特徴エンジニアリングとは何ですか?
選択、抽出、構築、変換のテクニックを通じて、生デー��タを ML モデルに役立つ特徴に変換する
によって Databricks Staff による投稿
- 選択:相関分析、相互情報量、再帰的特徴除去、またはドメイン専門知識を用いて、利用可能なデータから最も関連性の高い変数を特定し、冗長、無関係、またはノイズの多い特徴を除去します。
- 抽出:次元削減(PCA、t-SNE)、テキストベクトル化(TF-IDF、単語埋め込み)、または自動特徴学習(ディープラーニング表現)を用いて、既存の特徴から新しい特徴を導出します。
- 構築:比率、��集計、相互作用、ビニング、多項式特徴、時間的特徴(ローリングウィンドウ、ラグ)などのドメイン知識を用いて変数を組み合わせることで、複雑な関係性を捉えるエンジニアリング特徴を作成します。
機械学習のための特徴量エンジニアリング
特徴量エンジニアリングは、未加工データを機械学習モデルの開発に利用可能な特徴量に変換するプロセスで、データ前処理とも呼ばれています。ここでは、特徴量エンジニアリングの主要な概念と、MLのライフサイクル管理における役割について説明します。
機械学習における特徴量とは、モデルのトレーニングに使用される入力データのことです。これらは、モデルが学習するエンティティの属性です。未加工データは通常、ML モデルの入力として使用する前に処理する必要があります。優れた特徴量エンジニアリングは、モデル開発のプロセスを効率化し、よりシンプルで柔軟性の高い、より正確なモデルを実現します。
特徴量エンジニアリング
特徴量エンジニアリングとは、機械学習アルゴリズムの性能を向上させるためにデータを変換して強化するプロセスです。そのデータはモデルを学習に使用されます。
特徴量エンジニアリングには、データのスケーリングや正規化、数値以外のデータ(テキストや画像など)のエンコード、時間やエンティティによるデータの集約、さまざまなソースからのデータの結合、他のモデルからの知識の転送などのステップが含まれます。これらの変換の目的は、機械学習アルゴリズムがデータセットから学習す�る能力を高めることで、より正確な予測を行うことです。
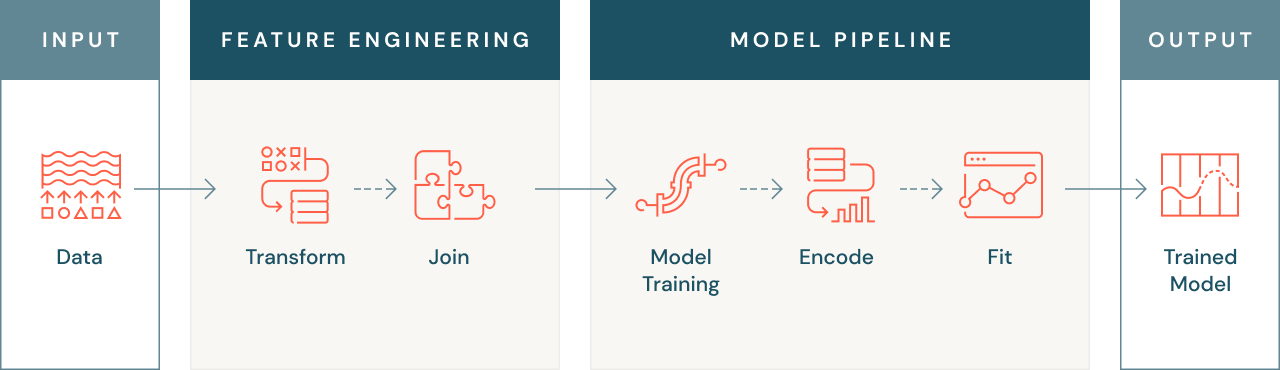
特徴量エンジニアリングが重要な理由
特徴量エンジニアリングが重要だと考えられているのにはいくつかの理由があります。まず、前述したように、機械学習モデルは未加工データを処理できない場合があるため、モデルが理解できる数値形式にデータを変換する必要があります。これには、テキストや画像データの数値への変換や、顧客の平均取引額などの集計結果の作成が含まれます。
機械学習の問題に関連する特徴量は、複数のデータソースにまたがって存在することがあります。効果的な特徴量エンジニアリングでは、これらのデータソースを結合して、単一で、利用可能なデータセットを作成します。これにより、利用可能な全てのデータを使用してモデルを学習させることができ、精度や性能を向上させることができます。
また、他には、転移学習と呼ばれるプロセスを使用して、他のモデルの出力と学習を新しい問題の特徴量として再利用することができます。これにより、以前のモデルで得た知識を活用して、新しいモデルの性能を向上させることができます。転移学習は、ゼロからモデルをトレーニングすることが現実的でない大規模で複雑なデータセットを扱う場合に特に有用です。
また、効果的な特徴量エンジニアリングにより、モデルを使用して新しいデータを予測する推論時に、信頼性の高い特徴量を実現で��きます。推論時に使用される特徴量はトレーニング時に使用される特徴量と一致する必要があるため、これは重要です。予測時に使用する特徴量がトレーニング時に使用する特徴量と異なって計算される「オンライン/オフラインの歪み」を回避できます。
特徴量エンジニアリングとその他のデータ変換の違い
特徴量エンジニアリングの目的は、機械学習モデルを構築するためにトレーニングできるデータセットを生成することです。データ変換に使用されるツールや手法の多くは、特徴量エンジニアリングにも使用されます。
特徴量エンジニアリングはモデルの開発に重点を置いているため、全ての特徴量変換に当てはまるわけではない要件がいくつかあります。例えば、複数のモデルや組織内のチーム間で特徴量を再利用したい場合があります。そのためには、特徴量を発見するための堅牢な手法が必要です。
また、特徴量が再利用されるようになると、特徴量がどこでどのように計算されたかを追跡する方法が必要になります。これを特徴量リネージと呼びます。特徴量の計算の再現性は、機械学習において特に重要です。特徴量はモデルのトレーニングのために計算する必要があるだけでなく、モデルを推論に使用する際にも全く同じ方法で再計算する必要があります。
効果的な特徴量エンジニアリングのメリットとは
効果的な特徴量エンジニアリングのパイプラインを持つことは、より堅牢なモデリングパイプラインを意味し、最終的にはモデルの信頼性と、性能の向上につながります。トレーニングと推論の両方に使用される特徴量を改善することは、モデルの品質に大�きな影響を与え、モデルの向上につながります。
また、別の観点では、効果的な特徴量エンジニアリングは再利用を促進し、実務者の時間を節約するだけでなく、モデルの品質も向上させます。特徴量の再利用は 2 つの理由で重要です。1 つは、時間の節約になることです。もう 1 つは、堅牢な特徴量を定義することで、モデルが一致した特徴量データをトレーニングと推論の間で使用することができ、「オンライン/オフライン」のずれを回避できます。
エンタープライズ向けエージェントAIプレイブック

特徴量エンジニアリングに必要なツール
一般に、データエンジニアリングに使用されるツールと同じものを特徴量エンジニアリングにも使用できます。これは、ほとんどの変換が両者に共通しているためです。これには、データストレージと管理システム、標準のオープン変換言語(SQL、Python、 Spark など)へのアクセス、変換を実行するための何らかのコンピューティングへのアクセスが必要です。
ただし、テキストや画像の埋め込み、カテゴリ変数のワンホットエンコーディングなど、機械学習に特化したデータに役立つ特定の Pythonライブラリの形で、特徴量エンジニアリングのために実装できる追加ツールがいくつかあります。また、モデルが使用する特徴量の追跡に役立つオープンソースプロジェクトもいくつかあります。
データのバージョニングは、特徴量エンジニアリングにとって重要なツールです。多くの場合、変更されたデータセットでモデルをトレーニングすることができます。データのバージョニングを適切に行うことで、時間の経過とともにデータが自然に進化しても、特定のモデルを再現できます。
特徴量ストアとは
特徴量ストアは、特徴量エンジニアリングの課題を解決するために設計されたツールです。特徴量ストアは、組織全体の特徴量を一元管理するリポジトリです。データサイエンティストは、特徴量ストアを使用して、特徴量を発見、共有し、特徴量の系統を追跡できます。また、特徴量ストアは、トレーニング時と推論時に同じ特徴量を使用することを保証します。特徴量の計算の再現性は、機械学習において特に重要です。特徴量はモデルのトレーニングのために計算する必要があるだけでなく、モデルを推論に使用する際にも全く同じ方法で再計算する必要があります。
Databricks Feature Store を選ぶ理由
Databricks Feature Store は、Databricks の他のコンポー�ネントと完全に統合されています。Databricks Notebook を利用して、特徴量を生成するためのコードを開発し、その特徴量に基づいたモデルを構築することができます。Databricks を利用してモデルにサービスを提供すると、モデルは特徴量ストアから自動的に特徴量を検索して推論します。Databricks Feature Store は、特徴量ストアがもつ主要なメリットをすべて備えています。
- 発見性:Databricks ワークスペースからアクセスできる Feature Store UI では、既存の特徴量を参照および検索できます。
- リネージ:Databricks Feature Store で特徴量テーブルを作成すると、特徴量テーブルの作成に使用されたデータソースが保存され、アクセスできるようになります。特徴量テーブルの各特徴量について、その特徴量を使用するモデル、 Notebook、ジョブ、エンドポイントにアクセスすることも可能です。
Databricks Feature Store には次のような追加の特長があります。
- モデルのスコアリングやサービングとの統合:Databricks Feature Store の特徴量を使用してモデルをトレーニングする場合、モデルは特徴量メタデータと一緒にパッケージ化されます。モデルをバッチスコアリングまたはオンライン推論に使用すると、Databricks Feature Store から自動的に特徴量が取得されます。推論側はこれらの特徴量の存在を意識する必要がなく、特徴量を検索または結合して新しいデータをスコアリングするロジックを組み込む必要もありません。これにより、モデルのデプロイメントや更新が容易になります。
- ポイントインタイムのルックアップ:Databricks Feature Store は、特定の時点��での正確性を必要とする時系列およびイベントベースのユースケースをサポートします。
FAQ
1. 特徴量エンジニアリングはなぜ重要なの?
モデルが理解できる形にデータを整え、学習精度・再現性・安定性を高めるためです。
2. Databricks Feature Store を使う利点は?
特徴量の管理・再利用・リネージ追跡が容易になり、学習と推論で同じ特徴量を自動的に参照できます。
3. training–serving skew とは何?
学習時と推論時で特徴量が異なる計算方法で作られ、モデル精度が低下する問題のことです。
関連資料
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。