データレイク入門
データレイクは、完全かつ信頼性の高いデータストアを提供し、データ分析、BI、機械学習を促進させます。

データレイク入門
データレイクとは?
データレイクとは、膨大な量のデータを集約し、未加工のネイティブな形式で��格納するレポジトリです。ファイルやフォルダ内にデータを格納する階層型データウェアハウスと比較して、データレイクはフラットなアーキテクチャとオブジェクトストレージでデータを格納します。データをメタデータタグと一意の識別子で格納するオブジェクトストレージにより、リージョン間でのデータの検索と取得は容易で、性能を向上させます。安価なオブジェクトストレージとオープンフォーマットを活用し、データレイクは、多くのアプリケーションにおけるデータ活用を可能にします。
データレイクは、データウェアハウスの制限に対処するために開発されました。データウェアハウスは、ビジネスにおける高性能かつスケーラブルな分析を可能にしますが、高価で独自仕様であることから、ほとんどの企業が対応しようとしている最新のユースケースを処理できません。ほとんどの組織では、データを一元的な場所に集約して格納することを目的にデータレイクを使用しています。データウェアハウスのようにスキーマ(データがどのように構成されるかの正式な構造)を事前に設定しなくても、データレイクではデータを「そのまま」格納できます。リファイメント処理のどの段階にあってもデータレイクにデータを格納し、取り込んだ未加工データを、組織の構造化されたデータベーステーブルなどの表形式のデータソースと一緒に格納することも、リファインメント処理の過程で生成される中間のデータテーブルと一緒に格納することも可能です。一般的なデータベースやデータウェアハウスとは異なり、データレイクは、あらゆる種類のデータを扱えます。これには、現在の�機械学習と高度な分析のユースケースには欠かすことができない、画像、動画、音声、文書などの非構造化や半構造化データが含まれます。
データレイクのメリット
データレイクはオープンフォーマットを採用できるため、ユーザーはデータウェアハウスのように独自システムにロックインされることはありません。これは、現代のデータアーキテクチャにおいてますます重要視されている課題です。また、データレイクは、オブジェクトストレージを拡張して活用できるため、高耐久性、低コストのメリットがあります。現在の企業において、非構造化データを高度な分析と機械学習に利活用することは最も戦略的な優先事項の 1 つです。さまざまな形式(構造化、非構造化、半構造化)で未加工データを取り込む独自の機能と、これまでに挙げた他のメリットにより、データレイクはデータストレージの明確な選択肢となります。
データレイクが適切に設計されている場合、次のことが可能になります。

データサイエンスと機械学習の強化
データレイクを活用することで、未加工データを SQL分析、データサイエンス、機械学習に対応した構造化データに低レイテンシで変換できます。未加工データを低コストで無期限に格納できるため、将来の機械学習や分析でそのデータを使用できます。

データの一元化、統合、カタログ化
一元化されたデータレイクにより、データサイロに起因する問題(データの重複、複数のセキュリティポリシー、コラボレーションが困難など)が解消されます。ダウンストリームのユーザーは、あらゆるデータが集約された単一の場所にアクセスしてデータを探索できるようになります。

多様なデー��タソースとフォーマットを迅速かつシームレスに統合
バッチ、ストリーミングデータ、動画、画像、バイナリファイルなど、あらゆるデータタイプを無期限でデータレイクに格納できます。データレイクは新しいデータのランディングゾーンを提供するため、常に最新の状態に保たれています。

セルフサービスツールの提供によりデータを民主化
データレイクは柔軟性に優れており、異なるスキルを持ち、さまざまなツール、言語を使用するユーザーがそれぞれの分析タスクを同時に実行できます。
データレイクにおける課題
データレイクには多くのメリットがある一方で、トランザクションのサポートやデータ品質の保証がなく、ガバナンスの実施や性能が最適化されていないなど、重要な機能が欠けています。データレイクは、これらの理由から本来の目的の達成には至っておらず、データスワンプ(活用できないデータが大量に溜まっている沼のような状態)となっているのが実情です。
信頼性の欠如
適切なツールがないと、データレイクのデータは信頼性に問題があり、データサイエンティストやアナリストはそのデータを推論に使用できない可能性があります。これはバッチデータとストリーミングデータの結合の複雑さ、データの破損、その他の要因に起因しています。
低速
データレイク内のデータ量が増大すると、従来のクエリエンジンの性能が低速になります。メタデータ管理、不適切なデ�ータパーティショニングなどがボトルネックの要因となっていました。
セキュリティ機能の不足
データレイクには、可視化や削除・更新機能がなく、適切なセキュリティやガバナンスの確保が困難です。このような制限により、規制要件を満たすことが極めて困難になっています。
このような理由から、従来のデータレイクだけでは、変革を目指す企業の要件を満たすことができません。そのため、企業では、データウェアハウス、データベース、その他のストレージシステムなど、さまざまなストレージシステムを扱い、複雑なアーキテクチャで運用しているのが実情です。機械学習とデータ分析を活用して今後 10 年の成功を目指す企業にとっては、データレイクに格納されたあらゆるデータを統合し、アーキテクチャを簡素化することが最初のステップになります。
レイクハウスによる課題解決
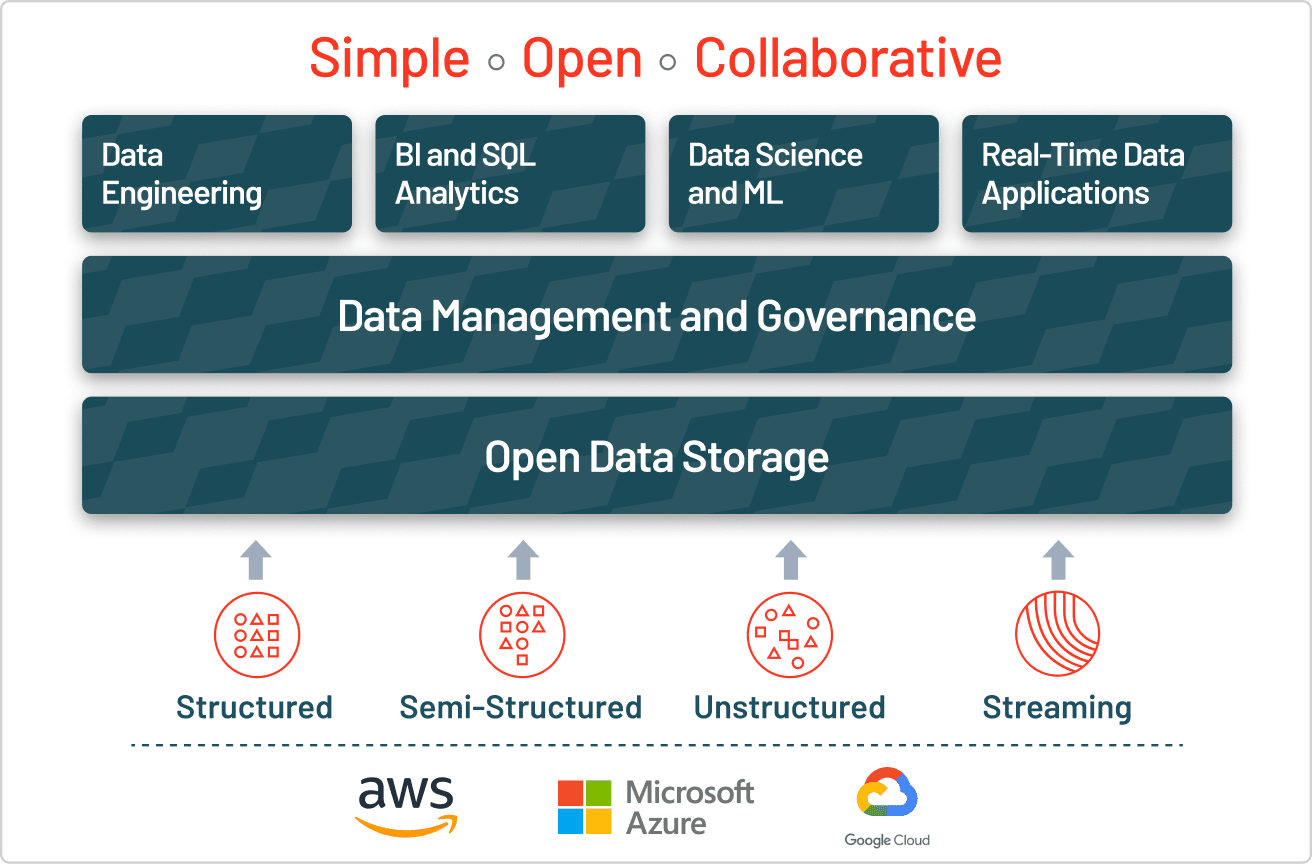
データレイクの課題を解決するのは、データレイク上にトランザクションストレージレイヤーを追加するレイクハウスです。レイクハウスは、データウェアハウスと類似のデータ構造とデータ管理機能を使用しますが、その機能をクラウドデータレイク上で直接実行します。レイクハウスは、従来の分析、データサイエンス、機械学習を同一のシステムにオープンフォーマットで統合します。
レイクハウスは、さまざまな部門を横断した企業規模の分析、BI、機械学習プロジェクトにおける幅広いユースケースの新たな展開を可能にし、膨大なビジネス価値を引き出します。データアナリストは、データレイクのデータを SQL を使用してクエリし、効果的な知見を抽出できます。データサイエンティストは、データセットを統合、強化して、これまでにない正確度の高い機械学習モデルを生成できるようになります。データエンジニアは、自動 ETL パイプラインの構築、BI アナリストは、視覚的なダッシュボードとレポートツールの迅速かつ容易な作成が可能になります。これらのユースケースは、新たなデータをストリーミングしているときでも、データをリフトや移動させることなく、データレイク上で同時に実行できます。
Delta Lake でレイクハウスを構築
効果的なレイクハウスを構築するために、各企業が注目しているのが Delta Lake です。Delta Lake は、データレイクとデータウェアハウスの両方の利点を兼ね備えた、オープンフォーマットのデータ管理およびガバナンスレイヤーです。業界を問わず、企業では、Delta Lake の信頼性の高い単一のデータソースを活用して、コラボレーションを強化しています。また、Delta Lake は、ストリーミングとバッチ処理の両方においてデータレイクに品質、信頼性、セキュリティ、性能をもたらします。データのサイロが解消され、企業のさまざまな事業部が分析にアクセスできるようになります。Delta Lake を使用することで、データサイロを排除し、エンドユーザーによるセルフサービス型の分析を可能にするコスト効率と拡張性に優れたレイクハウスを構築できます。
データレイク、データレイクハウス、データウェアハウス(DWH)の比較
| データレイク | レイクハウス | DWH | |
|---|---|---|---|
| データのタイプ | 全てのタイプ:構造化/半構造化/非構造化(生)データ | 全てのタイプ:構造化/半構造化/非構造化(生)データ | 構造化データのみ |
| コスト | $ | $ | $$$ |
| フォーマット | オープン | オープン | クローズド、独自 |
| スケーラビリティ | あらゆるタイプ/量のデータを低コストでスケール | あらゆるタイプ/量のデータを低コストでスケール | ベンダーコストが爆発的に増大 |
| ユーザー | データサイエンティスト(限定) | あらゆるタイプのユーザー(統合型) | データアナリスト(限定) |
| 信頼性 | 低品質、データスワンプ | データスワンプからの脱却 | データスワンプからの脱却 |
| 使いやすさ | 膨大な量の未加工データの探索に��は、データの整理・カタログ化のためのツールが必要(使いにくい) | データレイクの広範なユースケースで、DWH のシンプルさと構造を提供(使いやすい) | DWH の構造により、レポートや分析のためのデータに迅速かつ容易にアクセス可能(使いやすい) |
| 性能 | 低 | 高 | 高 |
レイクハウスのベストプラクティス
あらゆるデータのランディングゾーンとしてデータレイクを使用
機械学習やデータリネージに使用するために、データの変換や集計は行わず、あらゆるデータをデータレイクに格納しておくことができます。
個人情報を含むデータを匿名化してデータレイクに格納
GDPR に準拠し、データを無期限に保存できるようにするには、個人を特定できる情報 (PII) を匿名化する必要があります。
役割ベース、ビューベースのアクセス制御でデータレイクを保護
ビューベースのACL(アクセス制御レベル)が追加され、役割ベースの制御のみではできなかった、データレイクのセキュリティの緻密な調整、制御が可能になります。
Delta Lake がデータレイクの信頼性と性能を向上
ビッグデータの性質上、データベースと同レベルの信頼性と性能をデータレイクで提供することは困難とされていましたが、Delta Lake はそれを可能にする機能をデータレイクにもたらします。
データレイクのデータをカタログ化
データの取り込みの時点で、データカタログとメタデータ管理ツールを使用し、セルフサービスでのデータサイエンスと分析を可能にします。