Catalyst Optimizer とは何ですか?
Catalystオプティマイザーがツリー構造のクエリプランでルールベースとコストベースのテクニックを使用して、Spark SQLクエリをより高速かつ効率的にし、拡張しやすくする方法
によって Databricks Staff による投稿
- Catalyst が Spark SQL の中核を担い、パターンマッチングや準引用符などの Scala 機能を基盤とした拡張可能なオプティマイザーとして、新しいルールやデータ型をサポートする仕組みをご覧ください。
- Catalyst がクエリをツリーとして表現し、分析、論理最適化、物理計画、コード生成の各フェーズにルールを適用して効率的な実行プランを作成する仕組みをご覧ください。
- Catalyst がルールベースとコストベースの両方の最適化をサポートし、外部データソースやユーザー定義型用の拡張ポイン�トを公開する仕組みをご覧ください。
Catalyst オプティマイザとは、Spark SQL で主要な役割を果たす最適化機能です。Scala のパターンマッチングや準クォートなどの高度なプログラミング言語の機能を斬新な方法で利用し、拡張可能なクエリオプティマイザを実現します。Catalyst は Scala の関数型プログラミング構造に基づいており、次の 2 つの主要な目的を想定して設計されています。
- Spark SQLへの新しい最適化技術と機能の追加を容易にする
- 外部の開発者でもオプティマイザの拡張を実行できるようにする(データソース特有のルール追加、新規データ型のサポートなど)
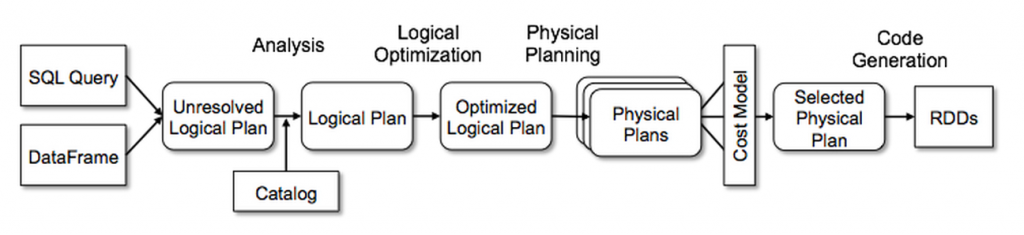 Catalyst には、ツリーを表示しルールを適用して操作するための一般的なライブラリが含まれています。
Catalyst には、ツリーを表示しルールを適用して操作するための一般的なライブラリが含まれています。
このフレームワークに加えて、リレーショナルクエリ処理(数式、論理クエリプランなど)に特化したライブラリと、分析、ロジック最適化、物理的プランニング、Java バイトコードに一部のクエリをコンパイルするコード生成など、クエリ実行のさまざまなフェーズを処理する数種のルールセットがあります。ルールセットは、Scala の別の機能である準クォートを使用し、実行時に構成可能な式から効率的にコードを生成できます。Catalyst は、外部データソースやユーザー定義型など、パブリックの拡張ポイントをいくつか提供し、ルールベースとコストベースの最適化をサポートします。
FAQ
エンタープライズ向けエージェントAIプレイブック

Catalystオプティマイザとは何ですか?
Spark SQLでクエリを最適化する仕組みで、拡張性と柔軟性を備えたフレームワークです。
どのような最適化を行いますか?
論理プランの最適化、物理プランニング、コード生成など複数のフェーズでクエリ効率を高めます。
開発者は拡張できますか?
はい。外部データソースや新しいデータ型への対応ルールを追加するなど、容易に拡張可能です。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。