クレジットロス予測のためのリファレンスアーキテクチャ
Databricks Data Intelligence Platformを使用してローンポートフォリオ、経済シナリオ、リスクモデルを統合し、スケーラブルで透明性があり、監査可能でコスト効率の良いCECLとストレステストを実現します。
動画の内容
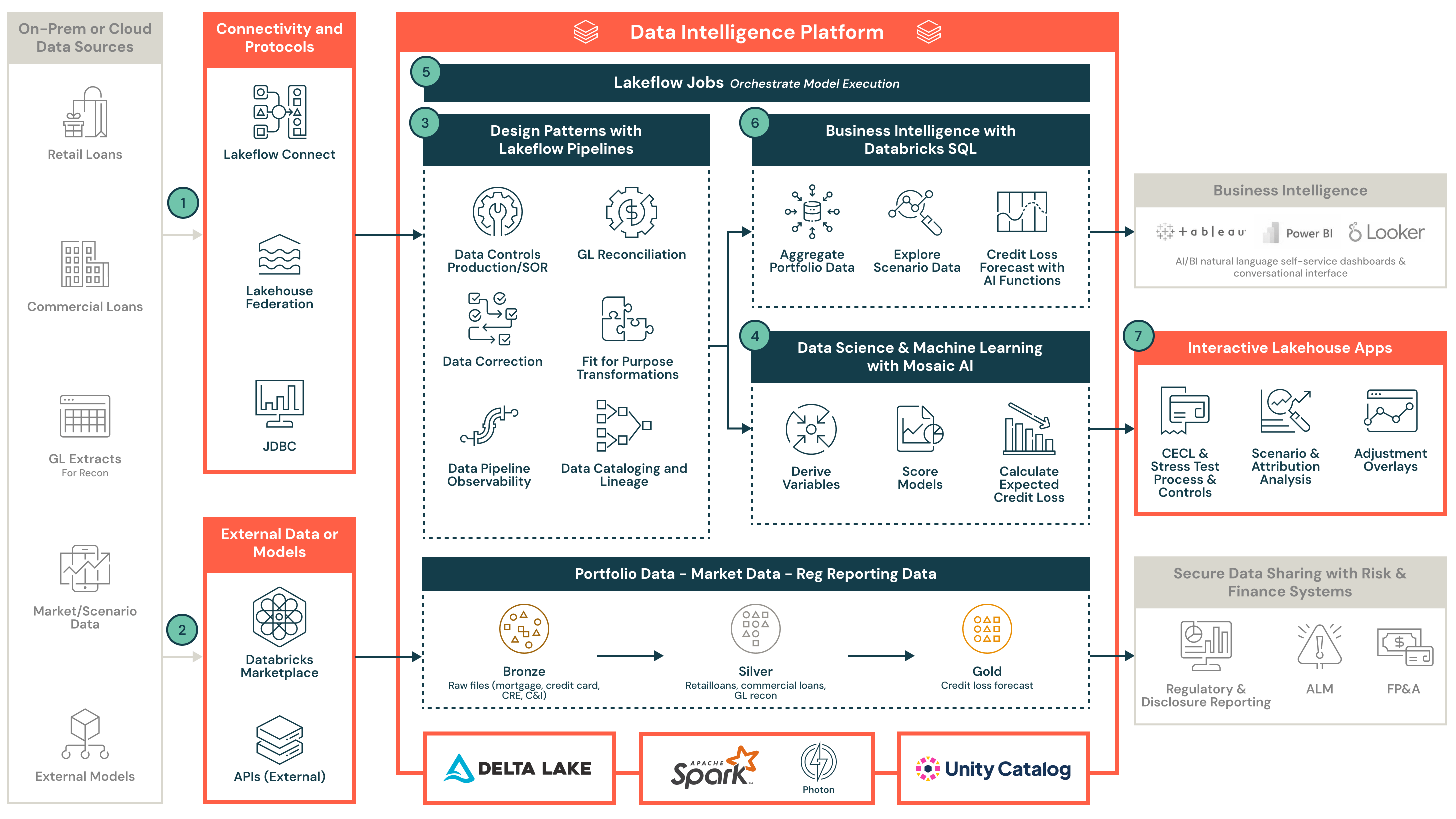
- リテールローン、商業ローン、総勘定元帳(GL)およびマクロ経済シナリオデータを取り込み、統合するためのエンドツーエンドのレイクハウスアーキテクチャ
- Lakehouse FederationとLakeflow Connectがクラウドとオンプレミスシステム間での安全でスケーラブルなデータ統合をどのようにサポートするか
- レイクハウスを使用して、ダウンストリームモデルの実行のためのデータを標準化、調整、品質チェックする方法
- Python、R、SASで構築されたモデルをDatabricksを使用して運用し、Databricks Workflowsを使用してワークフローを調整する方法
- 大規模なCECLとストレステストをサポートするためのスケーラブルな計算レイヤーをDatabricksクラスターを使用して実装
- Unity Catalogを使用してデータの系統、監査可能性、規制遵守を強制する中央集権的なデータとモデルのカタログ、セキュリティモデル、およびコントロール
- Lakehouse Appsがクレジットリスクチームとファイナンスチーム間での安全なコラボレーション、調整、予測の承認を可能にする方法
CECLとストレステストのためのクレジットロス予測を近代化する
- ポートフォリオデータソースと取り込み
- リテールローン、商業ローン、関連するエクスポージャーデータにアクセスし、取り込む
- GLデータを取り込み、口座数や未払い残高を含む、調整とデータの整合性のため
- 使用 Lakeflow Connect オンプレミスまたはクラウドデータシステムからのネイティブな、CDCベースの取り込み、またはLakehouse Federation を活用して安全でスケーラブルな、重複のないデータアクセスを実現
- マクロ経済シナリオデータ
- APIを通じて、ムーディーズのシナリオなどのマクロ経済シナリオデータを接続し、取得する
- カスタムシナリオ拡張ロジックを組み込むか、内部シナリオデータセットを直接プラットフォームに取り込む
- データ管理とガバナンス
- ポートフォリオデータ、シナリオデータ、モデル出力、オーバーレイ、開示報告のメタデータガバナンスを一元化するために Unity Catalog を利用します。ライニージトラッキング はデータの信頼性と監査の準備を保証します。
- マルチアセットクラスの統合を可能にし、リテールローンと商業ローンデータを標準化し、行レベルのアクセス制御を提供する
- データ品質チェックとGLの調整を行い、カーテッドシルバーテーブルに入力し、データコントロールに署名します
- 利用 システムテーブル と組み込みの監査トレイルをフル監査可能性と規制基準の遵守のために
- モデルの実行を実装
- Python、R、SASで開発されたモデルを実装またはインポートします。モデルをMLflowに登録します。
- 変数導出、モデルスコアリング、シナリオと時間軸による予想クレジットロス(ECL)計算のロジックを定義
- CECLとストレステストのワークフロー
- ビルド ワークフロー シナリオ分析、感度分析、および帰属分析のための
- Databricks Workflowsを使用して大規模なワークフローを実行し、複雑なモデルパイプラインの自動化、監視、スケジューリングを提供します
- BI
- 使用 Databricks SQL ポートフォリオデータとシナリオデータのレビューと分析のために
- 各シナリオとホライゾンに対するローンレベルのクレジットロス分析を実施します
- 結果を対話的に探索し、完全な透明性とトレーサビリティで仮定を検証します
- クレジットリスクと財務の協力
- クレジットリスクチームと財務チーム間のリアルタイムのコラボレーションを可能にする Lakehouse Apps (ウェブアプリケーション)
- 個々の評価を支援するためのエンドユーザー計算スプレッドシートをアップロード
- 管理オーバーレイと承認コントロールを適用し、GL投稿、開示報告などのための下流リスクおよびファイナンスシステムと統合します
メリット
- 規制遵守と監査可能性
CECL、CCAR、IFRS 9などの規制フレームワークの遵守を確保するために 自動化されたデータの系統、組み込まれたコントロール と 監査対応のワークフローを利用します。 - 複雑な計算のためのスケーラブルなパフォーマンス
オートスケーリングを使用して、Databricksクラスタ を使用して、計算集約的な金融ワークロード向けに設計されたクレジットロスモデルとシナリオを簡単に実行 - コスト効率の良いアーキテクチャ
利用消費ベースの価格モデル 追加のソフトウェアライセンス料金なし — 結果として、低いTCO とあなたの需要に合わせた柔軟なリソース使用 - セキュアでエンタープライズ対応のプラットフォーム
組み込みの セキュリティ、アイデンティティ管理と ガバナンス 機能により、機密性の高いリスクデータがエンタープライズと規制基準に従って保護され、管理されます - フルカスタマイズ可能なセルフサービス
内部チームが自分たちのモデリング環境を所有し、適応させることを可能にします これは、フルカスタマイズ、自動化、エンタープライズシステムとの統合をサポートしながら、セルフサービスプラットフォームを通じて行います
おすすめ

産業アーキテクチャ
金融サービス投資管理参照アーキテクチャ

リファレンスアーキテクチャ
Databricks上のインテリジェントデータウェアハウジング

リファレンスアーキテクチャ
データ取り込み参照アーキテクチャ
産業アーキテクチャ
保険業界向け販売チャネル最適化リファレンスアーキテクチャ

産業アーキテクチャ
保険業界向け引受アナリティクス リファレンスアーキテクチャ

リファレンスアーキテクチャ
Azure Databricksを使用したデータインテリジェンスのエンドツーエンドアーキテクチャ

産業アーキテクチャ
エネルギーグリッド運用参照アーキテクチャ
リファレンスアーキテクチャ
Databricksでのインテリジェントなデータウェアハウジング - クローン