Unity Catalog ガバナンスの実際の動作:モニタリング、レポーティング、リネージ
Databricks Unity Catalog(UC)は、クラウドやデータプラットフォームにわたる企業のすべてのデータとAI資産に対して、単一の統合ガバナンスソリューションを提供します。 このブログでは、Unity Catalog Governance Value Levers(ガバナンス・バリュー・レバー)をより深く掘り下げ、包括的なデータとAIのモニタリング、レポーティング、リネージを通じて、具体的にどのようにポジティブなビジネス成果を実現しているかを紹介します。
従来の非統合ガバナンスに伴う全体的な課題
Unity Catalog Governance Value Leversブログでは、情報セキュリティ、アクセス制御、利用監視、ガードレールの制定、データ資産からの「唯一の信頼できる情報源」の洞察の取得など、ガバナンスの組織的重要性の「理由」について議論しました。 Databricks UCがなければ、従来のガバナンスソリューションではもはやニーズに対応できません。
議論された主な課題には、複数のベンダーにまたがって管理されているコンプライアンスの弱体化とデータ・プライバシーの分断、管理されていないサイロ化したデータとAIの沼地(スワンプ)、指数関数的に上昇するコスト、機会、収益、コラボレーションの損失などがあります。
Databricks Unity Catalogが統合ビュー、モニタリング、可観測性をどのようにサポートするか
では、技術的な観点から見ると、どのように機能するのでしょうか? UCは、Databricksデータインテリジェンスプラットフォーム全体で登録されたすべての資産を管理しています。 これらの資産は、BI、DW、データエンジニアリング、データストリーミング、データサイエンス、MLなど、あらゆる分野で活用できます。 このガバナンスモデルは、アクセス制御、リネージ、ディスカバリー、モニタリング、監査、共有を提供します。 また、ファイル、テーブル、MLモデル、ノートブック、ダッシュボードのメタデータ管理も提供します。UCは、以下で説明するように、Databricksアセットカタログ、特徴量ストア、モデルレジストリ、リネージ機能、データ分類のためのメタデータのタグ付けなどを通じて、エンドツーエンドの情報全体を一元的に把握することができます。
データ資産全体の統合ビュー
- アセットカタログ:メタデータを含むシステムテーブルを通じて、スキーマ、テーブル、カラム、ファイル、モデルなど、カタログに含まれるすべてを確認できます。 Databricks 内のボリュームについてよくご存知でない�場合、ボリュームは表以外のデータセットを管理するために使用されます。 技術的には、構造化、半構造化、非構造化など、あらゆる形式のファイルにアクセスするための論理ボリュームです。
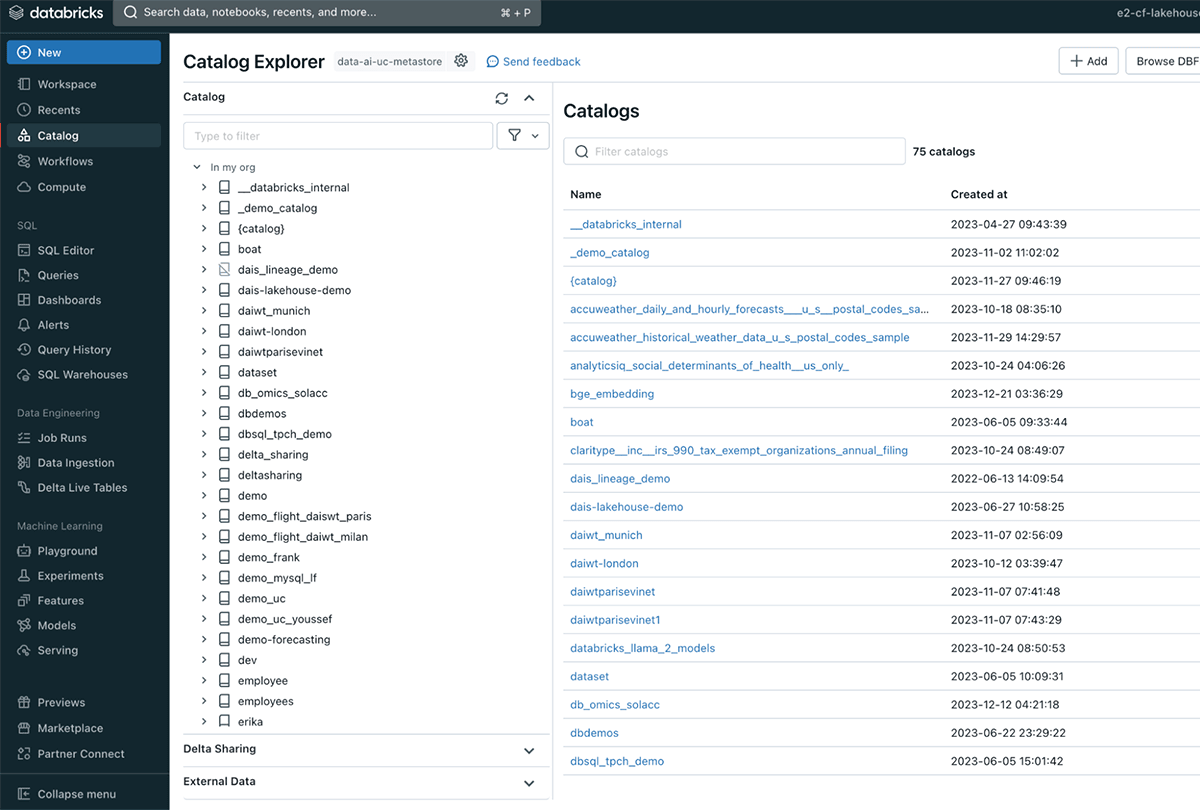
Catalog Explorer lets you discover and govern all your data and ML models - 特徴量ストアとモデルレジストリ:データサイエンティストが使用する機能を一元化されたリポジトリ内で定義します。これは、AIワークフロー全体の一貫したモデル学習と推論に役立ちます。
- リネージ機能:ビジネスで実際に行動を起こすためには、データへの信頼が重要です。 レポート、モデル、洞察を信頼するためには、データに対するエンドツーエンドの透明性が必要です。 UCはリネージ機能によってこれを容易にし、洞察を提供します:生のデータソースは?誰がいつ作ったのか? データはどのように統合され、変換されたのか? モデルから学習させたデータセ�ットまでのトレーサビリティはどうなっているか? テーブルレベルとカラムレベルの両方で、データからモデルまでのエンドツーエンドを表示します。 Snowflakeのようなデータソースを横断してクエリを実行し、すぐに利益を得ることもできます:

- データ分類のためのメタデータのタグ付け:データ資産に関する文脈的な知見を提供することで、データやクエリを充実させます。 これらのカラムやテーブルレベルでの記述は、手動で入力することもできますし、Databricksアシスタントによる生成AI機能で自動的に記述することもできます。 以下は、説明と定量化可能な特徴の例です:
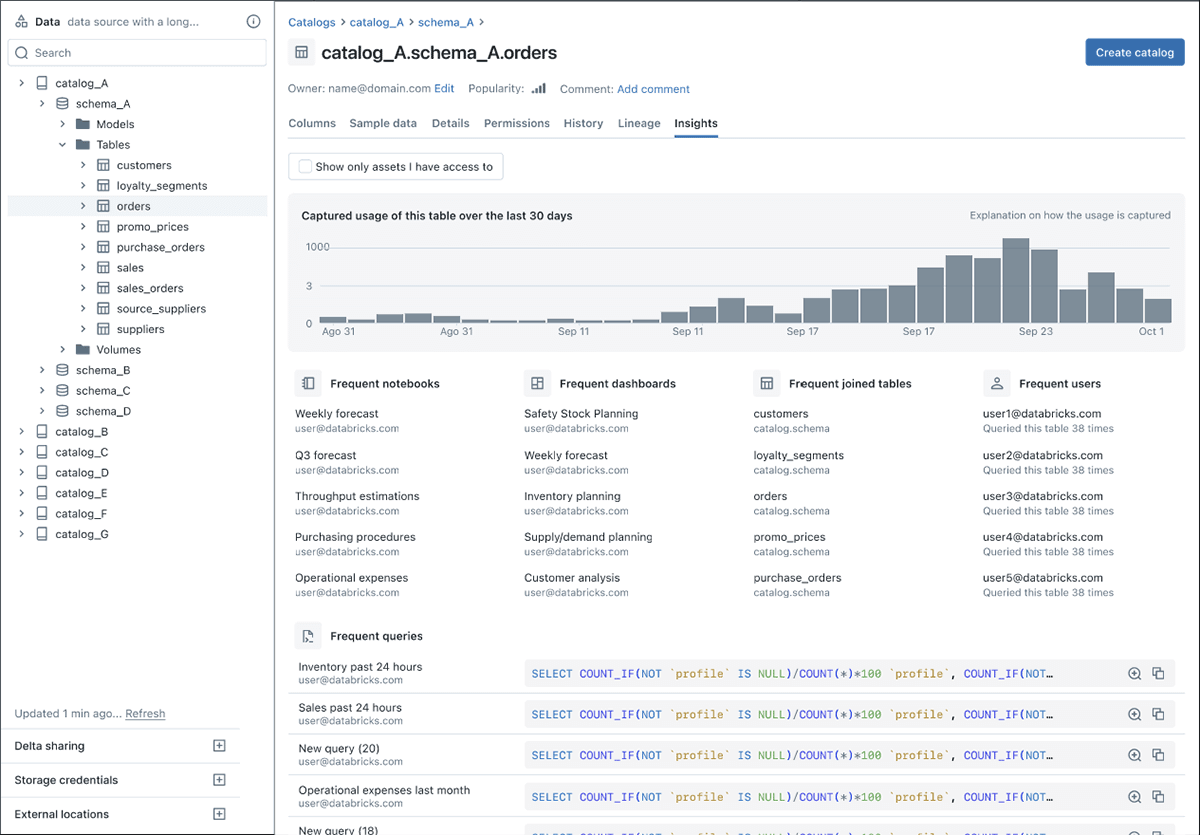
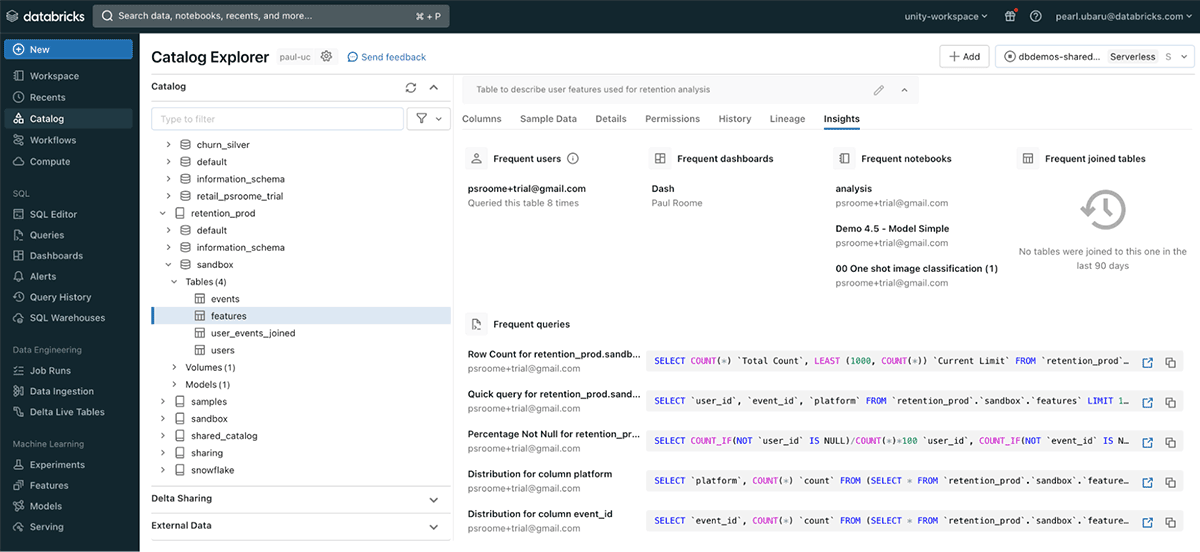
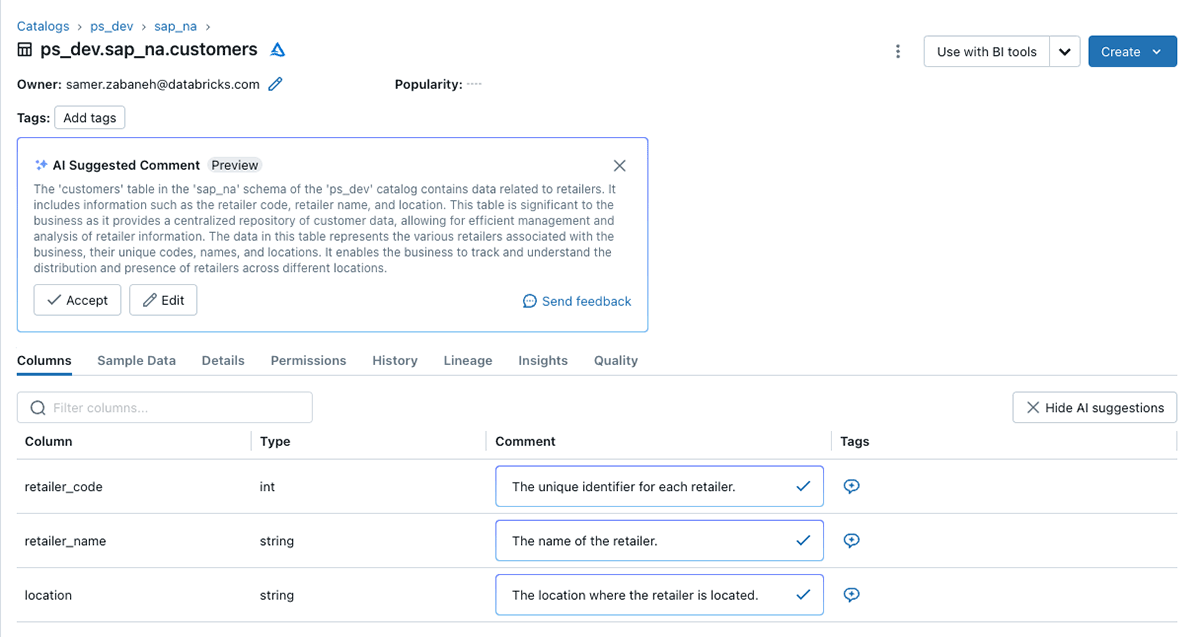
1つの統合ビューにより、次のような結果が得られます
- イノベーションの加速:洞察はデータと同じくらい優れています。 分析の精度はアクセスするデータによって決まります。したがって、データ検索を効率化することで、より迅速で優れたビジネス知見を生み出し、イノベーションを促進します。
- 資産カタログの一元化によるコスト削減:ライセンスコストの削減(多くのベンダーを必要とするのではなく、1つのベンダーソリューションで済みます)、利用料金の削減、市場投入までの時間の短縮、全体的な運用効率の向上が可能になります。
- 複数のデータベース、データウェアハウス、オブジェクトストレージシステムなどにまたがるデータの乱立を抑えることで、すべてのデータの発見とアクセスを容易にします。
包括的なデータとAIによるモニタリングとレポート
Databricksレイクハウスモニタリングは、データ、特徴量からMLモデルまで、データパイプライン全体を監視することができます。 Unity Catalogを利用することで、ユーザーはデータやAI資産のリネージに対する深い洞察を通じて、データやAI資産が高品質、正確、信頼できるものであることを独自に保証できます。 レイクハウスアーキテクチャが可能にする単一で統一された監視アプローチにより、エラーの診断、根本原因の分析、ソリューションの発見が簡単になります。
データがどこに存在するかにかかわらず、データパイプライン全体のデータ、MLモデル、AIの信頼性を単一のビューで確保するにはどうすればよいでしょうか? Databricks レイクハウスモニタリングは、データ(それがどこにあるかに関係なく)から洞察に至る業界唯一の包括的なソリューションです。 問題の発見を迅速化し、根本原因の特定を支援し、最終的にはソリューションの推奨を支援します。
UCは、民主化されたダッシュボードと、システムテーブルから直接照会できるきめ細かなガバナンス情報の両方を備えたレイクハウスもニアリング機能を提供します。 ガバナンスの民主化により、運用の監視とコンプライアンスが技術者以外にも広がり、さまざまなチームがパイプラインのすべてを監視できるようになります。
以下は、長期にわたる精度を含むMLモデルの結果のサンプルダッシュボードです:
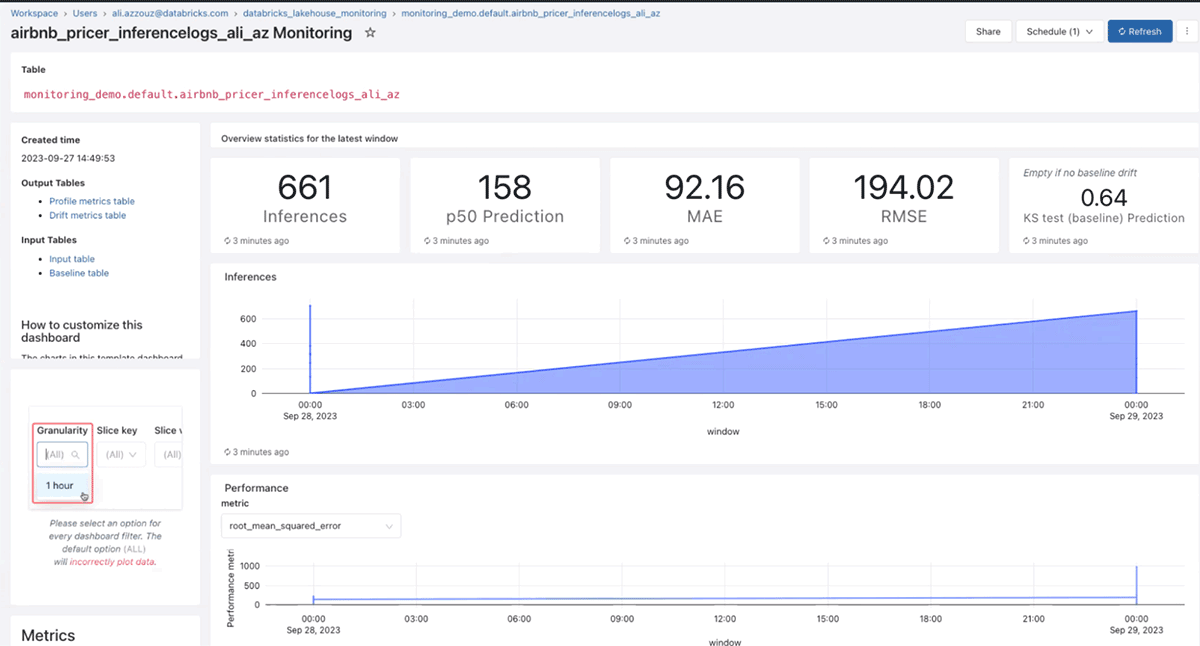
さらに、時間の経過に伴う予測とデータのドリフトの完全性を示しています:
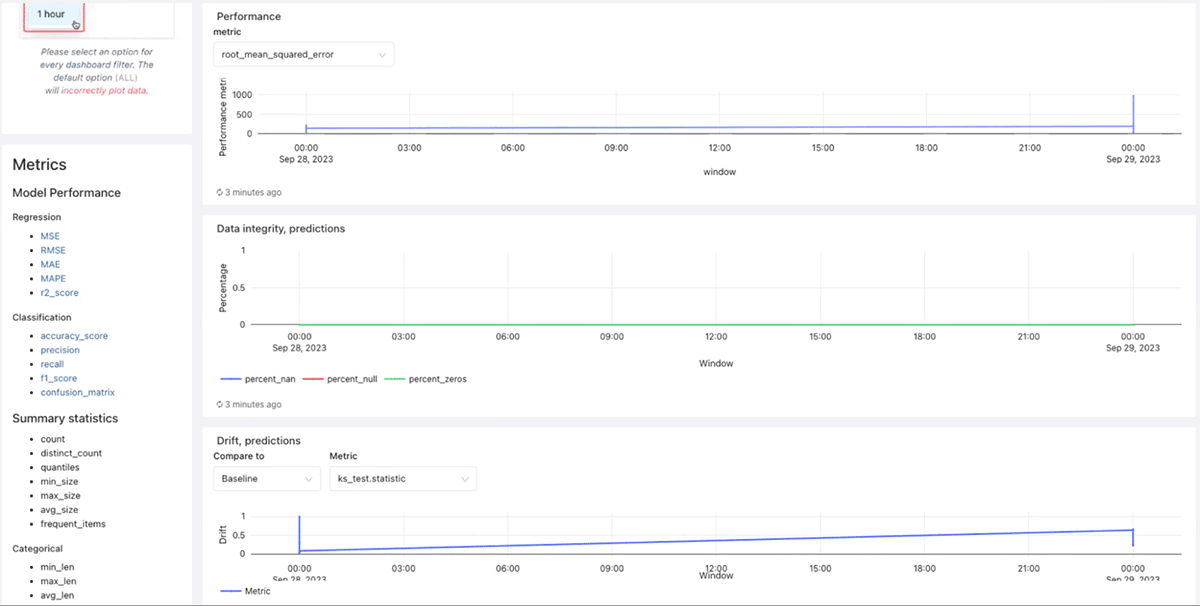
また、R2、RMSE、MAPEなどの様々なML メトリクス、指標に従って、時間の経過に伴うパフォーマンスをモデル化します:
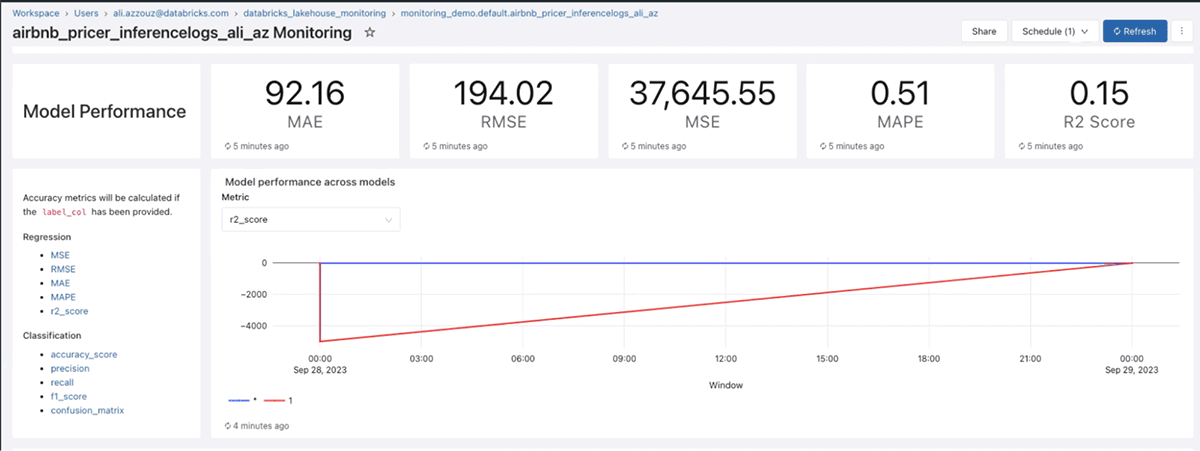
答えを探しているときに ML モデル情報を意図的に探すことは別のことですが、エラー、データ ドリフト、モデルの失敗、または品質の問題に関して自動的にプロアクティブなアラートを受け取ることはまったく別のレベルです。以下は、潜在的な PII (個人識別情報) データ侵害に対するアラートの例です。:
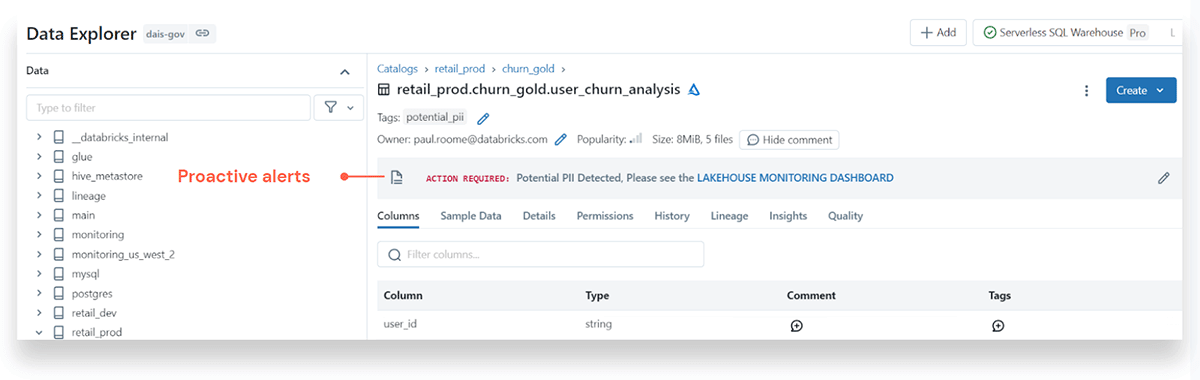
もう一つ、Databrickの強力なリネージ機能(テーブルレベルからカラムレベルまで)により、問題の影響を評価し、根本原因分析を行い、下流への影響を評価することができます。
システムテーブル:レイクハウスの可観測性とコンプライアンス確保のためのメタデータ情報
これらの基礎となるテーブルは、SQLまたはアクティビティダッシュボードを通じて照会することができ、Databricksインテリジェンスプラットフォーム内のすべての資産に関する可観測性を提供します。 例えば、どのユーザーがどのデータオブジェクトにアクセスできるか、価格と使用量を提供する請求テーブル、クラスターの使用量とウェアハウスのイベントを考慮する計算テーブル、列とテーブル間の系統情報などです:
- 監査テーブルには、UCの様々なイベント情報が記録されています。 UCは、メタストアに対して実行されたアクションの監査ログを取得し、管理者は、指定されたデータセットにアクセスしたユーザーと、そのユーザーが実行したアクションの詳細を確認できます。
- 請求テーブルと過去の価格テーブルには、アカウント全体の請求可能なすべての使用量のレコードが含まれます。したがって、ワークスペースがどのリージョンにある場合でも、アカウントのグローバルな使用量を表示できます。
- テーブルリネージとカラムリネージテーブルは、意思決定やレポートを作成するためにリネージデータをプログラムでクエリできるため、非常に便利です。 テーブル・リネージは、UC テーブルまたはパス上の各読み取り/書き込みイベントを記録します。このイベントには、テーブルに関連するジョブの実行、ノートブックの実行、ダッシュボードが含まれます。 カラムの系譜の場合、データはカラムの
- ノードタイプテーブルは、ノードタイプ名、インスタンスのvCPU数、インスタンスのGPU数とメモリ数を示す基本的なハードウェア情報とともに、現在利用可能なノードタイプをキャプチャします。 また、プライベートプレビューでは、各ノードがどの程度利用されているかを示すnode_utilization メトリクスが含まれます。
- クエリ履歴は、すべてのSQLコマンド、入出力パフォーマンス、返された行数に関する情報を保持します。
- クラスターテーブルには、汎用クラスターとジョブクラスターの長期にわたるクラスター構成の完全な履歴が含まれています。
- 予測最適化テーブルは、最高のパフォーマンスとコスト効率を実現するためにデータレイアウトを最適化するので、非常に優れています。 テーブルは、カタログ名、スキーマ名、テーブル名、コンパクションやバキュームに関する指標を提供することで、最適化されたテーブルのオペレーション、運用履歴を追跡します。
カタログエクスプローラーから、詳細を確認できるシステムテーブルのほんの一部を次に示します:
例として、"key_column_usage" テーブルを掘り下げていくと、テーブルが主キーを介してどのように互いに関連しているかを正確に見ることができます:
他の例としては、"share_recipient_privileges" テーブルがあります:
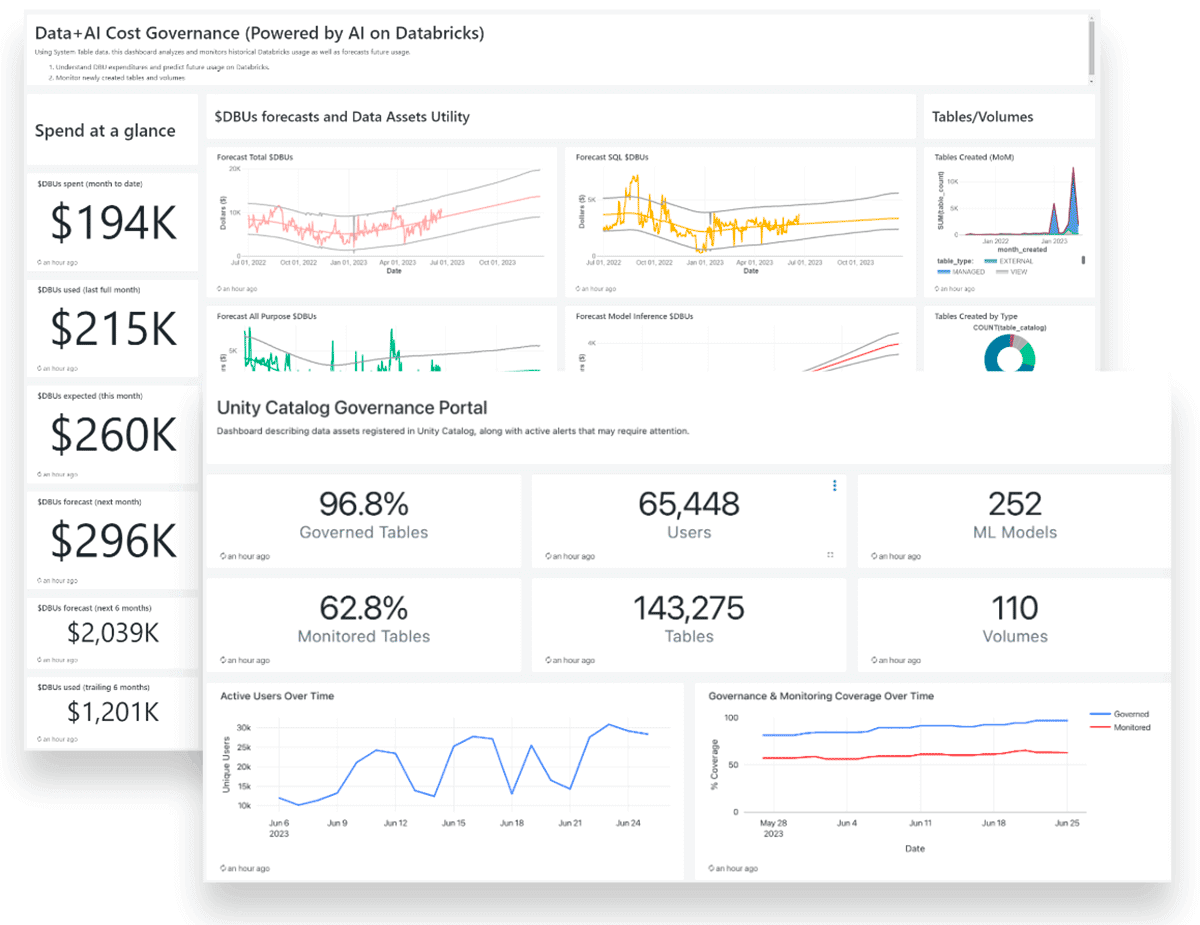
以下のダッシュボードの例では、ユーザ数、テーブル数、MLモデル数、監視対象テーブルの割合、Databricks DBUに費やされた金額などが表示されます:
包括的なデータとAIの監視・報告ツールを持つことは、何をもたらすか?
- 内部ポリシーやセキュリティ侵害の可能性をより的確に監視するこ�とで、コンプライアンス違反のリスクを低減し、レピュテーションを保護することで、従業員やパートナーからのデータおよびAIの信頼を向上させます。
- 「唯一の信頼できる情報源」、異常検知、信頼性メトリクスにより、データとAIの整合性と信頼性が向上します。
Databricks Unity Catalogを使用したバリューレバー
Unity Catalogがビジネスにもたらす価値について詳しくお知りになりたい場合は、以前のブログ「Unity Catalog Governance Value Levers」で、コンプライアンスに関するリスクの軽減、プラットフォームの複雑性とコストの削減、イノベーションの加速、社内外のコラボレーションの促進、データの価値の収益化について詳しく説明しています。
まとめ
ガバナンスは、リスクを軽減し、コンプライアンスを確保し、イノベーションを加速し、コストを削減するための鍵となります。 Databricks Unity Catalogは、クラウドとデータプラットフォームを横断する企業のすべてのデータとAIに単一の統合ガバナンスソリューションを提供する、市場でもユニークな製品です。
UC Databricksのアーキテクチャは、ガバナンスをシームレスにします。すべてのデータ資産の統一されたビューとディスカバリー、アクセス管理のための1つのツール、データとAIのセキュリティを強化するための監査のための1つのツール、そして最終的には、新しいビジネス価値を引き出すプラットフォームに依存しないコラボレーションを可能にします。
始めるのは簡単です。新規Databricksユーザー�の場合、UCはデフォルトで有効になっています! また、プレミアムワークスペースやエンタープライズワークスペースをご利用の場合、追加費用はかかりません。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。