MLflow를 사용하여 Keras 네트워크 모델을 실험하는 방법: 영화 리뷰의 바이너리 분류
즐겨 사용하는 Python IDE에서 MLflow 사용
작성자: Jules Damji
지난 블로그 게시물에서는 머신 러닝 수명 주기를 관리하는 오픈 소스 플랫폼인 MLflow를
쉽게 시작할 수 있는 방법을 설명했습니다. 특히 MLflow 및 PyCharm을 사용하여 간단한
Keras/TensorFlow 모델을 설명했습니다.
이번에는 이진 분류 Keras 네트워크 모델을 살펴봅니다.
MLflow의 추적 APIs사용하여 기준 모델과 실험 모델 간의 실행에서 학습 및 유효성 검사중에
메트릭(정확도 및 손실)을 추적합니다. 이전과 마찬가지로 PyCharm 및 localhost를 사용하여
모든 Experiment실행합니다.
IMDB 영화 리뷰를 위한 이진 분류
이진 분류는 특히 감정 분류의 경우 결과를 두 개의 고유한 클래스로 분류하려는
일반적인 머신 러닝 문제입니다. 이 예에서는 감정을 표현하는 일반적인 단어가 있는지
리뷰의 텍스트 콘텐츠를 검사하여 영화 리뷰를 "긍정적" 또는 "부정적" 리뷰로 분류합니다.
주로 François Chollet의 " Deep Learning with Python" 에서 차용한 Keras 네트워크
예제 코드는 MLFlow 프로젝트 로 구성되고 MLflow 추적 API 를 통합하여,
parameter 메트릭 및 아티팩트를 기록하도록 모듈화 및 수정 되었습니다.
방법론 및 Experiment
인터넷 영화 데이터베이스(IMDB)는 Keras와 함께 패키지로 제공됩니다.
50,000편의 인기 영화 세트로, 교육용 리뷰 25,000개와 검증용 리뷰 25,000개로 나뉘며
"긍정적"과 "부정적" 감정이 고르게 분포되어 있습니다.
이 데이터 세트를 사용하여 모델을 학습하고 유효성을 검사합니다.
간단한 데이터 준비를 통해 이 데이터를 Keras 신경망 모델이 처리할 수 있도록
numpy 배열로 텐서로 변환할 수 있습니다.
(데이터를 읽고 준비하기 위한 코드는 모듈에 있습니다: data_utils_nn.py.)
두 개의 Keras 신경망 모델(기준선 및 실험적)을 만들고 데이터세트에서 학습합니다.
기준 모델은 일정하게 유지되지만 Experiment 결과를 비교하기 위해 서로 다른
튜닝 parameter 및 손실 함수를 제공하여 두 가지 실험 모델을 합니다.
여기서 MLflow의 추적 구성 요소는 무수히 많은 튜닝 parameter 중 모델에서
최상의 메트릭을 생성하는 것을 평가하는 데 큰 도움이 됩니다.
먼저 기준 모델을 살펴보겠습니다.
기준 모델: Keras 신경망 성능
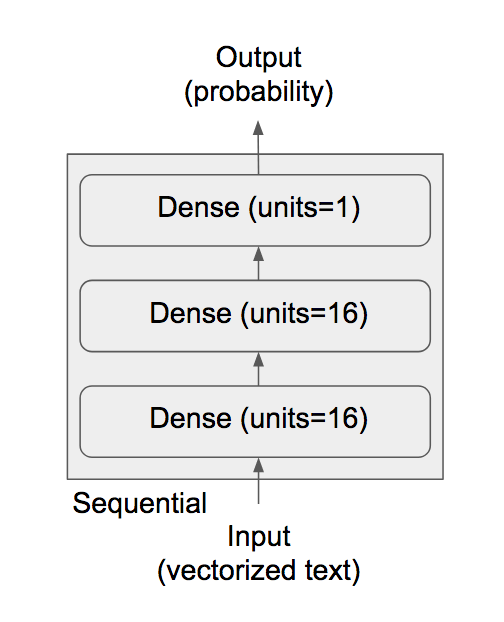
François의 코드 예제는 이진 분류를 위해 이 Keras 네트워크 아키텍처 선택을 사용합니다.
다이어그램에 표시된 대로 숨겨진 레이어 1개(16단위), 입력 계층 1개(16단위) 및
출력 계층 1개(1단위)의 세 가지 조밀한 레이어로 구성됩니다.
"숨겨진 단위는 레이어의 표현 공간에 있는 차원입니다"라고 Chollet은 썼는데,
여기서 16은 이 문제 공간에 적합합니다. 이미지 분류와 같은 복잡한 문제의 경우
항상 단위를 늘리거나 Experiment 에 숨겨진 레이어를 추가하고 정확도 및
손실 메트릭에 미치는 영향을 관찰할 수 있습니다(아래 Experiment 에서 수행).
입력 계층과 은닉 계층은 relu 를 활성화 함수로 사용하는 반면,
최종 출력 계층은 시그모이드를 사용하여 결과를 [0, 1] 사이의 확률로 스쿼시합니다.
1에 가까우면 긍정적이고 0.5보다 작으면 음수를 나타낼 수 있습니다.
이 권장 기준 아키텍처를 사용하여 기본 모델을 학습하고 모든 parameter,
메트릭 및 아티팩트를 기록합니다. 모듈 models_nn.py의 이 스니펫 코드,
위의 다이어그램에 표시된 대로 조밀한 레이어의 스택을 생성합니다.
다음으로, 모델을 구축한 후 적절한 손실 함수와 옵티마이저를 사용하여 모델을 컴파일합니다.
최종 출력으로 확률을 예상하기 때문에 이진 분류에 권장되는 손실 함수는 다음과 같고
해당 제안된 옵티마이저는 다음과 binary_crosstropy 같습니다.
rmsprop. 모듈 train_nn.py 의 코드 조각은 모델을 컴파일합니다.
마지막으로, 각 반복에 대한 IMDB 데이터 세트의 512개 샘플에 대해 default 배치 크기로
반복 또는 epoch를 실행하여 피팅(학습)하고 평가합니다 default parameter
- Epoch = 20
- 손실 = binary_misantropy
- 단위 = 16
- 숨겨진 레이어 = 1
명령줄에서 실행하려면 Git 리포지토리 디렉터리Keras/imdbclassifier 로
cd하고 다음 중 하나를 실행합니다.
Python main_nn.py
또는 GitHub repo 최상위 디렉토리에서 다음을 실행합니다.
mlflow run Keras/imdbclassifier -e main
또는 Gitbub에서 직접 :
mlflow 실행 'https://github.com/dmatrix/jsd-mlflow-examples.git#keras/imdbclassifier'
https://www.youtube.com/watch?v=6oGIwyAlUIM
그림 1: 로컬 호스트에서 기본 모델 parameter 사용한 애니메이션 실행
실행이 끝나면 모델은 모든 반복 후 학습 세트와 검증 세트 모두에 대해 binary_loss, binary_accuracy, validation_loss 및 validation_accuracy 와 같은 최종 메트릭 세트를 인쇄합니다.
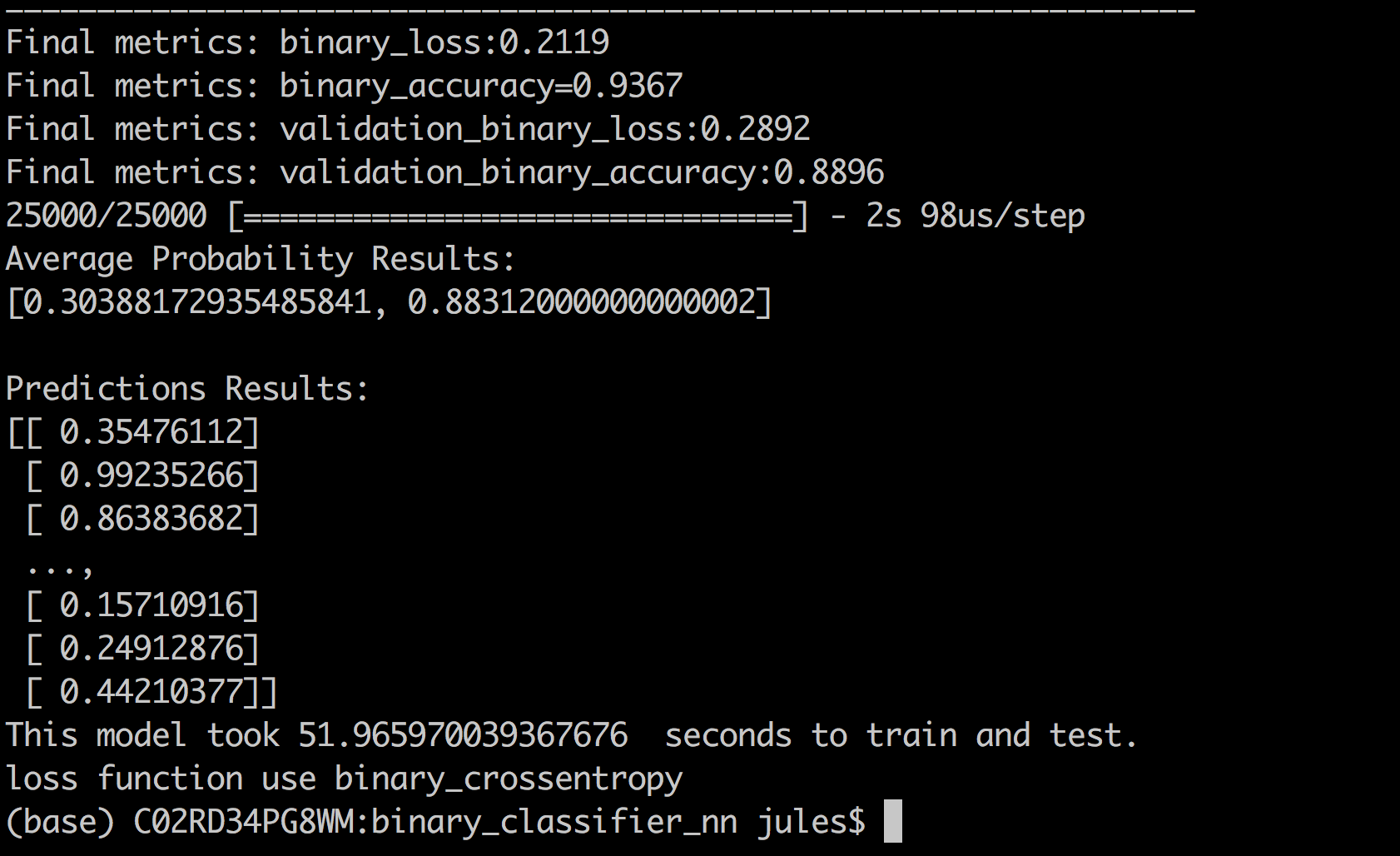
실행에서 알 수 있듯이 반복에 따라 손실이 감소하는 반면
정확도는 증가하며, 전자는 0으로, 후자는 1로 수렴합니다.
최종 학습 데이터(binary_loss)는 0.211로,
검증 데이터(validation_loss)는 0.29로 수렴했으며,
이는 binary_loss와 다소 비슷하게 추적되었습니다.
반면에, 정확도는 여러 epoch 후에 달라졌는데,
이는 훈련 데이터에 과적합될 수 있음을 시사합니다(아래 플롯 참조).
(참고: 이러한 플롯에 액세스하려면 MLFlow UI를 시작하고 실험 실행을
클릭한 다음 아티팩트 폴더에 액세스하십시오.)
보이지 않는 IMDB 리뷰로 예측했을 때 예측 결과의 평균 정확도는 0.88로
검증 정확도에 가깝지만 여전히 상당히 멀었습니다.
그러나 보시다시피 일부 리뷰의 경우 네트워크는
긍정적인 리뷰의 확률 99%로 결과를 자신 있게 예측했습니다.
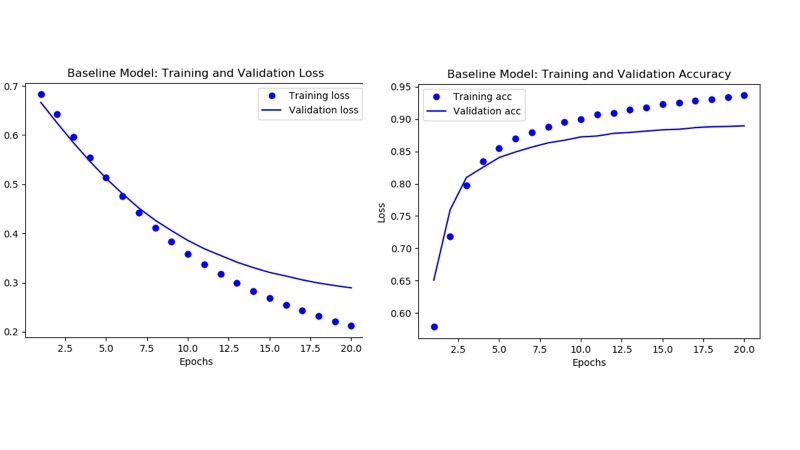
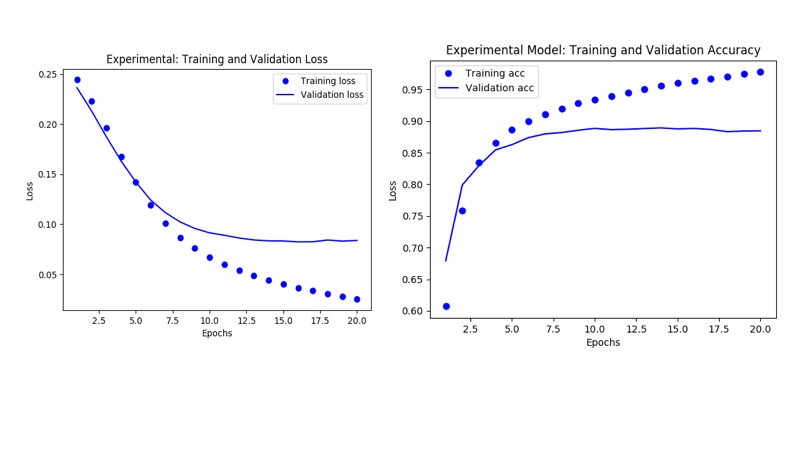
이 시점에서 기본 모델 메트릭을 관찰한 후 더 잘할 수 있는지 물을 수 있습니다.
더 나은 결과에 영향을 미치기 위해 숨겨진 레이어의 수, epoch, 손실 함수 또는
단위와 같은 일부 튜닝 parameter 조정할 수 있습니까?
몇 가지 추천 Experiment시도해 보겠습니다.
실험 모델: Keras 신경망 성능
MLflow의 추적 구성 요소를 사용하면 다양한 parameter 모델의 실험적 실행을 추적하고
분석을 위해 메트릭 및 아티팩트를 유지할 수 있습니다.
Chollet이 제안한 대로 모델과 다른 다음 실험 사용하여
몇 가지 실행을 parameter default 시작하고 결과를 관찰해 보겠습니다.
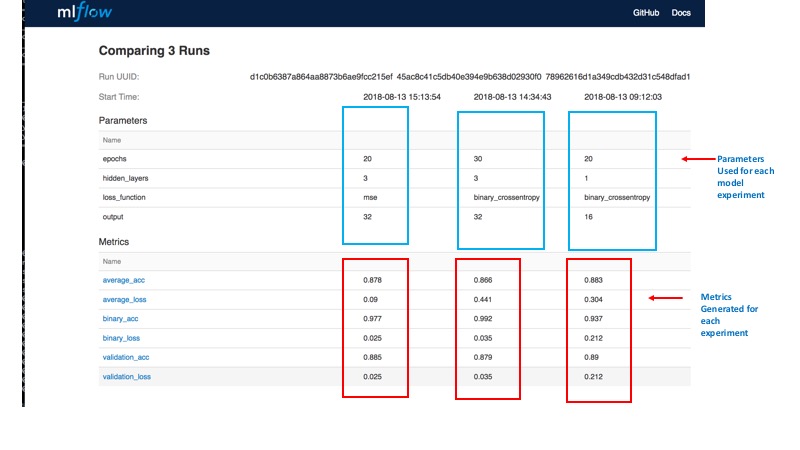
| 모델 | 단위 | 신 기원 | 손실 함수 | 숨겨진 레이어 |
|---|---|---|---|---|
| 기지 | 16 | 20 | binary_crosstropy | 1개 |
| Experiment-1 | 32 | 30 | binary_crosstropy | 3 |
| Experiment-2 | 32 | 20 | 증권 시세 표시기 | 3 |
표 1: 모델 및 parameter
로컬 호스트에서 Experiment 실행
로컬 머신에서 MLflow를 실행하고 있으므로 모든 결과가 로컬로 기록됩니다.
그러나 환경 변수를 MLFLOW_TRACKING_URI 설정하거나
mlflow.set_tracking_uri() 를 사용하여 프로그래밍 방식으로 설정하여
Databricks의 호스팅된 추적 서버에서 원격으로 메트릭을 쉽게 기록할 수 있습니다.
추적 URI에 연결하고 결과를 기록합니다.
두 경우 모두 URI는 원격 서버의 HTTP/HTTPS URI이거나
디렉터리의 로컬 경로일 수 있습니다.
로컬 호스트에서 URI는 default mlruns 디렉토리로 .
MLFlow를 사용하여 PyCharm 내에서 Experiment 실행
필자는 Python 개발에 PyCharm을 선호하기 때문에 랩톱의
PyCharm 내에서 Experiment 실행하여 실험적인 parameter제공합니다.
아래는 첫 번째 Experiment의 애니메이션입니다.
(PyCharm 내에서 MLflow를 사용하는 방법을 알아보려면 이전 블로그를 읽어보세요.)
Experiment 필자는 parameter PyCharm의 실행 구성 내에서 제공하여 실행했지만 Experiment 최상위 디렉터리의 명령줄에서 이러한 쉽게 실행할 수도 있습니다.
https://www.youtube.com/watch?v=Wgt6f6CfpkY
그림 4: Experiment-1 모델 parameter를 사용한 애니메이션 실행
모든 Experiment' 실행이 기록되며, 각 메트릭을 검사하고 다양한 실행을 비교하여 결과를
평가할 수 있습니다. MLflow 추적 API 를 사용하여 이러한 아티팩트를 기록하는 모든 코드는
train_nn.py 모듈에 있습니다. 다음은 부분 코��드 조각입니다.
MLFlow UI와 Experiment 및 결과 비교
이제 가장 좋은 부분입니다. MLflow를 사용하면 세 가지 실행의 메트릭을 모두 비교할 수 있는
MLflow GUI에서 모든 실행 및 기록된 결과를 볼 수 있습니다. MLFlow v0.5.1 의
최근 UI 개선 사항은 실행 비교에 더 나은 환경을 제공합니다.
localhost:5000 에서 Flask 추적 서버를 시작하려면 명령줄 mlflow ui을 사용합니다 .
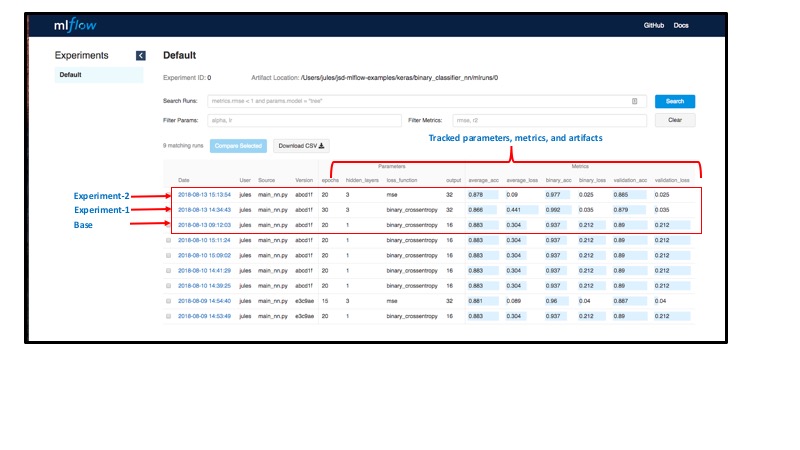
예를 들어, 세 가지 Experiment' 메트릭을 모두 비교하여 허용 가능한 유효성 검사 정확도 및
손실을 생성한 실행을 확인하고 각 Experiment' matplotlib 이미지를 보고 epoch에 걸쳐
어떻게 진행되었는지 확인할 수 있습니다.
https://www.youtube.com/watch?v=89I0Tro8BAQ
그림 6: 실험적 parameter있는 메트릭의 애니메이션 보기
세 실행의 결과 비교
MLFlow UI에서 실행을 빠르게 검사하면 다음을 쉽게 관찰할 수 있습니다.
- Epoch 수를 변경해도 모델이 99%의 훈련 정확도에 도달하면서 과적합이 시작되고
여러 epoch 후에 발산하는 검증 정확도에 해당하는 차이가 없다는 점을 제외하고는
아무런 이점이 없었습니다. - 그러나 손실 함수를
mse, 단위로 32로, 은닉층을 3으로 변경하면 검증 손실이
더 좋아지고 검증 데이터에 대한 average_loss 이 0으로 수렴됩니다.
다른 메트릭이 모델 간에 밀접하게 추적됨에 따라 몇 개의 추가 숨겨진 계층과
더 많은 단위가 유효성 검사 손실을 최소화했습니다.
추가 Experiment모델 메트릭 개선
특히 François Chollet은 추가 교육, 검증 및 테스트(TVT)를 통해 95% 이상의 더 높은
정확도를 달성하고 손실을 0.01%로 수렴할 수 있다고 가정합니다.
이를 달성하는 한 가지 방법은 다음과 같은 머신 러닝 기술을 사용하여
추가 Experiment 하는 것입니다. 더 많은 데이터를 추가하고, 단순 홀드아웃 검증,
k-폴드 검증을 수행하고, 가중치 정규화를 추가하고, 드롭아웃 신경망 계층을 추가하고,
신경망 용량을 늘릴 수 있습니다. 이를 통해 과적합을 최소화하고 일반화를
달성할 수 있으며, 결과적으로 정확도를 높이고 손실을 최소화할 수 있습니다.
여기에서 이러한 기술을 구현하고, 추가 Experiment수행하고,
MLflow를 사용하여 결과를 평가할 수 있습니다.
독자를 위한 연습으로 남겨두겠습니다.
이러한 Experiment 및 반복은 데이터 사이언티스트가 모델을
평가하는 방식의 핵심이므로 MLflow는 이러한 수명 주기 작업을 용이하게 합니다.
이 블로그는 MLflow 기능의 일부를 시연했습니다.
마무리 생각
지금까지 MLflow 추적 구성 요소의 APIs 모델의 무수한 parameter, 메트릭 및 아티팩트를
기록하��여 언제든지 또는 누구나 모델의 MLflow Git 프로젝트 리포지토리에서 결과를
재현할 수 있도록 하는 주요 용도를 보여 주었습니다.
둘째, 명령줄, PyCharm 실행 및 MLFlow UI를 통해 다양한 실행을 비교하여
최상의 메트릭을 조사한 결과, 일부 parameter변경하여 긍정적 또는 부정적 리뷰를
표현하는 일반적인 단어를 기반으로 IMDB 영화 리뷰의 감정 분류를 수행하는데
허용 가능한 정확도로 사용할 수 있는 모델에 접근했음을 관찰했습니다.
앞서 언급했듯이 제안된 머신 러닝 기술을 사용하여 모델의 결과를 더욱 개선할 수 있습니다.
마지막으로, 훨씬 더 중요한 것은 로컬 호스트의 PyCharm 내에서 MLflow를 사용하는
Experiment 있지만 원격 서버에서도 Experiment 쉽게 추적할 수 있다는 것입니다.
PyCharm Python 가상 환경의 일부로 설치된 MLflow, Numpy, Pandas, Keras 및
TensorFlow 패키지를 사용하는 이 체계적인 모델 Experiment 반복은 머신 러닝 모델의
수명 주기에서 중요한 단계입니다. 그리고 MLflow 플랫폼은 즐겨 사용하는
Python IDE 내에서 이 중요한 단계를 용이하게 합니다.
다음 단계
기준 모델을 몇 가지 실험적 모델과 비교하고 MLflow의 장점을 확인했으므로
다음 단계는 무엇일까요? 시작하려면 mlflow.org 에 MLflow를 사용해 보세요.
또는 설명서의 자습서 및 예제 중 일부를 사용해 보세요.
자세히 읽기
다음은 자세히 알아볼 수 있는 몇 가지 리소스입니다.
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.