トップチームはインテリジェントなデータパイプラインで成功を収めています。
データパイプラインのベストプラクティスをコード化
必要なデータ変換を宣言するだけです。残りはSpark宣言型パイプラインが処理します。効率的な取り込み
本番運用に対応したデータパイプラインの構築は、インジェストから始まります。Spark宣言型パイプラインを使用すると、データエンジニア、Python開発者、data scientists、SQLアナリストは効率的にデータを取り込むことができます。Databricks プラットフォームでは、バッチ、ストリーミング、CDC にかかわらず、Apache Spark™ でサポートされているあらゆるソースからデータを読み込めます。
インテリジェントな変換
Spark 宣言型パイプラインは、わずか数行のコードから、バッチまたはストリーミングのデータパイプラインを構築・実行するための最も効率的な方法を決定し、複雑さを最小限に抑えながらコストやパフォーマンスを自動的に最適化します。
自動化された運用
Spark 宣言型パイプラインは、すぐに使えるベストプラクティスを体系化し、依存関係管理、スケーリングとリカバリー、データ品質ルールなどを自動化することで、パイプライン開発を簡素化します。Spark宣言型パイプラインを使用すると、エンジニアはパイプライン インフラストラクチャの運用と保守ではなく、高品質なデータの提供に集中できます。
データパイプラインの構築を簡素化
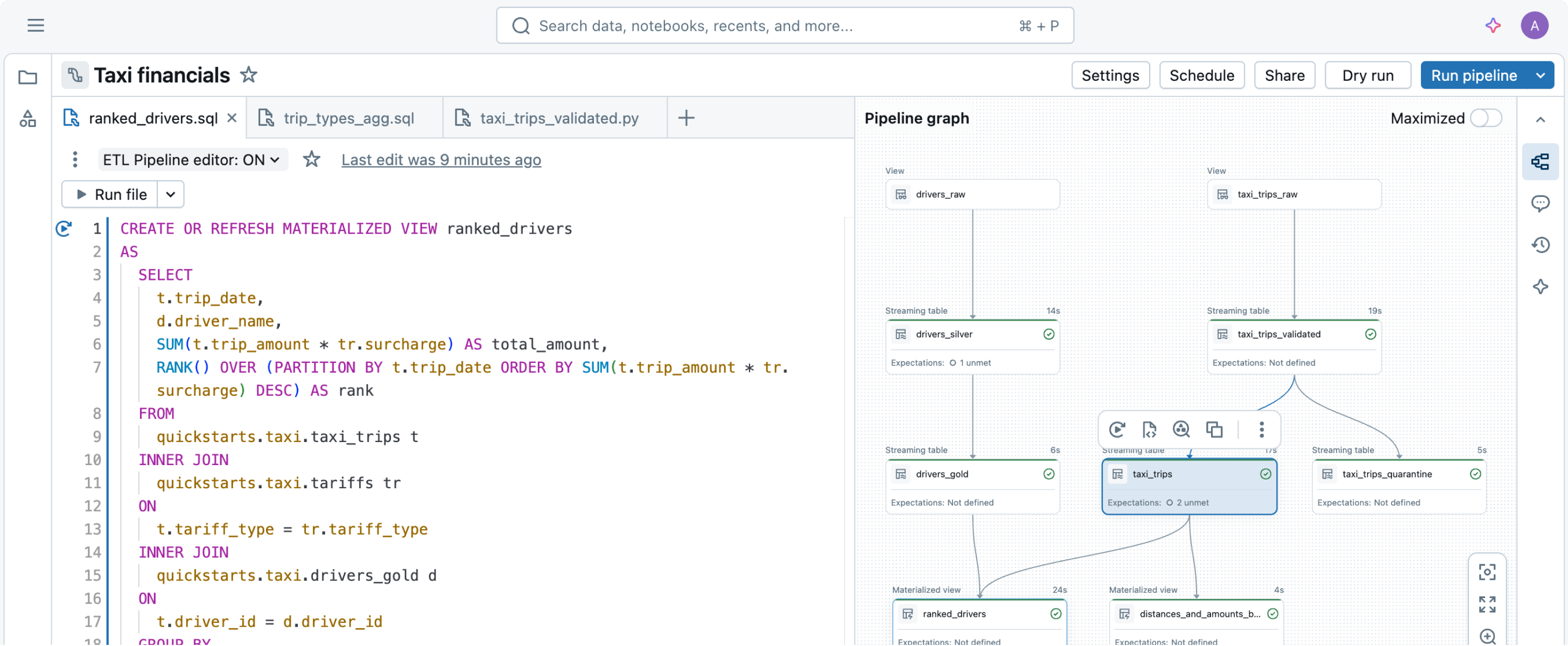
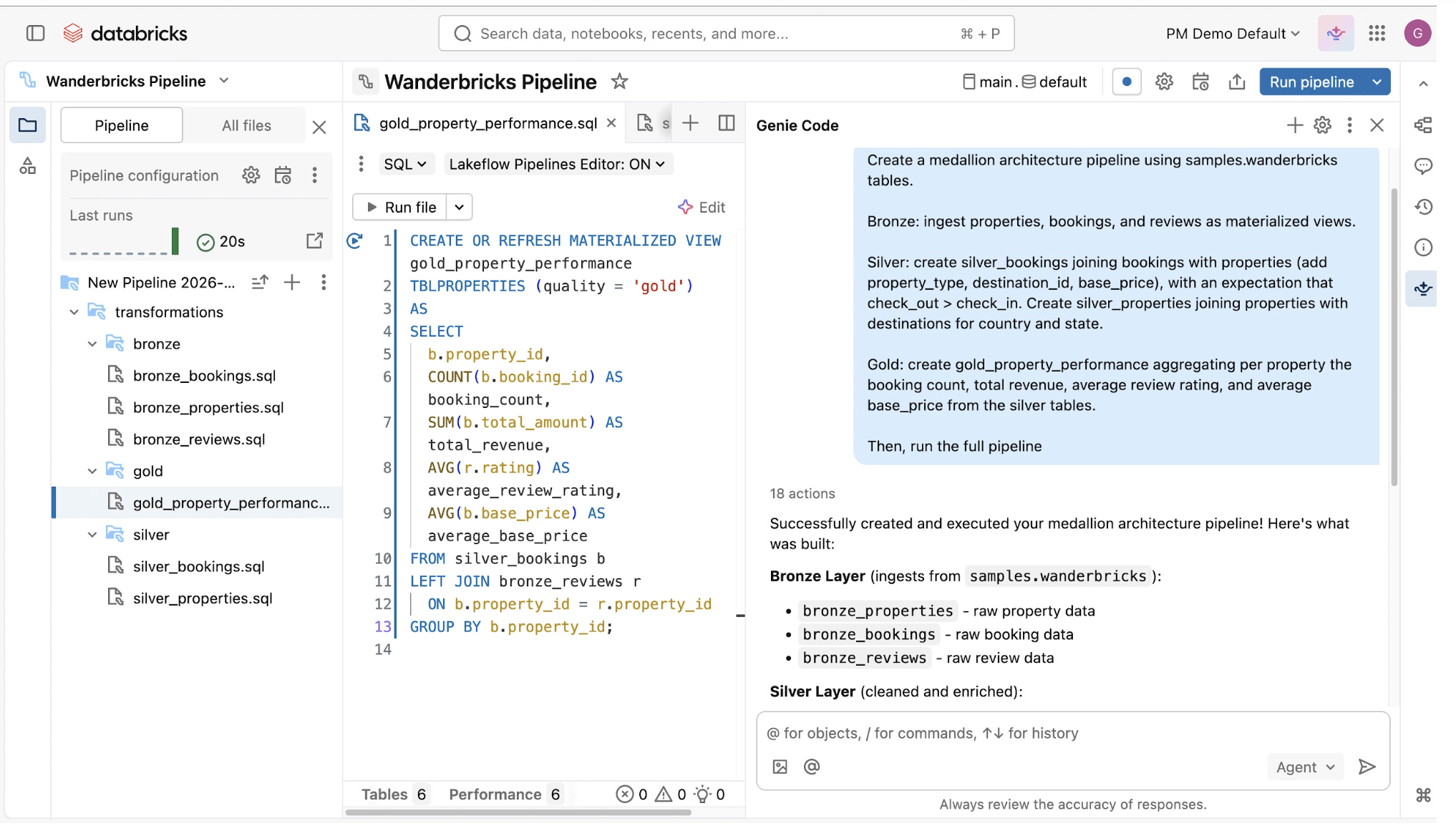
データパイプラインの構築と運用は難しいことがありますが、そうである必要はありません。Spark宣言型パイプライン は、パワフルかつシンプルに設計されているため、わずか数行のコードで堅牢な ETL を実行できます。Genie Codeを使用すると、自然な会話を通じてETLワークロードの自動化、クエリの最適化、パイプラインの構築ができます。
Spark宣言型パイプラインは、バッチ処理とストリーム処理のためのSparkの統合APIを活用しているため、処理モードを簡単に切り替えることができます。

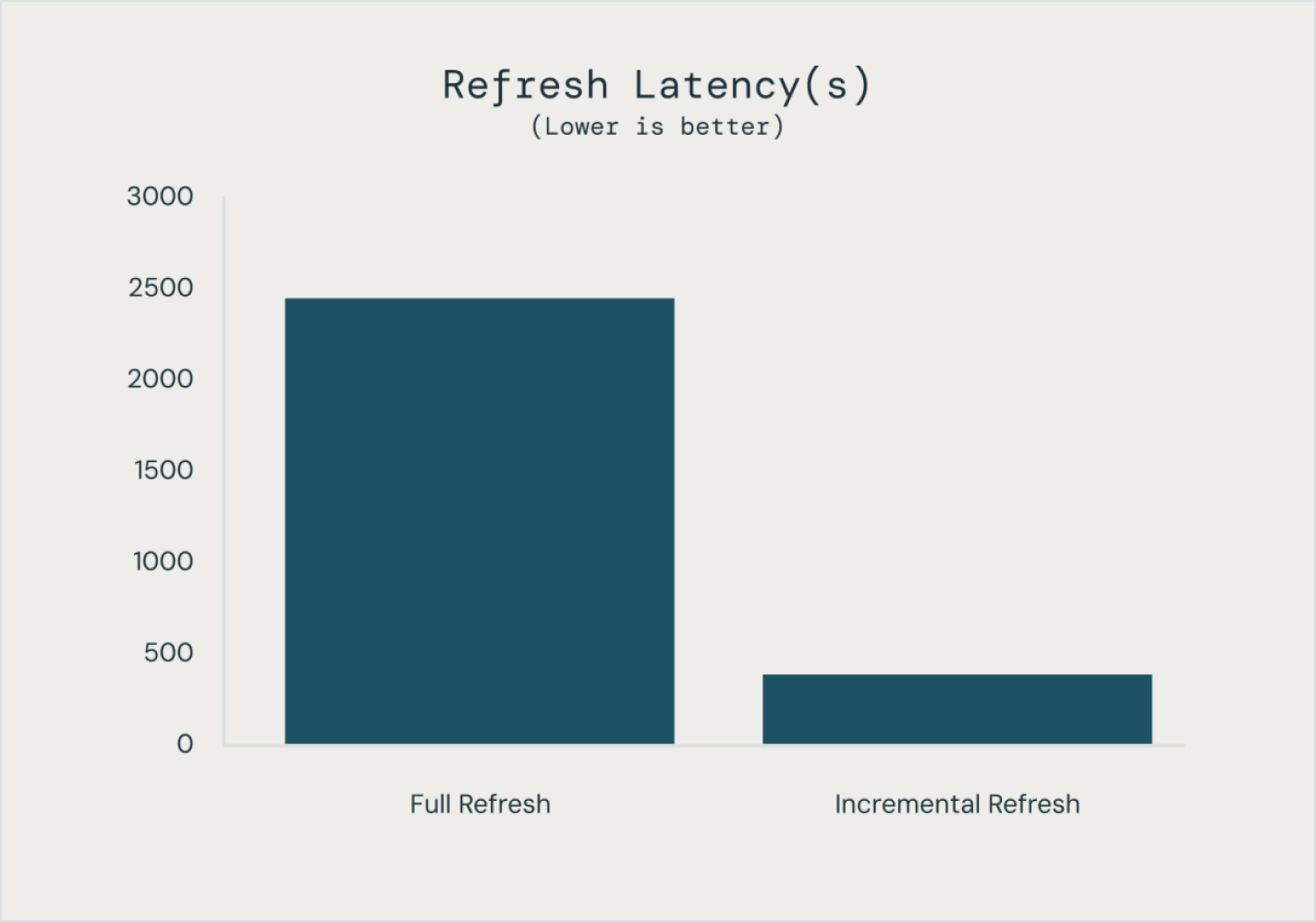
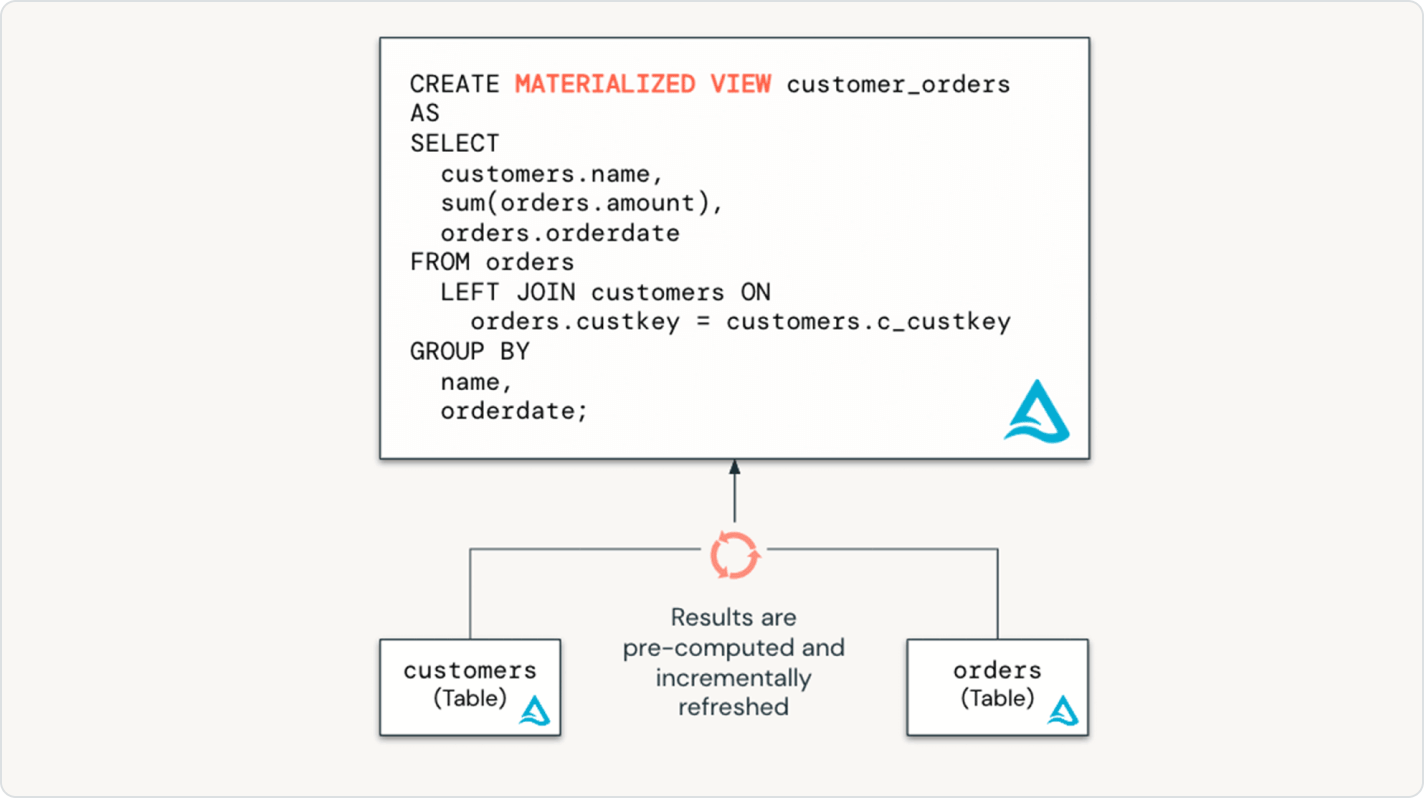
Spark宣言型パイプライン を使用すると、ストリーミング テーブルとマテリアライズド ビューで増分データパイプライン全体を宣言することで、パイプラインのパフォーマンスを簡単に最適化できます。
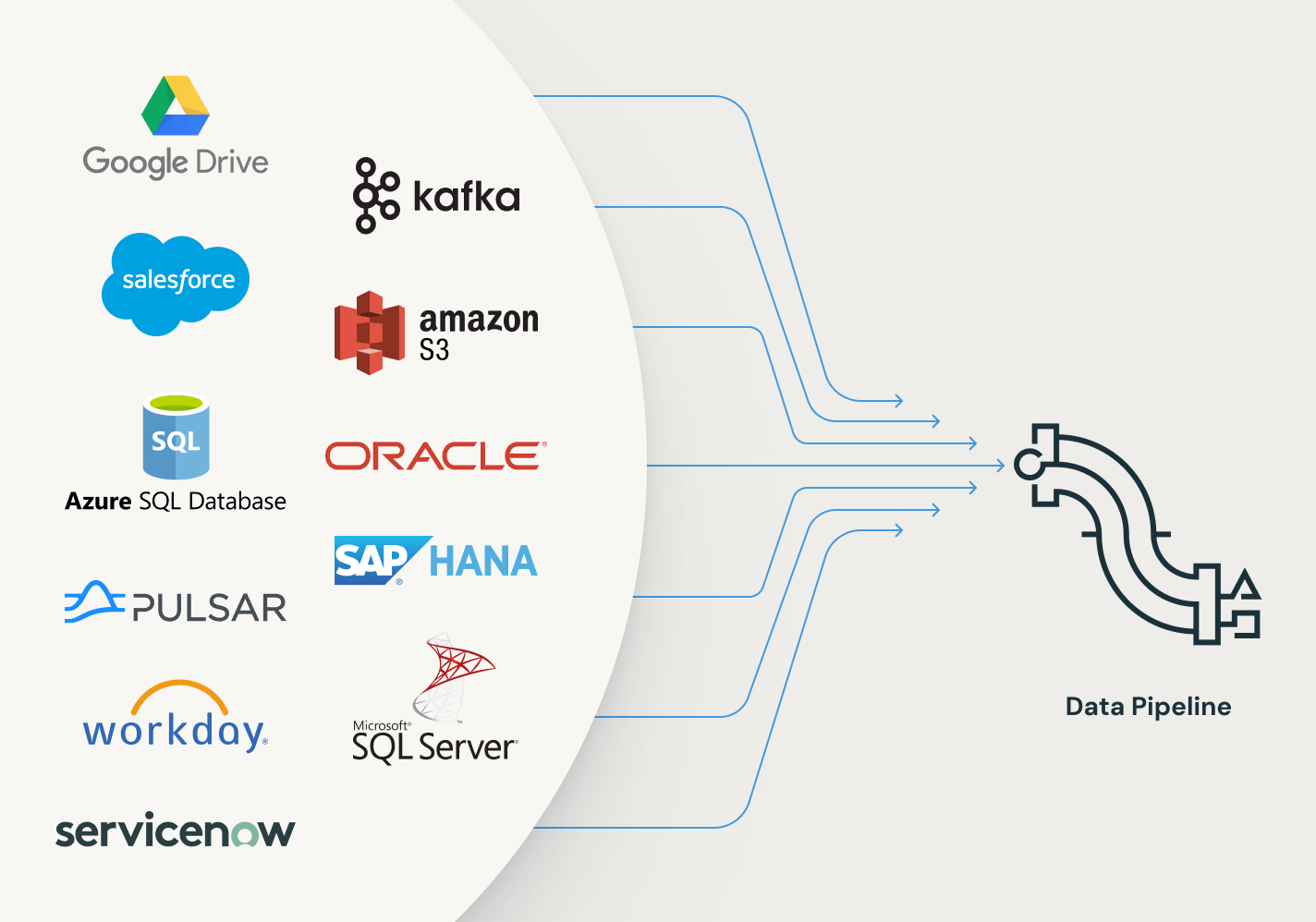
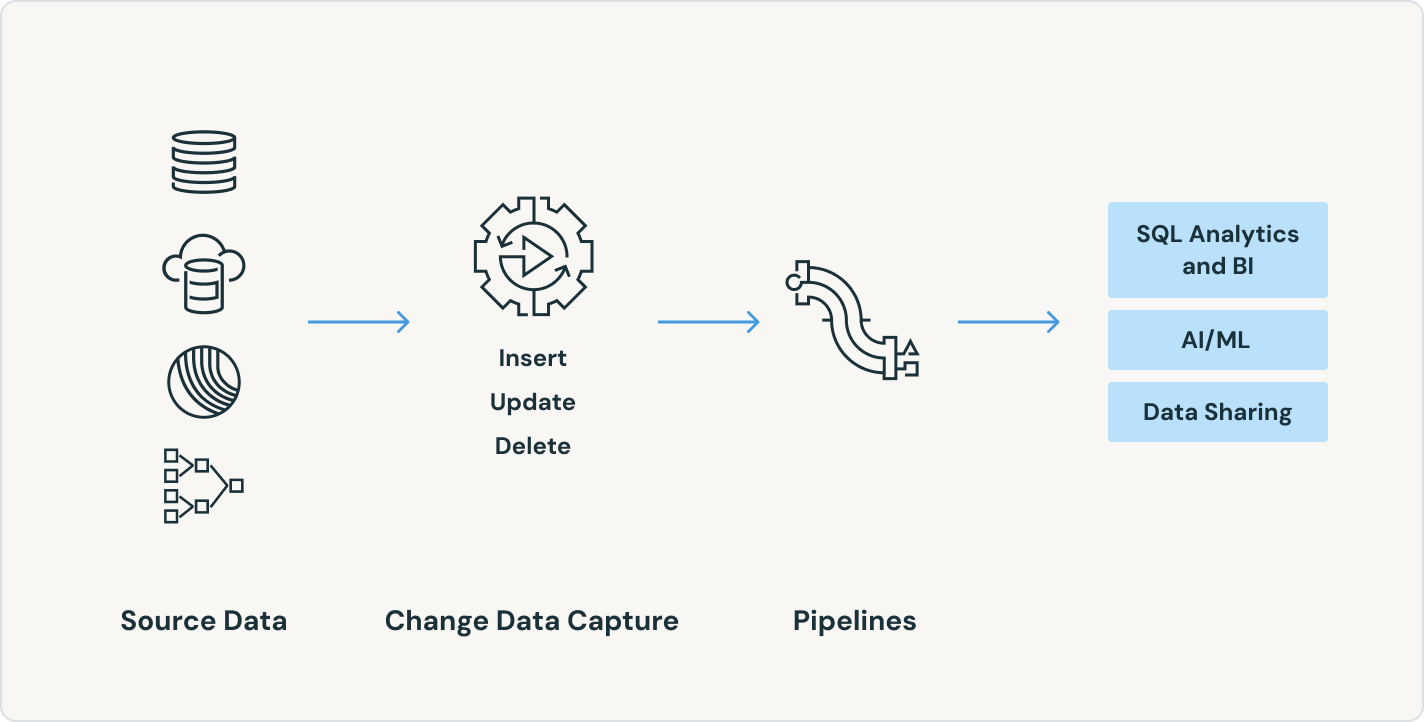
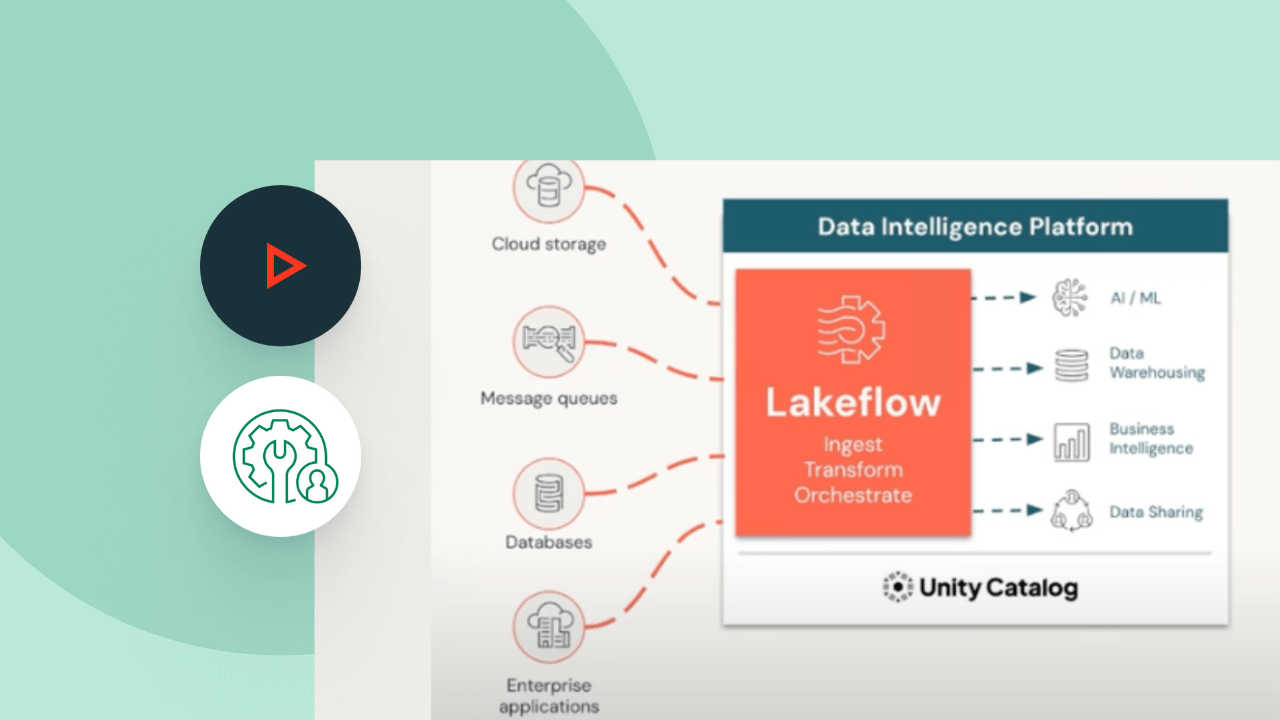
Spark宣言型パイプライン は、幅広いソースとシンクのエコシステムをサポートしています。クラウドストレージ、メッセージバス、変更データフィード、データベース、エンタープライズアプリなど、あらゆるソースからデータをロードします。
エクスペクテーションを使用すると、テーブルに到着するデータがデータ品質要件を満たしていることを保証し、パイプラインが更新されるたびにデータ品質に関する知見を提供できます��。
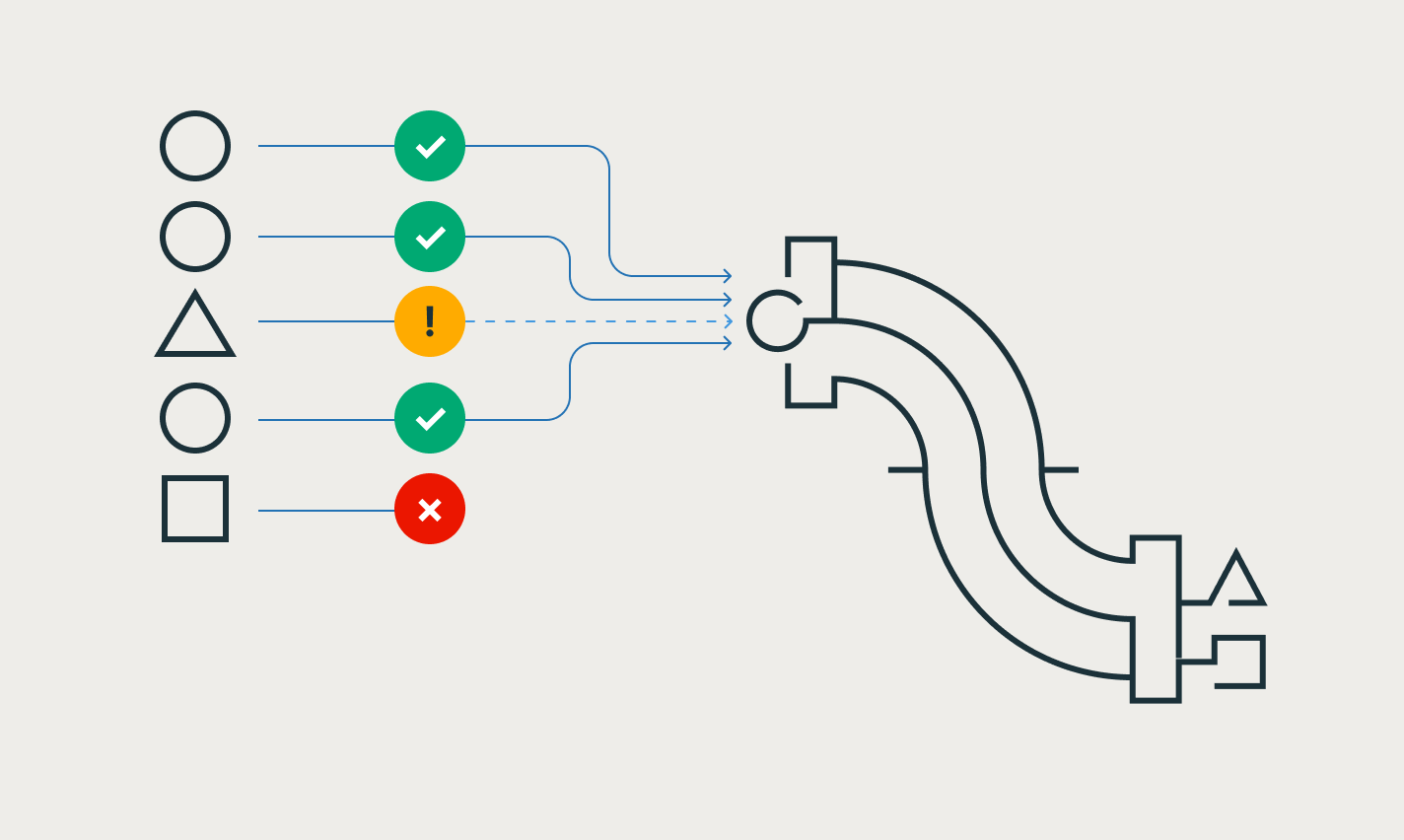
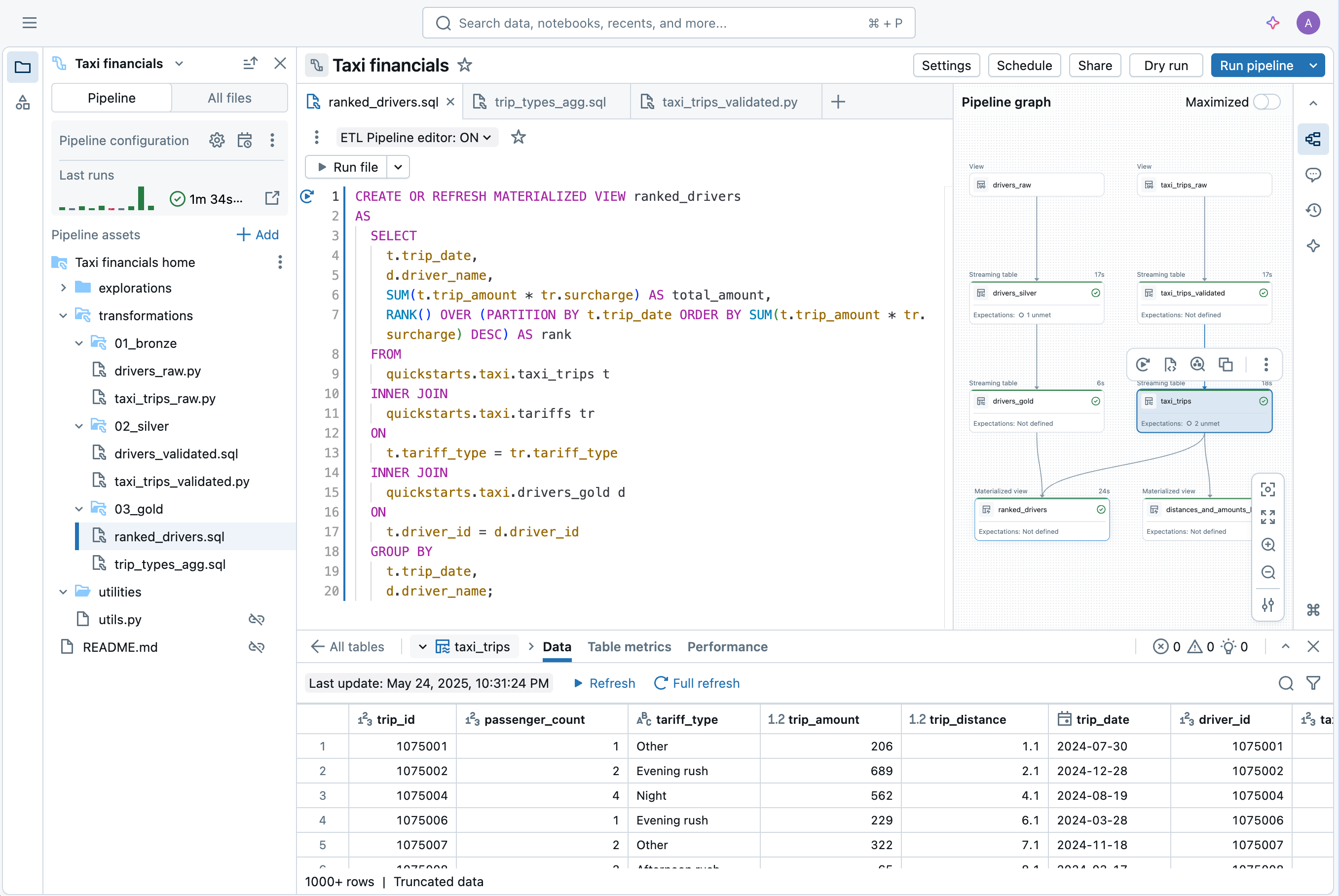
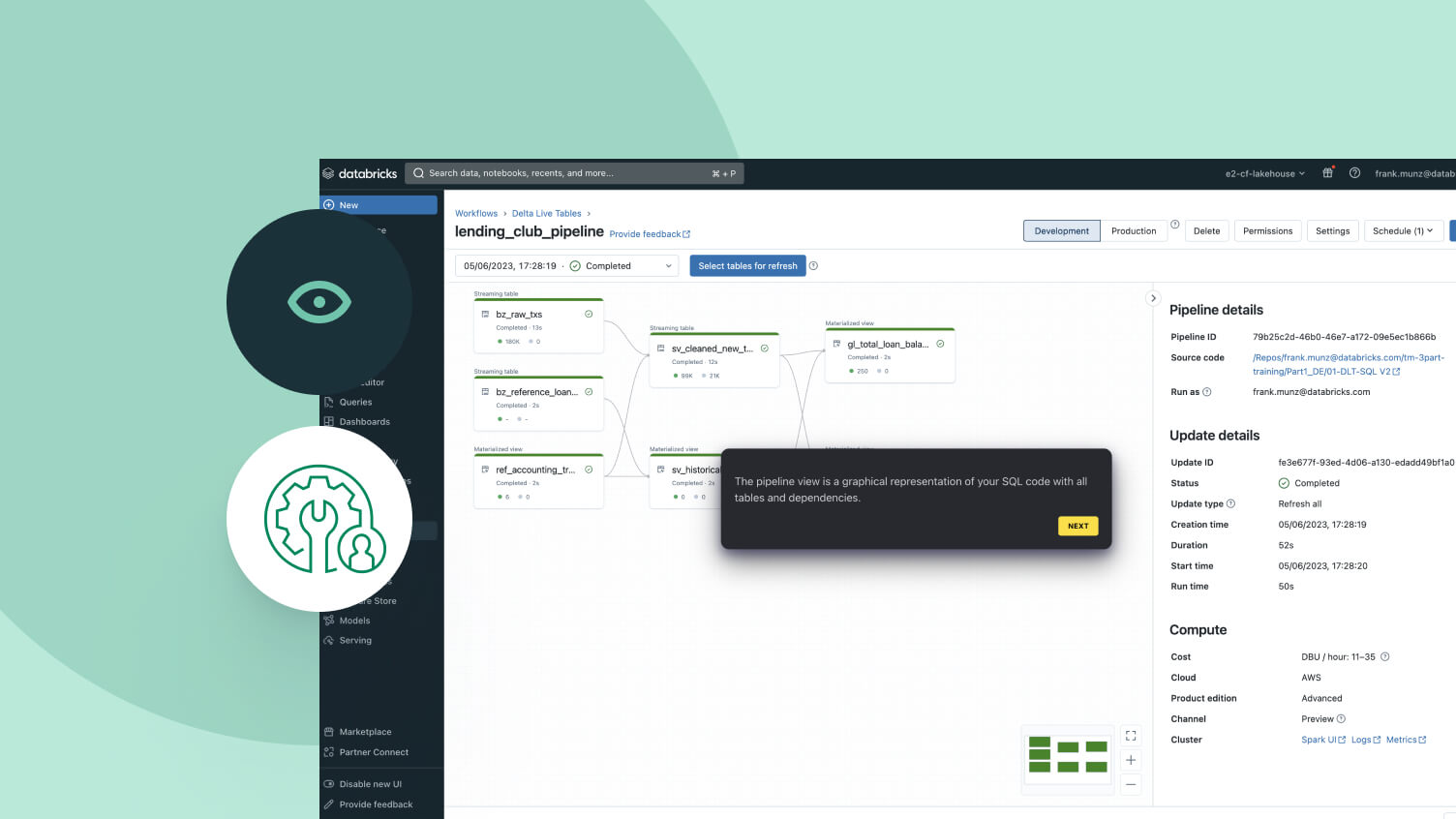
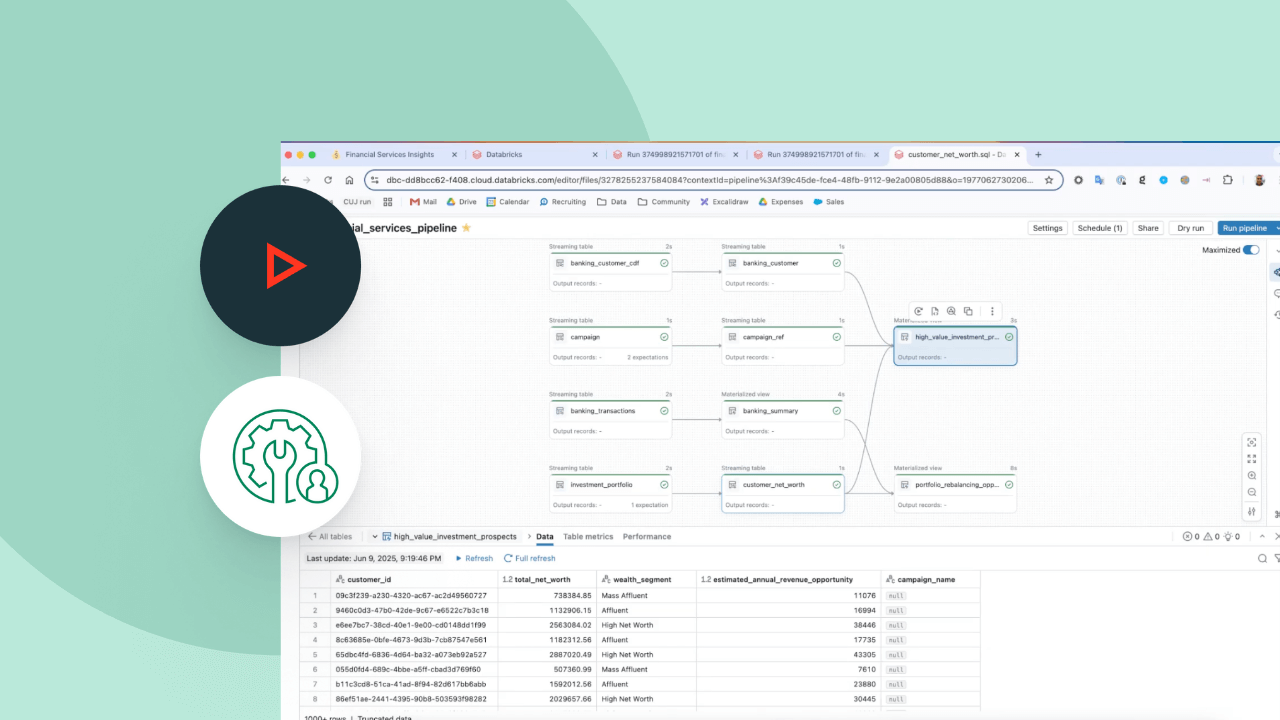
コンテキスト スイッチなしで、IDE でデータ エンジニアリング用のパイプラインを開発できます。DAG、データプレビュー、実行知見を1つのUIで確認できます。オートコンプリート、インラインエラー、診断機能により、コードを簡単に開発できます。
その他の機能
データパイプラインを合理化

使用量に応じた価格設定で、支出を抑制
使用した製品に対する秒単位での課金となります。さらに詳しく
Databricksプラットフォームで提供される、その他の統合されたインテリジェントなオファリングもご覧ください。
LakeFlow Connect
あらゆるソースからの効率的なデータ取り込みコネクタと、Databricks Platformとのネイティブ統合により、統一されたガバナンスの下で、アナリティクスとAIへ簡単にアクセスできるようになります。

Lakeflow Jobs
ETL、アナリティクス、Machine Learningパイプラインのマルチタスクワークフローを簡単に定義、管理、監視できます。幅広い対応タスクタイプ、深い観察可能性、高い信頼性により、データチームはパイプラインをより自動化・オーケストレーションし、生産性を高める力を得られます。

Genie Code
データ業務のための、あなたの自律型AIパートナー。

レイクハウスストレージ
lakehouse内のあらゆる形式と種類のデータを統合し、すべての**アナリティクス**および**AI**ワークロードで利用できるようにします。

Unity Catalog
Databricksプラットフォームに組み込まれた、データとAIのための業界唯一の統合型オープンガバナンスソリューションにより、すべてのデータ資産をシームレスに統制できます。
Databricks のプラットフォーム
Databricksプラットフォームが、データおよびAIワークロードをどのように実現するかをご覧ください。



