データ仮想化とは何ですか?
物理的に移動または複製することなく、複数のソースからデータにアクセスしてクエリを実行し、統合された仮想レイヤーを作成します。
によって Databricks Staff による投稿
- データ仮想化とは何か、そしてそれが統合インターフェースを通じて異種システム間のデータアクセスをどのように抽象化するかを理解します。
- 仮想化によってデータの移動が削減され、アーキテクチャが簡素化され、分散データソースへのリアルタイムアクセスがどのように実現されるかを学びます。
- フェデレーションクエリ、レガシーシステム統合、複雑なETLプロセスを必要としないアジャイル分析などのユースケースを学習します。
データ仮想化とは?
データ仮想化は、データを物理的に移動したりコピーしたりすることなく、組織が複数のデータソースからの情報の統合ビューを作成できるようにするデータ統合手法です。コアとなるデータ仮想化技術として、このデータマネジメントのアプローチは、データ利用者が単一の仮想レイヤーを通じて、異なるシステムからデータにアクセスすることを可能にします。データを中央リポジトリに抽出する代わりに、データ仮想化はデータコンシューマーとソースシステムの間に抽象レイヤーを配置します。基盤となるデータは元の場所に残ったままで、ユーザーはこのレイヤーに単一のインターフェースを通じてクエリーを実行します。
データ仮想化は、現代のデータマネジメントにおける基本的な課題に対処します。その課題とは、エンタープライズデータがデータベース、データレイク、ク�ラウドアプリケーション、レガシーシステムなど、複数のソースに分散していることです。従来のデータ統合アプローチでは、分析を開始する前に、データを中央のwarehouseに移動するための複雑なパイプラインを構築する必要がありました。データ仮想化は、情報がどこにあってもリアルタイムアクセスを提供することで、その遅延を解消します。
企業がマルチクラウド環境、レイクハウス アーキテクチャ、組織横断的なデータ共有を採用するにつれて、データ仮想化への関心が高まっています。こうした傾向により、チームがアクセスする必要のあるソースの数が増加し、物理的な統合はますます非現実的になっています。データ仮想化は、ストレージを統合することなくアクセスを統合する方法を提供します。
データ仮想化テクノロジーは、データコンシューマーとソースシステムの間に位置する仮想化レイヤーを作成します。この仮想レイヤーにより、ビジネスユーザーは各ソースの技術的な複雑さを理解することなく、データレイク、データウェアハウス、クラウドストレージサービスにまたがってデータにクエリーを実行できます。データ仮想化を導入することで、組織は一元化されたガバナンスを維持しながら、チームが複数のソースからのデータをリアルタイムで組み合わせることを可能にします。
明確にしておくべき、よく混同されがちな点が1つあります。データ仮想化とデータ可視化は響きは似ていますが、まったく異なる問題を解決するものです。データ仮想化は、分散ソース全体にアクセスレイヤーを作成する統合テクノロジーです。データ可視化は、ビジネスインテリジェ�ンスのために情報をチャート、グラフ、ダッシュボードとして表示するプレゼンテーションテクノロジーです。この2つは補完的な関係にあります。データ仮想化が統合アクセスを提供し、それを可視化ツールが人間が判読可能な形式で表示します。
アジャイルなデータマネジメントを追求する組織にとって、データ仮想化は、従来のアプローチのようなインフラストラクチャのオーバーヘッドなしに、より迅速な知見を得るための道筋を提供します。
関連リンク:ETLプロセスとデータ統合戦略
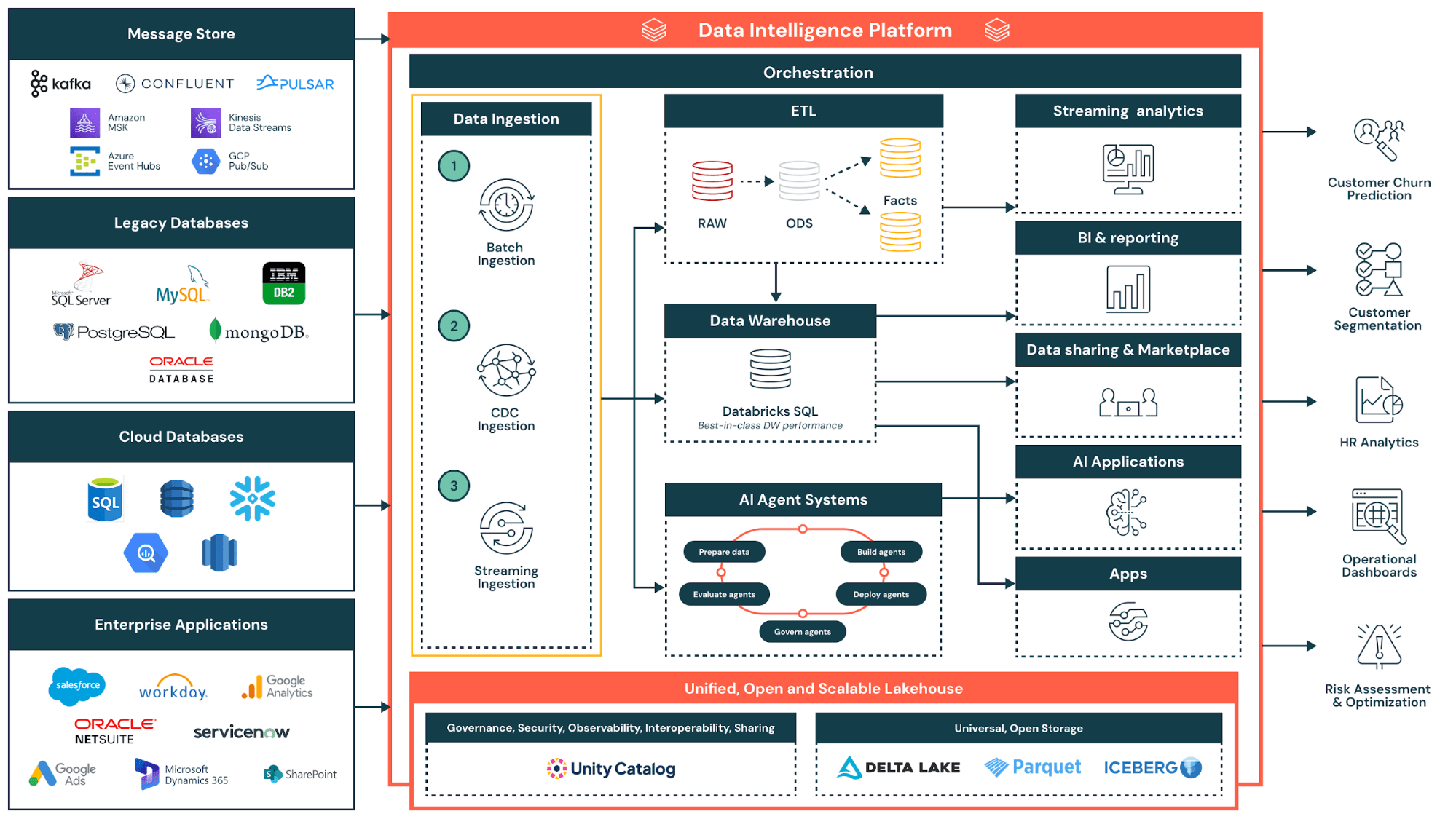
データ仮想化の仕組み: アーキテクチャとコンポーネント
データ仮想化アーキテクチャは、ビジネス定義のためのセマンティックデータレイヤー、クエリーフェデレーションのための仮想化レイヤー、ガバナンスのためのメタデータ管理という、3つの主要なデータマネジメントインフラストラクチャコンポーネントで構成されています。最新のプラットフォームはこれらのコンポーネントを統合し、データサイエンティスト、ビジネスユーザー、データコンシューマーが情報がどこに保存されているかを知ることなくデータソースやデータサービスにアクセスできる、完全な仮想データ環境を構築します。
仮想化レイヤーは、データコンシューマー(アナリスト、アプリケーション、BIツールなど)と基盤となるデータソー��スの間に位置します。このレイヤーは、データがどこに存在し、どのように構造化され、どうアクセスするかについてのメタデータを維持します。このレイヤー自体はデータを保存せず、インテリジェントなルーティングおよび変換エンジンとして機能します。Unity Catalogのようなガバナンスソリューションは、このメタデータを一元管理し、検出とアクセスポリシーのための単一の制御ポイントを提供できます。
ユーザーがクエリーを送信すると、データ仮想化エンジンが関連情報を含むデータソースを特定します。リレーショナルデータベースの場合はSQL、クラウドアプリケーションの場合はAPI呼び出し、データレイクの場合はファイルアクセスプロトコルなど、各システムのネイティブ言語にクエリーを変換します。エンジンはリクエストをシステム全体にフェデレーションし、結果をまとめて統一されたレスポンスを生成します。
データ仮想化は、この分散実行モデルを表すクエリー フェデレーションを可能にします。複雑なクエリーはサブクエリーに分割され、それぞれが適切なソースにルーティングされます。結果は仮想化レイヤーに返され、そこで結合および変換された後、単一の回答としてユーザーに配信されます。例えば、Lakehouse Federation を使用すると、ユーザーは最初にデータを移行することなく、レイクハウスから直接、外部データベース、ウェアハウス、クラウド アプリケーションに対してクエリを実行できます。パフォーマンスの最適化は、述語プッシュダウンのような技術を通じて行われます。この技術では�、フィルタリングロジックが中央ではなくソースで実行されます。
最新のプラットフォームでは、ジョインプッシュダウン、カラムプルーニング、インテリジェントキャッシングも実装されています。ソースの応答時間が異なる場合、エンジンはクエリーを並列実行し、タイムアウト処理を適用して、遅いソースが結果をブロックするのを防ぎます。これらの最適化により、仮想化されたクエリーは、物理的に統合されたデータに対するクエリーのパフォーマンスに近づきます。
レイクハウスネイティブのデータ仮想化は、フェデレーションデータと内部データの両方にわたる統一されたガバナンスという、さらなる利点を提供します。Unity Catalogがアクセスポリシーを管理することで、組織は外部データベースとlakehouseのテーブルに同じセキュリティルールを適用します。ユーザーは、個別のシステムや権限を管理することなく、同じSQLステートメントで仮想化されたデータと物理データをクエリーします。
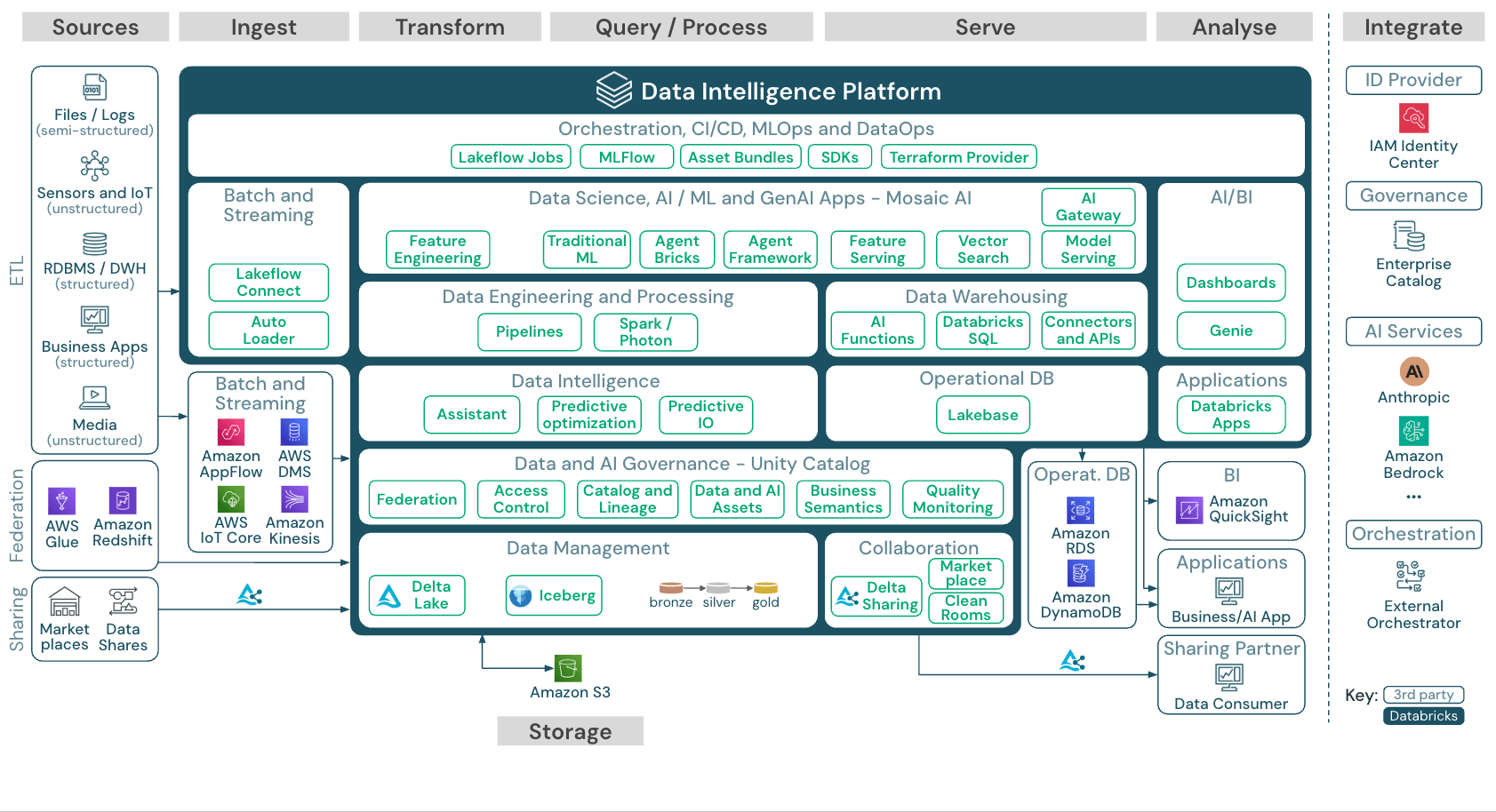
データ仮想化とETL: 主な違い
従来のETL(抽出, 変換, ロード)は、ソースシステムから中央のウェアハウスやレイクにデータを物理的に移動します。これにより、コピーが作成され、抽出サイクル間にレイテンシーが発生し、継続的なパイプラインのメンテナンスが必要になります。データ仮想化は逆のアプローチを取ります。データはその場に留まり、オンデマンドでアクセスされます。
そ��れぞれのアプローチは、異なるユースケースに対応します。主要な側面における違いを見てみましょう。
データ移動: ETL はデータを中央リポジトリにコピーします。データ仮想化は、重複を作成することなく、その場でデータにクエリーを実行します。
データの鮮度: ETLは、最後の更新サイクル時点のデータを提供しますが、これは数時間または数日前のものである可能性があります。データ仮想化は、ライブソースデータへのリアルタイムアクセスを提供します。
知見を得るまでの時間: ETLでは、分析を開始する前にパイプラインを構築する必要があり、多くの場合、数週間から数か月かかります。データ仮想化は、接続が構成されるとすぐにアクセスを提供します。
複雑な変換: ETLは、複数ステップの処理や履歴分析に優れています。データ仮想化は結合やフィルターは処理できますが、複雑な変換ロジックは苦手です。
ほとんどの組織は、両方のアプローチを併用しています。ETLとELTは、複雑な変換、履歴トレンド、パフォーマンスが重要なバッチワークロードを処理します。データ仮想化は、アドホック分析や運用ダッシュボードのためのアジャイルなリアルタイムアクセスを提供します。どちらを選択するかは、イデオロギーではなく、ワークロードの特性によって決まります。
クロスリンク: Unity Catalogによる統合ガバナンスとデータアーキテクチャパターン
主な利点: データ移動を伴わないリアルタイムアクセス
データ仮想化のビジ��ネスケースは、スピード、コスト削減、ガバナンスの簡素化が中心となります。データ仮想化により、組織はストレージコストを削減し、ビジネスユーザーのデータアクセスを改善し、さまざまなソースにまたがるインフラストラクチャを簡素化できます。
1. ストレージとインフラストラクチャのコスト削減
データ仮想化は、データ複製コストを削減することで、すぐに価値を生み出します。重複を排除することで、組織はwarehouse、マート、分析環境にわたって同じ情報の複数のコピーを保存するための支払いをやめることができます。データ量が増加し、チームが同期されたコピーを維持するというインフラストラクチャの複雑さを回避するにつれて、ストレージの節約効果は積み重なります。
2. データ利用者のためのほぼリアルタイムの知見
クエリーは、古いウェアハウスのコピーではなく、ライブシステムに対して実行されます。例えば、金融サービス会社はこの機能を使って不正検知を行い、小売業者は取引発生時にチャンネル全体の在庫を追跡し、医療システムは治療中に現在の患者記録にアクセスする可能性があります。ストリーミングパイプラインを構築することなく、リアルタイム分析が可能になります。
3. インフラストラクチャの簡素化
データ仮想化を導入することで、組織は複数のシステムにわたってガバナンスを複製するのではなく、アクセス ルール、セキュリティ ポリシー、メタデータを仮想データレイヤーに一元化します。管理者は、各ソースで個別にポリシーを維持するのではなく、一度ポリシーを定義するだけで済みます。スタンドアロンのインフラストラクチャとしてデプロイするのではなく、レイクハウス プラットフォームに組み込むことで、チームはさらに別のシステムを管理する必要がなくなります。
4. ビジネスイニシアチブの価値実現までの時間を短縮
企業は、デリバリーのタイムラインを数週間から数日、または数時間に短縮したと報告しています。この高速化は、新しい分析ユースケースごとに ETL パイプラインを設計、構築、テスト、維持するために通常必要とされる数か月を排除することによって実現されます。
これらのメリットは、多様なデータソース、急速に変化する要件、および履歴の深さよりもデータの鮮度を重視するシナリオに最も強く当てはまります。
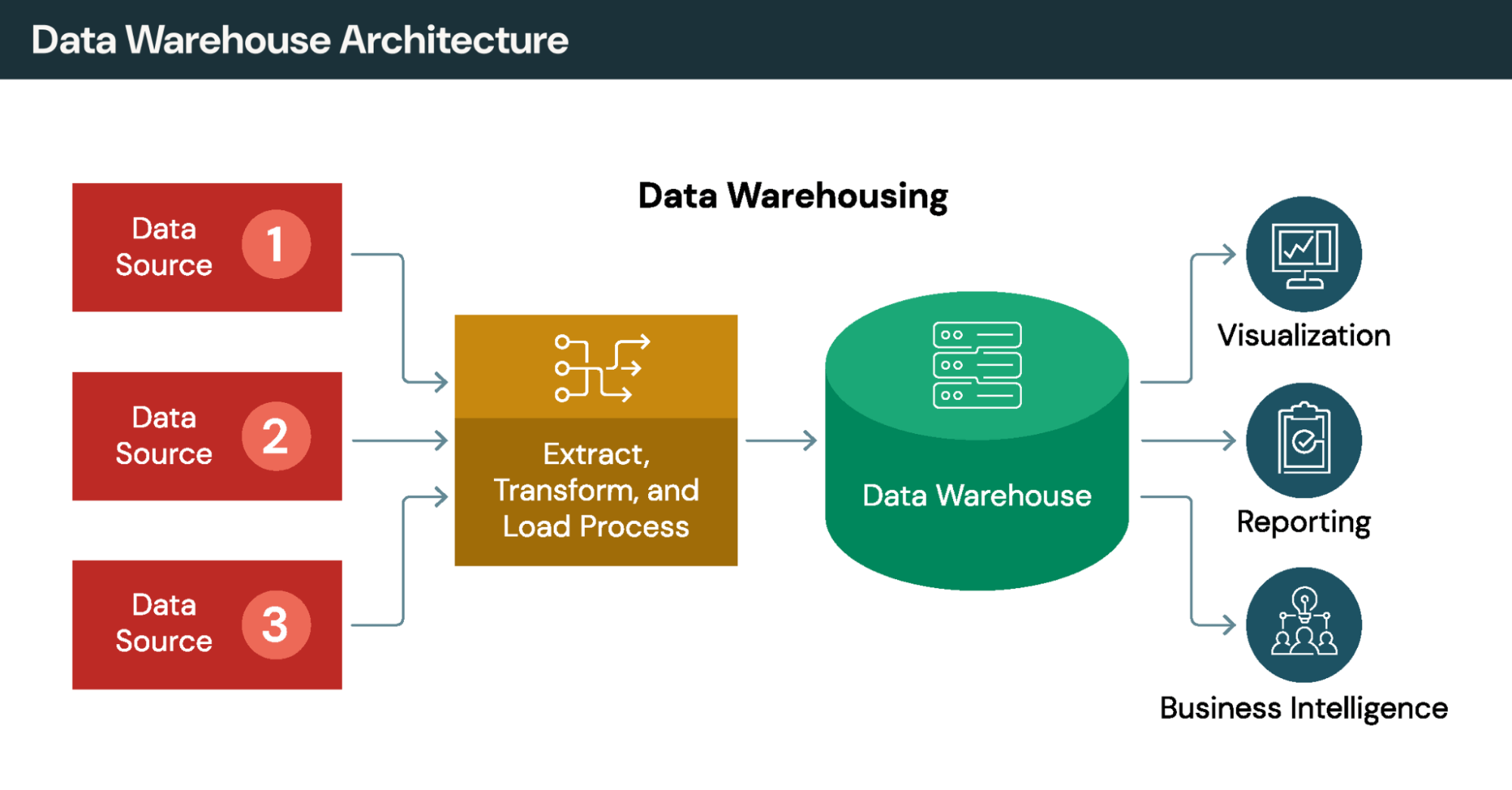
統合アプローチの比較
ETL などの従来の統合方法では、データを物理的に中央リポジトリに移動します。データ仮想化は、複製することなく、その場でデータにアクセスするという異なるアプローチを取ります。組織は、複雑な変換には ETL、アジャイルなアクセスにはデータ仮想化というように、両方の戦略を組み合わせることがよくあります。
クロスリンク: リアルタイム分析機能と 最新のデータウェアハウジング
エンタープライズ向けエージェントAIプレイブック

実用的なユースケースと業界アプリケーション
データ仮想化テクノロジーは、組織が運用システム、データレイク、クラウドアプリケーションにわたって統合アクセスを必要とする場合に優れています。データ仮想化により、従来のデータ統合プロジェクトのようなリードタイムなしで、複数のソースからのリアルタイムアクセスが可能になります。以下の例は、一般的なパターンを示しています。
リテール・消費財
小売業者は、eコマース プラットフォーム、実店舗システム、倉庫管理アプリケーション、POS 端末、サプライヤー ネットワークにわたって事業を展開しています。データ仮想化を導入すると、ポイントツーポイントの統合を構築することなく、複数のシステムにわたるアクセスを提供することで、エンドツーエンドのサプライチェーンの可視性が生まれます。
在庫管理は、リアルタイムデータ仮想化から特に恩恵を受けます。小売業者は、毎晩在庫数をバッチ同期するのではなく、すべてのチャンネルからライブデータにクエリを実行して、正確な在庫状況を提供します。これにより、顧客が注文する前に最新の在庫情報を必要とする、オンラインで購入して店舗で受け取るような機能がサポートされます。サプライチェーンアクセスのためにデータ仮想化を導入している組織は、在庫維持コストの削減と需要予測精度の向上により、大幅なコスト削減を報告しています。
金融サービス
金融サービス会社は、データ仮想化ソリューションを使用して、クレジットカードの取引、預金、ローンシステム、CRMプラットフォーム、および外部プロバイダーからの顧客データを集約し、包括的な顧客プロファイルを作成します。データ仮想化は、更新の間に古くなる事前構築済みの顧客レコードを維持するのではなく、オンデマンドでこれらのビューを組み立てます。
リアルタイムの不正検知には、複数のアカウントにわたる取引パターンへの 1 秒未満のアクセスが必要です。バッチ指向のウェアハウスでは、このレイテンシ要件をサポートできません。規制コンプライアンスにもメリットがあります。審査官のレビューのために監査証跡を維持しながら、システム全体での統合レポート��が可能になります。
医療・ヘルスケア
患者データは機密性が高く、電子カルテ、請求システム、画像アーカイブ、検査情報システムに分散しています。データ仮想化により、臨床医はデータをソースに保持したまま、ケア提供中に統一された患者ビューにアクセスできます。各システムはデータを独立して保存しますが、患者の履歴を確認する医師は、1 回のクエリーでプライマリケア、専門医の診察、検査結果の記録を確認できます。
このアーキテクチャはプライバシー要件をサポートします。機密情報が侵害に対して脆弱な単一の場所に集中することがないためです。病院や医療システムは、組織間でデータを物理的に転送することなくアクセスを共有できるため、連携したケアが可能になります。
データ仮想化が適していない場合
データ仮想化には明確な制限があります。大量のバッチ処理では依然として物理的な移動が必要です。数百万行を処理しても、一度データを移動する場合と比べてパフォーマンス上の利点はありません。例えば、1時間あたり数百万件のトランザクションを処理する決済処理業者は、そのワークロードを仮想化してもメリットは得られません。データ仮想化は現在のデータにしかアクセスしないため、特定の時点のスナップショットを必要とする履歴分析には、時間の経過とともに状態を記録するwarehouseが必要です。複雑な複数ステップの変換は、データベース形式の結合、フィルター、集計に限定された機能では処理できません。
非常に大規模なwarehouseの実装、データセンター間のオペレーション、および保証された低レイテンシーを必要とするワ�ークロードでは、通常、データエンジニアリングパイプラインを介した物理的な移動が必要になります。
クロスリンク: データレイクとビジネス インテリジェンス アプリケーション
ガバナンス、セキュリティ、品質に関する考慮事項
データ仮想化は、一元化された仮想化レイヤーに制御を統合することで、ガバナンスを強化します。データ仮想化ツールを使用すると、管理者は、ばらばらのソース全体で個別に管理するのではなく、セキュリティ ポリシーを一度定義するだけで済みます。
最新のプラットフォームのセキュリティ機能には、役割ベースのアクセス制御、行レベルおよび列レベルのセキュリティ、機密フィールドのデータマスキングなどがあります。分類タグに関連付けられた属性ベースのアクセス制御により、ユーザーのアクセス方法に関係なく、ポリシーをデータとともに移動させることができます。アナリストが SQL クエリー、REST APIs、BI ツールのいずれを介して接続しても、同じセキュリティ ルールが適用されます。
監査とリネージの追跡により、誰が、いつ、どのアプリケーションから、どのデータにアクセスしたかが記録されます。 Unity Catalog は、コンプライアンス レポート用に、��すべての言語にわたるユーザーレベルの監査ログとリネージを提供します。この可視性は、実証可能なガバナンスを要求するGDPR、HIPAA、CCPA、および金融規制をサポートします。
クエリーはライブソースに直接アクセスするため、データの鮮度はデータ仮想化に固有のものです。しかし、これによりデータ品質に関する考慮事項が生じます。システムにエラーや不整合が含まれている場合、データ仮想化はそれらの問題をコンシューマーに直接公開してしまいます。効果的な実装では、データ仮想化とデータ品質モニタリングを組み合わせて、統合ビューの完全性が維持されるようにします。
セマンティックの一貫性も、もう1つの課題です。異なるシステムでは、同じ概念に異なる名前を使用したり、同等のフィールドに異なるデータ型を使用したり、同様のメトリクスに別のビジネス定義を使用したりすることがあります。各システムがデータを異なる方法でラベル付けし、フォーマットしていても、CRMの顧客データが請求システムの同じ顧客と一致するように、仮想化レイヤーは一貫した命名規則を適用する必要があります。組織によっては、すべての仮想化ソースに適用される正規のビジネス用語と計算を定義するためにセマンティックデータレイヤーを追加し、どこの基盤システムにデータが保存されているかに関係なく、アナリストが一貫した定義を参照できるようにしています。
クロスリンク: Unity Catalogによるデータガバナンスとデータマネジメントのベストプラクティス
実装のベストプラクティスとツールの選択
データ仮想化を導入する組織は、デプロイを成功させるために、実績のあるパターンに従う必要があります。小さく始める: 成功した導入は、多くの場合、小規模なチームが特定の価値の高いプロジェクトに取り組み、利害関係者に価値を実証した後にのみ拡大することから始まります。テクノロジーをデプロイする前に、所有権、セキュリティ モデル、開発標準を確立して、最初にガバナンスを定義します。パフォーマンスを定期的に監視して、実行速度の遅いクエリーを特定し、頻繁にアクセスされる仮想ビューを最適化し、使用パターンの変化に応じて接続を調整します。
データ仮想化の実際:現実世界での実装
具体的な例を考えてみましょう。ある小売企業が顧客生涯価値を分析したいと考えていますが、顧客データはSalesforce CRMに、取引履歴はPostgreSQLデータベースに、ウェブサイトの行動履歴はGoogle Analyticsにあり、返品データはレガシーのOracleシステムに残っています。
従来のデータ統合では、ETLパイプラインを構築して、これらすべてのデータを抽出し、変換し、warehouseにロードする必要があります。そのプロジェクトには数か月かかります。データ仮想化を使用すると、管理者は各ソースへの接続を作成し、システム間のデータを組み合わせた仮想ビューを公開します。アナリストは、使い慣れたSQLを介してこのビューにクエリーを実行するか、BIツールを直接接続します。すべてのソースからの最新データを1つの統一されたスキーマで確認できます。後で会社が独自のデータベースを持つモバイルアプリを追加した場合、そのソースを仮想ビューに追加するには、ウェアハウスの再設計を必要とせずに数日で完了します。
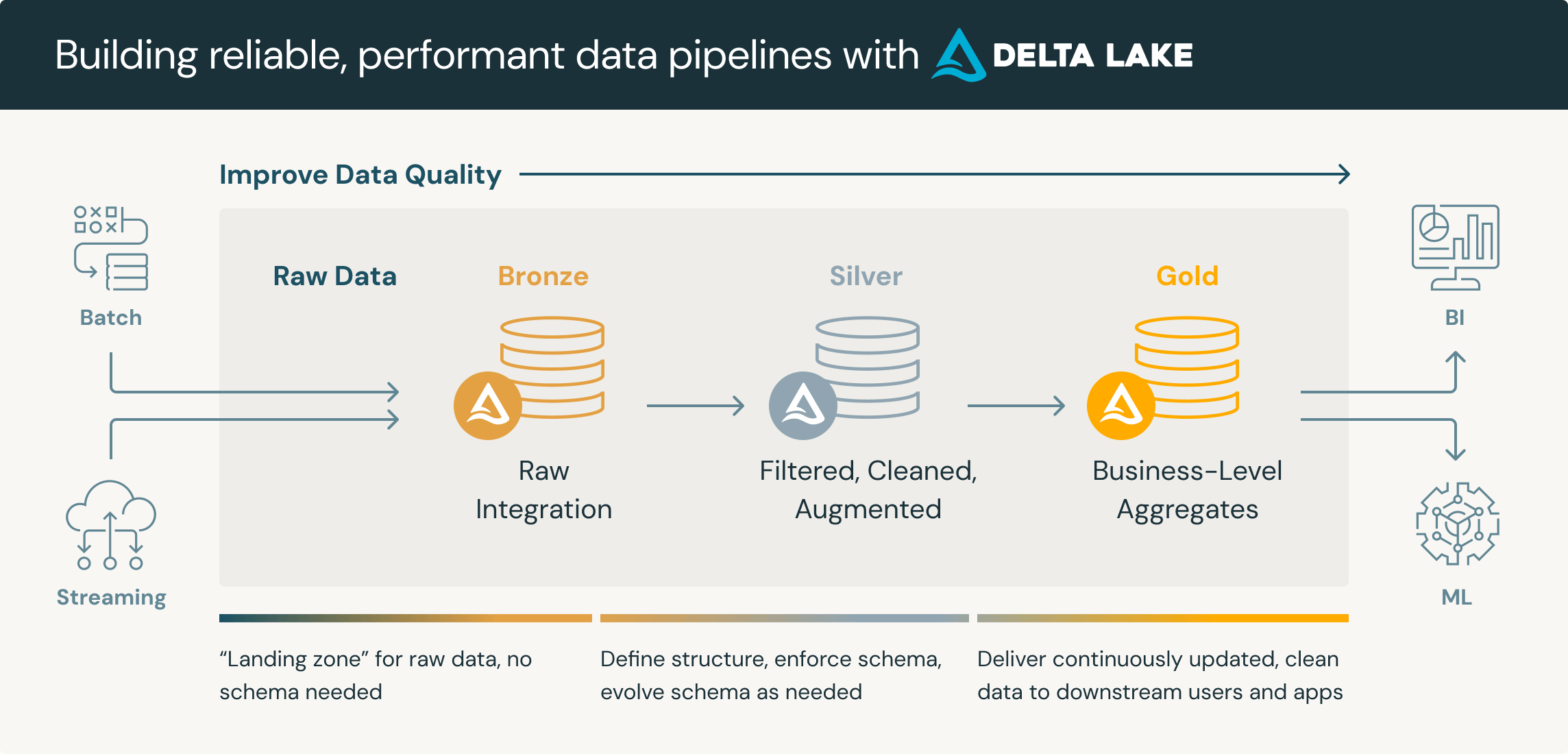
このパターンは、「最初に仮想化し、後で移行する」という戦略もサポートします。チームはまず外部ソースへのクエリーをフェデレーションし、その後、どのデータが最も頻繁にアクセスされるかを監視します。使用頻度の高いデータセットは、 Delta Lakeへの物理的な移行の候補になります。Delta Lakeでは、クエリーのパフォーマンスが向上し、ストレージコストが削減される可能性があります。使用頻度の低いデータは仮想化されたままになるため、不要な移行の手間が省けます。
データ仮想化ソフトウェアとツールの評価
データ仮想化ツールを評価する際は、3つの基準を優先してください。
ソースの多様性のサポート: プラットフォームは、リレーショナルデータベース、クラウドアプリケーション、API、ファイルベースのストレージなど、現在および将来予想されるすべてのソースに接続しますか?必要なデータサービスをサポートしているかどうかを検討してください。接続性のギャップがあると、データ仮想化が約束する統一されたアクセスを損なう回避策が必要になります。
セキュリティ機能: 行レベルおよび列レベルのセキュリティ、マスキング、暗号化、包括的な監査ログを探してください。これらの機能は、ユーザーが仮想化されたデータにどのようにアクセスするかに関係なく、一貫して適用される必要があります。
セルフサービス機能: ビジネスユーザーは、すべてのリクエストに対してIT部��門の介入なしに、仮想化されたデータを発見してアクセスできますか?新しいクエリーごとに管理者の関与が必要な場合、データ仮想化の価値は低下します。
これら3つに加えて、クエリーのパフォーマンス要件、デプロイメントモデルの好み、総所有コストを考慮してください。
クロスリンク: データ統合とセマンティックレイヤー機能のためのLakeFlow
結論: データ仮想化を選択すべきとき
データ仮想化は、リアルタイムの運用アナリティクス、多様なソースの定期的な調査、概念実証開発、およびクエリーのパフォーマンスよりもデータの鮮度が重要なシナリオで優れています。データ仮想化は、組織が複雑なパイプラインなしで複数のソースからデータにアクセスできるようにしますが、従来のwarehouseを介したアプローチは、複雑な変換、履歴トレンド、大量のバッチ処理、およびレイテンシーが重要な分析ワークロードにおいて依然として優れています。
問題は、どちらか一方のアプローチを排他的に選択することではなく、包括的なアーキテクチャの中でそれぞれがどこに適合するかということです。組織は、アジャイルなアクセスと実験のためのデータ仮想化と、ワークロードの特性がそれを要求する物理的な統合という、両方のテクノロジーをますます導入しています。「最初に仮想化し、後で移行する」パターンにより、チームはフェデレーションクエリーを通じてすぐに価値を提供できると同時に、実際の使用状況データを使用して、どのソースがDelta Lakeや他のレイクハウスストレージへの物理的な移行の投資を正当化するかを優先順位付けできます。
ま��ず、分散データへのリアルタイム アクセスが明確なビジネス価値を生み出すユースケースを特定することから始めます。そこでデータ仮想化を試験的に導入し、結果を測定し、実証された成功に基づいて拡大します。
クロスリンク: ETLとELTの意思決定フレームワーク
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。