Lakeflow Spark Declarative Pipelinesを使用して本番ETLを構築します
現代の分析とAIのワークロードに対応するように設計されたこのリファレンスアーキテクチャは、バッチとストリーミングデータを跨いで抽出、変換、ロード(ETL)パイプラインを構築し、自動化するための堅牢でスケーラブルな基盤を提供します。
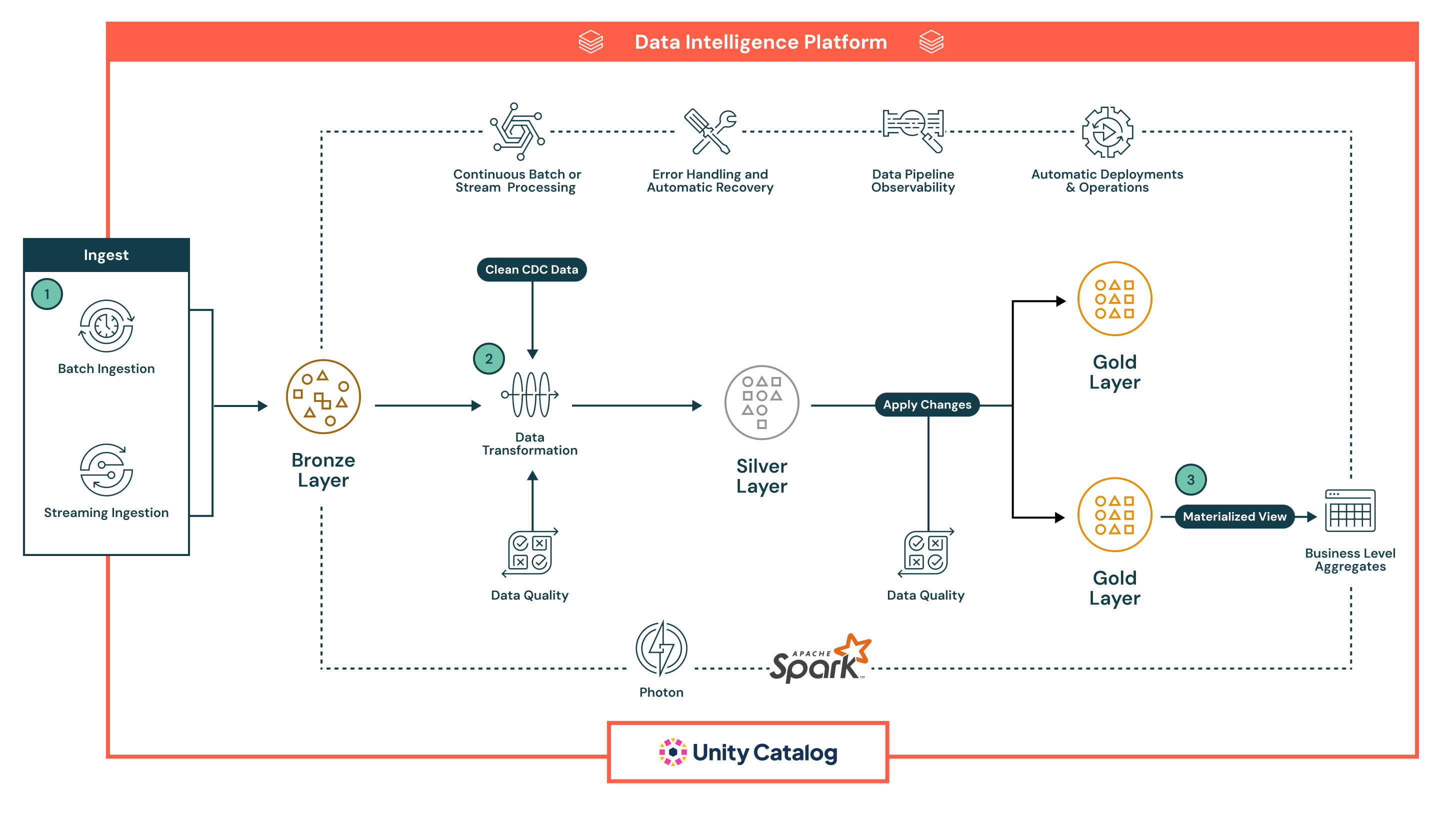
アーキテクチャの概要
このリファレンスアーキテクチャは、バッチとストリーミングのパイプラインを一つの宣言的フレームワークで統一し、データの信頼性、品質、ガバナンスを各段階で確保したい組織に適しています。これは、Databricks Data Intelligence Platformを活用してパイプライン管理を簡素化し、データの期待値を強制し、組み込みの観測性と自動化でリアルタイムの洞察を提供します。
データの取り込みと変換からリアルタイムの品質チェック、ビジネスロジック、自動回復を含む複雑なワークフローまで、幅広いデータエンジニアリングと分析のシナリオをサポートします。このアーキテクチャを採用する組織は、しばしばレガシーETLを近代化し、運用上のオーバーヘッドを削減し、ビジネスインテリジェンス、機械学習、運用アプリケーションのためのキュレーションされた高品質なデータの提供を加速させることを目指しています。
技術ユースケース
- このアーキテクチャは、ソースシステムからの更新をインクリメンタルに適用する変更データキャプチャ(CDC)パイプラインを可能にします。
- データエンジニアは、分析レイヤーで次元モデルを管理するためのゆっくりと変化する次元(SCD)パターンを構築することができます。
- ストリーミングパイプラインは、ウォーターマークとチェックポイントを使用して、順不同のイベントと遅延データを耐性を持って処理することができます
- データエンジニアは、宣言的な制約を使用してスキーマの進化と自動化された品質ルールを強制することができます
- データエンジニアは、手動の計測なしでパイプライン全体のデータライニージの追跡と監査ログを自動化できます
ビジネスユースケース
- 小売業者や消費者パッケージ製品(CPG)企業は、このアーキテクチャを使用して、複数のチャネルでの販売、在庫、顧客行動を追跡するリアルタイムダッシュボードを構築することができます
- 金融機関は、取引、デジタルインタラクション、CRMシステムからのデータを統合することで、詐欺検出と顧客セグメンテーションをサポートできます
- 医療機関は、医療機器のデータと患者記録を処理し、正規化して、臨床的な洞察とコンプライアンス報告を提供できます
- メーカーは、IoTセンサーデータと過去のログを組み合わせて、予測保守と供給チェーンの最適化を推進できます
- 通信プロバイダーは、CRMとネットワークテレメトリーデータを統合して、ほぼリアルタイムで顧客の離脱と使用パターンをモデル化できます
主な機能
- 宣言的パイプラインの開発: SQLまたはPythonを使用してパイプラインを定義し、オーケストレーションロジックを抽象化します。
- バッチとストリーミングのサポート: リアルタイムとスケジュールされたワークロードを統一されたフレームワークで処理します。
- データ品質の強制: パイプライン内で直接期待値を適用し、不良データを検出、ブロック、または隔離します
- 観測可能性と系統: 組み込みの監視、アラート、視覚的な系統追跡が透明性とトラブルシューティングを改善します
- エラーハンドリングとリカバリ: パイプラインの任意の段階での障害を自動的に検出し、回復します
- Unity Catalogによるガバナンス: 細かいアクセス制御を強制し、データの使用を監査し、スタック全体でデータ分類を維持します。
- 最適化された実行: スパークとフォトンを活用して、スケーラブルで高性能な処理を実現します
- 自動化された操作: パイプラインはバージョン管理され、CI/CDを通じてデプロイおよび管理され、スケジューリングとパラメータ化のサポートがあります。
データフロー
このアーキテクチャは、Lakeflowの宣言的パイプラインの自動化、ガバナンス、信頼性のための組み込み機能を強化した、堅牢で多層的なメダリオンアーキテクチャに従っています。パイプラインの各フェーズは、バッチとストリーミングの両方のユースケースに最適化された宣言的で観察可能です。
- Lakeflowの宣言的パイプラインは、バッチとストリーミングの両方の取り込みをサポートし、データをlakehouseに統一的かつ自動的に取り込む方法を提供します。
- バッチ取り込みは、スケジュールまたはトリガーに基づいてデータをロードし、定期的なETLワークフローに最適です。それはクラウドストレージとデータベースからの完全なロードと増分ロードをサポートしています。伝統的なツールとは異なり、宣言的なものはオーケストレーション、リトライ、スキーマ進化をネイティブに管理し、外部スケジューラーやスクリプトの必要性を減らします。
- ストリーミング取り込みは、Structured Streamingを使用してKafkaやEvent Hubsなどのソースからデータを連続的に処理します。宣言的パイプラインはチェックポイント、状態管理、自動スケーリングを自動的に処理し、ストリーミングパイプラインで通常必要とされる手動設定を排除します。
すべてのデータは最初にブロンズレイヤーに生の形で着地し、完全な系統、トレーサビリティ、安全な再処理を可能にします。パイプラインの宣言的なアプローチ、組み込みの品質チェック、自動インフラストラクチャ処理は、運用の複雑さを大幅に削減し、堅牢で本番環境に適したパイプラインを構築するのを容易にします。これは、ほとんどのレガシーETLツールがネイティブに提供するのに苦労しています。
- 取り込み後、データはシルバーレイヤーで処理され、クリーニング、結合、エンリッチメントが行われ、ダウンストリームの消費に備えます。
- パイプラインは宣言的なSQLまたはPythonを使用して定義され、変換を容易に読み取り、維持、バージョン管理することができます。変換は、スケーラブルで高性能な処理を提供するApache Spark™ with Photonを使用して実行されます。
- データ品質チェックは、期待値を使用してインラインで適用され、チームが検証ルール(例:nullチェック、データ型、範囲制限)を強制することを可能にします。無効なデータは、不良レコードを削除するか、隔離するか、パイプラインを失敗させるように設定することができます。これにより、下流のシステムは信頼できるデータのみを受け取ることが保証されます。
- パイプラインは自動的にジョブ依存性の追跡、タスクのリトライ、エラーの隔離を処理し、運用上のオーバーヘッドを削減します。これにより、シルバーレイヤーで処理されたデータが正確で一貫性があり、プロダクションレディーであることを保証しつつ、運用の簡素化を維持します。
- ゴールドレイヤーでは、パイプラインが消費の準備ができたビジネスレベルの集計とキュレーションされたデータセットを生成します。
- これらの出力は、BIダッシュボード、機械学習の特徴、運用システムの使用に最適化されています。
- 宣言的パイプラインは、時間的なテーブルとSCDロジックをサポートし、歴史的な追跡や監査報告などの高度なユースケースを可能にします。
- すべてのレイヤーを通じて、宣言的パイプラインは豊富な観察可能性とパイプラインの系譜を提供します。
- UIはデータフローグラフ、運用メトリクス、品質ダッシュボードを表示し、迅速なトラブルシューティングとコンプライアンスレポートのサポートを提供します。
- Unity Catalogの統合により、すべてのテーブル、列、変換が集中的なアクセス制御、監査ログ、データ分類を通じて管理されます。
- パイプラインは設計時から本番環境で使用可能です。
- チームは、バージョン管理された定義を使用してDeclarative Pipelinesをデプロイし、Lakeflow Jobsを介してスケジュールし、GitHub ActionsやAzure DevOpsのようなCI/CDツールを通じて管理することができます。
- この自動化は、壊れやすいスクリプトと複雑なオーケストレーションの設定を置き換え、データチームがインフラストラクチャではなくビジネスロジックに集中するのを助けます。



