Apache Spark とは何ですか?
バッチ、ストリーミング、ML、グラフ用の Java、Scala、Python、R の API を備えた大規模分散データ処理用の統合分析エンジン
によって Databricks Staff による投�稿
- 耐障害性に優れた分散データセット(RDD)を基盤とし、遅延評価によるフォールトトレラントなインメモリ並列処理を実現。反復ワークロードにおいてHadoop MapReduceと比較して10~100倍の高速化を実現します。
- クエリプランニングのためのCatalystオプティマイザーとメモリ管理のためのTungsten実行エンジンを備えたDataFrame APIを提供し、SQLクエリと構造化データ処理をサポートします。
- 分散機械学習用のMLlib、リアルタイム処理用のStructured Streaming、グラフ分析用のGraphXを搭載。これらはすべて同じ実行フレームワークを共有しています。
Apache Spark とは
Apache Spark は、ビッグデータのワークロードに使用するオープンソースの分析エンジンです。リアルタイム分析とデータ処理のワークロードに加えて、両方のバッチ処理が可能です。Apache Spark は 2009 年にカリフォルニア大学バークレー校の研究プロジェクトとして開発されました。それまで研究者は、Hadoop システムでのジョブ処理を高速化する方法を模索していました。Apache Spark は Hadoop MapReduce をベースとして、MapReduce モデルを拡張し、対話型クエリやストリーム処理など、より多くのタイプの計算に効率的に使用できるようになっています。プログラミング言語の Java、Scala、Python、R でバインディングをネイティブ機能として実装しています。さらに、機械学習(MLlib)、ストリーム処理(Spark Streaming)、グラフ処理(GraphX)用のアプリケーション構築を支援するライブラリもいくつか備えています。Apache SparkはSpark Coreと複数のライブラリから構成されます。Spark Coreは分散実行、スケジューリング、I/Oを担う中核コンポーネントです。また、Spark Core のエンジンは基本的なデータタイプである Resilient Distributed Dataset(RDD)という抽象データ構造を用い、分散処理の複雑さをユーザーから隠蔽しています。Spark はデータ処理の方法に優れています。データとパーティションはサーバークラスタ全体で集約され、次に計算が行われて別のデータストアへ移動するか、分析モデルを使用して実行します。ファイルを保存・取得するために必要なファイルや計算リソースの保存先の指定は不要です�。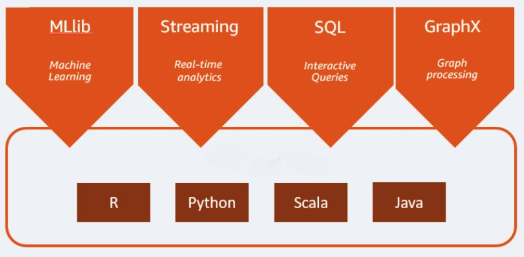
Apache Spark を使用するメリット
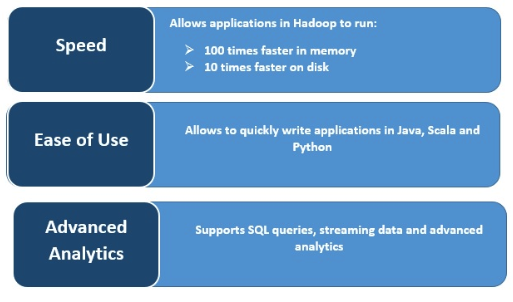
スピード
Spark では、複数の並列処理中にメモリにデータをキャッシュするため、動作が非常に高速です。Spark の主な特徴は、処理速度を高めるインメモリエンジンです。インメモリ処理での大規模なデータ処理に関しては、MapReduce と比較して最大 100 倍、ディスクでは 10 倍高速になります。Spark は、ディスク操作への読み取り/書き込み回数を減らすことによってこれを可能にします。
リアルタイムのストリーム処理
Apache Spark は、他のフレームワークの統合に加えて、リアルタイムのストリーミング処理を実行できます、Spark はミニバッチ単位でデータを取り込み、そのミニバッチのデータに対してRDD変換を行います。
複数のワークロードをサポート
Apache Spark は、対話型クエリ、リアルタイム分析、機械学習、グラフ処理など複数のワークロードを実行できます。複数のワークロードは、単一のアプリケーションにシームレスに統合可能です。
操作性の向上
複数のプログラミング言語をサポートする機能により、操作が動的になります。Java、Scala、Python、R でアプリケーションを迅速に記述することができ、アプリケーション構築のための多様な言語を提供します。
高度なアナリティクス
Spark は SQL クエリ、機械学習、ストリーム処理、グラフ処理をサポートしています。
エンタープライズ向けエージェントAIプレイブック

FAQ
1. Apache Sparkが高速な理由は何ですか?
データをメモリ上にキャッシュし、ディスクI/Oを最小限に抑えるインメモリ処理を採用しているためです。
2. Sparkはどのような処理に対応していますか?
バッチ処理、ストリーム処理、対話型SQL、機械学習、グラフ処理など幅広い分析処理に対応します。
3. Sparkで利用できるプログラミング言語は何ですか?
Java、Scala、Python、Rをネイティブにサポートしています。
関連資料
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。