機械学習モデルとは何ですか?
線形回帰や決定木からディープニューラルネットワークまで、トレーニングデータからパターンを学習して予測を行うアルゴリズム
によって Databricks Staff による投稿
- 学習プロセスでは、勾配降下法、バックプロパゲーション、正則化などの手法を用いて、ラベル付きデータを内部パラメータ(重み、係数)を調整するアルゴリズムに入力し、検証セットにおける予測誤差を最小化します。
- モデルの種類は、教師あり学習(分類、回帰)、教師なし学習(クラスタリング、次元削減)、強化学習、半教師ありアプローチなど多岐にわたり、それぞれ異なる問題構造とデータの可用性に適しています。
- 評価指標には、分類では精度、適合率、再現率、F1スコア、AUC-ROC、回帰ではMSE、MAE、R²、クラスタリングではシルエットスコア、Davies-Bouldin指数などがあり、モデル選択とハイパーパラメータ調整に役立ちます。
機械学習モデルとは
機械学習モデルとは、未知のデータセットからパターンを発見したり、判断を導き出すプログラムのことです。例えば、自然言語処理では、機械学習モデルにより、これまで聞き取れなかった文章や単語の組み合わせの背後にある意図を解析し、正しく認識できます。また、画像認識では、機械学習モデルを学習させることで、車や犬などのオブジェクトを認識できます。機械学習モデルは、大規模なデータセットを用いて「トレーニング」することで、上述のようなタスクの実行が可能になります。トレーニングでは、機械学習アルゴリズムは、タスクに応じてデータセットから特定のパターンや出力を見つけるように最適化されます。このプロセス��の出力(多くの場合、特定のルールとデータ構造を持つコンピュータプログラム)は、機械学習モデルと呼ばれます。
機械学習アルゴリズム
機械学習アルゴリズムとは、データセットからパターンを見つけるための数学的手法です。Machine Learningアルゴリズムは、統計学、微積分学、線形代数学から導き出されることがよくあります。機械学習アルゴリズムの一般的な例として、線形回帰、決定木、ランダムフォレスト、XGBoostなどがあります。
機械学習におけるモデルのトレーニング
データセット(トレーニングデータ)で機械学習アルゴリズムを実行し、特定のパターンや出力を検出するようにアルゴリズムを最適化するプロセスは、モデルトレーニングと呼ばれます。こうして得られた、ルールとデータ構造を持つ関数を、学習済み機械学習モデルと呼びます。
機械学習の種類
機械学習の手法は主に、教師あり学習、教師なし学習、強化学習に分類されます。
教師あり学習
教師あり学習では、アルゴリズムは提供されたインプットデータセットに対して特定のアウトプットのセットを満たすように正解を与えられ、最適化されます。例えば、画像認識には、教師あり学習の分類と呼ばれる手法が広く用いられています。また、人口増加や健康状態などの人口統計の予測には、教師あり学習の回帰と呼ばれる手法が利用されています。
教師なし学習
教師なし学習では、アルゴリズムは入力データセットを提供されますが、特定のアウトプットに対する正解は与えられず、共通の特性によってデータセット内のオブジェクトをグループ化するようにトレーニン�グされます。例えば、オンラインショップの推薦エンジンには、教師なし学習のクラスタリングと呼ばれる手法が用いられています。
強化学習
強化学習では、アルゴリズムは多くの試行錯誤を繰り返しながら、自らトレーニングを行います。強化学習は、アルゴリズムがトレーニングデータに依存するのではなく、環境と継続的に相互作用することで実現されます。強化学習の代表的な例として、自律走行が挙げられます。
機械学習モデルの種類
機械学習モデルは数多く存在しますが、そのほとんどが特定の機械学習アルゴリズムに基づくものです。一般的な分類アルゴリズムと回帰アルゴリズムは教師あり学習に該当し、クラスタリングアルゴリズムは教師なし学習のシナリオで利用されます。
教師あり学習
- ロジスティック回帰:ロジスティック回帰は、ある入力が特定のグループに属しているかどうかを判断するために使用されます。
- サポートベクターマシン(SVM):サポートベクターマシンは、n 次元空間における各オブジェクトの座標を作成し、超平面を用いて共通の特徴によってオブジェクトをグループ化します。
- ナイーブベイズ:ナイーブベイズは、変数間の独立性を仮定し、確率を用いて特徴量から対象を分類するアルゴリズムです。
- 決定木:決定木は、ツリー状に枝分かれした節(ノード)を走査することにより、入力がどのカテゴリーに分類されるかを判断する分類器として利用されます。
- 線形回帰:線��形回帰は、対象となる変数と入力の関係を識別し、入力変数の値に基づいてその値を予測するために使用されます。
- k 近傍法(k-NN):k 近傍法は、データセット内の最も近いオブジェクトをグループ化し、オブジェクト間の最頻値または平均的な特性を見つける手法です。
- ランダムフォレスト:ランダムフォレストは、ランダムなデータのサブセットから多数の決定木を集めたもので、結果的に、単一の決定木よりも予測精度が高くなる可能性があります。
- ブースティングアルゴリズム:Gradient Boosting Machine、XGBoost、LightGBM などのブースティングアルゴリズムは、アンサンブル学習を用いています。以前のアルゴリズムとの誤差を考慮しながら、決定木などの複数のアルゴリズムの予測を組み合わせます。
教師なし学習
- k 平均法(k-means):K 平均法アルゴリズムは、オブジェクト間の類似性を見つけ、それらを k 個の異なるクラスタにグループ化します。
- 階層型クラスタリング:階層型クラスタリングは、クラスタが入れ子状になったツリーを構築します。クラスタ数の指定は必要ありません。
機械学習における決定木
決定木は、機械学習における予測手法の 1 つで、オブジェクトがどのクラスに属するかを示すものです。特定の条件を用いてオブジェクトのクラスを段階的に決定する、ツリー状のフローチャートです。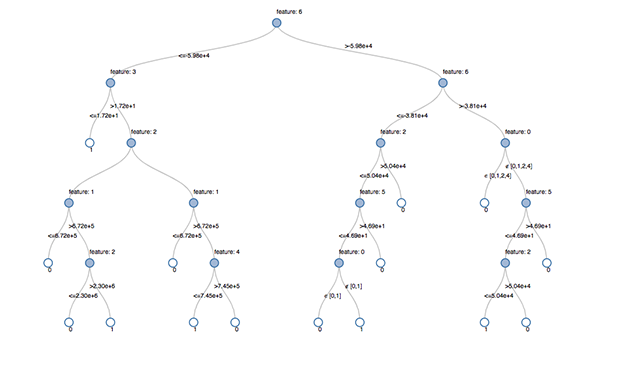 Databricks のレイクハウスで可視化された決定木
Databricks のレイクハウスで可視化された決定木
出典:ブログ「機械学習モデル、決定木(ディシジョンツリー)による分析を活用した金融詐欺検知の大規模展開」
エンタープライズ向けエージェントAIプレイブック

機械学習における回帰
データサイエンスや機械学習における回帰は、入力変数のセットに基づいて結果を予測できる統計的手法です。結果として得られる値は、多くの場合、入力変数の組み合わせに依存します。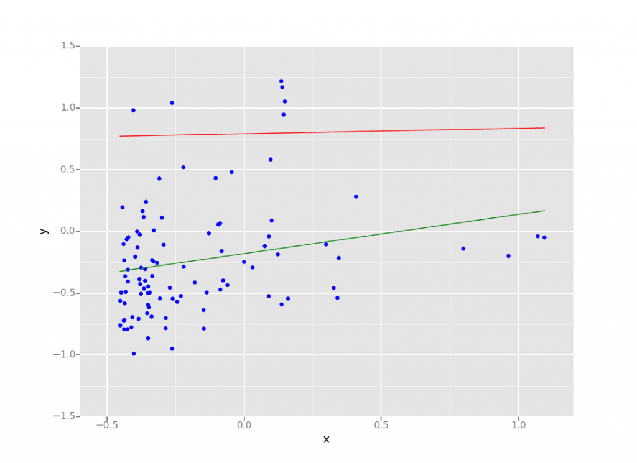 Databricks のレイクハウスで実行された線形回帰モデル
Databricks のレイクハウスで実行された線形回帰モデル
出典:ブログ「Databricks の Apache Spark で機械学習を簡素化 」
機械学習における分類器
分類器とは、あるカテゴリーやグループの 1 つとしてオブジェクトを割り当てる機械学習アルゴリズムです。例えば、スパムメールや不正取引の検知に分類器が使われています。
機械学習におけるモデル数
機械学習のモデルは、数多く存在します。機械学習は進化している分野であり、常に多くの機械学習モデルが開発されています。
機械学習に最適なモデル
特定の状況に最も適した機械学習モデルは、期待する結果によって異なります。例えば、ある都市の自動車購入台数を過去のデータから予測する場合、線形回帰のような教師あり学習が最も有効であると考えられます。一方、その都市に住む潜在的な顧客が、収入や通勤の履歴から自動車を購入するかどうかを特定するには、決定木が最も効果的かもしれません。
機械学習におけるモデルのデプロイメント
モデルのデプロイメントとは、機械学習モデルをテスト環境または本番環境で使用できるようにするプロセスを指します。機械学習モデルは、通常、API を通じて環境内にあるデータベースや UI などの他のアプリケーションと統合されています。デプロイメントを経て、組織はモデル開発への多大な投資に対し、実際に利益を得られるようになります。Databricks のレイクハウスにおける機械学習モデルのライフサイクルの全容
出典:ブログ「機械学習の本番化:デプロイからドリフト��検出まで」
深層学習モデル
深層学習モデルは、人間が情報を処理する方法を模倣した機械学習モデルの一種です。このモデルは、提供されたデータからハイレベルな特徴を抽出するために、多数の処理層で構成されています。これが「深層」と呼ばれる所以です。各処理層は、より抽象的なデータ表現を次の層に伝え、最終層はより人間に近い知見を導き出します。データのラベリングが必要な従来の機械学習モデルとは異なり、ディープラーニングモデルは大量の非構造化データを取り込むことができます。顔認識や自然言語処理といった、より人間らしい機能を実行するために使用されます。 深層学習の簡略図
深層学習の簡略図
出典:AI と深層学習の民主化
時系列機械学習
時系列機械学習モデルとは、独立変数に連続した時間の長さ(分、日、年など)を含み、従属変数または予測変数に関係するモデルです。時系列機械学習モデルは、翌週の天気、翌月の予想顧客数、翌年の収益ガイダンスといった時間的制限のある事象を予測するために使用されます。
機械学習についての詳細情報
- eBook「機械学習ユースケースのビッグブック」では、世界中の企業で展開されている魅力的な機械学習のユースケースを数多くご紹介しています。
- 機械学習のエキスパートによるブログは、こちらからご覧いただけます。
関連リソース
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。