アルミニウム製造のサステナビリティ
GraphFramesで再定義するバッチトレーサビリティ
- オペレーションチェーンにおける材料トレーシングのビジネス価値と一般的な課題について
- GraphFramesが入力バッチと出力バッチの階層的な関係をどのように表現するかについて
- Pregelアルゴリズムを使用して任意のバッチの全系統(フルリネージ)をトレースする方法について
持続可能なアルミニウム製造の推進:GraphFramesでリサイクル率を算出する方法
近年の製造業界において、持続可能な生産はもはや選択肢ではなく、必要不可欠なものとなっています。全米製造業者協会(NAM)の2022年の調査によると、製造業者の79%が具体的なサステナビリティ目標を掲げているとされています。あるアルミニウム板・箔のグローバルメーカーは、この課題に正面から取り組み、Databricksを活用して生産ラインのデータを分析。製品品質の向上、資源の最適化、環境負荷の低減を目指しています。
課題:複雑な製造工程と排出量の把握
アルミニウムの製造は、原材料から最終製品へと加工するまでに多くの工程を要する複雑なプロセスです。このプロセス全体を通してサステナビリティを確保するために、同社では環境への影響を追跡するレポートシステムを構築しました。その中でも特に重要な指標が「リサイクル率(リカバリーレシオ)」です。これはスクラップから新製品として再利用されたアルミニウムの割合を示すもので、正確に算出するには最終製品ができるまでの各工程(いわゆる「バッチトレース」)を特定し、それぞれの工程で発生する材料ロスを把握する必要があります。
しかしながら、扱うデータは非常に膨大です。生産システムには10億件以上のレコードが蓄積されており、最大で40階層にも及ぶバッチ間の関連情報が含まれています。従来のDataFrameベースの手法では、こうした複雑な関係性の解析には適していませんでした。また、Pandas UDFの利用も検討されましたが、データ量や構造の複雑化によりパフォーマンスに課題が生じました。
そこで同社が採用したのが、関係性をグラフとしてモデル化し解析する方法です。DatabricksのML Runtimeに含まれ、Photon Engineで最適化された分散グラフ処理フレームワーク「GraphFrames」を活用することで、スケーラブルかつ高パフォーマンスなエンド・ツー・エンドのバッチトレースを実現しました。
GraphFramesを用いた解析アプローチ
製造シス��テムでは、ひとつの原材料から何百もの中間工程を経て、何百もの最終製品が生み出されます。各工程は入力と出力に関する情報を持っていますが、リサイクル率のようなサステナビリティ指標を評価するためには、原材料から最終製品までの一連の流れを俯瞰する必要があります。
目的は、出力されたバッチとその元となる原材料バッチとを、中間バッチIDを介してつなぐことです。この全体の流れが明らかになれば、各工程で失われた材料量を特定できるようになります。
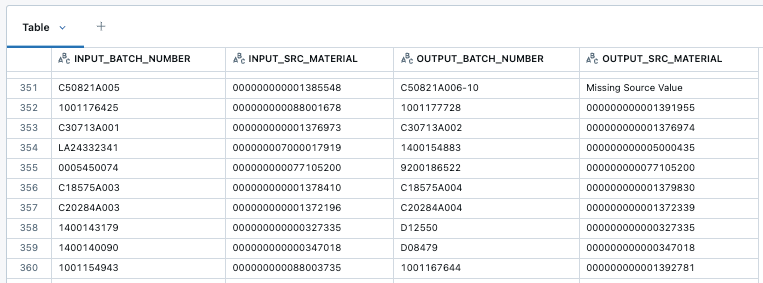
最終製品の製造過程で発生した総材料ロスを算出するために、DataFrameに格納された生産バッチの履歴をたどることは容易ではありません。DataFrameは、ビジネスオブジェクトの集合に対する分析クエリには便利ですが、複雑な階層構造を持つオブジェクトのモデリングや解析には適していません。
このような複雑なオブジェクト階層の取り扱いには、GraphFramesが有効なデータ構造となります。GraphFramesは、階層構造をグラフとしてモデル化し、以下のように�構成します:
-
頂点(Vertex):ビジネスオブジェクト(例:製造工程におけるバッチA)を表す
-
辺(Edge):オブジェクト間の関係(例:バッチAがバッチBの元となる)を表す
GraphFramesライブラリには、グラフデータを処理するための多くのツールが組み込まれています。そのひとつが Pregelアルゴリズム です。Pregelは、グラフの辺を通じて情報を伝搬させることで計算を行う仕組みです。
今回のバッチトレーシングでは、Pregelを用いて過去の生産工程(例:出力されたバッチ番号)に関する情報を上流へ伝搬させ、各最終製品に対してすべての上流バッチの一覧を生成しました。
Pregelの理解
Pregelは、ユーザーが自分たちのビジネス課題に合わせて、カスタムな並列メッセージパッシングアルゴリズムを構築できるフレームワークです。
各頂点(Vertex)は初期値でセットされ、「スーパー ステップ(superstep)」と呼ばれる反復処理を通じて計算が進められます。各スーパー ステップにおいて、頂点は次のような��処理を行うことができます:
- 隣接する頂点(ノード)にメッセージを送信する
- 隣接する頂点から受け取ったメッセージを集約する
- メッセージを処理し、自身の内部状態を更新する
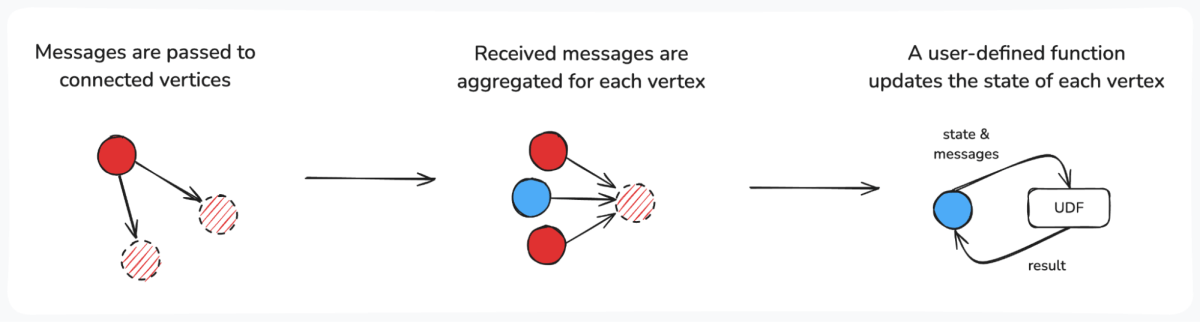
ユーザー定義関数(UDF)は、メッセージの送信方法や、受信したメッセージを使って頂点の状態をどのように更新するかを制御します。この柔軟性により、Pregelアルゴリズムはさまざまなユースケースに対応可能です。
私たちの製造プロセスにおけるバッチトレースの実装では、ある頂点から別の頂点へ入力バッチ番号をメッセージとして送信し、受信時に各頂点の階層の深さ(depth)やソースバッチ番号を更新していきました。
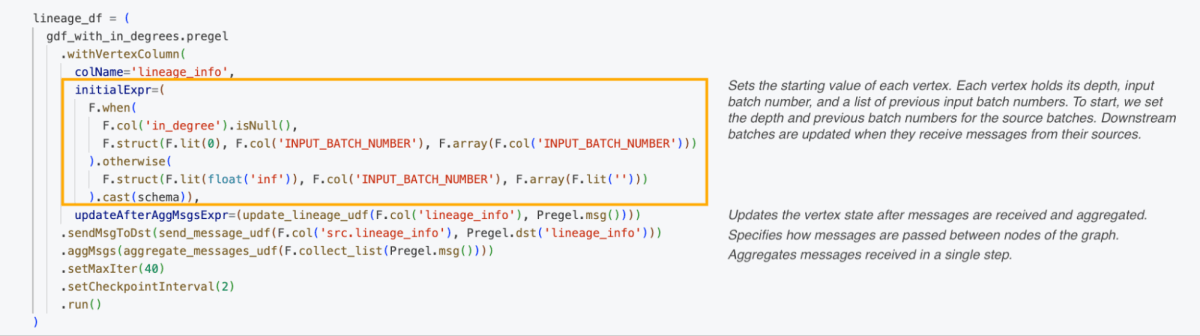
バッチトレーシングのための関数の定義
Pregelを使ってバッチトレーシングを実装するために、私たちはグラフに沿ってバッチ番号を送信したいと考えていました。まず、メッセージ構造を定義しました—私たちのものには、ノードの深さ、バッチ番号、および以前のバッチ番号(いわゆる「トレース」)が含まれていました。メッセージスキーマを定義した後、親から子バッチへのメッセージが送信されるように、各頂点の深さに基づいてUDFを作成しました。

製造システムは複数の入力を含むことができるため、複数の上流頂点からのメッセージを処理する方法が必要でした。上流の生産ラインから受け取ったバッチ番号の単一リストを収集する関数を作成しました。

最後に、集約されたバッチ番号で各頂点を更新する関数を作成しました。

データの前処理
最初のステップは、データセット内のソースバッチを特定することでした。バッチデータからGraphFrameを作成し、inDegreesプロパティを使用して、各出力バッチに対する入力バッチの数を決定しました。

ソースバッチを見つけた後、私たちはPregelアルゴリズムを構築して、各エッジに沿ってバッチ番号を入力から出力まで送信し、すべてのバッチの完全な系譜をトレースしました。
Pregelアルゴリズムの実行
下の画像は、アルゴリズムを実行し、系統を追跡するためのPregelフレームワークの呼び出しを示しています。
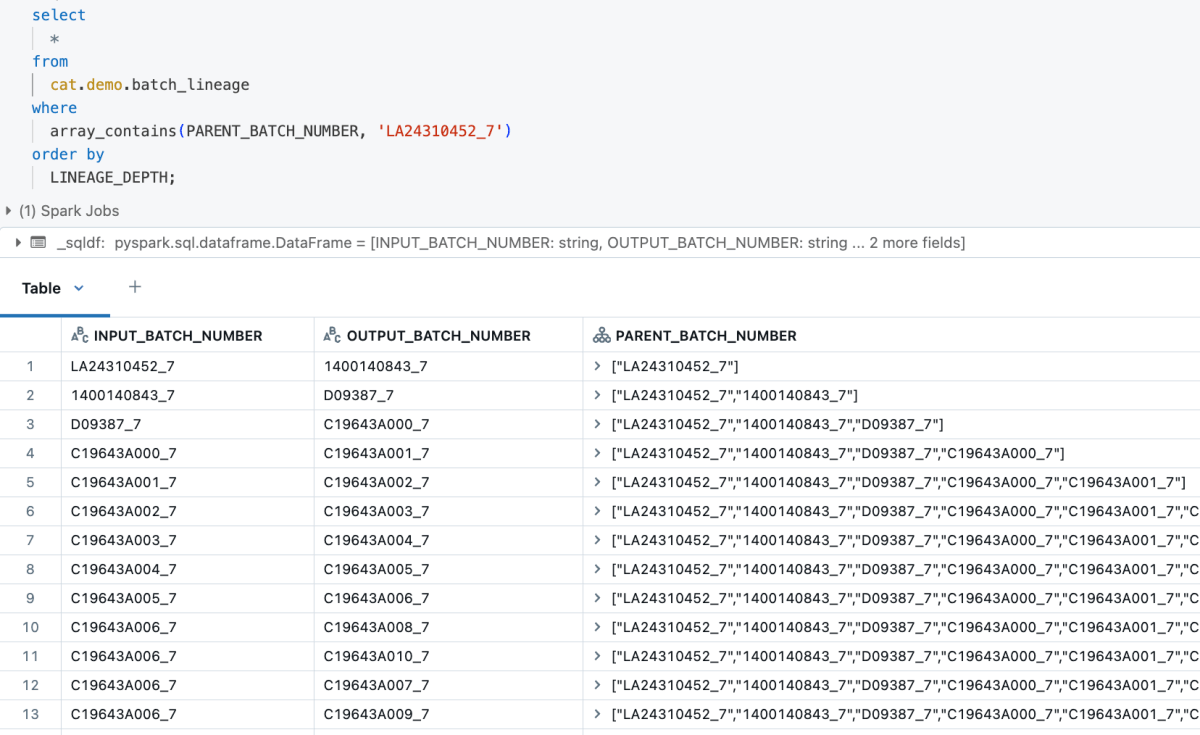
GraphFramesは、1百万バッチに対してPandas UDFsが同じクラスタ上で実行されるのと比べて、階層的なトラバーサルを24倍(4時間から約10分)に高速化しました。Pandas UDFsはワーカーサイズを増やすことでしかスケールアップできなかったのに対し、テストではGraphFramesがワーカーをクラスタに追加することで水平にスケールアップしたことが示されました。
まとめ
Databricks上でGraphFramesを活用することで、この製造業者は自社の生産プロセスをより可視化できるようになりました。バッチトレースによって得られたデータをもとにしたレポートにより、オペレーションマネージャーは不良の早期発見や廃棄の削減、製品品質の安定化を実現しています。また、廃棄物や排出量の追跡精度が向上したことで、環境負荷の最小化や、年々厳しくなる規制への対応、さらには顧客の価値観との整合性を図ることができるようになりました。この企業は、データドリブンなアプローチを取り入れることで、より効率的かつ持続可能な製造方法を見つけることができました。GraphFramesは、Sparkネイティブで扱えるグラフ解析機能を提供しており、他の製造業者にとっても、生産プロセスをスケーラブルに理解するための有効なツールとなるでしょう。
あなたのビジネスで持続可能性を推進することに興味がありますか?
まずはじめに、私たちのESGパフォーマンス分析ソリューションアクセラレータをチェックしてみてください!
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。