上記の例は単体で動作し、箱から出してすぐに完全に機能します。ただし、本番環境へのデプロイでは、通常いくつかの追加設定が必要になります。実運用では、OpenSky のデータ収集に使う地理的リージョンの指定、認証の有効化(API のレート制限引き上げのため)、そしてデータ品質制約の適用(不正なデータの流入防止)などを行う場合があります。
メインコンテンツへジャンプ
1本の宣言型パイプラインで、数千機の航空機からの数百万イベントを処理
Lakeflowの宣言型パイプラインとPySparkカスタムデータソースで構築するスケーラブルシステム
によって フランク・ムンツ による投稿
- PySparkカスタムデータソースとLakeflowストリーミングテーブルを使用して、ライブADS-Bフライトデータをストリームします。
- マテリアライズドビューでメトリクスを事前に集計し、AI/BI GenieまたはSQLで瞬時にクエリします。
- このパイプラインが製品規模で、つまり1日に数億イベントまで動作するための設計選択、落とし穴、データ品質チェックを学びます。
毎秒、世界中の空では数万機の航空機が IoT イベントを生成しています――グランドキャニオン上空を4人の観光客を乗せて飛ぶ小型のセスナから、フランクフルトを570人の乗客とともに離陸し、ニューヨークへ向かう大西洋横断航路で位置・高度・飛行経路をブロードキャストしているエアバス A380 まで。
気象や混雑の変化に合わせて複雑な飛行経路を絶えず更新しなければならない管制官と同じように、データエンジニアには、高スループット・低レイテンシでミッションクリティカルな航空データのストリームを扱えるプラットフォームが求められます。どちらのシステムにとっても、処理を止めるという選択肢はありません。
こうしたデータパイプラインの構築は、かつては何百行ものコードとコンピュートクラスターの管理、複雑な権限設定による ETL の維持という“格闘”を意味していました。そんな時代は終わりました。Lakeflow Declarative Pipelines を使えば、プレーンな SQL(あるいは希望すれば Python)だけで数分で本番運用レベルのストリーミングパイプラインを構築できます。サーバーレスなコンピュート上で、統合ガバナンスときめ細かなアクセス制御も備わっています。
本記事では、交通・物流・貨物といったユースケースのアーキテクチャを解説し、北米上空を飛行中のすべての航空機からリアルタイムのアビオニクスデータを取り込み、わずかな宣言的コードでフライトステータスをライブ処理するパイプラインを紹介します。
現実世界の大規模ストリーミング
多くのストリーミング解説は「実データ」を謳いながら、実際には本番規模の量・速度・多様性を見落とした合成データセットを使いがちです。航空業界は世界でも最も厳しいリアルタイム要件を持つデータストリームを扱っています�――航空機の位置情報は安全が絡む用途のため、1秒に複数回更新され、低レイテンシが必須です。
OpenSky Network は、オックスフォード大学などの研究機関によるクラウドソース型プロジェクトで、非商用利用に限りライブのアビオニクスデータへ無料アクセスを提供しています。これにより、説得力のあるデータを使ってエンタープライズ級のストリーミングアーキテクチャを実演できます。
スマホでフライトを追うのは気軽な娯楽ですが、同じデータストリームが何十億ドル規模の物流オペレーションを支えています。港湾当局は地上オペレーションを調整し、配送事業者は通知にフライトスケジュールを取り込み、フォワーダーはグローバルなサプライチェーンで貨物の動きを追跡しています。
アーキテクチャの革新:カスタムデータソースを“第一級の存在”に
従来のアーキテクチャでは、外部システムをデータプラットフォームにつなぐために、多くのコードとインフラ運用の負荷が必要でした。サードパーティのデータストリームを取り込むには、一般に外部SaaSへ費用を払うか、認証管理・フロー制御・複雑なエラーハンドリングを備えたカスタムコネクタを自作する必要があります。
Data Intelligence Platform では、Lakeflow Connect が Salesforce、Workday、ServiceNow のようなエンタープライズ業務システム向けにこの複雑さに対処します。増え続けるマネージドコネクタ群が、認証、変更データキャプチャ(CDC)、エラー復旧を自動で処理してくれます。
Lakeflow の OSS 基盤である Apache Spark™ は、ビルトインのデータソース群を備え、数多くの技術システムから読み取れます。たとえば Parquet、Iceberg、Delta Lake(delta.io)のようなクラウドストレージフォーマットから、Apache Kafka、Pulsar、Amazon Kinesis のようなメッセージバスまで幅広く対応します。たとえば spark.readStream.format("kafka") のように簡単に Kafka トピックへ接続でき、このおなじみの構文はサポートされるすべてのデータソースで一貫して機能します。
しかし、任意の API 経由でサードパーティシステムにアクセスする場合には、Lakeflow Connect がカバーするエンタープライズシステムと、Spark の“技術ベース”のコネクタの間にギャップが生まれます。REST API を提供していてもどちらのカテゴリにも当てはまらないサービスがあり、しかし組織としてはそのデータをレイクハウスに取り込みたい――そんなケースです。
PySparkカスタムデータソースは、このギャップをきれいな抽象化レイヤで埋め、API 連携をほかのデータソースと同じくらい簡単にします。
このブログでは、OpenSky Network 向けの PySpark カスタムデータソースを実装し、pip install で使える形で公開しました。このデータソースは API 呼び出し、認証、エラーハンドリングを内包しています。上の例の「kafka」を「opensky」に置き換えるだけで、あとは同じように動作します。
この抽象化により、チームは統合まわりのオーバーヘッドではなくビジネスロジックに集中でき、どのデータソースでも同じ開発体験を保てます。
カスタムデータソースというパターンは汎用的なアーキテクチャ解として機能し、あらゆる外部 API――金融市場データ、IoT センサーネットワーク、ソーシャルメディアのストリーム、予知保全システム――にシームレスに対応します。開発者はおなじみの Spark DataFrame API をそのまま使い、HTTP コネクションプーリングやレート制限、認証トークンといった煩雑さを気にする必要がありません。
このアプローチは、再利用可能なコネクタを作るだけの価値はあるが、エンタープライズ級のマネージド製品は存在しないようなサードパーティシステムに特に有効です。
ストリーミングテーブル:Exactly-Once な取り込みをシンプルに
カスタムデータソースで API 接続を扱えるようになったところで、このデータを確実に処理するストリーミングテーブルを見ていきましょう。IoT データストリームには、重複検出、遅延到着イベント、処理保証といった固有の課題があります。従来のストリーミング基盤では、厳密に一度だけ(exactly-once)のセマンティクスを実現するために複数コンポーネントの綿密な調整が求められてきました。
Lakeflow の宣言的パイプラインにおけるストリーミングテーブルは、この複雑さを宣言的なセマンティクスで解消します。Lakeflow は、低レイテンシ処理と高スループット処理の双方に優れています。
カスタムデータソースを原動力とするストリーミングテーブルを紹介するこの記事は、おそらく最初期の一つですが、これが最後にはなりません。宣言的パイプラインと PySpark データソースがオープンソース化され、Apache Spark™ で広く利用できるようになった今、これらの機能はあらゆる開発者に手の届くものになりつつあります。
上のコードは、アビオニクス(航空機搭載)データにデータストリームとしてアクセスします。同じコードが、ストリーミング処理とバッチ処理の双方でまったく同じように機能します。Lakeflow では、パイプライ��ンの実行モードを設定し、Lakeflow Jobs などのワークフローで実行をトリガーできます。
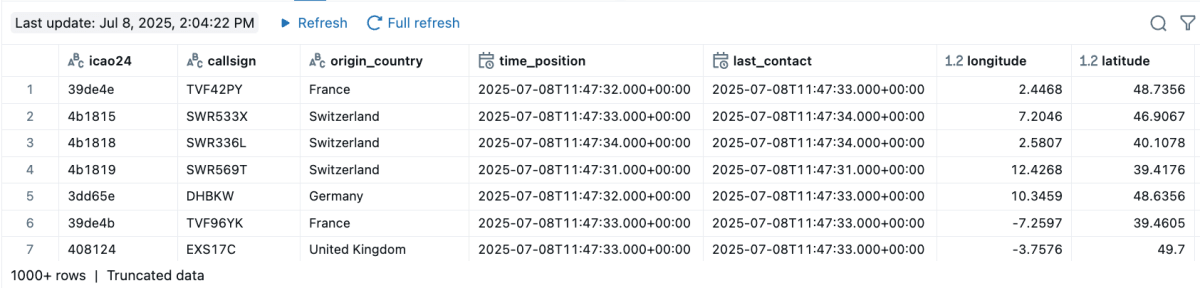
この短い実装は、宣言的プログラミングの強さを示しています。上のコードは、ライブのアビオニクスデータを継続的に取り込むストリーミングテーブルを生成します――時間帯にもよりますが、現在米国内の上空を飛ぶ約1万機の航空機からデータをストリームする、完全な実装です。認証、増分処理、エラー復旧、スケーリングといった残りのすべては、プラットフォームが処理します。
機体のコールサイン、現在位置、高度、速度、方位、目的地といったあらゆる詳細がストリーミングテーブルに取り込まれます。この例はコード風のスニペットではなく、スケールで実際に役立つデータを提供する実装です。
新しい Lakeflow宣言型パイプラインエディタを使えば、フルアプリケーションをゼロから対話的に簡単に作成できます。新しいエディタはデフォルトでファイルベースのため、ノートブックで pip install を実行する代わりに、エディタの Settings/Environments からデータソースパッケージ pyspark-data-sources を直接追加できます。
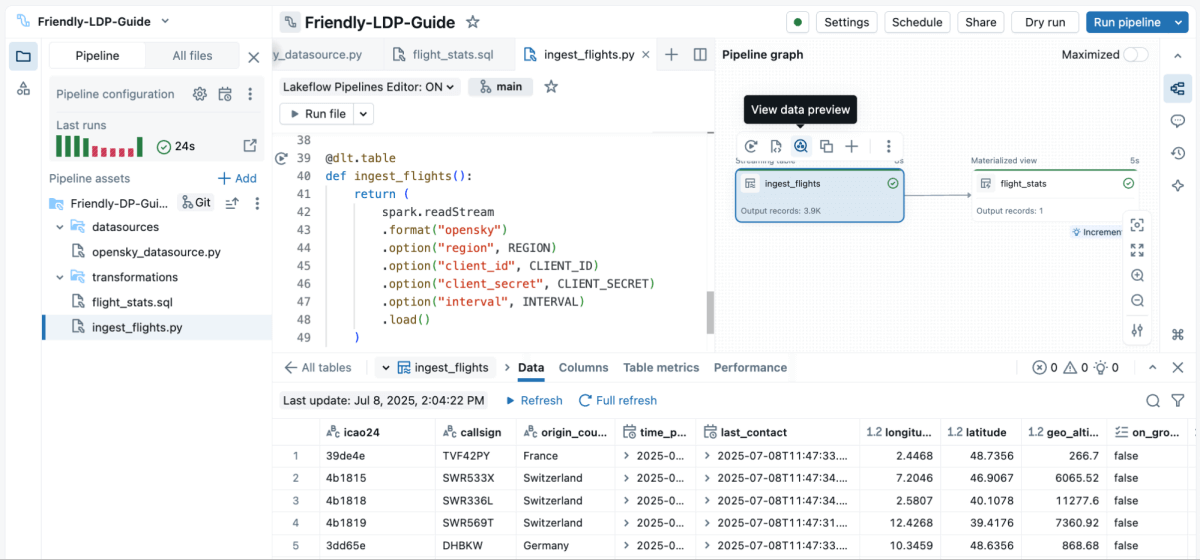
舞台裏では、Lakeflow がストリーミング基盤を管理します。自動チェックポイントにより障害復旧を担保し、増分処理で冗長な計算を排除し、exactly-once の保証でデータ重複を防ぎます。データエンジニアはビジネスロジックを書くだけで、運用上の卓越性はプラットフォームが担保します。
任意の設定
地理的リージョン
主要な大陸や地域ごとにあらかじめ定義されたバウンディングボックスを指定することで、特定地域上空のフライトを追跡できます。データソースには AFRICA、EUROPE、NORTH_AMERICA などの地域フィルターに加え、世界全体を対象にするグローバルオプションも含まれています。これらのビルトイン地域設定により、特定ユースケースで地理的に関連するエリアに分析対象を絞りつつ、返されるデータ量を制御できます。
レート制限と OpenSky Network の認証
OpenSky Network で認証すると、本番運用�に有益なメリットが得られます。OpenSky API のレート制限は匿名利用で1日100回ですが、認証済みだと1日4,000回まで増え、リアルタイムのフライト追跡には不可欠です。
認証するには、https://opensky-network.org で API 資格情報を登録し、データソースを設定する際に client_id と client_secret をオプションとして指定します。これらの資格情報はコードにベタ書きせず、Databricks Secrets として保存してください。
なお、OpenSky Network にデータ提供を行う場合、上限は1日8,000回まで引き上げられます。これは自宅のベランダなどに ADS-B アンテナを設置して、このクラウドソースのイニシアチブに貢献するという、ちょっと楽しいプロジェクトです。
期待値によるデータ品質
信頼できる分析にはデータ品質が重要です。Declarative Pipeline ��の Expectations は、ストリーミングデータを自動検証するルールを定義し、クリーンなレコードだけがテーブルに到達するようにします。
これらのルールは、欠損値や不正な形式、業務ルール違反を検知できます。不正レコードをドロップする、検証用に隔離(クアランティン)する、検証失敗時にパイプラインを停止する、といった動作を選べます。次のセクションのコードでは、本番利用に向けたリージョン選択、認証設定、データ品質検証の構成方法を示します。
改訂版ストリーミングテーブルの例
以下の実装は、地域パラメーターと認証を備えたストリーミングテーブルの例を示しており、データソースが地理的フィルタリングと API 資格情報をどのように取り扱うかを示します。データ品質の検証では、国際民間航空機関(ICAO)が管理する航空機 ID と機体の座標が設定されているかをチェックします。
マテリアライズドビュー:分析のための事前集計結果
ストリーミングデータに対するリアルタイム分析は、従来はストリーム処理エンジン、キャッシュ層、分析用データベースを組み合わせた複雑なアーキテクチャを必要としてきました。どのコンポーネントも運用のオーバーヘッドや一貫性の課題、追加の故障要因を招きます。
Lakeflow Declarative Pipelines のマテリアライズドビューは、サーバーレスコンピュートで基盤のランタイムを抽象化することで、こうしたアーキテクチャ上の負担を軽減します。シンプルな SQL ステートメントで、あらかじめ計算された結果を含むマテリアライズドビューを作成でき、新しいデータが到着するたびに自動更新されます。これらの結果は、ダッシュボードや Databricks Apps、あるいは Lakeflow Jobsで実装したワークフロー内の追加の分析タスクなど、下流での利用に最適化されています。
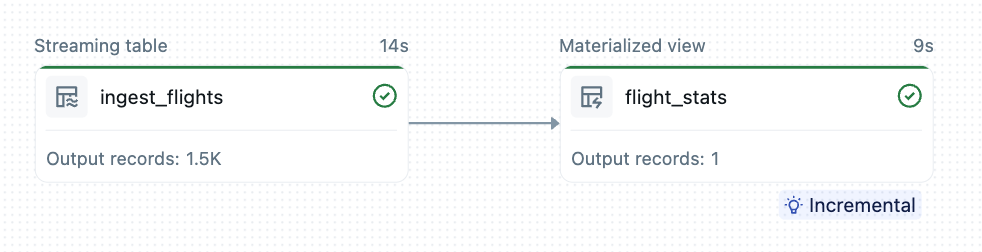
このマテリアライズドビューは、ストリーミングテーブルからの航空機ステータス更新を集約し、飛行パターン、速度、高度に関するグローバル統計を生成します。新たな IoT イベントが到着すると、ビューはサーバーレスの Lakeflow プラットフォーム上で増分的に更新されます。ほぼ毎日10億件に近いイベントを再計算するのではなく、数千件の変更だけを処理することで、処理時間とコストが劇的に削減されます。
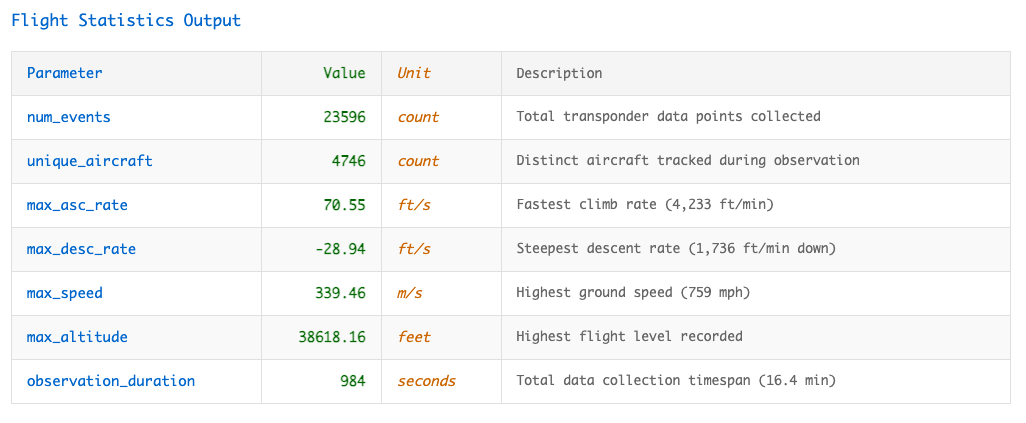
Lakeflow Declarative Pipelines の宣言的アプローチは、変更データキャプチャ、増分計算、結果キャッシュにまつわる従来の複雑さを取り除きます。これによりデータエンジニアは、ダッシュボードや Databricks アプリケーション、その他あらゆる下流ユースケース向けのビュー作成において、分析ロジックそのものに専念できます。
AI/BI Genie:リアルタイム洞察のための自然言語
データが増えるほど、組織には新たな課題が生まれます。リアルタイムデータが利用可能でも、パイプラインを変更するのは通常テクニカルなデータエンジニアリングチームだけであり、業務の分析チームはアドホック分析のためにエンジニアのリソースに依存しがちです。
AI/BI Genie は、誰もがストリーミングデータに対して自然言語でクエリできるようにします。非テクニカルなユーザーでも平易な英語で質問でき、クエリは自動的にリアルタイムデータソースに対する SQL に変換されます。生成された SQL を検証できる透明性は、AI のハルシネーションに対する重要なセーフガードであると同時に、クエリ性能やガバナンス基準の維持にも寄与します。
舞台裏では、Genie はエージェント型の推論を用いて質問を理解しつつ、Unity Catalog のアクセスルールに従います。不確かな場合は確認質問を行い、サンプルクエリや指示を通じてあなたのビジネス用語を学習��します。
たとえば「現在追跡されているユニークなフライトは何便?」という質問は、内部的には SELECT COUNT(DISTINCT icao24) FROM ingest_flights に変換されます。すごいのは、自然言語のリクエストで列名をまったく知っている必要がないことです。
別のコマンド「すべての航空機について高度と速度の相関を可視化して」は、速度と高度の相関を示す可視化を生成します。また「すべての航空機の位置を地図にプロットして」は、アビオニクスイベントの空間分布を示し、高度を色分けで表現します。
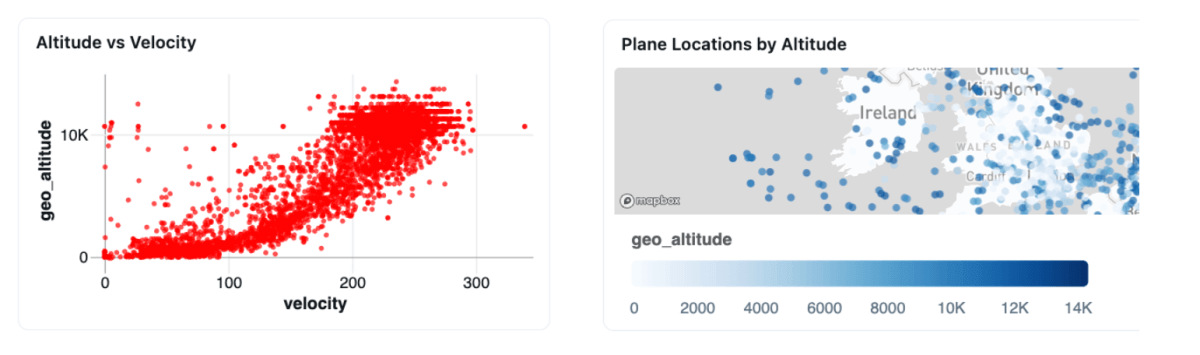
この機能は、状況の変化に応じてビジネス上の問いが急速に生まれるリアルタイム分析においてとりわけ強力です。エンジニアリングリソースが複雑な時間窓集計を含むカスタムクエリを書くのを待つ代わりに、ドメインの専門家がストリーミングデータを直接探究し、即時のオペレーション判断を後押しする洞察を得られます。
リアルタイムでデータを視覚化する
データが Delta または Iceberg テーブルとして利用可能になれば、事実上どんな�可視化ツールやグラフィックスライブラリでも使えます。たとえばここで示している可視化は Dash を用いて作成しており、Lakehouse Application として動作し、タイムラプス効果を備えています。
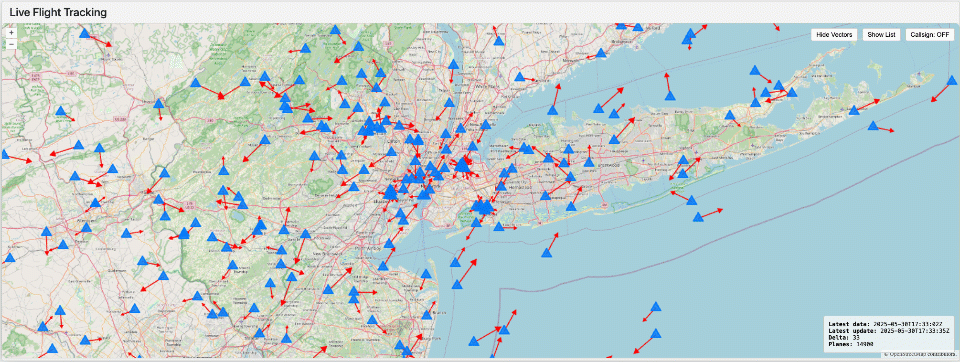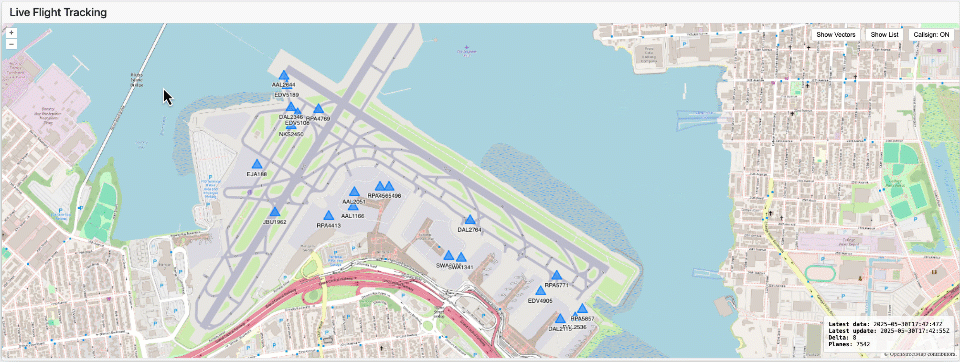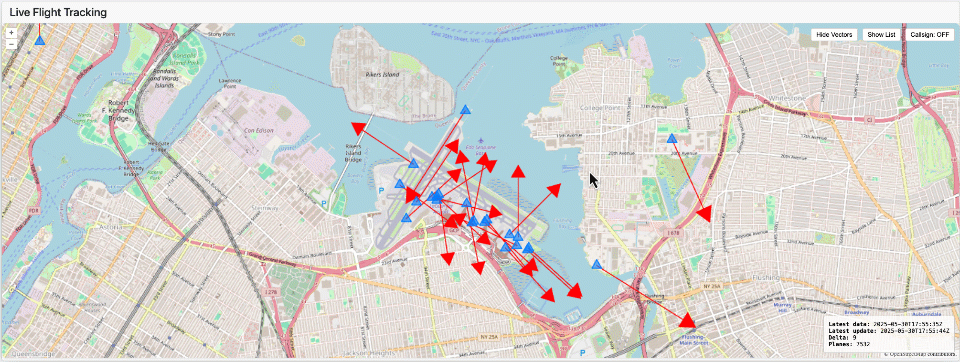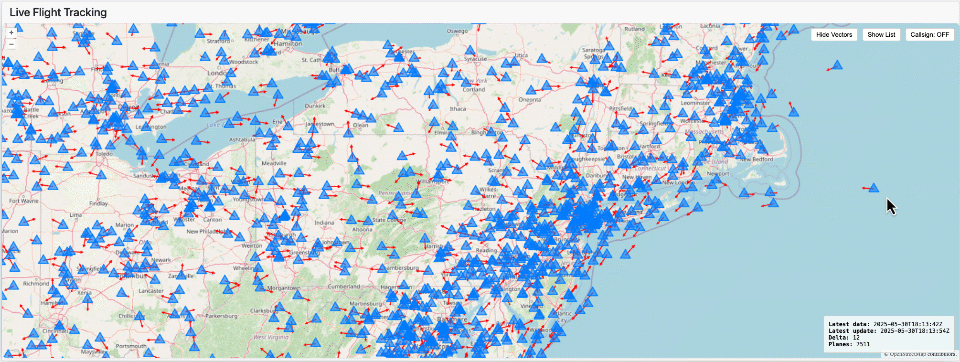
このアプローチは、現代のデータプラットフォームがデータエンジニアリングを簡素化するだけでなく、リアルタイムに視覚的でインパクトのあるインサイトを提供できるようチームを力づけることを示しています。
データエンジニアリングの未来について得た7つの教訓
このリアルタイムのアビオニクス・パイプラインを実装する中で、モダンなストリーミング・データアーキテクチャに関する基本的な教訓を学びました。
これらの7つの示唆は普遍的です。自然言語でアクセスでき、データエンジニアがインフラではなくビジネスロジックに集中でき、AI主導のインサイトが即時の業務判断を後押しする――そのとき、ストリーミング分析は競争優位になります。
1. カスタム PySpark データソースがギャップを埋める
PySpark のカスタムデータソースは、Lakeflow のマネージドコネクタと Spark の技術的な接続性の間にあるギャップを埋めます。API の複雑さを再利用可能なコンポーネントにカプセル化し、Spark 開発者にとって“ネイティブ”に感じられる形にします。こうしたコネクタの実装は決して簡単ではありませんが、Databricks Assistant やその他の AI 支援が開発プロセスで有益なガイダンスを提供してくれます。
これについて書いたり実際に使ったりしている人はまだ多くありませんが、PySpark カスタムデータソースは、より良いベンチマーク、テストの改善、より充実したチュートリアル、魅力的なカンファレンス発表など、多くの可能性を切り開きます。
2. 宣言的アプローチは開発を加速する
新しい Declarative Pipelines と PySpark データソースを組み合わせることで、見た目はコードスニペットのようでも実は完全な実装、という驚くほどのシンプルさを実現できました。記述行数を減らすことは生産性だけでなく運用信頼性にも直結します。宣言的パイプラインは、状態管理、チェックポイント、エラー復旧まわりのバグの“種別そのもの”を排除します。これは命令的なストリーミングコードを悩ませてきた問題です。
3. レイクハウスアーキテクチャは物事をシンプルにする
レイクハウスは、データレイク、ウェアハウス、そしてあらゆるツールを一つの場所にまとめてくれました。
開発中は、取り込みパイプラインの構築、DBSQL での分析実行、AI/BI Genie や Databricks Apps による可視化を、同じテーブルを使いながら素早く切り替えられました。どこからでも使える Databricks Assistant と、プラットフォーム上でリアルタイム可視化をデプロイできる能力により、ワークフローはシームレスになりました。
データプラットフォームとして始まったものが、コンテキスト切り替えやツールのやりくりなしの完全な開発環境へと変わったのです。
4. 可視化の柔軟性が鍵
レイクハウスのデータは幅広い可視化ツールやアプローチから利用できます。素早い探索にはクラシックなノートブック、即席のダッシュボードには AI/BI Genie、リッチでインタラクティブな体験にはカスタム Web アプリ――本記事の前半で示したように、Lakehouse Application として Dash を使う実例もあります。
5. ストリーミングデータは“会話的”になる
長年、リアルタイムの洞察にアクセスするには高度な技術スキル、複雑なクエリ言語、専門ツールが必要で、データと意思決定者の間に壁がありました。
今では、Genie を使ってライブのデータストリームに直接質問できます。Genie はストリーミングデータ分析を、技術的な難題からシンプルな会話へと変えてくれます。
6. AI ツールの支援は乗数効果を生む
レイクハウス全体に AI 支援が統合されていることは、作業スピードを根本的に変えました。特に印象的だったのは、Genie がプラットフォームのコンテキストから学習する様子です。
7. インフラとガバナンスの抽象化がビジネスへの集中を生む
スケーリングからエラー復旧まで、運用の複雑さをプラットフォームが自動で引き受ければ、チームは技術的な制約と闘うのではなく、ビジネス価値の創出に集中できます。インフラ管理からビジネスロジックへの重心移動こそが、ストリーミング・データエンジニアリングの未来を示しています。
TL;DR
ストリーミング・データエンジニアリングの未来は、AI支援、宣言的、そしてビジネス成果への一点集中です。このアーキテクチャ転換を受け入れた組織は、データに対してより質の高い問いを立て、より多くの解決策をより速く生み出せるようになります。
もっと詳しく知りたいですか?
- この例のためのガイド付きGitHubリポジトリ
- OpenSkyネットワーク
- Matthias Schäfer、Martin Strohmeier、Vincent Lenders、Ivan Martinovic、Matthias Wilhelm。"OpenSkyの立ち上げ:研究のための大規模ADS-Bセンサーネットワーク"。センサーネットワークの情報処理に関する第13回IEEE/ACM国際シンポジウムの議事録、83-94ページ、2014年4月。
- 新しいPythonデータソースAPIでデータ取り込みを簡素化
- Honeywellは、ストリーミングデータのためのLakeflow宣言的パイプラインを選択します
- Volvoは、Databricks Lakeflow Declarative Pipelinesを使用してスペアパーツの在庫にリア��ルタイムで可視性を提供します。
実践してみましょう!
完全なフライト追跡パイプラインはDatabricks Free Editionで実行することができ、LakeflowはGitHubリポジトリで概説された数ステップで誰でも利用可能です。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。