Hadoop エコシステムとは何ですか?
HDFS、MapReduce、YARN、Hive、Spark などの包括的なオープンソース ツール スイートが連携して、大規模なデータセットを保存、処理、分析します。
によって Databricks Staff による投稿
- HDFSはNameNodeとDataNodeアーキテクチャを用いたフォールトトレラントな分散ストレージを提供し、YARNはクラスタリソースを管理し、MapReduceは並列データ処理を担います。
- Apache Hiveは、データウェアハウス操作のためのHiveQLを介したSQLライクなクエリ機能を提供し、Apache Sparkはリアルタイム分析と機械学習のためのインメモリ処理を提供します。
- エコシステムには、スクリプト作成用のPig、NoSQLストレージ用のHBase、ワークフロースケジューリング用のOozie、Hadoopとリレーショナルデータベース間のデータ転送用のSqoopといった補完的なツールが含まれています。
Hadoop エコシステムとは
Apache Hadoop エコシステムとは、Apache Hadoop ソフトウェアライブラリのさまざまなコンポーネントを指します。オープンソースプロジェクトだけでなく、補足ツールの全てが含まれます。Hadoop エコシステムの最もよく知られているツールには、HDFS、Hive、Pig、YARN、MapReduce、Spark、HBase Oozie、Sqoop、Zookeeper、などがあります。開発者が頻繁に使用する主要な Hadoop エコシステムコンポーネントは次のとおりです。
HDFS とは
Hadoop 分散ファイルシステム(HDFS)は、代表的なApacheプロジェクトと Hadoop のプ�ライマリストレージシステムの 1 つで、ネームノードとデータノードのアーキテクチャを採用しています。コモディティハードウェアのクラスタ上で実行されている大きなファイルを格納できる分散ファイルシステムです。
Hive とは
Hive は、Hadoop エコシステム内に格納されている大規模なデータセットをクエリまたは分析するために使用される、ETL およびデータウェアハウスツールです。Hive には、Hadoop の非構造化データと半構造化データの要約、クエリ、分析という3つの主要な機能があります。SQL に似たインターフェースである HQL 言語を備えており、SQL と同様に動作し、クエリを MapReduce ジョブに自動的に変換します。
Apache Pig とは
Pig は、Hadoop 内で使用される大規模なデータセットのクエリを実行するために使用される、高レベルスクリプト言語です。PigはSQLに似た簡潔なスクリプト言語は Pig Latin と呼ばれ、その主な目的は、必要な演算を実行し、最終的な出力を目的の形式で準備することです。
エンタープライズ向けエージェントAIプレイブック

MapReduce とは
 MapReduce は、Hadoop の別のデータ処理層です。大規模な構造化データと非構造化データを処理する機能を備えている他、ジョブを独立したタスク (サブジョブ) のセットに分割して、非常に大きなデータファイルを並行して管理できます。
MapReduce は、Hadoop の別のデータ処理層です。大規模な構造化データと非構造化データを処理する機能を備えている他、ジョブを独立したタスク (サブジョブ) のセットに分割して、非常に大きなデータファイルを並行して管理できます。
YARN とは
YARN は、Yet Another source Navigator の頭字語をとった略語です。リソース管理に適したオープンソース Apache Hadoop のコアコンポーネントの 1 つであり、ワークロードの管理、監視、およびセキュリティ制御の実装を担当します。また、Hadoop クラスタで実行されているさまざまなアプリケーションにシステムリソースを割り当てると同時に、各クラスタノードで実行するタスクを割り当てます。YARN には、2 つの主要なコンポーネントがあります。
- リソースマネージャー
- ノードマネージャー
Apache Spark とは
Apache Spark は、さまざまな状況での使用に適した、高速なメモリ内データ処理エンジンです。Spark は、いくつかの方法で展開することができ、Java、Python、Scala、R のプログラミング言語を備え、SQL、ストリーミングデータ、機械学習、およびグラフ処理をサポートしている��ため、これらをアプリケーション内で一緒に使用できます。 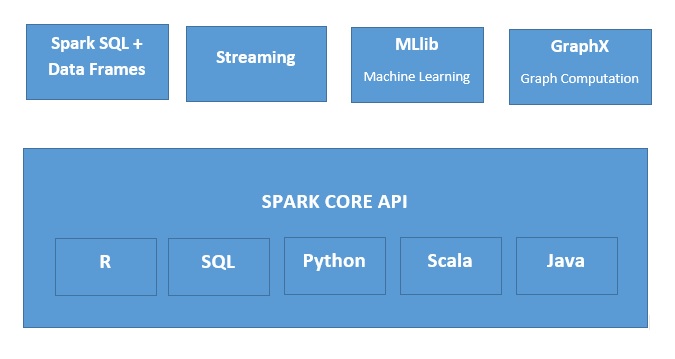
FAQ
Hadoopエコシステムとは何ですか?
Hadoopと関連するオープンソースツール群の総称で、大規模データの保存、処理、分析を可能にします。
HiveとPigの違いは何ですか?
HiveはSQLライクなHQLでデータウェアハウス的分析を行い、PigはPig Latinを用いた柔軟なデータ処理に適しています。
SparkはMapReduceとどう違いますか?
Sparkはインメモリ処理により高速で、多様な言語と機械学習・グラフ処理もサポートする点でMapReduceより柔軟です。
関連資料
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。