DataFrameの等式関数を使ったPySparkテストのシンプル化
PySpark DataFrameの等式テスト関数の紹介、なぜ重要なのか、どのように使うのか。
DataFrameの等式テスト関数は、PySparkのユニットテストを簡素化するためにApache Spark™ 3.5とDatabricks Runtime 14.2で導入されました。 このブログ記事で説明した機能一式は、次期Apache Spark 4.0とDatabricks Runtime 14.3から利用可能になります。
DataFrameの等式テスト関数を使用して、より信頼性の高いDataFrame変換を記述
PySparkでデータを扱うには、DataFrameに変換、集約、操作を適用します。 変換が蓄積されるにつれて、コードが期待通りに動作することをどうやって確信できるでしょうか? PySparkの等式テストユーティリティ関数は、データを期待される結果と照らし合わせてチェックする効率的で効果的な方法を提供�し、予期しない差異を特定して分析プロセスの初期段階でエラーを検出するのに役立ちます。 さらに、デバッグに多くの時間を費やすことなく、即座に対策を講じることができるように、違いを正確に特定する直感的な情報を返します。
DataFrame の等式テスト関数の使用
Apache Spark 3.5では、PySpark DataFrame用の2つの等式テスト関数assertDataFrameEqualと assertSchemaEqualが導入されました。 それぞれの使い方を見てみましょう。
assertDataFrameEqual:この関数を使うと、1行のコードで2つのPySpark DataFrameが等しいかどうかを比較し、データとスキーマが一致するかどうかをチェックできます。 違いがある場合は、説明的な情報を返します。
例を見てみましょう。 まず、2つのDataFrameを作成し、最初の行に意図的に差分を入れます:
そして、2つのDataFrameでassertDataFrameEqualを呼び出します:
この関数は、2つのDataFrameの最初の行が異なることを示す説明的なメッセージを返します。 この例では、この行のAlfredの最初の金額が同じではありません(予想:1500、実際:1200):
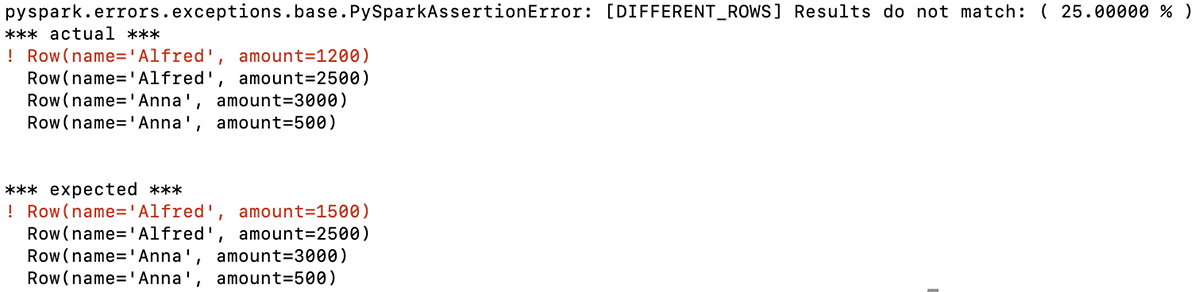
この情報があれば、あなたのコードが生成したDataFrameの問題をすぐに知ることができ、それに基づいてデバッグを行うことができます。
また、この関数には、DataFrame の比較の厳密さを制御するため�のいくつかのオプションがあります。
assertSchemaEqual:行データの比較は行いません。 これにより、2つの異なるDataFramesのカラム名、データ型、Nullableプロパティが同じかどうかを検証することができます。
例を見てみましょう。 まず、異なるスキーマを持つ2つのDataFrameを作成します:
では、これら2つのDataFrameスキーマを使ってassertSchemaEqualを呼び出してみましょう:
この関数は2つのDataFramesのスキーマが異なることを判定し、出力がどこで分岐しているかを出力します。

この例では、amount列のデータ型が、実際のDataFrameではLONGですが、期待されるDataFrameではDOUBLEであることと、スキーマを指定せずに期待されるDataFrameを作成したため、列名も異なるという2つの違いがあります。
これらの違いは、ここに示されているように、関数の出力で強調表示されます。
assertPandasOnSparkEqualはApache Spark 3.5.1から非推奨となり、次期Apache Spark 4.0.0で削除される予定なので、このブログ記事では取り上げません。 Spark 上での Pandas API のテストについては、Pandas API on Spark equality test functions を参照してください。
PySpark DataFrames の違いをデバッグするための構造化出力
assertDataFrameEqual関数とassertSchemaEqual関数は主にPySpark関数をテストするために小さいデータセットを使用するユニットテストを目的としていますが、数行と数列以上のDataFrameで使用することもあります。 このような場合、異なる行のデータを簡単に取得することができ、デバッグが容易になります。
その方法を見てみましょう。 先ほどと同じデータを使って、2つのDataFrameを作ります:
そして今度は、assertDataFrameEqual をコールした後に、アサーション・エラー・オブジェクトから 2 つの DataFrame の間で異なるデータを取得します:
この例で行ったように、異なる行に基づいてDataFrameを作成し、それを表示することで、この情報へのアクセスがいかに簡単であるかを示しています:

ご覧のように、異なる行の情報はすぐに分析に利用できます。 デバッグのために、この情報を実際のDataFramesと期待されるDataFramesから抽出するコードを書く必要はもうありません。
この機能は、次期Apache Spark 4.0とDBR 14.3から利用可能になります。
PandasのAPIをSparkの等式テスト関数で実行
PySparkのDataFrameの等質性をテストする関数に加えて、Pandas API on Sparkのユーザは以下のDataFrameの等式テスト関数を利用するこ�とができます:
assert_frame_equalassert_series_equalassert_index_equal
この関数は、比較の厳密性を制御するオプションを提供し、Spark DataFrames上でのPandas APIのユニットテストに最適です。 これらはpandasのテストユーティリティ関数と全く同じAPIを提供しているため、Spark上でPandas APIを使用して実行したい既存のpandasテストコードを変更することなく使用することができます。
以下は、Pandas APIとSpark DataFramesを比較し、パラメータを変えてassert_frame_equalを使用する例です:
この例では、2つのDataFrameのスキーマが異なっています。 関数の出力は、ここに示すように、差分を一覧表示します:

この例のように、check_dtype引数を使用して、カラムのデータ型が同じでなくてもカラムのデータを比較するように関数を指定することができます:
assert_frame_equalは列のデータ型を無視するように指定したので、2つのDataFrameは等しいとみなされます。
これらの関数は、Sparkオブジェクト上のPandas APIとpandasオブジェクトの比較も可能で、この例で示されているように、異なるDataFrameライブラリ間の互換性チェックを容易にします:
新しい PySpark DataFrame と Pandas API on Spark の等式テスト関数を使用することは、PySpark コードが期待通りに動作することを確認する素晴らしい方法です。 これらの機能は、エラーをキャッチするだけでなく、何が問題なのかを正確に理解し、問題がどこにあるのかを素早く簡単に特定するのに役立ちます。 詳しくはTesting PySparkのページを参照してください。
これらの機能は、次期Apache Spark 4.0から利用可能になります。 DBR14.2はすでにサポートしています。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。