TAO:ラベルなしデータでテストタイムコンピュートを活用した効率的なLLMの訓練
によって データブリックス AI 研究チーム による投稿
大規模言語モデル(LLM)は、新しい企業タスクに適応させることが難しいという課題があります。プロンプティングはエラーが発生しやすく、品質向上が限られる一方、ファインチューニングには大量の人間によるラベル付きデータが必要ですが、多くの企業タスクではそのようなデータが入手できません。
今日、私たちはラベルなしの使用データのみを必要とする新しいモデル調整手法を紹介します。これにより、企業は既に持っているデータだけでAIの品質とコストを改善できるようになります。私たちの手法「テスト時適応最適化(TAO)」は、テストタイムコンピュート(o1やR1で普及)と強化学習(RL)を活用し、過去の入力例のみに基づいてタスクをより良く実行するようモデルに教えます。つま��り、人間によるラベル付け作業ではなく、調整可能な計算予算に合わせてスケールします。
重要なのは、TAOはテストタイムコンピュートを使用しますが、それはモデルを訓練するプロセスの一部として使用されるという点です。訓練されたモデルはその後、低い推論コストで直接タスクを実行します(つまり、推論時に追加の計算を必要としません)。驚くべきことに、ラベル付きデータがなくても、TAOは従来のファインチューニングよりも優れたモデル品質を達成でき、LlamaのようなオープンソースモデルをGPT-4oやo3-miniなどの高価な独自モデルの品質レベルに近づけることができます。
TAOは、企業が既に持っているデータを使用して特定のドメインでAIを優れたものにするという「データインテリジェンス」の問題に取り組む研究チームのプログラムの一部です。TAOにより、以下の3つの成果を達成しました:
-
文書の質問応答やSQL生成などの専門的な企業タスクにおいて、TAOは数千のラベル付き例に対する従来のファインチューニングを上回ります。Llama 8Bや70Bなどの効率的なオープンソースモデルを、ラベルを必要とせずにGPT-4oやo3-miniなどの高価なモデルと同等の品質にします。
-
マルチタスクTAOを使用して、多くのタスクにわたってLLMを広く改善することもできます。ラベルを使用せずに、TAOはLlama 3.3 70Bの幅広い企業ベンチマークでのパフォーマンスを2.4%向上させました。
-
調整時のTAOの計算予算を増やすと、同じデータでもモデル品質が向上し、調整されたモデルの推論コストは同じままです。
図1は、TAOが3つの企業タスク(FinanceBench、DB Enterprise Arena、BIRD-SQL(Databricks SQLダイアレクトを使用))でLlamaモデルをどのように改善するかを示しています。LLM入力のみにアクセスできるにもかかわらず、TAOは数千のラベル付き例を使った従来のファインチューニング(FT)を上回り、Llamaを高価なプロプライエタリモデルと同じ範囲に引き上げます。


図1:3つのエンタープライズベンチマークでのTAO on Llama 3.1 8BとLlama 3.3 70B。TAOは品質の大幅な改善をもたらし、微調整を上回り、高価な独自のLLMに挑戦します。
TAOは現在、Llamaを調整したいDatabricksの顧客向けにプレビュー版で利用可能であり、今後いくつかの製品に搭載される予定です。プライベートプレビューの一環として自分のタスクで試してみたい場合は、このフォームに記入してください。この記事では、TAOの仕組みとその結果についてさらに詳しく説明します。
TAOの仕組み:テストタイムコンピュートと強化学習を使用したモデル調整
人間によるアノテーション付き出力データを必要とする代わりに、TAOの鍵となるアイデアは、テストタイムコンピュートを使用してモデルにタスクに対する妥当な応答を探索させ、これらの応答を評価して強化学習によりLLMを更新することです。このパイプラインは、高価な人間の労力ではなく、テストタイムコンピュートを使用してスケールし、品質を向上させることができます。さらに、タスク固有の洞察(カスタムルールなど)を使用して簡単にカスタマイズできます。驚くべきことに、高品質なオープンソースモデルでこのスケーリングを適用すると、多くの場合、人間によるラベル付けよりも優れた結果が得られます。
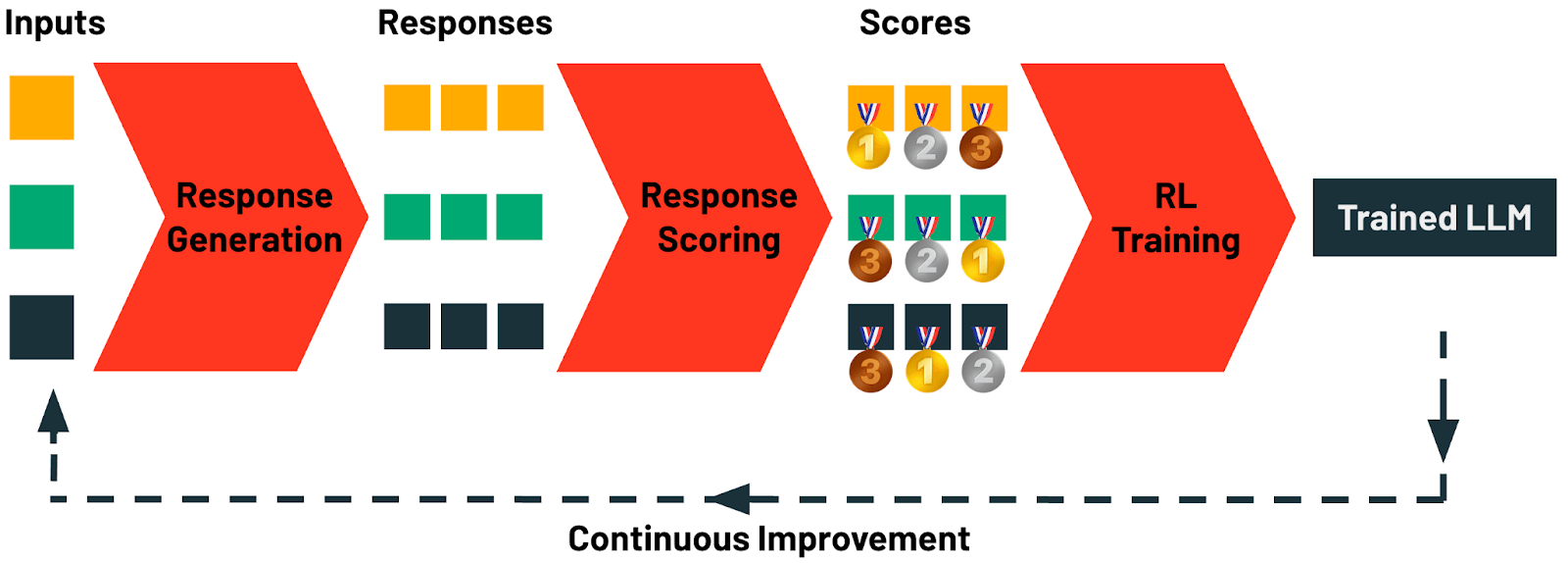
具体的に、TAOは4つの段階で構成されています:
-
応答生成:このステージでは、タスクの例となる入力プロンプトやクエリを収集することから始まります。Databricksでは、AI Gatewayを使用してあらゆるAIアプリケーションからこれらのプロ��ンプトを自動的に収集できます。各プロンプトは、多様な候補応答を生成するために使用されます。ここでは、単純な思考連鎖プロンプティングから高度な推論や構造化プロンプティング技術まで、さまざまな生成戦略を適用できます。
-
応答スコアリング:このステージでは、生成された応答が体系的に評価されます。スコアリング手法には、報酬モデリング、選好ベースのスコアリング、またはLLMジャッジやカスタムルールを活用したタスク固有の検証など、さまざまな戦略が含まれます。このステージでは、生成された各応答の品質と基準への適合度が定量的に評価されます。
-
強化学習(RL)トレーニング:最終ステージでは、RL手法を適用してLLMを更新し、前のステップで特定された高スコアの応答に密接に一致する出力を生成するようモデルを導きます。この適応学習プロセスを通じて、モデルは予測を改良して品質を向上させます。
-
継続的改善:TAOが必要とするのは、LLM入力の例だけです。ユーザーはLLMと対話することで自然にこのデータを作成します。LLMをデプロイするとすぐに、次のラウンドのTAOのためのトレーニングデータの生成が始まります。Databricksでは、TAOのおかげで、使えば使うほどLLMが向上します。
重要なのは、TAOはテストタイムコンピュートを使用しますが、それは低い推論コストで直接タスクを実行するモデルを訓練するために使用するという点です。つまり、TAOによって生成されたモデルは、元のモデルと同じ推論コストと速度を持ちます - o1、o3、R1などのテストタイムコンピュー��トモデルよりも大幅に低いコストです。結果が示すように、TAOで訓練された効率的なオープンソースモデルは、品質面で主要な独自モデルに匹敵することができます。
TAOは、AIモデルを調整するためのツールキットに強力な新手法を提供します。遅くてエラーが発生しやすいプロンプトエンジニアリングとは異なり、また高価で高品質な人間のラベルを生成する必要があるファインチューニングとも異なり、TAOはAIエンジニアがタスクの代表的な入力例を提供するだけで優れた結果を達成できるようにします。
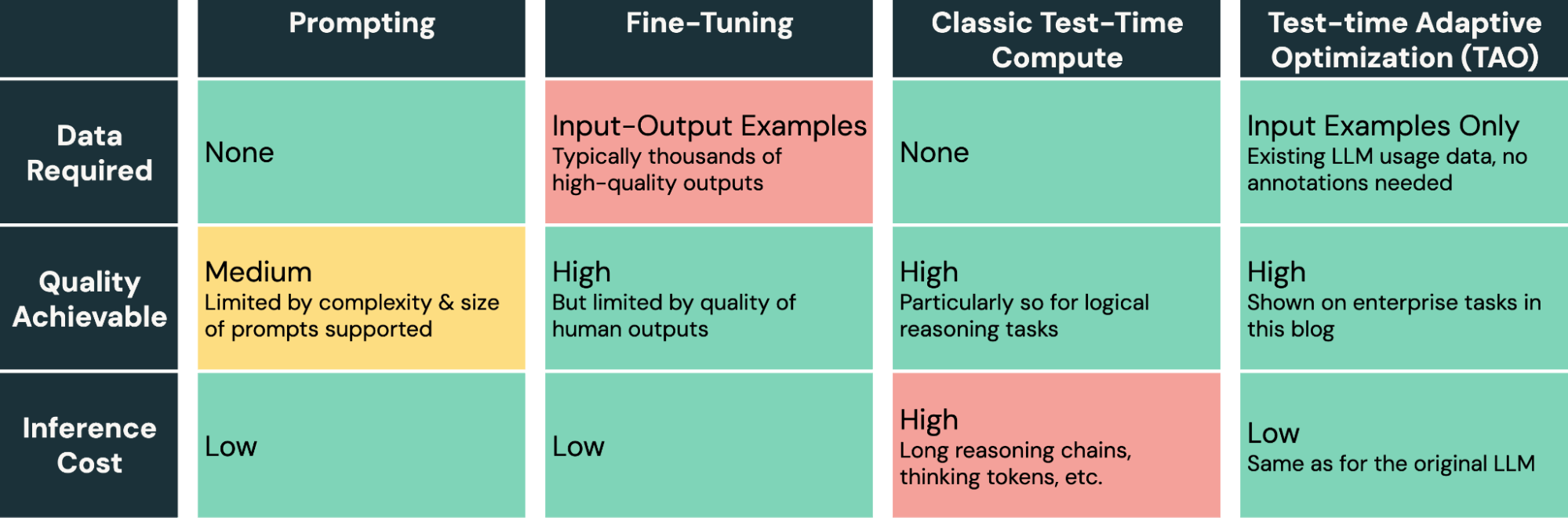
TAOは必要に応じて高度にカスタマイズできる手法ですが、Databricksでのデフォルト実装は、多様な企業タスクでそのまま使用しても効果的です。実装の核心には、TAOが探索によって学習し、RLを使用して基盤となるモデルを調整できるようにする、チームが開発した新しい強化学習と報酬モデリング技術があります。例えば、TAOを支える要素の1つは、企業タスク向けにトレーニングしたカスタム報酬モデルDBRMで、幅広いタスクにわたって正確なスコアリング信号を生成できます。
TAOによるタスクパフォーマンスの向上
このセクションでは、TAOを使用して専門的な企業タスクでLLMを調整した方法についてさらに詳しく説明します。人気のあるオープンソースベンチマークと、ドメインインテリジェンスベンチマークスイート(DIBS)の一部として開発した内部ベンチマークを含む、3つの代表的なベンチマークを選びました。

各タスクについて、いくつかのアプローチを評価しました:
- オープンソースのLlamaモデル(Llama 3.1-8BまたはLlama 3.3-70B)をそのまま使用。
- Llamaのファインチューニング。これには、通常ファインチューニングで良いパフォーマンスを達成するために必要な数千の例を含む大規模で現実的な入出力データセットを使用または作成しました:
- FinanceBenchのためのSEC文書に関する7200の合成質問。
- DB Enterprise Arenaのための4800の人間が書いた入力。
- Databricks SQLダイアレクトに合わせて修正されたBIRD-SQLトレーニングセットからの8137の例。
- Llamaに対するTAO。ファインチューニングデータセットからの例の入力のみを使用し、出力は使用せず、企業向けの報酬モデルDBRMを使用。DBRMはこれらのベンチマークでトレーニングされていません。
- 高品質な独自LLM - GPT 4o-mini、GPT 4o、o3-mini。
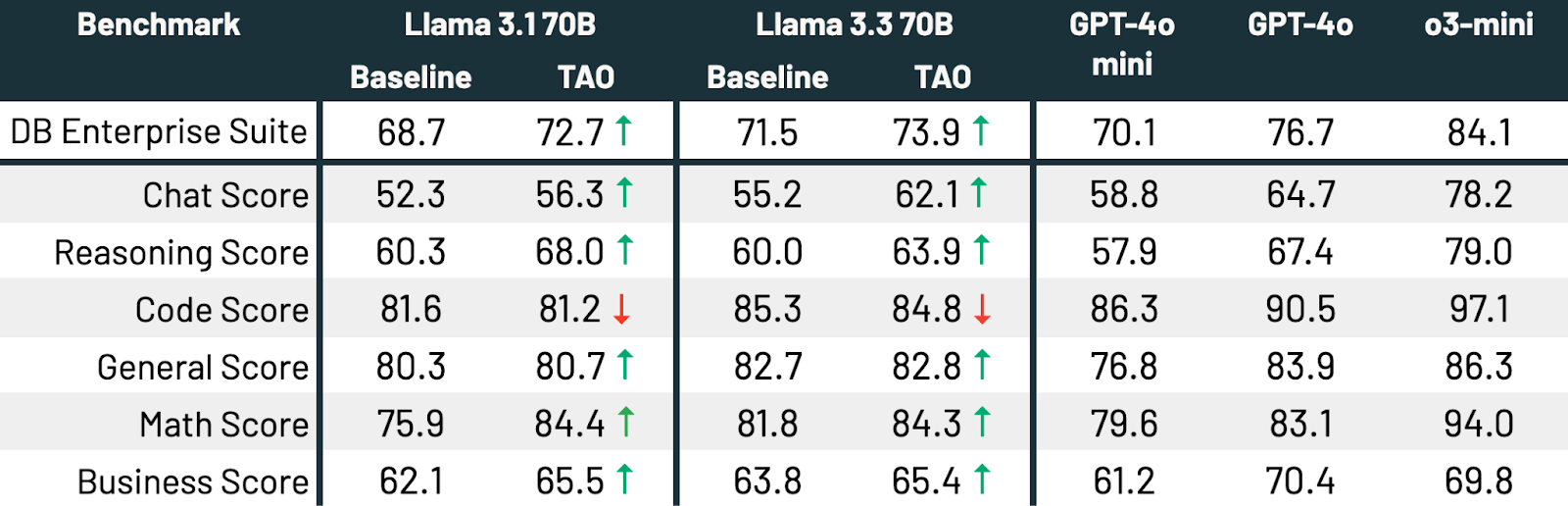
表3に示すように、3つのベンチマークと両方のLlamaモデルにおいて、TAOはベースラインのLlamaパフォーマンスを大幅に向上さ�せ、ファインチューニングを超えています。

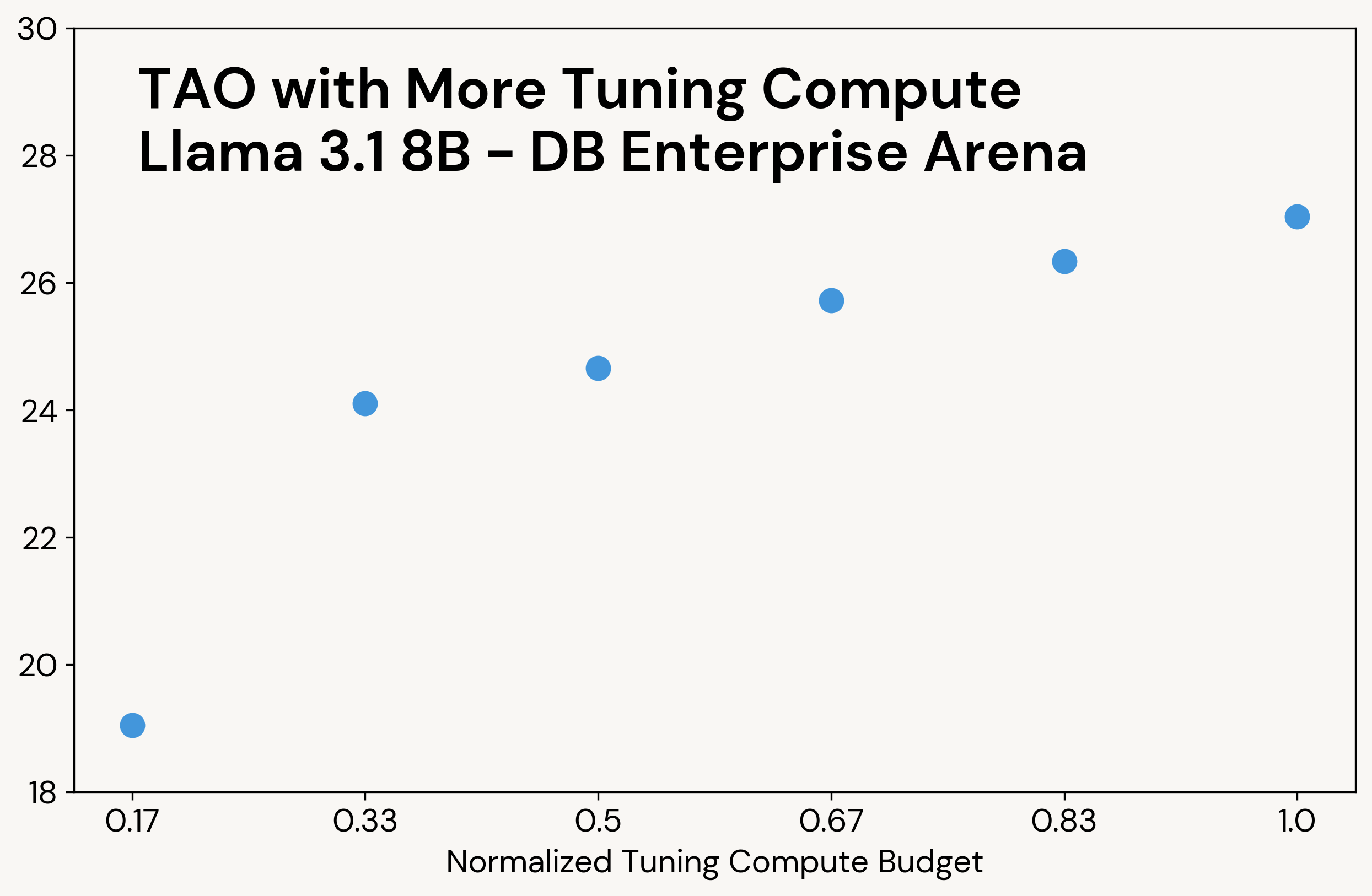
従来のテストタイムコンピュートと同様に、TAOはより多くの計算能力にアクセスできるとより高品質な結果を生成します(例については図3を参照)。ただし、テストタイムコンピュートとは異なり、この追加の計算は調整フェーズでのみ使用されます。最終的なLLMは元のLLMと同じ推論コストを持ちます。例えば、o3-miniは私たちのタスクで他のモデルよりも5〜10倍多くの出力トークンを生成し、比例して高い推論コストになりますが、TAOは元のLlamaモデルと同じ推論コストです。
TAOによるマルチタスクインテリジェンスの向上
これまで、SQLの生成�などの個別の狭いタスクでLLMを改善するためにTAOを使用してきました。しかし、エージェントがより複雑になるにつれて、企業は複数のタスクを実行できるLLMをますます必要としています。このセクションでは、TAOが企業タスクの範囲全体でモデルのパフォーマンスをどのように広く改善できるかを示します。
この実験では、コーディング、数学、質問応答、文書理解、チャットなど、多様な企業タスクを反映した175,000のプロンプトを収集しました。次に、Llama 3.1 70BとLlama 3.3 70BでTAOを実行しました。最後に、人気のあるLLMベンチマーク(Arena Hard、LiveBench、GPQA Diamond、MMLU Pro、HumanEval、MATHなど)と企業に関連する複数の分野における内部ベンチマークを含む、企業に関連するタスクのスイートをテストしました。
TAOは両方のモデルのパフォーマンスを有意義に向上させます。Llama 3.3 70BとLlama 3.1 70Bはそれぞれ2.4および4.0パーセントポイント向上します。TAOはLlama 3.3 70Bを企業タスクにおいてGPT-4oにかなり近づけます。これらはすべて、人間によるラベル付けコストなしで、代表的なLLM使用データとTAOの本番実装だけで達成されます。静的なパフォーマンスを示すコーディングを除いて、すべてのサブスコアで品質が向上します。
実践でのTAOの使用
TAOはテストタイムコンピュートを活用して多くのタスクで驚くほどうまく機能する強力な調整方法です。自分のタスクで成功裏に使用するには、以下が必要です:
- タスクの十分な入力例(数千)。デプロイされたAIアプリケーション(エージェントに送信された質問など)から収集したものか、合成的に生成したもの。
- 十分に正確なスコアリング方法:Databricksの顧客にとって、ここでの強力なツールの1つはTAOの実装を支える独自の報酬モデルDBRMですが、タスクに適用可能であればカスタムスコアリングルールや検証ツールでDBRMを補強できます。
TAOやその他のモデル改善手法を可能にするベストプラクティスの1つは、AIアプリケーション用のデータフライホイールを作成することです。AIアプリケーションをデプロイするとすぐに、Databricks Inference Tablesなどのサービスを通じて入力、モデル出力、その他のイベントを収集できます。その後、入力だけを使用してTAOを実行できます。アプリケーションを使用する人が増えるほど、調整するためのデータが増え、TAOのおかげでLLMはさらに良くなります。
結論とDatabricksでの開始方法
このブログでは、ラベル付きデータを必要とせずに高品質な結果を達成する新しいモデル調整技術、テスト時適応最適化(TAO)を紹介しました。TAOは、企業の顧客が直面している重要な課題に対処するために開発されました:標準的なファインチューニングに必要なラベル付きデータが不足していたのです。TAOはテストタイムコンピュートと強化学習を使用して、入力例などの企業が既に持っているデータを使用してモデルを改善し、デプロイされたAIアプリケーションの品質を向上させ、小さなモデルを使用してコストを削減することを容易にします。TAOは専門的なAI開発のためのテストタイムコンピュートの力を示す高度に柔軟な手法であり、プロンプティングやファインチューニングと並んで使用できる強力でシンプルな新しいツールを開発者に提供すると考えています。
Databricksの顧客は既にプライベートプレビューでLlamaでTAOを使用しています。プライベートプレビューの一環として自分のタスクで試してみたい場合は、このフォームに記入してください。TAOは今後のAI製品のアップデートや発表の多くにも組み込まれています - ご期待ください!
¹ 著者:Raj Ammanabrolu、Ashutosh Baheti、Jonathan Chang、Xing Chen、Ta-Chung Chi、Brian Chu、Brandon Cui、Erich Elsen、Jonathan Frankle、Ali Ghodsi、Pallavi Koppol、Sean Kulinski、Jonathan Li、Dipendra Misra、Jose Javier Gonzalez Ortiz、Sean Owen、Mihir Patel、Mansheej Paul、Cory Stephenson、Alex Trott、Ziyi Yang、Matei Zaharia、Andy Zhang、Ivan Zhou
² このブログ全体でo3-mini-mediumを使用しています。
³ これはDatabricksのSQL方言と製品に合わせて修正されたBIRD-SQLベンチマークです。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。