SHAP와 머신러닝을 사용하여 데이터 편향 감지하기
머신러닝과 SHAP가 개발자 급여와 성별 임금 격차의 관계에 대해 알려주는 것
작성자: 션 오웬
SHAP를 사용하여 데이터 편향 감지 노트북을 사용해 아래에 설명된 단계를 재현하고 온디맨드 웨비나를 시청하여 더 자세히 알아보세요.
StackOverflow의 연례 개발자 설문조사 가 올해 초에 마무리되었으며, 분석을 위해 (익명화된) 2019년 결과를 공개했습니다. 이는 전 세계 소프트웨어 개발자들의 경험을 풍부하게 보여줍니다. 가장 좋아하는 에디터는 무엇일까요? 경력은 얼마나 되나요? 탭인가요, 공백인가요? 그리고 결정적으로, 급여는 어떤가요. 소프트웨어 엔지니어의 급여는 높은 편이며, 때로는 눈이 휘둥그레질 정도로 많아 뉴스거리가 되기도 합니다.
또한 기술 업계는 표방하는 능력주의 이상에 항상 부응하지는 못한다는 점을 뼈저리게 인식하고 있습니다. 급여는 순수하게 능력의 함수가 아니며, 명문 학교, 나이, 인종, 성별과 같은 요인이 급여와 같은 결과에 영향을 미친다는 이야기가 계속해서 들려옵니다.
머신러닝은 예측 이상의 것을 할 수 있을까요? 급여를 설명하고, 이를 통해 이러한 요인들이 바람직하지 않게 임금 격차를 유발할 수 있는 사례를 조명할 수 있을까요? 이 예시에서는 표준 모델을 SHAP(SHapley Additive exPlanations) 으로 보강하여 예측 결과가 우려되는 개별 인스턴스를 탐지하고, 데이터가 해당 예측으로 이어진 구체적인 원인을 더 깊이 파고드는 방법을 간략하게 설명합니다.
모델 편향 또는 데이터 (약) 편향?
이 주제는 종종 "모델 편향" 감지로 특징지어지지만, 모델은 학습에 사용된 데이터를 비추는 거울에 불과합니다. 모델이 '편향'되었다면 데이터의 과거 사실로부터 학습된 것입니다. 모델 자�체가 문제가 아니라 편향의 증거를 찾기 위해 데이터를 분석할 기회입니다.
모델을 설명하는 것은 새로운 것이 아니며, 대부분의 라이브러리는 모델에 대한 입력의 상대적 중요성을 평가할 수 있습니다. 이는 입력의 영향에 대한 집계 뷰입니다. 하지만 일부 머신 러닝 모델의 출력은 '대출이 승인되었는가?'와 같이 매우 개별적인 영향을 미칩니다. 재정 지원을 받게 되나요? 의심스러운 여행객인가요?
실제로 StackOverflow는 자체 설문조사를 기반으로 예상 급여를 추정하는 편리한 계산기를 제공합니다. 전반적으로 예측이 얼마나 정확한지에 대해서는 추측만 할 수 있지만, 개발자가 특히 신경 쓰는 것은 자신의 전망입니다.
올바른 질문은 데이터가 전반적으로 편향을 시사하는지가 아닐 수 있습니다. 오히려 데이터가 개별적인 편향 사례를 보여주는지 여부입니다.
StackOverflow 설문조사 데이터 평가
다행히 2019년 데이터는 데이터 문제가 없는 깨끗한 데이터입니다. 약 88,000명의 개발자가 85개의 질문에 응답한 내용이 포함되어 있습니다.
이 예시는 정규직 개발자에게만 초점을 맞춥니다. 데이터 세트에는 경력, 학력, 직무, 인구 통계학적 정보와 같은 관련 정보가 많이 포함되어 있습니다. 특히 이 데이터 세트에는 보너스와 지분에 대한 정보는 없고 급여만 포함되어 있습니다.
또한 블록체인에 대한 태도, fizz buzz, 설문조사 자체에 대한 광범위한 질문의 답변도 포함되어 있습니다. 이러한 항목은 보상을 결정하는 데 당연히 반영 되어야 할 경험과 기술을 반영할 가능성이 낮으므로 여기에서는 제외됩니다. 마찬가지로 단순화를 위해 미국 기반 개발자에게만 초점을 맞출 것입니다.
모델링 전에 데이터를 약간 더 변환해야 합니다. "개발자로서 생산성에 가장 큰 어려움은 무엇인가요?" 와 같이 여러 질문에 복수 응답이 허용됩니다. 이 단일 질문은 여러 개의 예/아니요 응답을 생성하며 여러 개의 예/아니요 특성으로 분리해야 합니다.
"현재 근무 중인 회사나 조직에 고용된 인원은 몇 명입니까?" 와 같은 일부 객관식 질문은 "2~9명의 직원"과 같은 응답을 제공합니다. 이는 사실상 구간화된 연속형 값이며, 모델이 순서와 상대적인 크기를 고려할 수 있도록 "2"와 같이 추론된 연속형 값으로 다시 매핑하는 것이 유용할 수 있습니다. 안타깝게도 이 변환은 수동으로 이루어지며 약간의 판단이 필요합니다.
관심 있는 분들을 위해, 이를 수행할 수 있는 Apache Spark 코드가 함께 제공되는 노트북에 있습니다.
Apache Spark를 사용한 모델 선택
데이터를 머신러닝에 더 친화적인 형태로 변환한 후, 다음 단계는 이러한 특성으로 급여를 예측하는 회귀 모델을 적합시키는 것입니다. Spark로 필터링하고 변환한 데이터 세트 자체는 4MB에 불과하며, 약 12,600명 개발자의 206개 특성을 포함하고 있어 서버는 물론 손목시계의 DataFrame으로도 메모리에 쉽게 들어갈 수 있습니다.
인기 있는 그래디언트 부스팅 트리 패키지인 xgboost는 Spark 없이 단일 머신에서 몇 분 만�에 이 데이터에 모델을 적합시킬 수 있습니다. xgboost 는 모델 품질에 영향을 미치는 조정 가능한 다양한 "하이퍼파라미터"(최대 깊이, 학습률, 정규화 등)를 제공합니다. 추측하기보다는 이러한 값의 여러 설정을 시도하고 가장 정확한 모델을 만드는 조합을 선택하는 것이 간단한 표준 방식입니다.
다행히도 이 지점에서 Spark가 다시 사용됩니다. 수백 개의 이러한 모델을 병렬로 구축하고 각각의 결과를 수집할 수 있습니다. 데이터 세트가 작기 때문에 Worker에게 브로드캐스트하고, 시도할 하이퍼파라미터의 여러 조합을 만든 다음, Spark를 사용하여 각 조합을 통해 데이터에 로컬로 모델을 빌드할 수 있는 동일한 단순 비분산 `xgboost` 코드를 적용하는 것이 간단합니다.
그러면 많은 모델이 생성됩니다. 결과를 추적하고 평가하기 위해 mlflow 는 각 모델을 메트릭 및 하이퍼파라미터와 함께 log하고 노트북의 Experiment에서 볼 수 있습니다. 여기서는 여러 실행에 걸친 하나의 하이퍼파라미터를 결과 정확도(평균 절대 오차)와 비교합니다.
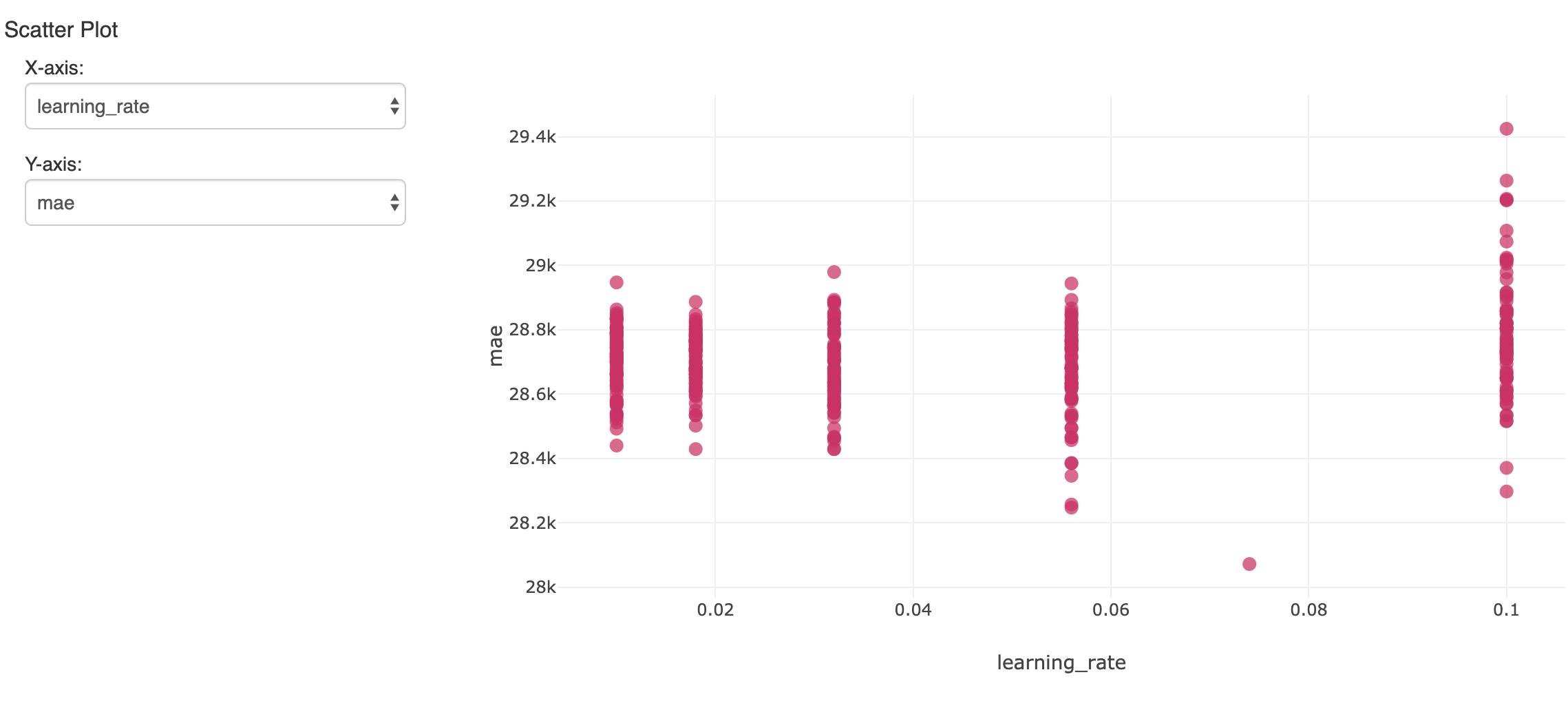
홀드아웃 검증 데이터 세트에서 가장 낮은 오류를 보인 단일 모델이 중요합니다. 평균 약 $119,000의 급여에서 약 $28,000의 평균 절대 오차를 산출했습니다. 나쁘지는 않지만, 모델이 급여 편차의 대부분 만 설명할 수 있다는 점을 인지해야 합니다.
xgboost 모델 해석하기
모델을 사용하여 미래의 급여를 예측할 수도 있지만, 대신 모델이 데이터에 대해 무엇을 말하는지가 문제입니다. 급여를 정확하게 예측할 때 어떤 특성이 가장 중요하게 작용할까요? xgboost 모델 자체는 특성 중요도라는 개념을 계산합니다.
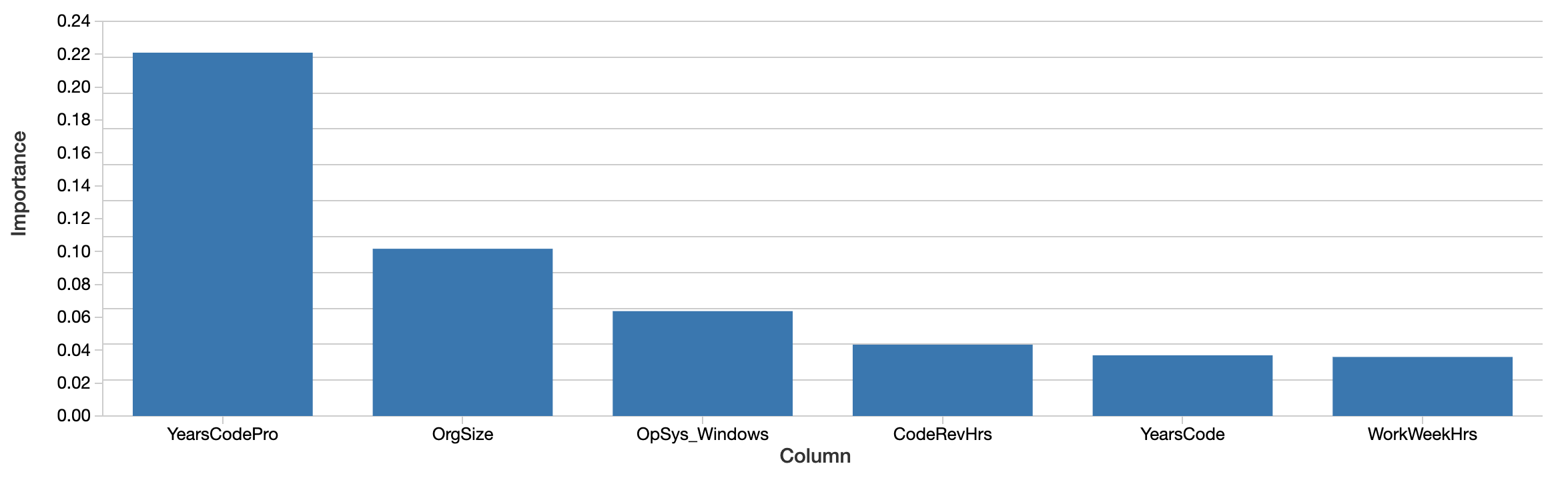
전문적인 코딩 경력, 조직 규모, Windows 사용과 같은 요인이 가장 "중요합니다". 이는 흥미롭지만 해석하기는 어렵습니다. 이 값은 절대적인 중요성이 아닌 상대적인 중요성을 반영합니다. 즉, 효과가 달러로 측정되지 않습니다. 여기서 중요도의 정의(총 이득)는 의사 결정 트리가 구축되는 방식에 따라 결정되므로 직관적으로 해석하기 어렵습니다. 중요한 특성이 반드시 급여와 양의 상관관계를 갖는 것도 아닙니다.
더 중요한 것은, 이것이 종합적으로 특성이 얼마나 중요한지를 보여주는 '전체적인' 관점이라는 점입니다. 성별 및 민족과 같은 요인은 이 목록의 뒷부분에 가서야 나타납니다. 이것이 이러한 요인들이 여전히 중요하지 않다는 것을 의미하지는 않습니다. 한 가지 예로, 특성은 서로 상관관계가 있거나 상호작용할 수 있습니다. 성별과 같은 요인이 트리가 대신 선택한 다른 특성과 상관관계가 있을 수 있으며, 이것이 어느 정도 그 효과를 가릴 수 있습니다.
더 흥미로운 질문은 이러한 요인이 전반적으로 중요한지 여부(평균 효과는 비교적 작을 수 있음)가 아니라, 일부 개별 사례에서 상당한 효과가 있는지 여부입니다. 이러한 경우는 모델이 개인의 경험에 대해 중요한 것을 알려주는 사례이며, 그 개인에게는 바로 그 경험이 중요합니다.
개발자 수준의 설명을 위한 SHAP 패키지 적용
다행히도 지난 5년여 동안 개별 예측 수준에서 이론적으로 더 타당한 모델 해석을 위한 일련의 기술이 등장했습니다. 이는 통칭 "Shapley Additive Explanations"라고 하며, 편리하게도 Python 패키지 shap에 구현되어 있습니다.
어떤 모델이든 이 라이브러리는 해당 모델에서 "SHAP 값"을 계산합니다. 이 값들은 각 값이 예측에 미치는 특성의 영향을 해당 단위로 나타내므로 쉽게 해석할 수 있습니다. 여기서 SHAP 값 1000은 "예측된 급여의 +$1,000를 설명함"을 의미합니다. SHAP 값은 상관 관계와 상호 작용을 분리하는 방식으로도 계산됩니다.
SHAP 값은 모델 전체가 아닌 모든 입력에 대해 계산되므로 이러한 설명은 각 입력에 대해 개별적으로 사용할 수 있습니다. 또한 각 예측에 대해 각 기능의 주요 효과와 별도로 기능 상호 작용의 효과를 추정할 수도 있습니다.
설명 가능한 AI: 전반적인 특성 효과 파악
개발자 수준의 설명은 절댓값을 단순히 평균하여 전체 데이터 세트에서 급여에 미치는 피처의 영향에 대한 설명으로 집계할 수 있습니다. 전반적으로 가장 중요한 피처에 대한 SHAP의 평가는 다음과 같이 유사합니다.
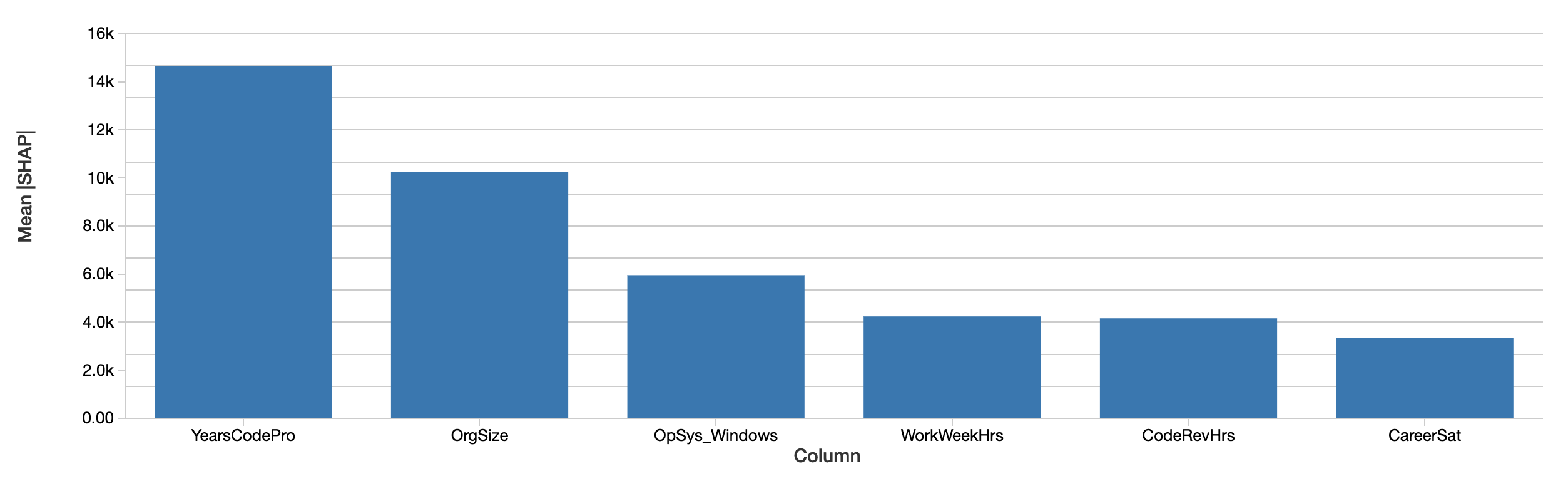
SHAP 값도 비슷한 결과를 보여줍니다. 첫째, SHAP는 급여에 미치는 영향을 달러로 정량화할 수 있어 결과 해석의 질을 크게 높입니다. 위는 예측된 급여에 대한 각 특성의 절대적인 영향을 개발자 전체에 걸쳐 평균을 내어 그린 플롯입니다. 전문 코딩 경력 연수가 여전히 가장 지배적인 요인이며, 급여에 미치는 영향은 평균적으로 거의 $15,000에 달합니다.
SHAP 값으로 성별의 영향 살펴보기
성별, 인종 및 급여 자체를 예측해서는 안 되는 기타 요인의 영향을 구체적으로 살펴보았습니다. 이 예에서는 성별의 영향을 살펴보지만, 이것이 찾아야 할 유일하거나 가장 중요한 편향 유형임을 의미하는 것은 결코 아닙니다.
성별은 이분법적이지 않으며, 설문조사에서는 "남성", "여성", "논바이너리, 젠더퀴어 또는 젠더 비순응" 및 "트랜스" 응답을 별도로 인식합니다. (설문조사에서 성적 지향에 대한 응답도 별도로 기록하지만 여기서는 고려되지 않았습니다.) SHAP는 각각에 대해 예측된 급여에 미치는 영향을 계산합니다. 남성 개발자(남성으로만 식별)의 경우 성별의 영향은 단순히 남성이라는 효과뿐만 아니라 여성, 트랜스젠더 등으로 식별하지 않는 것의 영향도 포함됩니다.
SHAP 값을 사용하면 네 가지 각 범주로 식별되는 개발자에 대한 이러한 효과의 합계를 읽을 수 있습니다.

남성 개발자의 성별은 평균 약 225달러로, 대략 -230달러에서 +890달러 사이의 미미한 영향을 설명하는 반면, 여성의 경우 평균 -1,320달러로, 약 -4,260달러에서 -690달러까지 그 범위가 더 넓습니다. 트랜스젠더 및 논바이너리 개발자의 결과도 비슷하지만 부정적인 영향은 약간 덜합니다.
아래에서 이것이 무엇을 의미하는지 평가할 때 여기에서 사용된 데이터와 모델의 한계를 기억하는 것이 중요합니다.
- 상관관계는 인과관계가 아닙니다. 예측된 급여를 '설명'하는 것은 어떤 특성이 급여를 직접적으로 높거나 낮추는 원인이 되었음을 암시할 뿐, 증명하지는 않습니다.
- 모델이 완벽하게 정확하지는 않습니다.
- 이는 단 1년 치의 데이터이며 미국 개발자들만의 데이터입니다.
- 이는 기본급만 반영하며, 더 폭넓게 달라질 수 있는 보너스나 주식은 포함하지 않습니다.
SHAP를 사용하여 성별과 상호 작용하는 특성 시각화하기
SHAP 라이브러리는 특성 상호 작용 효과를 분리하는 기능을 활용하여 흥미로운 시각화를 제공합니다. 예를 들어, 위의 값은 남성으로 응답한 개발자가 다른 개발자보다 약간 더 높은 급여를 받을 것으로 예측됨을 시사합니다. 하지만 이것이 전부일까요? 이와 같은 의존성 플롯이 도움이 될 수 있습니다.
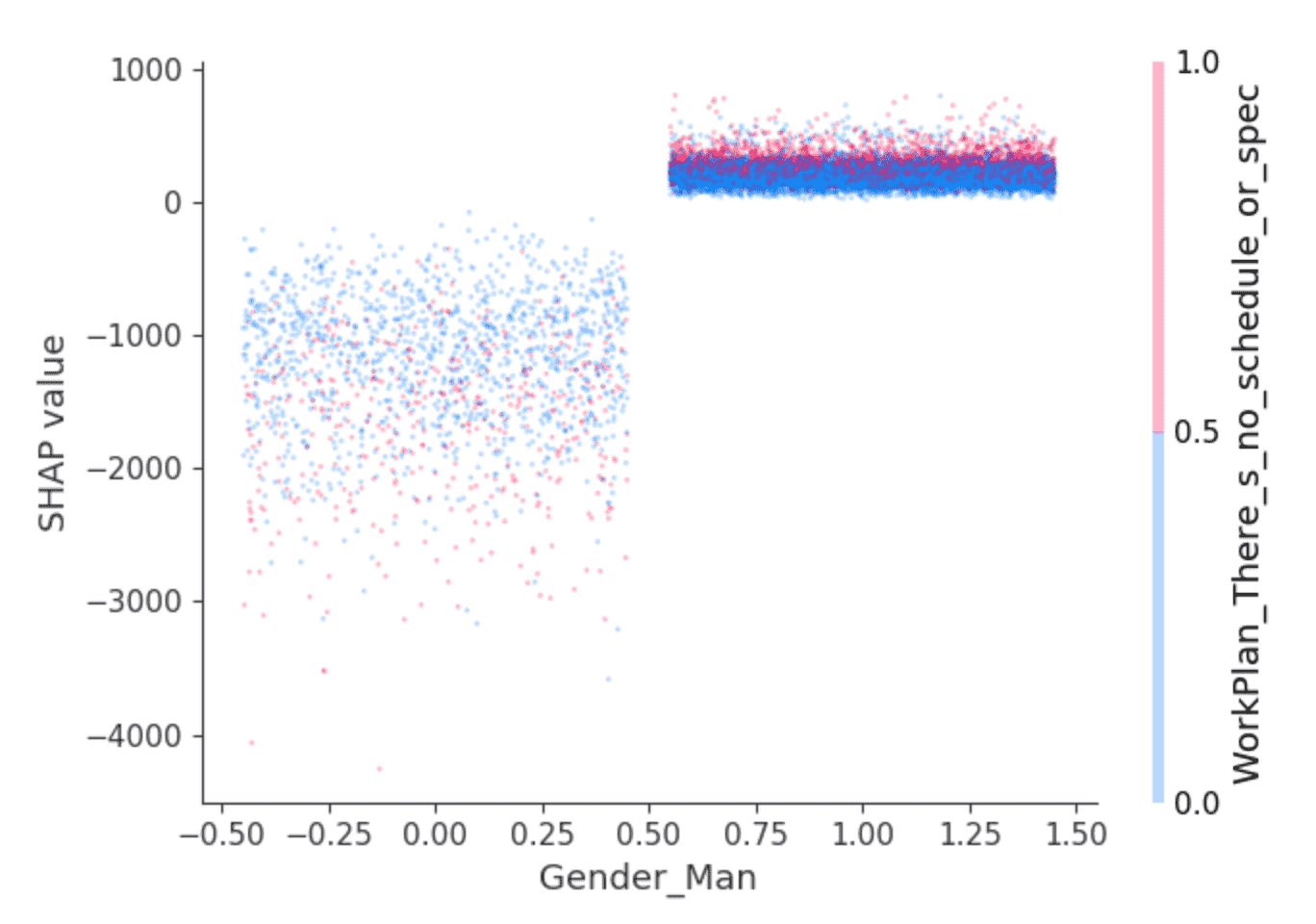
점은 �개발자입니다. 왼쪽의 개발자는 자신을 남성으로 정체화하지 않는 사람들이고, 오른쪽은 남성으로 정체화하는 사람들인데, 이들은 주로 남성으로만 정체화하는 사람들입니다. (명확성을 위해 점들이 수평으로 무작위로 분산되어 있습니다.) y축은 SHAP 값으로, 남성으로 정체화하는지 여부가 각 개발자의 예측 급여를 얼마나 설명하는지 나타냅니다. 위와 같이 자신을 남성으로 정체화하지 않는 사람들은 전반적으로 음수 SHAP 값을 보이며 그 변동 폭이 넓은 반면, 다른 사람들은 일관되게 작은 양수 SHAP 값을 보입니다.
이러한 편차의 원인은 무엇일까요? SHAP은 여기서는 남성으로 식별되는지 여부의 값에 따라 그 효과가 가장 많이 달라지는 두 번째 피처를 선택할 수 있습니다. "업무가 얼마나 체계적이거나 계획적입니까?"라는 질문에 "가장 중요하거나 긴급해 보이는 작업을 처리합니다"라는 답변을 선택합니다. 남성으로 식별되는 개발자 중에서 이렇게 답변한 사람들(빨간색 점)은 SHAP 값이 약간 더 높은 것으로 나타났습니다. 나머지 개발자들 사이에서는 효과가 더 복합적이지만 전반적으로 SHAP 값이 더 낮은 것으로 보입니다.
해석은 독자의 몫이지만, 이러한 의미에서 권한을 부여받았다고 느끼는 남성 개발자들은 약간 더 높은 급여를 받는 반면, 다른 개발자들은 급여가 낮은 역할과 밀접한 관련이 있을 때 이를 즐기는 것은 아닐까요?
성별에 따른 이례적인 효과가 있는 인스턴스 탐색
급여에 가장 부정적인 영향을 받는 개발자를 조사해 보면 어떨까요? 성별 관련 피처의 전반적인 영향을 살펴볼 수 있는 것처럼, 성별 관련 피처가 예측 급여에 가장 큰 영향을 미친 개발자를 검색하는 것도 ��가능합니다. 이 사람은 여성이며, 그 영향은 부정적입니다. 모델에 따르면 그녀는 성별 때문에 연간 약 4,260달러를 덜 벌 것으로 예측됩니다.

예측된 급여는 $157,000가 약간 넘는 금액이며, 실제 보고된 급여가 $150,000이므로 이 경우에는 정확합니다.
예측된 급여에 영향을 미치는 가장 긍정적인 특성 세 가지와 가장 부정적인 특성 세 가지는 다음과 같습니다.
- 대학교 학위만 있음 (+$18,200)
- 전문 경력 10년 (+$9,400)
- 동아시아인으로 식별 (+$9,100)
- ...
- 주 40시간 근무 (-$4,000)
- 남성으로 식별되지 않음(-$4,250)
- 직원 100-499명 규모의 중견 기업 근무 (-$9,700)
남성으로 식별되지 않는 것이 예측 급여에 미치는 영향의 크기를 고려할 때, 이 개발자를 둘러싼 맥락을 더 잘 이해하고 그녀의 경험이나 급여 또는 둘 다 변경이 필요한지 알아보기 위해 여기서 분석을 중단하고 오프라인으로 이 사례의 세부 사항을 조사할 수 있습니다.
SHAP 값을 사용하여 상호 작용 설명하기
해당 -$4,260에 대한 더 자세한 내용이 있습니다. SHAP는 이러한 특성의 효과를 상호작용으로 분해할 수 있습니다. 예측에 대한 '여성'이라는 응답의 전체적인 영향은 '여성'이면서 엔지니어링 관리자인 경우의 영향, 그리고 Windows를 사용하는 경우의 영향 등으로 세분화할 수 있습니다.
성별 요인 자체로 설명되는 예측 급여에 대한 효과는 약 -$630에 불과합니다. 오히려 SHAP은 성별 효과의 대부분을 다른 특성과의 상호작용에 할당합니다.
여성으로 식별되고 PostgreSQL을 사용하는 것은 예측 연봉에 약간 긍정적인 영향을 미치는 반면, 동아시아인으로도 식별되는 것은 예측 연봉에 더 부정적인 영향을 미칩니다. 이 맥락에서 이렇게 세부적인 수준으로 이러한 값을 해석하기는 어렵지만, 이러한 추가 수준의 설명은 제공됩니다.
아파치 스파크에 SHAP 적용하기
SHAP 값은 주어진 모델에 대해 각 행에 대해 독립적으로 계산되므로, Spark를 사용하여 이 작업을 병렬로 수행할 수도 있었습니다. 다음 예제는 SHAP 값을 병렬로 계산하고 이와 유사하게 비정상적으로 큰 성별 관련 SHAP 값을 가진 개발자를 찾습니다.
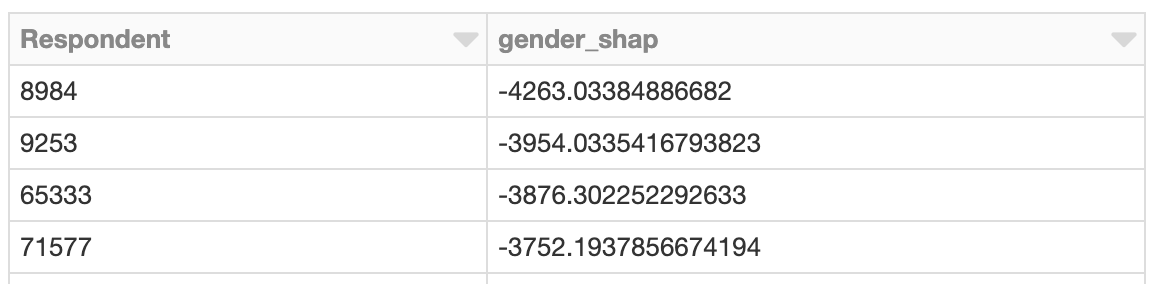
SHAP 값 클러스터링
SHAP로 평가할 예측이 많을 때 Spark를 적용하면 유리합니다. 해당 출력이 주어지면, 예를 들어 bisecting k-means와 같은 알고리즘으로 Spark를 사용하여 결과를 클러스터링할 수도 있습니다.
총 성별 관련 SHAP 효과가 가장 부정적으로 나타난 클러스터는 추가 조사가 필요할 수 있습니다. 클러스터에 있는 응답자의 SHAP 값은 어떻게 ��되나요? 클러스터의 구성원은 전체 개발자 인구와 비교했을 때 어떤 모습인가요?
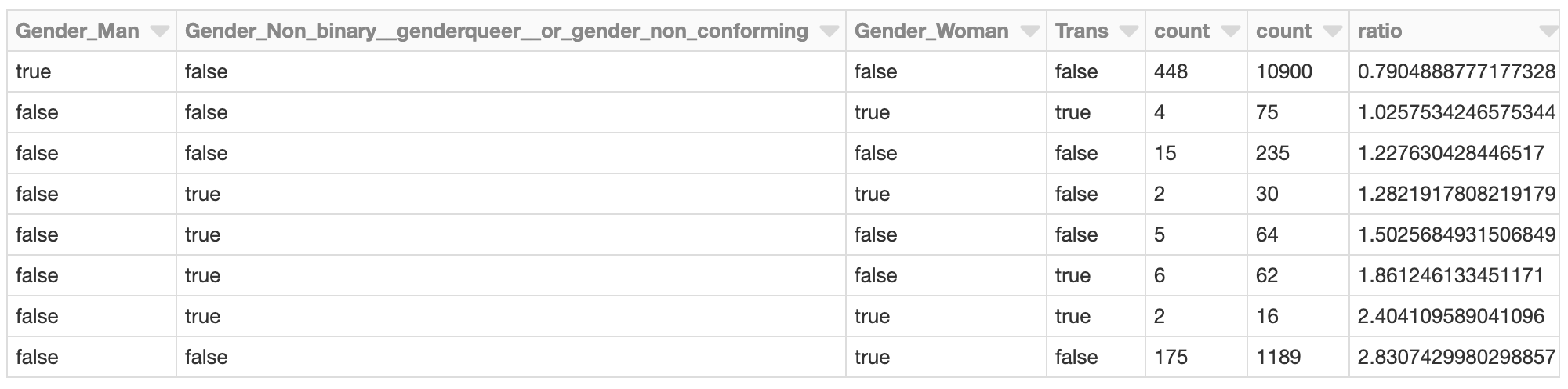
예를 들어, 자신을 여성(으로만)으로 밝힌 개발자는 이 클러스터에서 전체 개발자 인구보다 거의 2.8배 높은 비율로 나타납니다. 이전 분석을 고려하면 이는 놀랍지 않습니다. 이 클러스터를 추가로 조사하여 전반적으로 예측 급여가 낮아지는 데 기여하는 이 그룹의 다른 특정 요인을 평가할 수 있습니다.
결론
SHAP을 이용한 이러한 유형의 분석은 어떤 모델에든, 그리고 대규모로도 실행할 수 있습니다. 분석 도구로서, 모델을 데이터 탐정으로 전환하여 예측을 통해 더 자세히 살펴봐야 할 개별 인스턴스를 찾아냅니다. SHAP의 출력은 해석하기 쉽고 직관적인 플롯을 생성하며, 비즈니스 사용자는 이를 사례별로 평가할 수 있습니다.
물론 이 분석은 성별, 연령 또는 인종 편향 문제를 조사하는 데만 국한되지 않습니다. 더 현실적으로 말하자면, 고객 이탈 모델에 적용될 수 있습니다. 여기서 질문은 "이 고객이 이탈할 것인가?"뿐만 아니라 "이 고객은 왜 이탈하는가?"입니다. 가격 때문에 취소하는 고객에게는 할인을 제공할 수 있는 반면, 제한된 사용량 때문에 취소하는 고객에게는 업셀링이 필요할 수 있습니다.
마지막으로, 이 분석은 검증 프로세스의 일부로 실행될 수 있으며 머신 러닝 모델 �전반에 더 큰 투명성을 가져올 수 있습니다. 모델 검증은 종종 모델의 전반적인 정확도에 초점을 맞춥니다. 또한 모델의 '추론', 즉 어떤 특성이 예측에 가장 많이 기여했는지에도 초점을 맞춰야 합니다. SHAP을 사용하면 너무 많은 개별 예측의 설명이 전체 특성 중요도와 상충될 때 이를 감지하는 데 도움이 될 수 있습니다.
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.