Spark Streaming とは何ですか?
Spark StreamingがDStreamsを使用してリアルタイムデータのマイクロバッチを処理する方法と、構造化ストリーミングが現在推奨されるエンジンである理由
によって Databricks Staff による投稿
- Apache Spark Streamingとは何か、それがコアSpark APIをどのように拡張するのか、そしてなぜStructured Streamingに代わってレガシーストリーミングエンジンと見なされているのかを理解しましょう。
- Spark StreamingがKafka、Flume、Amazon Kinesisなどのソースからデータを取り込み、マイクロバッチで処理し、DStreamsを使用して結果をファイル、データベース、ダッシュボードにプッシュする方法をご覧ください。
- Spark Streamingがもたらす主なメリット(バッチ処理とストリーミング処理の統合、フォールトトレランス、MLlibおよびSpark SQLとの統合など)を探ります。
Apache Spark ストリーミングは、Apache Spark の前世代ストリーミングエンジンです。Sparkストリーミングは現在メンテナンス対象外となっており、レガシー技術として位置付けられています。Apache Spark には、「構造化ストリーミング」と呼ばれる新しくて使いやすいストリーミングエンジンがあります。ストリーミングアプリケーションとパイプラインには、SQL 自動生成と最適化を標準で活用できるSpark 構造化ストリーミングの利用が推奨されます。構造化ストリーミングの詳細はこちらでご覧いただけます。
Sparkストリーミングとは
Apache Sparkストリーミングとは、スケーラブルで耐障害性に優れた特性を持つストリーミング処理システムです。バッチ処理とストリーミング処理のワークロードをネイティブにサポートしています。Spark ストリーミングは、コアのSpark APIを拡張したもので、データエンジニアやデータサイエンティストは、KafkaやFlume、Amazon Kinesisなどの複数のソースからリアルタイムデータを処理することが可能です。処理されたデータは、ファイルシステムやデータベース、ライブダッシュボードに出力することができます。その中核となる抽象化が、小さなバッチに分割されたデータストリームを表す「離散ストリーム(DStream)」です。DStreamは、Sparkのコアなデータ抽象化機能であるRDD を基盤に構築されています。これにより、SparkストリーミングはMLlibやSpark SQLのような他のSparkコンポーネントとシームレスに統合することが可能となります。Sparkストリーミ��ングは、ストリーミングのためだけに設計された処理エンジンを備えているシステムや、Sparkストリーミングと類似したバッチとストリーミングAPIを持ちながら、内部的には異なるエンジンにコンパイルされるシステムとは異なります。Sparkの単一実行エンジンと、バッチとストリーミング処理のための統合プログラミングモデルは、従来のストリーミングシステムにはない利点をもたらします。
Spark ストリーミングの4つの特徴
- 障害時における迅速なリカバリ
- 優れた負荷分散とリソース使用率
- ストリーミングデータと静的データセット、対話型クエリの統合
- 高度な処理ライブラリ(SQL、機械学習、グラフ処理)とのネイティブ統合
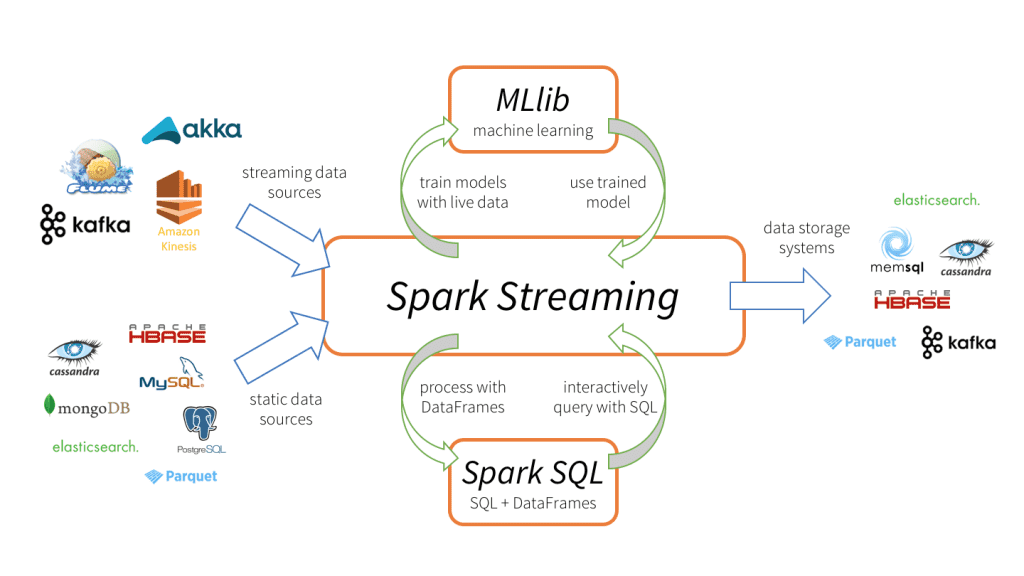 このような異なるデータ処理機能の統合は、Sparkストリーミングを急速に普及させる大きな理由になりました。この統合により、開発者は単一のフレームワークを使用して、容易にあらゆる処理ニーズに対応できます。
このような異なるデータ処理機能の統合は、Sparkストリーミングを急速に普及させる大きな理由になりました。この統合により、開発者は単一のフレームワークを使用して、容易にあらゆる処理ニーズに対応できます。
エンタープライズ向けエージェントAIプレイブック

FAQ
1. Sparkストリーミングとは何ですか?
Apache Sparkの旧来型ストリーミングエンジンで、リアルタイムデータを小さなバッチに分割して処理します。Spark SQLと連携でき、初期のSQL 自動生成による分析基盤として利用されてきました。
2. SparkストリーミングではSQL 自動生成は可能ですか?
DStream自体は低レベルAPIですが、Spark SQLと組み合わせることで、集計や分析クエリをSQL 自動生成に近い形で扱うことが可能でした。
3. 現在はどの技術が推奨されていますか?
Sparkストリーミングはレガシー技術のため、DataFrame/DatasetベースでSQL 自動生成と最適化を活用できる「構造化ストリーミング」への移行が推奨されています。
関連資料
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。