベース、クラウドストレージ、メッセージバスなど、幅広いサポート対象ソースから 構造化データと非構造化データ の両方をAzure Databricksにインジェストできます。Lakeflow Connectは、Private Linkやデータベース用のVNetへのインジェストゲートウェイのデプロイなど、Azureのネットワークパターンもサポートしています。
リアルタイムの取り込みには、Azure Databricks 上の Lakeflow にあるサーバーレスのダイレクトライト API、Zerobus Ingest をお試しください。イベントデータをデータプラットフォームに直接プッシュするため、メッセージバスが不要になり、よりシンプルで低レイテンシーな取り込みが実現します。
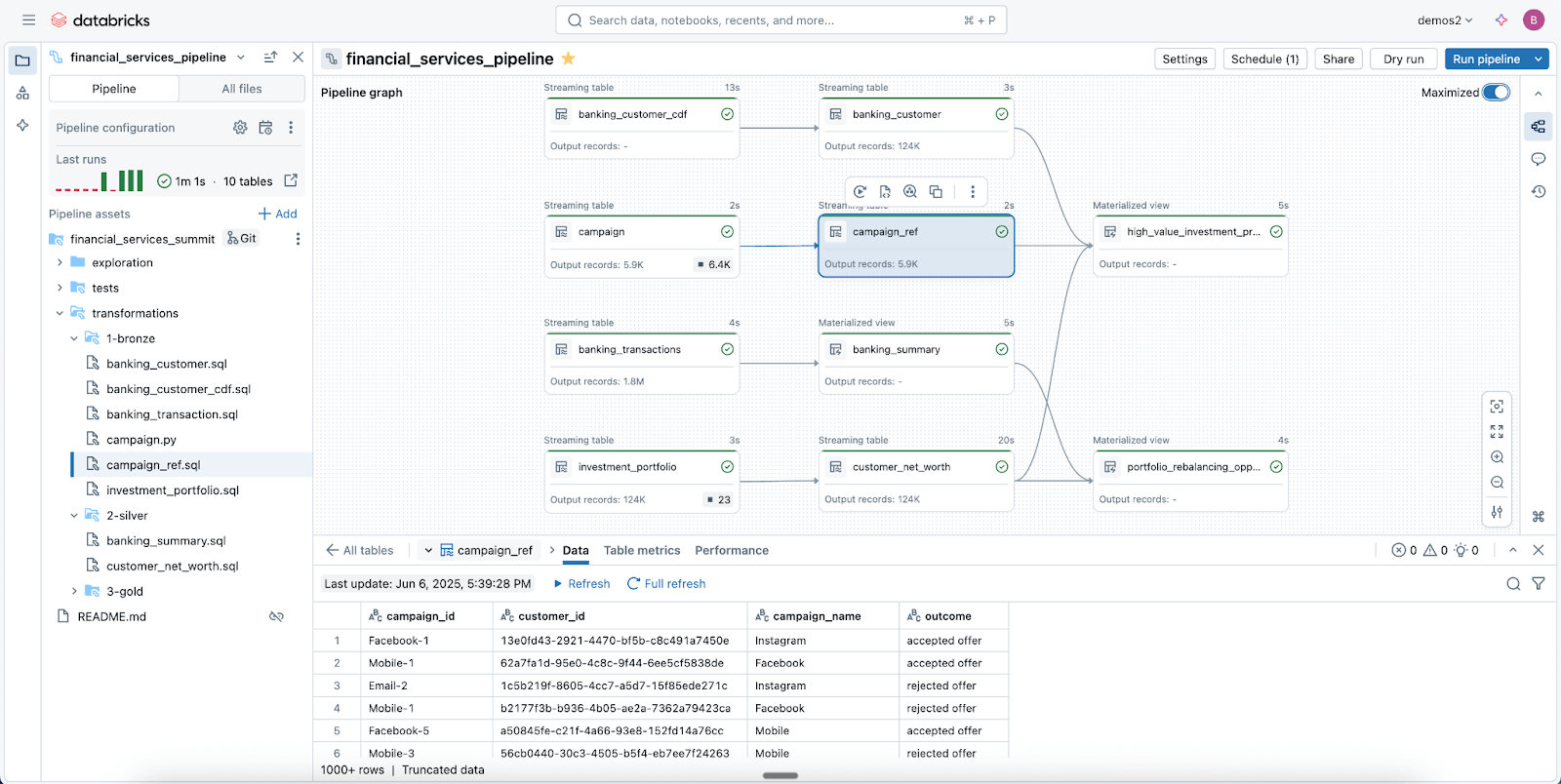
Spark宣言型パイプラインで信頼性の高いデータパイプラインを容易に構築
Lakeflow Spark Declarative Pipelines(SDP)を活用して、ビジネスニーズに合わせてデータを容易にクレンジング、整形、変換できます。
SDPでは、わずか数行のPython(またはSQL)コードで、信頼性の高いバッチおよびストリーミングETLを構築できます。必要な変換を宣言するだけで、依存関係のマッピング、デプロイ用インフラストラクチャ、データ品質など、残りの処理はすべてSDPに任せることができます。
SDP は、データエンジニアリングのベストプラクティスを標準でコード化することで開発時間と運用オーバーヘッドを最小限に抑え、わずか数行のコードで差分処理や SCD タイプ 1 & 2 のような複雑なパターンの実装を容易にします。Spark Structured Streaming のパワーのすべてを、驚くほどシンプルにしました。
また、Lakeflow は Azure Databricks に統合されているため、 Databricks Asset Bundles (DABs) や レイクハウスモニタリング などの Azure Databricks ツールを使用して、本番運用に対応した統制されたパイプラインを数分でデプロイできます。
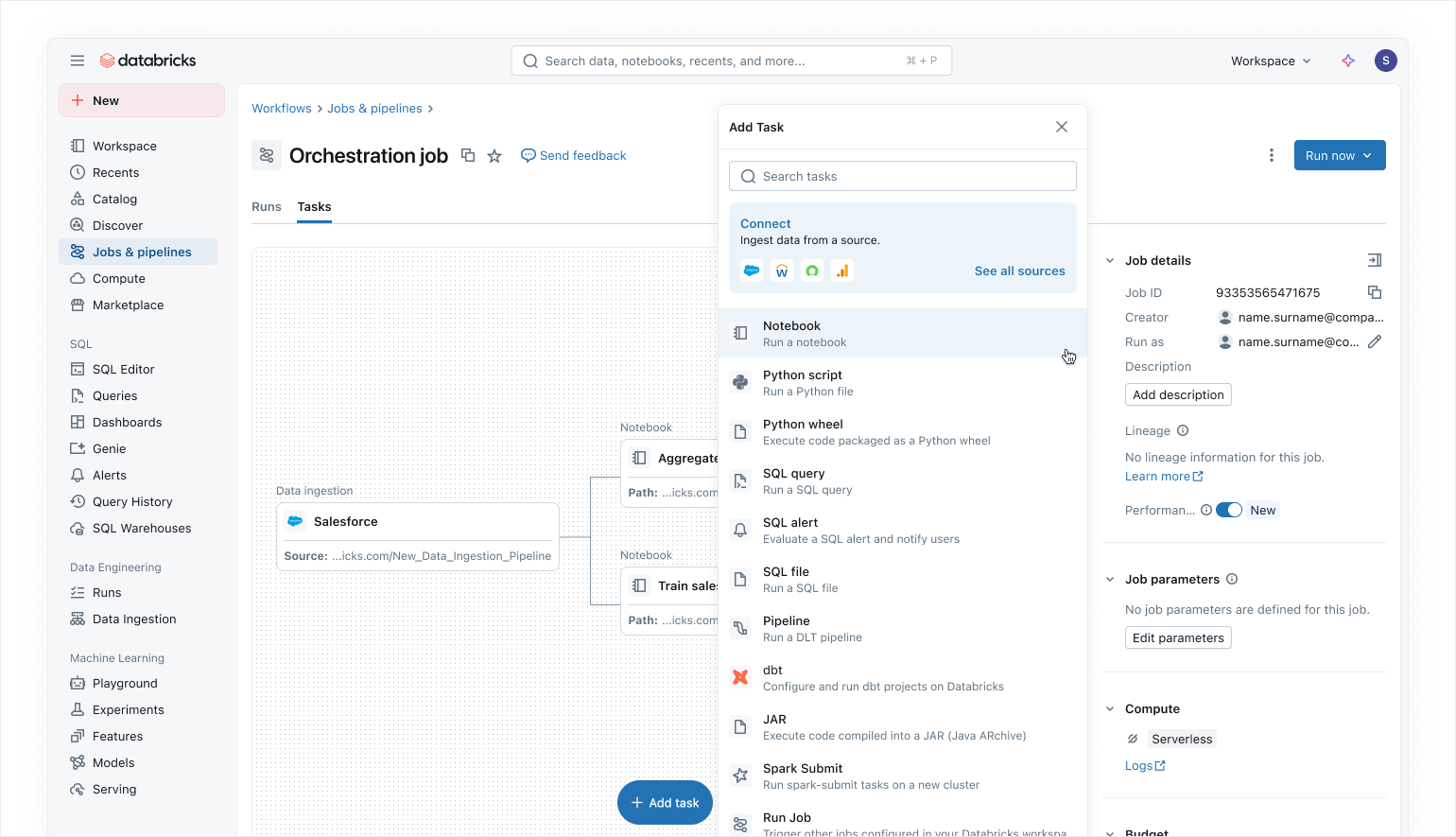
Lakeflow Jobsによる最新のデータファーストオーケストレーション
Lakeflow Jobs を使用し 、Azure Databricks 上のデータと AI のワークロードをオーケストレーションします。モダンでシンプルなデータファーストのアプローチにより、Lakeflow Jobs は Databricks で最も信頼されているオーケストレーターとして、大規模なデータと AI の処理およびリアルタイム アナリティクスを 99.9% の信頼性でサポートします。
Lakeflow Jobs では、SQL ワークロード、Python コード、ダッシュボード、パイプライン、外部システムを連携させて単一の統合 DAG としてすべての依存関係を可視化できます。テーブルの更新やファイルの到着などの データ認識Triggerや制御フロータスクにより、ワークフローの実行はシンプルで柔軟です。ノーコードの バックフィルランと組み込みの可観測性により、Lakeflow Jobs は下流のデータを常に最新でアクセスしやすく、正確な状態に保つことを容易にします。
Azure Databricks ユーザーは、 Lakeflow Jobs の Power BI タスク (詳細は こちら) を使用して Power BI セマンティック モデルを自動的に更新することもでき、Lakeflow Jobs を Azure ワークロードのシームレスなオーケストレーターとして活用できます。
組み込みのセキュリティと統合ガバナンス
Unity Catalog により、Lakeflow は、取り込み、変換、オーケストレーションにわたって、一元化された ID、セキュリティ、ガバナンスの制御を継承します。接続によって認証情報が安全に保存され、アクセス ポリシーがすべてのワークロードで一貫して適用され、きめ細かな権限によって適切なユーザーとシステムのみがデータを読み書きできるようになります。
Unity Catalogは、データ取り込みからLakeflow Jobs、下流のアナリティクスやPower BIに至るまでのエンドツーエンドのリネージも提供し、依存関係の追跡とコンプライアンスの確保を容易にします。 システムテーブルは、ジョブ、ユーザー、データ使用状況にわたる運用およびセキュリティの可視性を提供するため、チームは外部ログを繋ぎ合わせることなく、品質の監視とベストプラクティスの徹底が可能です。
Lakeflow と Unity Catalog を組み合わせることで、Azure Databricks ユーザーはdefaultでガバナンスの効いたパイプラインを利用でき、その結果、チームが信頼できる、安全で監査可能、かつ本番運用に対応したデータデリバリーが実現します。
Unity CatalogによるOneLakeのサポート に関するブログをお読みください。
あらゆるユーザーに対応する柔軟なユーザーエクスペリエンスとオーサリング
これらのすべての機能に加えて、Lakeflow は非常に柔軟で使いやすいため、組織内のあらゆるユーザー、特に開発者にとって最適です。
コードファーストのユーザーは、Lakeflow の強力な実行エンジンと開発者中心の高度なツールを高く評価しています。 Lakeflow Pipeline Editor により、開発者は IDE を活用し、堅牢な開発ツールを使用してパイプラインを構築できます。また、Lakeflow Jobs には、再現可能な CI/CD パターンを実現するため、 DB Python SDK と DAB を使用したコードファーストのオーサリングおよび開発ツールも備わっています。
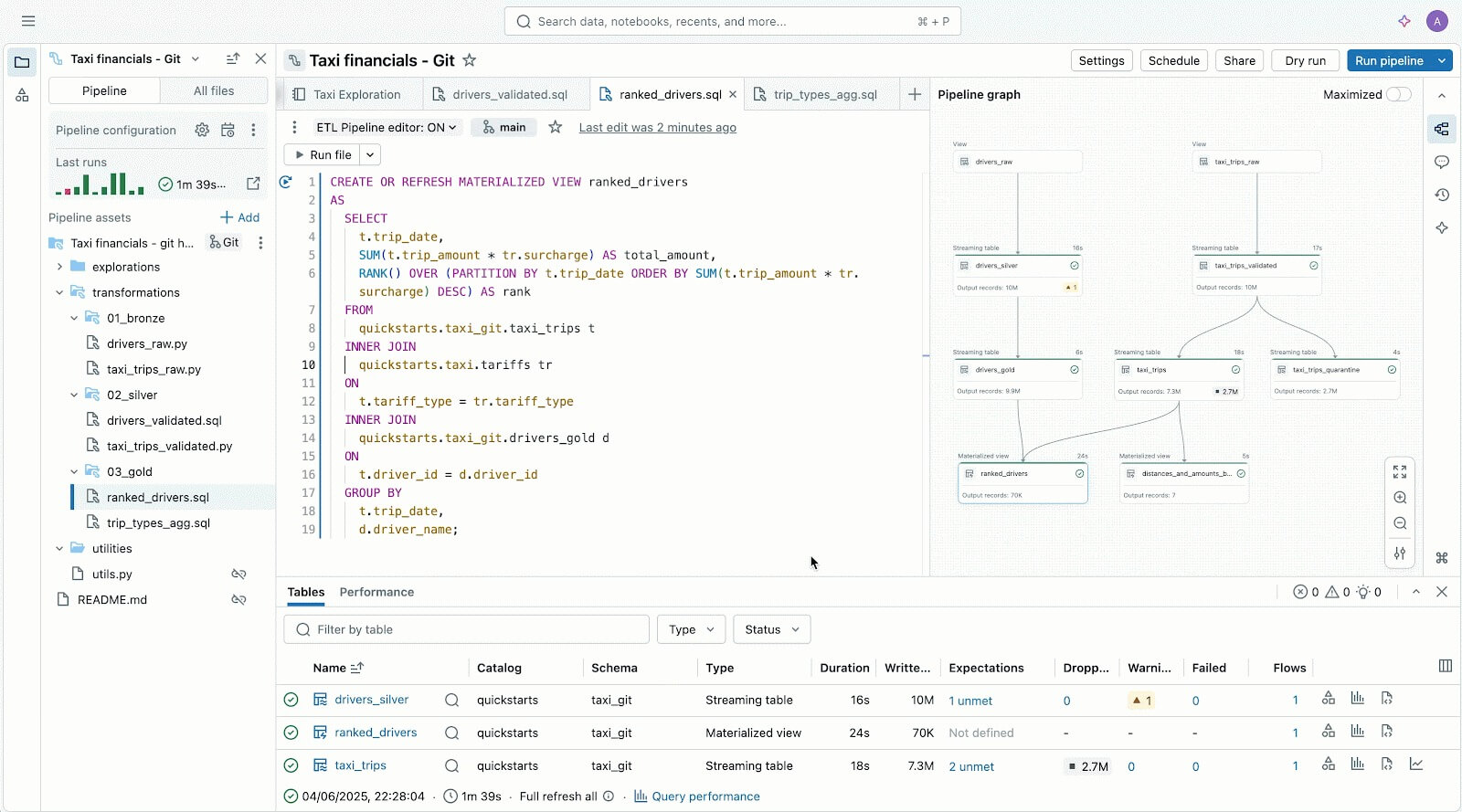
Lakeflow Pipelines Editorで、データパイプラインのオーサリングとテストをすべて1か所で。
初心者やビジネスユーザーにとって、Lakeflow は非常に直感的で使いやすく、シンプルなポイント&クリックインターフェースと、Lakeflow Connect によるデータ取り込み用の API を備えています。
ネイティブの可観測性により、当て推量を減らし、より正確なトラブル��シューティングを実現
監視ソリューションは多くの場合データプラットフォームからサイロ化されているため、可観測性の運用が難しくなり、パイプラインが破損しやすくなります。
Azure Databricks 上の Lakeflow Jobs は、データエンジニアがパイプラインの問題を迅速に把握して解決するために必要な、詳細かつエンドツーエンドの可視性を提供します。Lakeflowの可観測性機能を使用すると、統合された実行リストを備えた単一のUIで、パフォーマンスの問題、依存関係のボトルネック、失敗したタスクを即座に特定できます。
LakeflowのシステムテーブルとUnity Catalogに組み込まれたデータリネージは、データセット、ワークスペース、クエリ、下流への影響に関する完全なコンテキストも提供し、根本原因分析を迅速化します。新たにGAとなったJobsのシステムテーブルでは、すべてのジョブにわたるカスタムダッシュボードを構築し、ジョブの状態を一元的に監視できます。
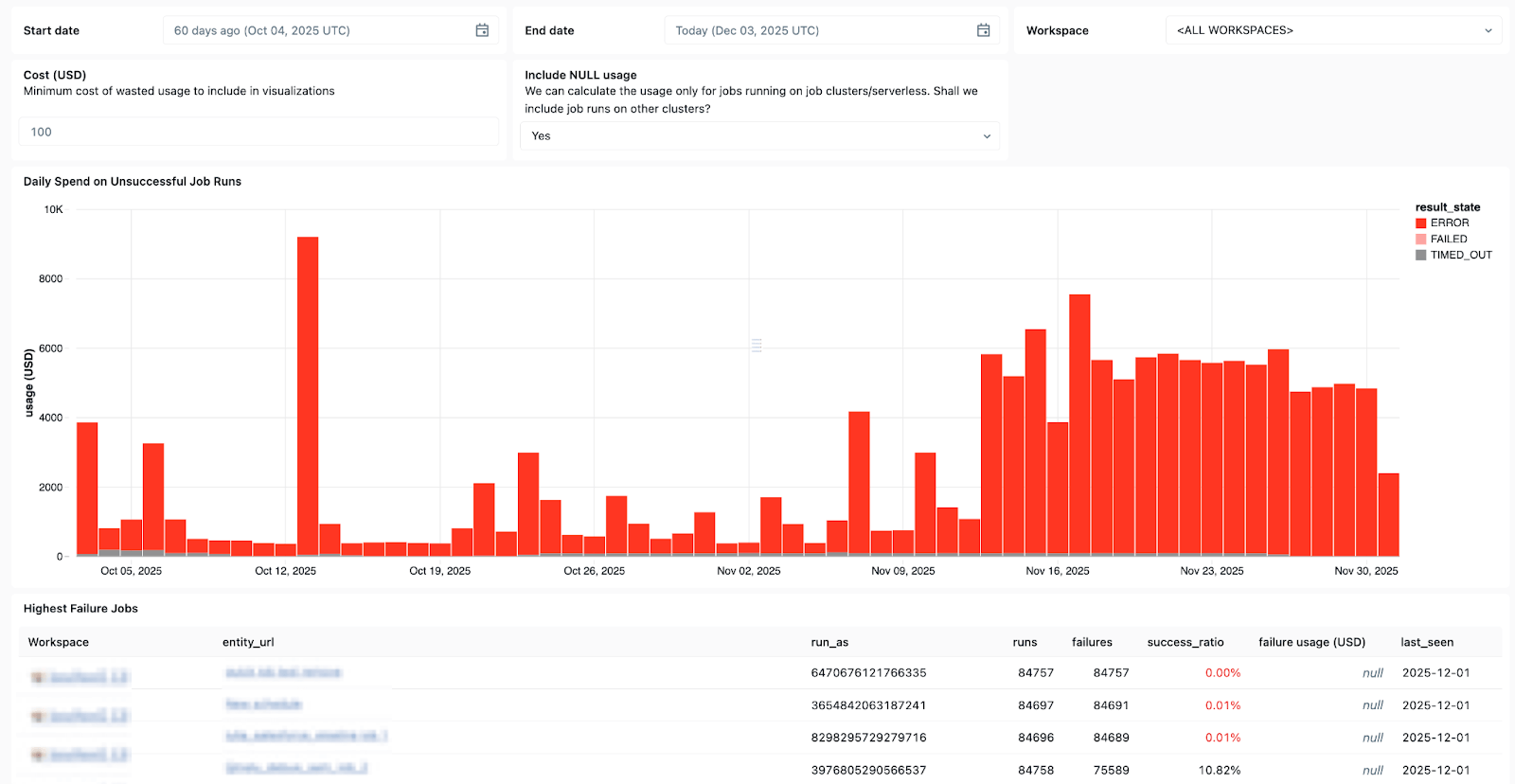
Lakeflowのシステムテーブルを使用して、最も頻繁に失敗するジョブ、全体的なエラーの傾向、一般的なエラーメッセージを確認できます。
そして問題が�発生した際には、Databricks Assistant がサポートします。
Databricks Assistantは、Azure Databricksに組み込まれたコンテキスト認識型AIコパイロットであり、自然言語を使用してノートブック、SQLクエリ、ジョブ、ダッシュボードを迅速に構築およびトラブルシューティングできるようにすることで、障害からの迅速な復旧を支援します。
しかし、アシスタントの機能はデバッグだけではありません。Unity Catalogを基盤とする機能により、コンテキストを理解した上でPySpark/SQLコードを生成して説明することもできます。また、提案の実行、パターンの発見、データディスカバリーや EDA の実行にも使用できるため、あらゆるデータエンジニアリングのニーズに対応する優れたコンパニオンとなります。
コストと消費量を管理下に
パイプラインが大規模になるほど、リソース使用量を適正化し、コストを管理下に置くことはより困難になります。
Lakeflowの サーバーレスデータ処理では、Databricksによってコンピューティングが自動的かつ継続的に最適化され、アイドル時の無駄やリソース使用量が最小限に抑えられます。データエンジニアは、ミッションクリティカルなワークロードにはパフォーマンスモードで、コスト��がより重要な場合は標準モードでサーバーレスを実行するかどうかを決定でき、柔軟性を高めることができます。
Lakeflow Jobsはクラスターの再利用も可能で、ワークフロー内の複数のタスクを 同じジョブクラスター で実行できるため、コールドスタートの遅延が解消されます。 また、 きめ細かい制御 がサポートされており、各タスクは再利用可能なジョブクラスターまたは専用クラスターのいずれかをターゲットにできます。サーバーレスコンピュートと合わせて、クラスターの再利用によりスピンアップが最小限に抑えられるため、データエンジニアは運用上のオーバーヘッドを削減し、データコストをより詳細に管理できるようになります。
Microsoft Azure + Databricks Lakeflow - 実績のある強力な組み合わせ
Databricks Lakeflow により、データチームはガバナンス、スケーラビリティ、パフォーマンスを損なうことなく、より迅速かつ確実に業務を進めることができます。Azure Databricks にデータエンジニアリングがシームレスに組み込まれているため、チームは、あらゆるデータと AI のニーズに大規模に対応できる単一のエンドツーエンドプラットフォームを活用できます。
Azure をご利用の顧客は、自社のスタックに Lakeflow を統合することで、すでに次のような好結果を得ています。
- パイプライン開発の迅速化: チームは本番稼働可能なデータパイプラインを最大25倍速く構築、デプロイでき、作成時間を70%削減できます。
- パフォーマ�ンスと信頼性の向上:一部の顧客は、パフォーマンスが90倍向上し、処理時間が数時間から数分に短縮されたことを実感しています。
- さらなる効率化とコスト削減: 自動化と最適化された処理により、運用上のオーバーヘッドが劇的に削減されます。顧客からは、年間最大数千万ドルのコスト削減や、ETLコストの最大83%削減が報告されています。
Databricks ブログで Azure と Lakeflow のお客様の成功事例をご覧ください。
Lakeflowにご興味がありますか?Databricksを無料でお試し いただき、データエンジニアリングプラットフォームの全貌をご確認ください。
(このブログ記事はAI翻訳ツールを使用して翻訳されています) 原文記事
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。