Databricks上でドメインエキスパートがガイドする自己最適化サッカーチャットボット
ディフェンスコーディネーターが対戦相手の傾向を予測するのを助け、専門家のフィードバックに基づいて継続的に最適化するエージェント型アシスタントを作成、デプロイ、評価、管理するための実践的なガイド。
によって ウェズリー・パスフィールド 、 ニック・ラゴネーゼ による投稿
- 目的: プレーバイプレー、参加状況、選手名簿のデータに対し、管理された本番運用グレードのツールを使用して、「このオフェンスはどう動くか?」といった質問に答える、コーチ向けの自律型アシスタントを構築します。* アプローチ: Unity Catalog 関数(Delta に対する SQL アナリティクス)でツール呼び出しエージェントを作成し、MLflow Tracing を使用して Agent Framework 経由でデプロイします。MLflowのラベリングセッションでキャプチャされた専門家のフィードバックが、アライメントされたジャッジ(align())をトレーニングし、そのジャッジが自動プロンプト改善(optimize_prompts())を駆動することで、専門的なサッカーの知識をシステムに直接エンコードする自己最適化ループを実装します。* 結果: コーディネーターは、迅速なイテレーションと品質チェックにより、試合週の導入に向けて、状況に応じた傾向(ダウンと距離、フォーメーション/選手構成、ツーミニッツドリル、スクリーン率)を把握できます。開発者はあらゆるドメインで再利用可能なアーキテクチャを得られます。専門家のフィードバックを収集し、ユースケースにとっての「良い」状態をジャッジに反映させ、そのジャッジによるガイダンスでプロンプトを最適化することで、システムを継続的に改善できます。
汎用的なLLM審査員と静的なプロンプトでは、ドメイン固有のニュアンスを捉えることはできません。フットボールの守備分析が「良い」ものであるかを判断するには、カバレッジスキーム、フォーメーションの傾向、状況に応じたコンテキストといった、フットボールに関する深い知識が必要です。汎用的な評価者は、これを見逃してしまいます。法的レビュー、医療トリアージ、財務デューデリジェンスなど、専門家の判断が重要となるあらゆるドメインについても同様です。
この記事では、Databricks Agent Framework 上に構築された自己最適化エージェントのアーキテクチャについて解説します。このアーキテクチャでは、MLflow を使用して企業固有の専門知識が AI の品質を継続的に向上させ、開発者がエクスペリエンス全体を制御します。この記事では、アメリカン フットボールのディフェンシブ コーディネーター (DC) アシスタントを実例として使用します。これは、"サードダウン残り 6 ヤードの 11 人フォーメーションで誰がボールを受けますか" や "ハーフの残り 2 分で相手チームは何をしますか" といった質問に答えられるツール呼び出しエージェントです。次の例は、このエージェントが Databricks Apps を介してユーザーと対話する様子を示しています。

エージェントから自己最適化システムへ
このソリューションには、エージェントを構築し、専門家のフィードバックを得て継続的に最適化するという 2 つのフェーズがあります。
構築
- データの取り込み: Unity Catalog の管理対象 Delta テーブルにドメインデータ (実況、参加状況、選手名簿) を読み込みます。
- このエージェントのデータとして、
nflreadpyから 2 年間 (2023 ~ 2024 年) のフットボールの参加データとプレーバイプレーデータを取得しました。
- このエージェントのデータとして、
- ツールの作成: 抽出されたデータを活用し、エージェントが呼び出せる Unity Catalog ツールとして SQL 関数を定義します。
- エージェントの定義とデプロイ: ツールを
ResponsesAgentに接続し、Prompt Registryにベースライン システム プロンプトを登録して、Model Servingにデプロイします。 - 初期評価: LLM 審査員による自動評価をランし、カスタム審査員のベースライン バージョンを使用してトレースを記録します。
最適化
- 専門家のフィードバックを収集:SMEがエージェントの出力をレビューし、MLflowのラベリングセッションを通じて構造化されたフィードバックを提供します。
- 審査員の調整: MLflow の
align()関数を使用して、ベースライン LLM 審査員を調整して専門家の好みに一致させ、このドメインにとって「良い」とは何かを教えます。 - プロンプトの最適化: MLflowの
optimize_prompts()は、アラインされたジャッジに導かれたGEPAオプティマイザを使用して、元のシステムプロンプトを繰り返し改善します。 - 繰り返し: 各 MLflow ラベリング セッションはジャッジの改善に使用され、それがさらにシステムプロンプトの最適化に使用されます。このプロセス全体は自動化が可能で、パフォーマンスのベンチマークを超える新しいプロンプトバージョンを自動的に昇格させたり、観測された失敗モードに基づいてツールやデータを追加するなど、エージェントへの手動更新の判断材料にしたりすることができます。
ビルドフェーズで初期プロトタイプを構築し、最適化フェーズで本番運用を加速させます。その際、ドメインエキスパートのフィードバックをエンジンとしてエージェントを継続的に最適化します。
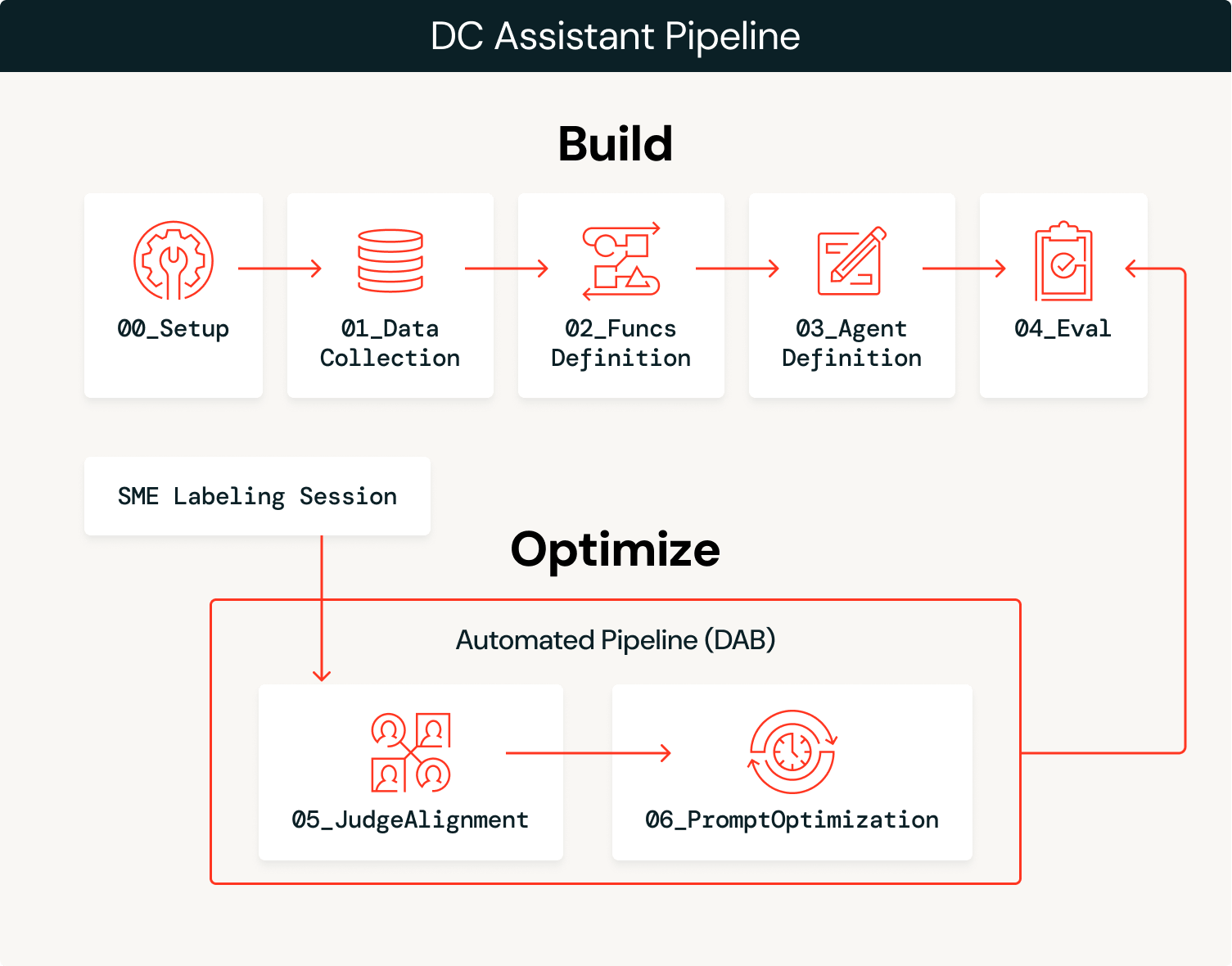
アーキテクチャの概要
エージェントは確率論と決定論のバランスを取ります。LLMはユーザーのクエリーが持つ意味的な意図を解釈して適切なツールを選択し、決定論的なSQL関数は100%の精度でデータを取得します。たとえば、コーチが「相手はブリッツにどう対抗してきますか?」と質問すると、LLMはこれをパスラッシュ/カバレッジ分析のリクエストとして解釈し、success_by_pass_rush_and_coverage()を選択します。SQL関数は、基になるデータから正確な統計を返します。Unity Catalog関数を使用すること�で、統計が100%正確であることが保証され、LLMは会話のコンテキストを処理します。
| ステップ | テクノロジー |
|---|---|
| データを取り込む | Delta Lake + Unity Catalog |
| ツールを作成 | Unity Catalog機能 |
| エージェントをデプロイ | ResponsesAgent + agents.deploy() によるモデルサービング |
| 審査員としてのLLMによる評価 | 組み込みおよびカスタムのジャッジを使用した MLflow GenAI evaluate() |
| フィードバックの収集 | 専門家のフィードバックを得るためのMLflow ラベリングセッション |
| ジャッジのアライン | カスタムSIMBAオプティマイザを使用したMLflow align() |
| プロンプトを最適化する | GEPA オプティマイザを使用した MLflow optimize_prompts() |
DC Assistant の実装のコードと出力とともに、各ステップを順に見ていきましょう。
構築
1. データを取り込みます。
セットアップ ノートブック(00_setup.ipynb)では、ワークフロー全体で使用されるすべてのグローバル構成変数(ワークスペース カタログ/スキーマ、MLflow エクスペリメント、LLM エンドポイント、モデル名、評価データセット、Unity Catalog ツール名、認証設定)を定義します。この設定は config/dc_assistant.json に永続化され、後続のすべてのノートブックで読み込まれることで、パイプライン全体の一貫性が確保されます。このステップは任意ですが、全体的な構成に役立ちます。
この構成を導入することで、nflreadpy を介してフットボールのデータを読み込み、増分処理を適用してエージェントが使用できるように準備します。具体的には、未使用の列の削除、スキーマの標準化、クリーンな Delta テーブルの Unity Catalog への永続化などです。ここでは、データ処理の大部分には触れずにデータを読み込む簡単な例を示します。
このプロセスの出力は、Unity Catalog 内のガバナンスが適用された Delta テーブル (プレーバイプレー、参加、名簿、チーム、選手) であり、ツールの作成とエージェントによる使用が可能です。
2. ツールを作成する。
エージェントは、基になるデータをクエリーするための決定論的なツールを必要とします。これらを、さまざまな状況的側面における攻撃傾向をコンピュートする Unity Catalog SQL 関数として定義します。各関数は team や season などのパラメータを受け取り、エージェントがコーディネーターの質問に答えるために使用できる集計された統計情報を返し�ます。この例では SQL ベースの関数のみを使用していますが、プロセスを監督する LLM を補足するためにエージェントが活用できる追加機能として、Python ベースの UC 関数、ベクトル検索インデックス、モデル コンテキスト プロトコル (MCP) ツール、Genie スペースを設定することもできます。
次の例は、パスラッシャーの数とディフェンスカバレッジの種類でグループ化された、パス/ランの分割、EPA (期待追加得点)、成功率、獲得ヤードをコンピュートするsuccess_by_pass_rush_and_coverage()を示しています。この関数には、その目的を説明するCOMMENTが含まれており、LLMはこれを使用していつ呼び出すかを決定します。
これらの関数はUnity Catalog内に存在するため、役割ベースのアクセス制御、リネージ追跡、ワークスペース全体での発見可能性といった、プラットフォームのガバナンスモデルを継承します。チームはロジックを重複させることなくツールを見つけて再利用でき、管理者はエージェントがどのデータにアクセスでき��るかについての可視性を維持できます。
3. エージェントを定義してデプロイします。
AI Playgroundを使用するだけで、エージェントを簡単に作成できます。使用したいLLMを選択し、Unity Catalogツールを追加し、システムプロンプトを定義して「Create agent notebook」をクリックすると、ResponsesAgent形式のエージェントを生成するノートブックがエクスポートされます。次のスクリーンショットは、このワークフローの動作を示しています。エクスポートされたノートブックにはエージェントの定義構造が含まれており、UCFunctionToolkit を介して UC 関数がエージェントに接続されています。
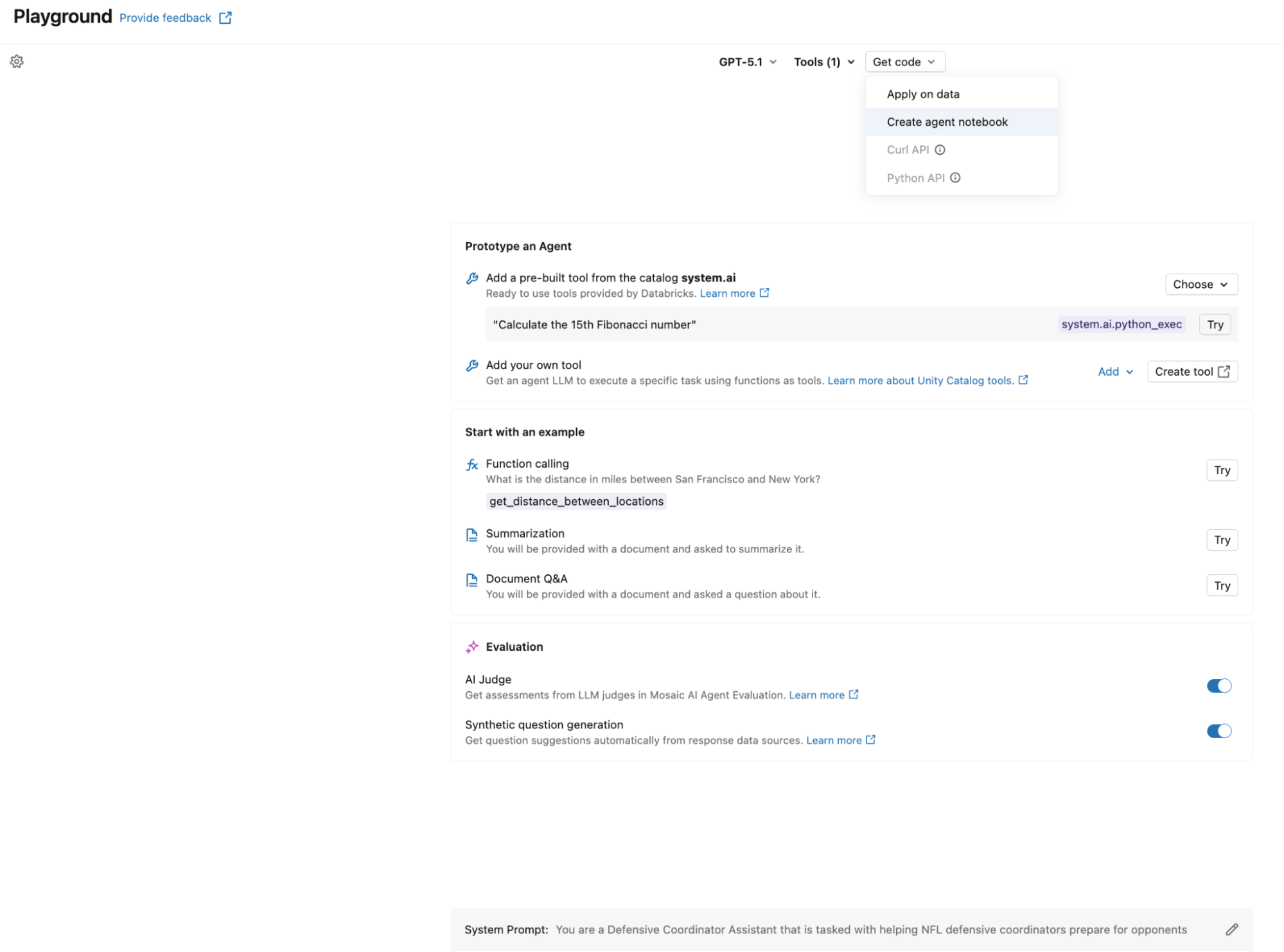
自己最適化ループを有効にするには、システムプロンプトをハードコーディングするのではなく、プロンプトレジストリに登録します。これにより、最適化フェーズでエージェントを再デプロイすることなくプロンプトを更新できます。
エージェントコードをテストし、モデルをUnity Catalogに登録すれば、以下のコードのように簡単に永続的なendpointにデプロイできます。これにより、MLflow Tracingが有効になり、リクエスト/レスポンスをロギングするための推論テーブルと自動スケーリングを備えたモデルサービングエンドポイントが作成されます。
エンドユーザーがアクセスできるよう、エージ��ェントを Databricks アプリとしてデプロイすることもできます。これにより、コーディネーターやアナリストは、ノートブックや API にアクセスすることなく、チャットインターフェースを直接使用できます。導入部のスクリーンショットは、このアプリベースのデプロイメントが動作している様子を示しています。
4. 初期評価。
エージェントをデプロイした後、LLMジャッジを使用して自動評価を実行し、ベースラインとなる品質測定値を確立します。MLflow は 複数のジャッジタイプをサポートしており、ここでは 3 種類を組み合わせて使用します。
組み込みの審査員は、一般的な評価基準をすぐに処理します。RelevanceToQuery()は、応答がユーザーの質問に対応しているかどうかをチェックします。ガイドラインベースの審査員は、特定のテキストベースのルールに照らして合否判定方式で評価します。応答が適切なプロフットボールの専門用語を使用するように、ガイドラインを定義します。
カスタムジャッジは make_judge() を使用して、スコアリング基準を完全に制御しながらドメイン固有の評価を行います。これは、最適化フェーズで専門家のフィードバックに合わせて調整するジャッジです。
すべてのジャッジが定義されたので、データセットに対して評価を実行できます。
カスタムのfootball_analysis_base評価者はベースライン スコアを提供しますが、それは真のドメイン専門知識というよりは、LLMがその判断に使用できるルーブリックをゼロから提供しようとするベストエフォートの試みを反映しているにすぎません。MLflow エクスペリメント UIには、このベースライン評価者に対するエージェントのパフォーマンスと、各例のスコアの根拠が表示されます。
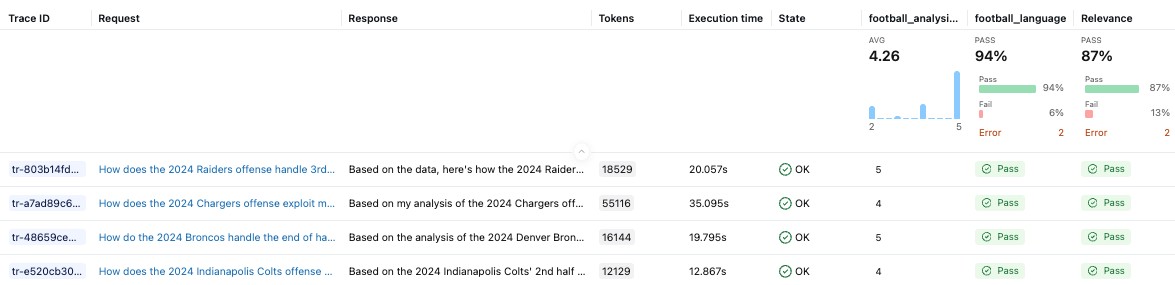

最適化フェーズでは、フットボール分析ジャッジをSME (主題専門家) の好みに合わせてアラインし、ディフェンスコーディネーターの分析にとって「良い」が実際に何を意味するかを教えます。
最適化
5. 専門家のフィードバックを収集する。
エージェントがデプロイされ、ベースライン評価が完了すると、最適化ループに入ります。ここで、ドメインの専門知識がシステムにエンコードされます。まず調整済みのLLM審査員を通じて、次にその調整済み審査員に導かれるシステムプロンプトの最適化を通じてエージェントに直接エンコードされます。
まず、make_judge() で作成したフットボール分析審査員と同じ指示と評価基準を使用するラベル スキーマを作成します。次に、ドメイン エキスパートが evaluate() ジョブで使用したのと同じトレースに対する応答を確認し、レビュー アプリ (下の図) を介してスコアとフィードバックを提供できるラベリング セッションを作成します。
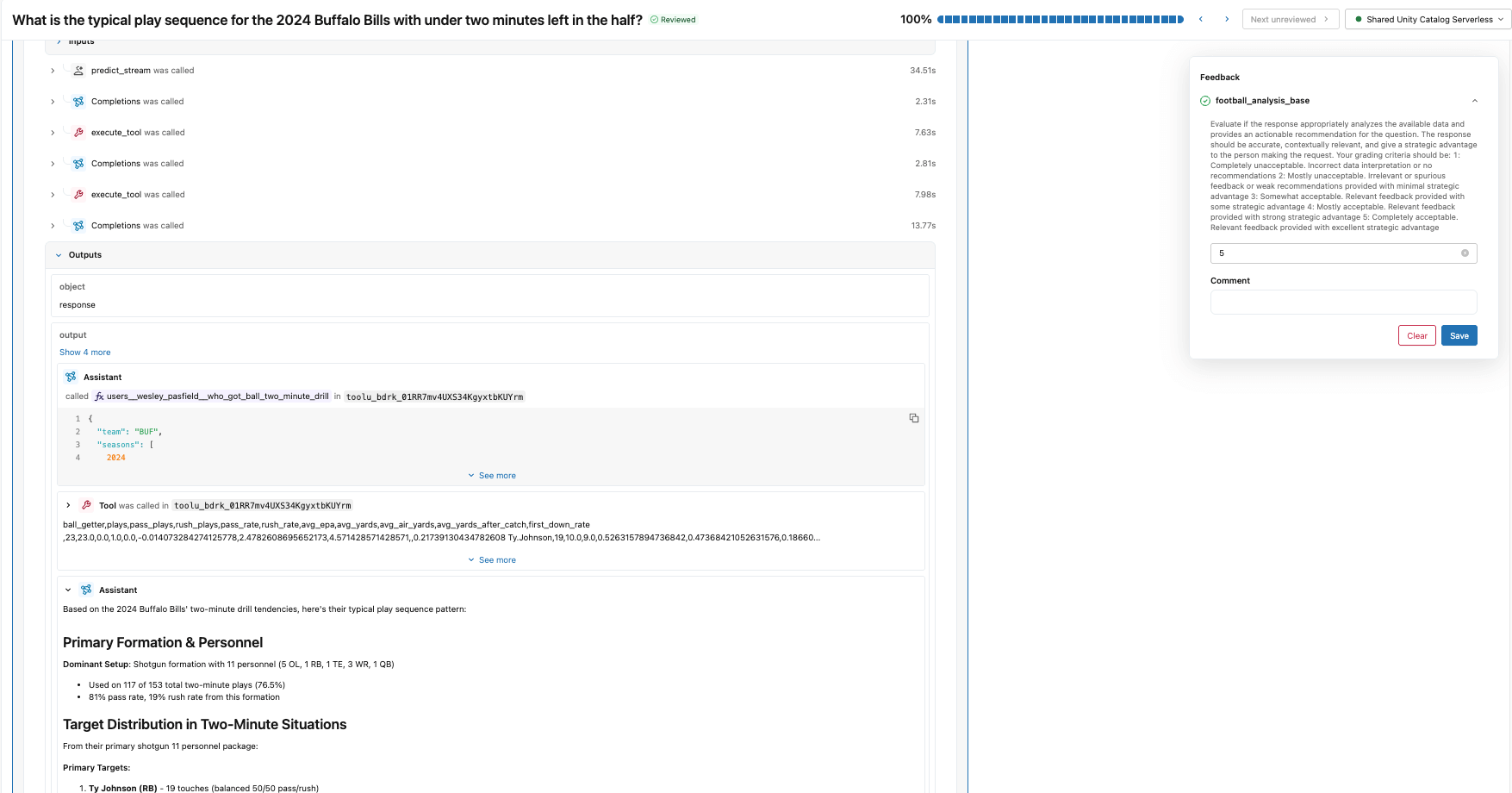
このフィードバックは、ジャッジのアライメントのためのグラウンドトゥルースとなります。ベースラインジャッジと専門家のスコアが乖離している箇所を見ることで、ジャッジがこの特定のドメインについて何を間違えているかを学習します。
6. 審査員の調整。
ドメイン エキスパートのフィードバックと LLM 審査員のフィードバックの両方を含むトレースができたので、MLflow の align() 機能を利用して、LLM 審査員をドメイン エキスパートのフィードバックに合わせることができます。調整された審査員は、ドメイン エキスパートの視点と組織固有のデータを反映します。アラインメントは、これまで不可能だった方法でドメイン エキスパートを開発プロセスに参加させます。ドメイン フィードバックは、システムが品質を測定する方法を直接形成し、エージェントのパフォーマンス メトリックを信頼性が高くスケーラブルなものにします。
align() を使用すると、独自のオプティマイ�ザまたはデフォルトのバイナリ SIMBA (Simplified Multi-Bootstrap Aggregation) オプティマイザを使用できます。この場合、カスタムの SIMBA オプティマイザを活用して、リッカート尺度審査員を調整します。
次に、プロセスを通じてタグ付けした、LLM 判定スコアと専門家フィードバックの両方を含むトレースを取得します。これらのペアスコアは、SIMBAが一般的な判断と専門家の判断とのギャップを学習するために使用するものです。
次のスクリーンショットは、進行中のアライメントプロセスを示しています。モデルは、LLM ジャッジと専門家フィードバックの間のギャップを特定し、そのギャップを埋めるためにジャッジに組み込む新しいルールと詳細を提案します。その後、新しい候補ジャッジを評価して、ベースラインジャッジのパフォーマンスを上回るかどうかを確認します。

このプロセスの最終的なアウトプットは、詳細な指示とともにドメイン専門家のフィードバックを直接反映する、アラインされたジャッジです。

効果的なアラインメントのヒント:
- アラインメントの目標は、開発中にドメイン エキスパートが隣に座っているかのように感じさせることです。このプロセスにより、ベースライン エージェントのパフォーマンス スコアが低下する可能性がありますが、これはベースライン審査員の仕様が不十分であったことを意味します。SME が行うのと同じ方法でエージェントを評価する審査員ができたので、手動または自動で改善を加えてパフォーマンスを向上させることができます。
- アラインメント プロセスの品質は、提供されるフィードバックの品質によって決まります。量より質を重視してください。多数の例に対する一貫性のないフィードバックよりも、少数の例 (最低 10 件) に対する詳細で一貫性のあるフィードバックの方が、より良い結果を生み出します。
品質を定義することが、エージェントのパフォーマンスを向上させる上での主な障害となることがよくあります。どのような最適化手法を用いても、品質の定義が明確でなければ、エージェントのパフォーマンスは期待を下回るでしょう。Databricksは、反復的な部門横断型演習を通じて顧客が品質を定義するのを支援するワークショップを提供しています。詳細については、Databricksのアカウントチームにお問い合わせいただくか、こちらのフォームにご記入ください。
7. プロンプトの最適化。
SME (専門家) の好みを反映したアラインされたジャッジを使用することで、エージェントのシステムプロンプトを自動的に改善できるようになりました。MLflow の optimize_prompts() 関数は、GEPA を使用して、アラインされたジャッジのスコアリングに基づいてプロンプトを繰り返し改良します。Databricks の CTO である Matei Zaharia が共同開発した GEPA (Genetic-Pareto) は、遺伝的進化的プロンプトアルゴリズムです。大規模言語モデルを活用してプロンプトに反映的な変更 (reflective mutations) を加え、指示を繰り返し改良することで、モデルのパフォーマンス最適化において従来の強化学習技術を上回る性能を発揮します。
開発者がシステム プロンプトに追加する形容詞を推測する代わりに、GEPA オプティマイザーが、専門家によって定義された特定のスコアを最大化するようにプロンプトを数学的に進化させます。最適化プロセスでは、オプティマイザーを望ましい動作に導くために、次のような期待される応答を含むデータセットが必要です。
GEPAオプティマイザは、現在のシステムプロンプトを取得し、各候補をアラインされたジャッジに対して評価しながら、繰り返し改善案を提案します。ここでは、MLflowのoptimize_prompts()を活用するために、初期プロンプト、作成した最適化データセット、およびアラインされたジャッジを取得します。次に、GEPAオプティマイザを使用して、アラインされたジャッジに導かれた新しいシステムプロンプトを作成します。
次のスクリーンショットはシステム プロンプトの変更を示しています。左が古いもので、右が新しいものです。最終的に選択されたプロンプトは、アラインされたジャッジによって測定されたスコアが最も高いものです。新しいプロンプトはスペースの都合で一部省略されていますが、この例から、ドメイン専門家の応答を取り入れ、特定リクエストの処理方法に関する明確なガイダンスを備えた、ドメイン固有の言語に根差したプロンプトを作成できたことは明らかです。

専門家フィードバックを使用してこの種のガイダンスを自動生成する機能により、専門家は、エージェントからのトレースにフィードバックを与えるだけで、エージェントに間接的に指示を与えることができます。
このケースでは、調整済みジャッジによると、新しいプロンプトによって最適化データセットのパフォーマンスが向上したため、新しく登録されたプロンプトに本番エイリアスを付与し、この改善されたプロンプトでエージェントを再デプロイできるようにしました。
プロンプト最適化のヒント:
- 最適化データセットは、エージェントが処理するクエリーの多様性を網羅する必要があります。エッジケース、曖昧なリクエスト、ツールの選択が重要になるシナリオを含めてください。
- 期待される応答は、正確な出力テキストではなく、エージェントが何をすべきか(どのツールを呼び出すか、どの情報を含めるかなど)を記述する必要があります。
- まず、
max_metric_callsを50~100に設定します。値を大きくすると、より多くの候補が探索されますが、コストとランタイムが増加します。 - GEPAオプティマイザは失敗モードから学習します。アラインされた判定機能が、欠落しているベンチマークや小規模サンプルの注意点にペナルティを課す場合、GEPA はそれらの要件を最適化されたプロンプトに組み込みます。
8. ループを閉じる: 自動化と継続的改善
これまで見てきた個々のステップは、継続的な最適化パイプラインとして編成することができます。このパイプラインでは、ドメイン専門家によるラベリングが最適化ループのtriggerとなり、すべてをAsset Bundlesを使用してDatabricksジョブにまとめることができます。
- 専門家は、MLflowラベリングセッションUIを通じてエージェントの出力をラベリングし、実際の本番運用トレースにスコアとコメントを提供します。
- パイプラインは、新しいラベルを検出し、専門家フィードバックとベースライン LLM ジャッジのスコアの両方を含むトレースを取得します。
- 審査員の調整が実行され、最新のSMEの好みに合わせて調整された新しい審査員バージョンが生成されます。
- プロンプトの最適化ランが実行され、調整された審査員を使用してシステム プロンプトが繰り返し改善されます。
- 条件付きプロモーションは、パフォーマンスのしきい値を超えた場合に、新しいプロンプトを本番環境に反映します。これには、新しいプロンプトが他の例にも汎化することを確実にするために、別の評価ジョブをトリガーすることが含まれる場合があります。
- プロンプトレジストリが最適化されたバージョンを提供するため、エージェントは自動的に改善されます。
ドメインエキスパートがラベリングセッションを完了すると、evaluate()ジョブがトリガーされ、同じトレース上でLLMジャッジスコアが生成されます。evaluate()ジョブが完了すると、LLMジャッジをドメインエキスパートのフィードバックと整合させるためにalign()ジョブが実行されます。そのジョブが完了すると、optimize_prompts()ジョブが実行され、新しいデータセットに対する即時テストや、必要に応じた本番運用へのプロモートが可能な、新しく改善されたシステムプロンプトが生成されます。
このプロセス全体は完全に自動化できますが、どのステップにも手動レビューを組み込むことができ、開発者は自動化のレベルを完全にコントロールできます。SME がラベリングを続けるとこのプロセスが繰り返され、エージェントの新しいバージョンでの迅速なパフォーマンステスト、そして開発者が実際に信頼できる累積的なパフォーマンス向上につながります。
まとめ
このアーキテクチャは、Databricks Agent Framework と MLflow を使用して、エージェントが時間とともに改善される方法を変革します。開発者が優れた応答を推測するのではなく、ドメインエキスパートが専門家のフィードバックを通じてエージェントの動作を直接形成します。ジャッジのアライメントと最適化プロセスは、ドメインの専門知識を具体的なシステム�変更に変換します。その一方で、開発者は、どの部分を自動化し、どこで手動介入を許可するかを含め、システム全体を制御し続けます。
この投稿では、プロフットボールのドメイン専門家にとって重要な特定の言語や詳細を反映するようにエージェントを調整する方法を説明しました。DCアシスタントはこのパターンを実証していますが、このアプローチは、法的文書のレビュー、プロ野球の打席準備、医療トリアージ、ゴルフショット分析、顧客サポートのエスカレーションなど、ドメイン専門家のサポートなしでは開発者が「良い」ものを特定するのが難しい、専門家の判断が重要となるあらゆるドメインで機能します。
ご自身のドメイン固有の問題でお試しいただき、専門家のフィードバックに基づいて自動化された継続的な改善を推進する方法をご覧ください。
Databricks Sports と Agent Bricks の詳細を確認するか、デモをリクエストして、貴社がどのように競争上の知見を推進できるかをご覧ください。
(このブログ記事はAI翻訳ツールを使用して翻訳されています) 原文記事
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。