オペレーショナル機械学習とは何ですか?
ライブデータに対するリアルタイム予測のために ML モデルを本番環境に導入するには、サービス提��供、監視、再トレーニング、統合のためのインフラストラクチャが必要です。
によって Databricks Staff による投稿
- デプロイメントパターンには、同期予測用のREST API、オフライン推論用のバッチスコアリング、デバイスへのエッジデプロイメント、レイテンシ、スループット、リソース制約のバランスをとるアプリケーション内への組み込みモデルが含まれます。
- モニタリングでは、予測精度、モデルパフォーマンス指標、分布の変化を検出するデータドリフト、関係の変�化を特定するコンセプトドリフト、リソース使用率、モデルの影響を測定するビジネスKPIを追跡します。
- MLOpsプラクティスには、モデルデプロイメント用のCI/CDパイプライン、自動再トレーニングトリガー、A/Bテストフレームワーク、リスクを最小限に抑えるカナリアデプロイメント、ロールバック機能、モデル障害に対するインシデント対応手順が含まれます。
著者: Kevin Stumpf、共同創業者兼CTO
2015年にUberの機械学習プラットフォームであるMichelangeloの展開を開始したところ、興味深い傾向が見えてきました。プラットフォーム上でローンチされた機械学習モデルの80%が、エンドユーザー(Uberの乗客とドライバー)のエクスペリエンスに直接影響を与えるオペレーショナル機械学習のユースケースを支えていたのです。分析的な意思決定を支援する分析機械学習(analytical machine learning)のユースケースは、わずか20%でした。
私たちが観測した運用機械学習と分析機械学習の比率は、他のほとんどの企業が現場で機械学習を応用する方法とは正反対でした。分析機械学習が主流だったのです。今にして思えば、Uber が運用機械学習を大規模に採用したことは当然とも言えます。Michelangelo によって運用機械学習の実装が非常に簡単になり、さらに同社にはインパクトの大き��いユースケースが数多くあったからです。7 年後の今日、Uber の運用機械学習への依存度は高まるばかりです。もしそれがなければ、採算の取れない乗車料金やひどい ETA 予測が表示され、不正行為によって数億ドルもの損失が出ていたでしょう。要するに、運用機械学習がなければ、会社は機能停止に陥っていたでしょう。
オペレーショナル機械学習はUberの成功の鍵となってきましたが、長い間、それは巨大テック企業だけが達成できることのように思われていました。しかし幸いなことに、この7年間で多くのことが変わりました。新しいテクノロジーやトレンドのおかげで、どんな企業でも、主に分析機械学習を使っていたところからオペレーショナル機械学習の活用に切り替えられるようになりました。この記事では、そのためのヒントをいくつかご紹介します。詳しく見ていきましょう。
オペレーショナル機械学習と分析機械学習
オペレーショナル機械学習とは、アプリケーションが 機械学習 モデルを使用して、ビジネスにリアルタイムで影響を与える意思決定を自律的かつ継続的に行うことです。これらのアプリケーションはミッションクリティカルであり、企業の運用スタック上の本番運用で「オンライン」に実行されます。
一般的な例としては、レコメンデーション システム、検索ランキング、動的価格設定、不正検知、ローン申請の承認などがあります。
「オフライン」の世界におけるオペレーショナル機械学習の兄貴分が、分析機械学習です。これらは、ビジネスユーザーがmachine learningを使ってより良い意思決定を下すのを助けるアプリケーションです。�分析機械学習アプリケーションは企業の分析スタックに配置され、通常はレポート、ダッシュボード、ビジネスインテリジェンスツールに直接データを提供します。
一般的な例としては、売上予測、解約予測、顧客セグメンテーションなどがあります。
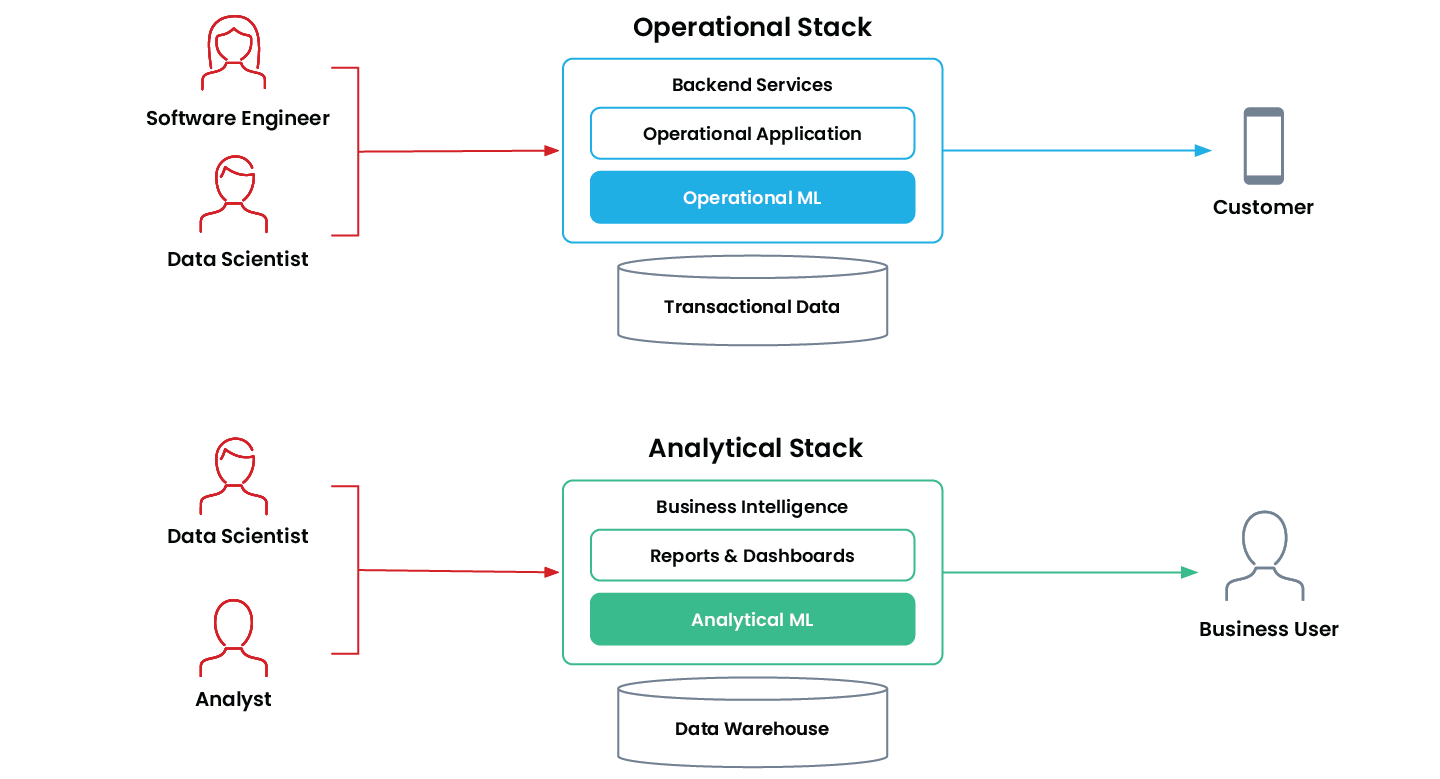
組織はオペレーショナル機械学習と分析機械学習を異なる目的で使用し、それぞれに異なる技術的要件があります。
| 分析機械学習 | オペレーショナル機械学習 | |
|---|---|---|
| 意思決定の自動化 | ヒューマンインザループ | 完全自律型 |
| 意思決定スピード | 人間のスピード | リアルタイム |
| 最適化の対象 | 大規模なバッチ処理 | 低レイテンシと高可用性 |
| 主な対象者 | 社内のビジネスユーザー | お客様 |
| 機能 | レポート&ダッシュボード | 本番運用アプリケーション |
| 例 | 売上予測 リードスコアリング 顧客セグメンテーション 解約予測 | 製品のレコメンデーション 不正検知 トラフィック予測 リアルタイムの価格 |
分析機械学習とオペレーショ�ナル機械学習の特徴
オペレーショナル Machine Learning の実践
Uber Eats の実際の運用machine learningの例を、より具体的に見ていきましょう。アプリを開くと、おすすめのレストランのリストが表示され、注文した商品が玄関先に届くまでの待ち時間の目安が提示されます。アプリではシンプルに見えますが、その裏側は実は非常に複雑です:
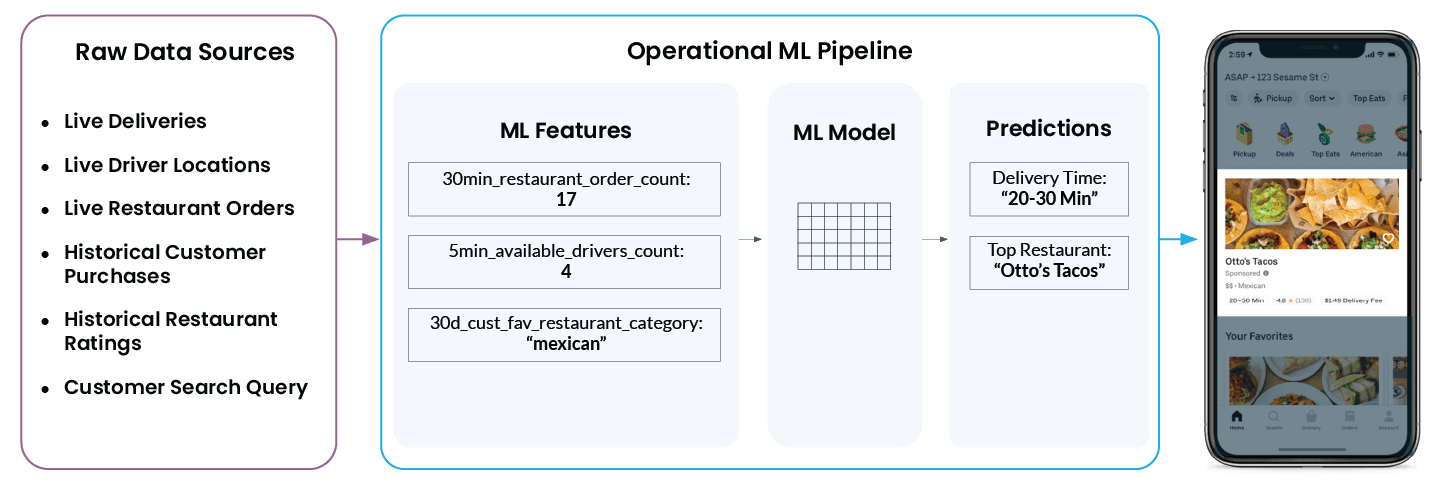
アプリで最終的に「Otto’s Tacos」と「20~30 分」を表示するには、Uber の機械学習プラットフォームがさまざまな生のデータソースから多種多様なデータを調べる必要があります。
- 現在、レストランの周辺には何人のドライバーがいますか?注文を配達中ですか、それとも次の配車が可能ですか?
- レストランの厨房は今、どのくらい混雑していますか?レストランが現在処理している注文が多ければ多いほど、新しい注文の起動に取り掛かるまでにより長い時間がかかります。
- 顧客が過去に高く評価したレストランと、低く評価したレストランはどれですか?
- ユーザーが現在、積極的に検索している料理の種類は何ですか?
- そして…ユーザーの現在地はどこですか?
Michelangelo の特徴量プラットフォームは、このデータを機械学習の特徴量に変換します。これらは、モデルが学習し、リアルタイムで予測を行うために使用するシグナルです。例えば、‘num_orders_last_30_min’ は配達時間を予測するための入力特徴量として使用され、その結果が最終的にモバイルアプリに表示されます。
上記で概説した、多種多様なデータソースから生データを特徴量に、特徴量を予測に変換するステップは、あらゆるオペレーショナルmachine learningのユースケースに共通しています。システムがクレジットカードの不正利用を検出しようと、自動車ローンの金利を予測しようと、新聞の国際情勢欄の記事を提案しようと、あるいは2歳児に最適なおもちゃを推薦しようと、その技術的な課題は同じです。そして、まさにこの根本的な技術の共通性こそが、すべてのオペレーショナル機械学習ユースケースのための単一の集中プラットフォームの構築を可能にしたのです。
エンタープライズ向けエージェントAIプレイブック

運用Machine Learningを可能にするトレンド
Uber は、技術スタック全体を最新のデータアーキテクチャと原則に基づいて構築していたため、運用機械学習を活用する準備が整っていました。ここ数年、シリコンバレーの枠をはるかに超えて、同様の現代化が進んでいるのを目の当たりにしてきました。
ヒストリカルデータはほぼ無期限に保存されます
ここ数年でデータストレージのコストは大幅に低下しました。その結果、企業は顧客とのあらゆるタッチポイントに関する情報を収集、購入、保存できるようになりました。これは ML にとって極めて重要です。優れたモデルをトレーニングするには、大量のヒストリカルデータが必要だからです。そして、データがなければ、machine learningは成り立ちません。
データのサイロ化が解消されつつあります
Uber は初日から、ほぼすべてのデータを Hive ベースの分散ファイル システムに一元化しました。一元化されたデータストレージ(または代替として、分散データストアへの中央集権的なアクセス)は、機械学習モデルをトレーニングするデータサイエンティストがどのようなデータが利用可能で、どこにあり、どのようにアクセスできるかを知ることができるため重要です。ほとんどの企業では、すべてのデータ(アクセス)がまだ完全には一元化されていません。しかし、The Modern Data Stack のようなアーキテクチャのトレンドは、データアクセスの民主化というデータ サイエンティストの夢を、現実のものとして大きく脚光を浴びさせています。
ストリーミングによってリアルタイムデータが利用可能になります
Uberでは幸運なことに、データストリームの「中枢神経系」としてKafkaがありました。サービスやモバイルアプリからの多くのリアルタイムシグナルが、Kafkaを介してストリームされます。これはオペレーショナル機械学習にとって非常に重要です。
昨日の出来事しか知らなければ、不正を検知することはできません。過去 30 秒間に何が起こったかを知る必要があります。データウェアハウスとデータレイクは、ヒストリカルデータを長期保存するために構築されています。そして過去数年間で、アプリケーションにリアルタイムのシグナルを供給するために、Kafka や Kinesis のようなストリーミング インフラストラクチャが大規模に採用されるようになりました。
MLOps は迅速なイテレーションを可能にします。
Uber では、個々のエンジニアが本番運用システムに毎日変更を加える権限を与えられています。このプロセスは、DevOps の原則に従い、それを自動化することによってサポートされています。Michelangelo によって、私たちはそのプロセスが MLOps と呼ばれるようになる前に、これらの原則を運用機械学習に導入しました 🙂。データサイエンティストがモデルをトレーニングし、文字通り1日以内に安全に本番運用にデプロイできることは、私たちにとって重要でした。
Uber やシリコンバレーの枠をはるかに超えて、MLOps を通じて DevOps の原則と自動化を、ソフトウェアエンジニアリングだけでなくデータサイエンスチームにも導入するアーリーアダプターが増えています。もちろん、ほとんどの企業にとって機械学習は、このブログで概説した理由から、依然としてソフトウェアよりもはるかに厄介なものです。しかし、業界は着実に未来に向かっており、いずれはフォーチュン 500 に名を連ねるような一般的な企業にいるごく普通のデータサイエンティストが、1 日に何度も運用機械学習モデルのイテレーションを実行できるようになると私は確信しています。
運用機械学習を可能にする最新のデータアーキテクチャは次のようになります。
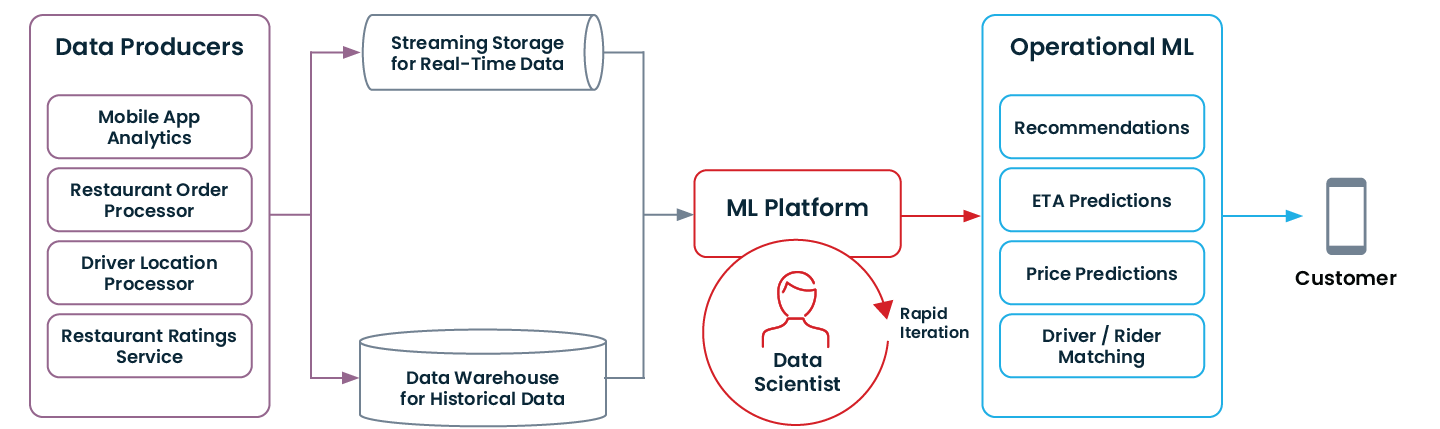
あなたの組織が、上記で述べたいくつかの現代化をすでに実施している(あるいは、ゼロから始めている!)のであれば、機械学習の運用を始める準備ができているかもしれません。
オペレーショナルMachine Learningを起動しましょう
2013年、Uberは本番運用でmachine learningを使用していませんでした。現在、本番運用で数万ものモデルを実行しています。その変化は一夜にして起こったわけではありません。
組織で運用機械学習の活用を検討している場合は、次のステップを実行することをお勧めします。
machine learningに適したユースケースを選びましょう
すべての問題が機械学習で解決できるわけではありません。機械学習の活用に適した問題の条件:
- システムが、非常に似通った反復的な意思決定を多数(少なくとも数万回)行っている
- 正しい意思決定をすることは、簡単なことではありません
- 意思決定後、しばらく経ってから、その決定が良かったか悪かったかを判断できます。
これらの要素が当てはまる場合、machine learningアプリケーションは意思決定を行い、その決定から学習し、継続的に改善することができます。
実際に重要なユースケースを選びましょう
前述のとおり、最初のモデルを本番運用に導入するまでの道のりは困難です。最初のmachine learningアプリケーションの将来的な見返りがあまり期待できない場合、困難に直面したときに簡単に諦めてしまうでしょう。優先順位は変わり、経営陣はしびれを切らし、その取り組みは長続きしないでしょう。ポテンシャルの高いユースケースを選びましょう。
最初のモデルでは、少人数のチームに権限を与え、ステークホルダーを最小限に抑えましょう
モデルのトレーニングとデプロイに関わる引き継ぎの数が増えるほど、プロジェクトの失敗確率は高まります。理想的には、必要なすべてのデータにアクセスでき、単純なモデルをトレーニングする方法を把握しており、アプリケーションを本番運用に導入できる程度にプロダクション スタックに精通している 2~3 人の小規模なチームから起動するとよいでしょう。
機械学習エンジニアは、データエンジニアリング、ソフトウェアエンジニアリング、データサイエンスのスキルを併せ持つ稀有な存在であるため、この道を切り開くのに最も適しています。これはまた、機械学習の専門家からなる小グループを製品開発チームに組み込むという、machine learningチームをスケールさせる方法でもあります。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。