Azure Databricks 및 Azure Data Factory를 사용하여 90+ 데이터 소스를 Data Lake에 연결
Delta Lake 사용을 시작하는 데 필요한 단계별 지침을 보려면
O'Reilly의 새로운 ebook 미리 보기를 확인하세요.
데이터 레이크를 통해 조직은 다양한 데이터 소스에 대한 안전하고 시기적절한
액세스를 통해 가치와 인사이트를 일관되게 제공할 수 있습니다.
이 여정의 첫 번째 단계는 강력한 데이터 파이프라인을 사용하여 수집을
오케스트레이션하고 자동화하는 것입니다.
데이터 볼륨, 다양성 및 속도가 빠르게 증가함에 따라 데이터를 추출,
변환 및 로드(ETL)하기 위한 안정적이고 안전한 파이프라인에 대한
필요성이 커지고 있습니다. Databricks 고객은 매달 2엑사바이트(20억 기가바이트)
이상의 데이터를 처리하며, Azure Databricks 는 현재 Microsoft Azure에서
가장 빠르게 성장하는 데이터 및 AI 서비스입니다.
Azure Databricks와 다른 Azure 서비스 간의 긴밀한 통합을 통해 고객은
데이터 수집 파이프라인을 간소화하고 확장할 수 있습니다.
예를 들어 Azure AD(Azure Active Directory)와 통합하면
일관된 클라우드 기반 ID 및 액세스 관리가 가능합니다.
또한 ADLS(Azure Data Lake Storage)와의 통합은 빅데이터 분석을 위한
확장성이 뛰어나고 안전한 스토리지를 제공하며,
ADF(Azure Data Factory)를 통해 하이브리드 데이터 통합을 통해
대규모 ETL을 간소화할 수 있습니다.
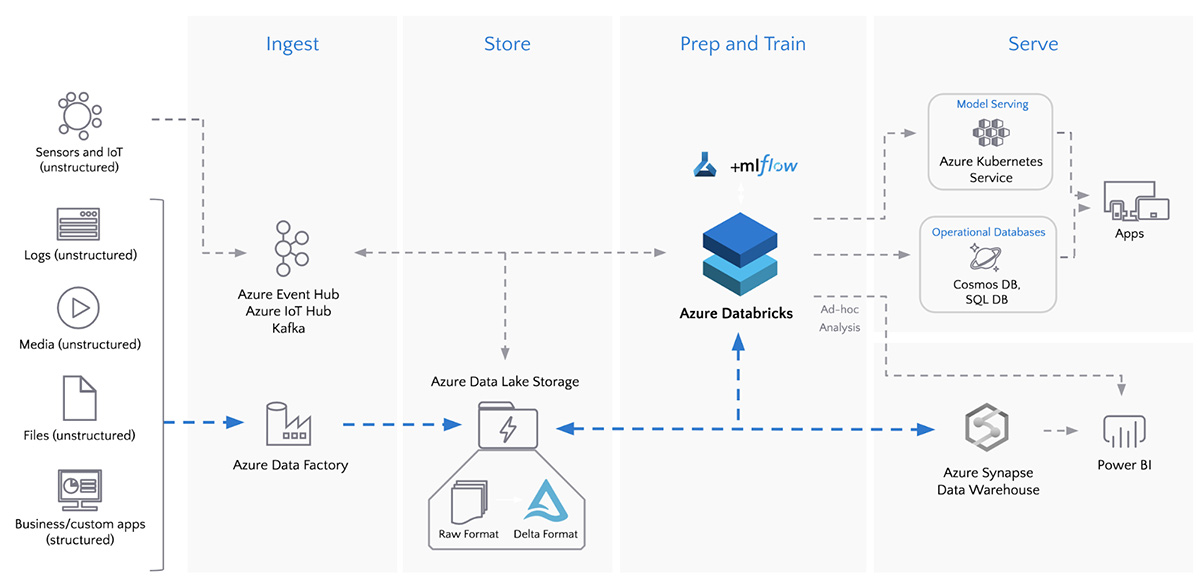
다이어그램: Azure Data Factory 및 Azure Databricks를 사용한 배치 ETL
단일 워크플로우를 통한 연결,
수집 및 데이터 변환
ADF에는 90+ 기본 내장 데이터 소스 커넥터 가 포함되어 있으며
Azure Databricks 노트북을 원활하게 실행하여 모든 데이터 소스를
단일 데이터 레이크에 연결하고 수집합니다.
또한 ADF는 기본 내장 워크플로 제어,
데이터 변환, 파이프라인 예약, 데이터 통합 및 신뢰할 수 있는
데이터 파이프라인을 만드는 데 도움이 되는 더 많은 기능을 제공합니다.
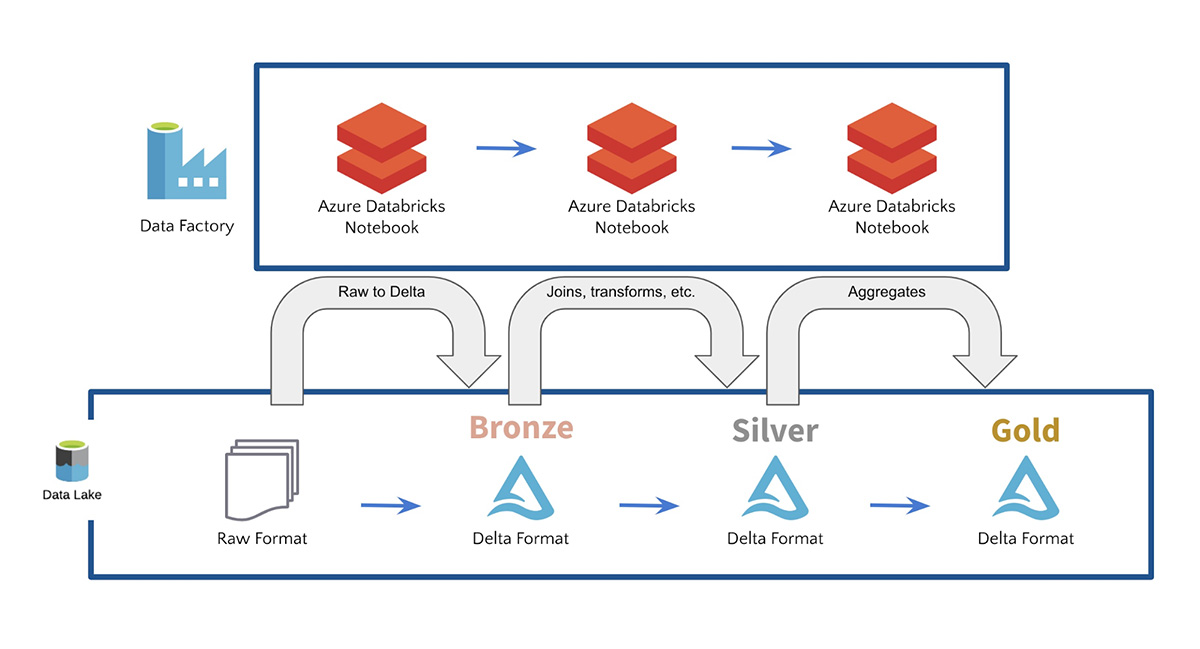
ADF를 사용하면 고객이 원시 형식으로 데이터를 수집한 다음,
Azure Databricks 및 Delta Lake를 사용하여 데이터를 구체화하고
브론즈, 실버 및 골드 테이블로 변환할 수 있습니다.
예를 들어 고객은 Azure Databricks Delta Lake와 함께
ADF를 사용하여 데이터 레이크에서 SQL query 사용하도록 설정하고
머신 러닝을 위한 데이터 파이프라인을 빌드하는 경우가 많습니다.
Azure Databricks 및 Azure Data Factory 시작
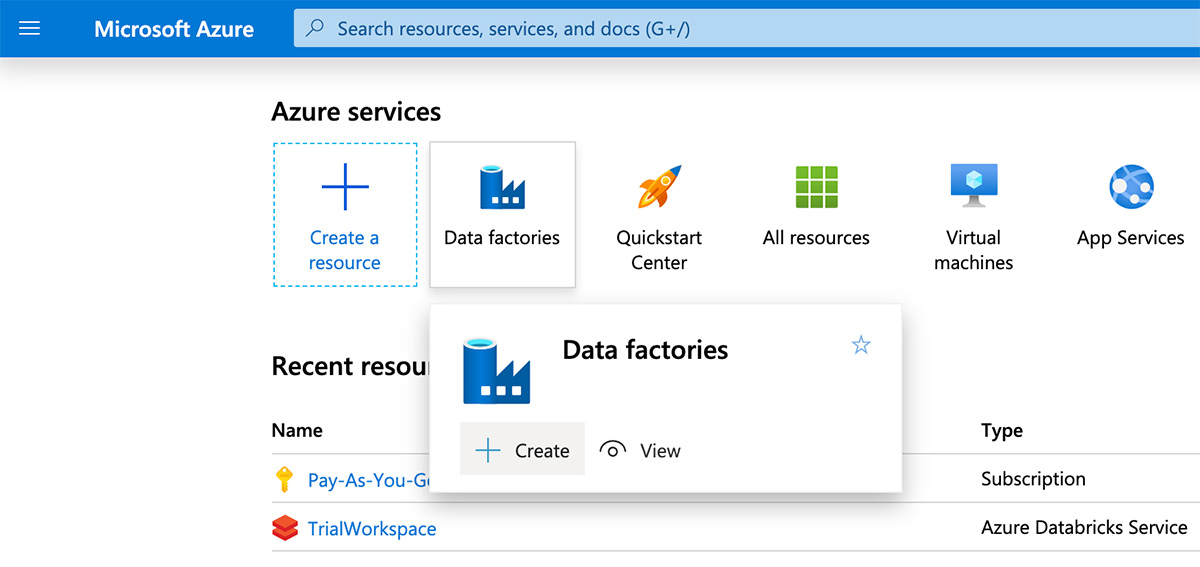
Azure Data Factory를 사용하여 Azure Databricks 노트북을 실행하려면 Azure Portal로 이동하여 "데이터 팩터리"를 검색한 다음, "만들기"를 클릭하여 새 데이터 팩터리를 정의합니다.
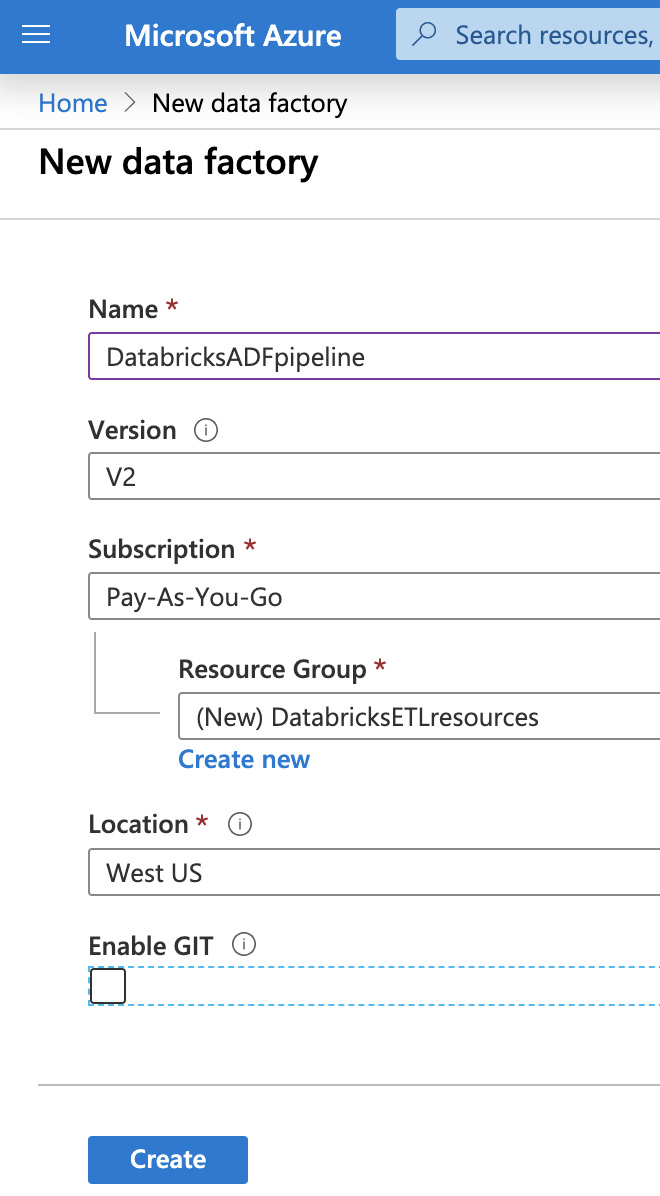
다음으로, 데이터 팩터리의 고유한 이름을 제공하고, 구독을 선택한 다음, 리소스 그룹 및 지역을 선택합니다. "Create(만들기)"를 클릭합니다.
만든 후에는 "리소스로 이동" 단추를 클릭하여 새 데이터 팩터리를 봅니다.
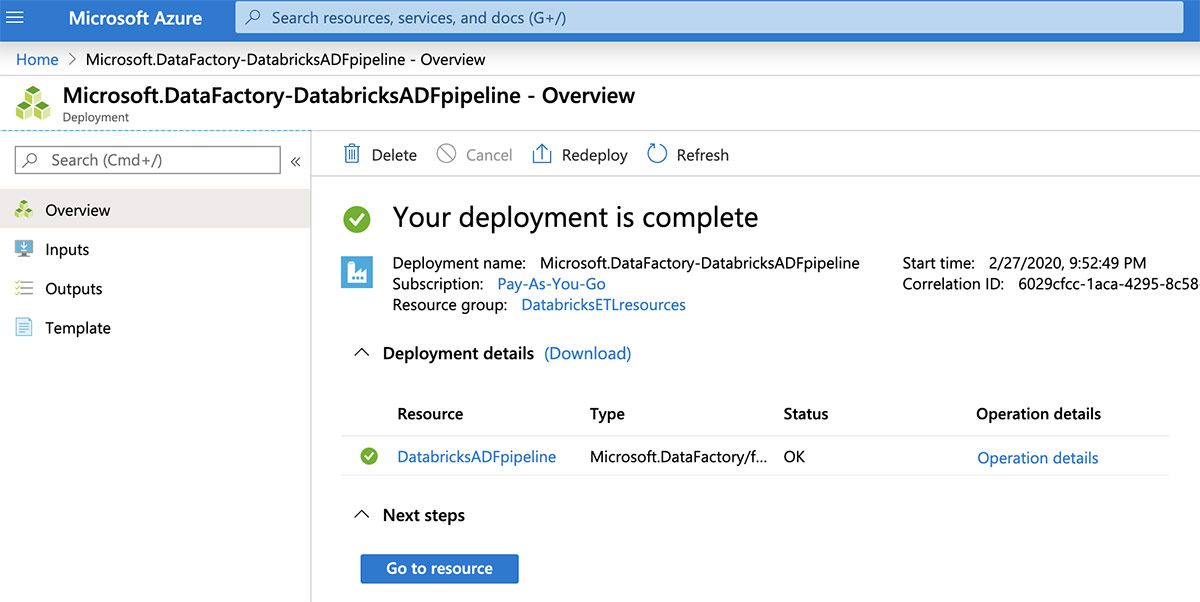
이제 "작성자 및 모니터" 타일을 클릭하여 Data Factory 사용자 인터페이스를 엽니다.
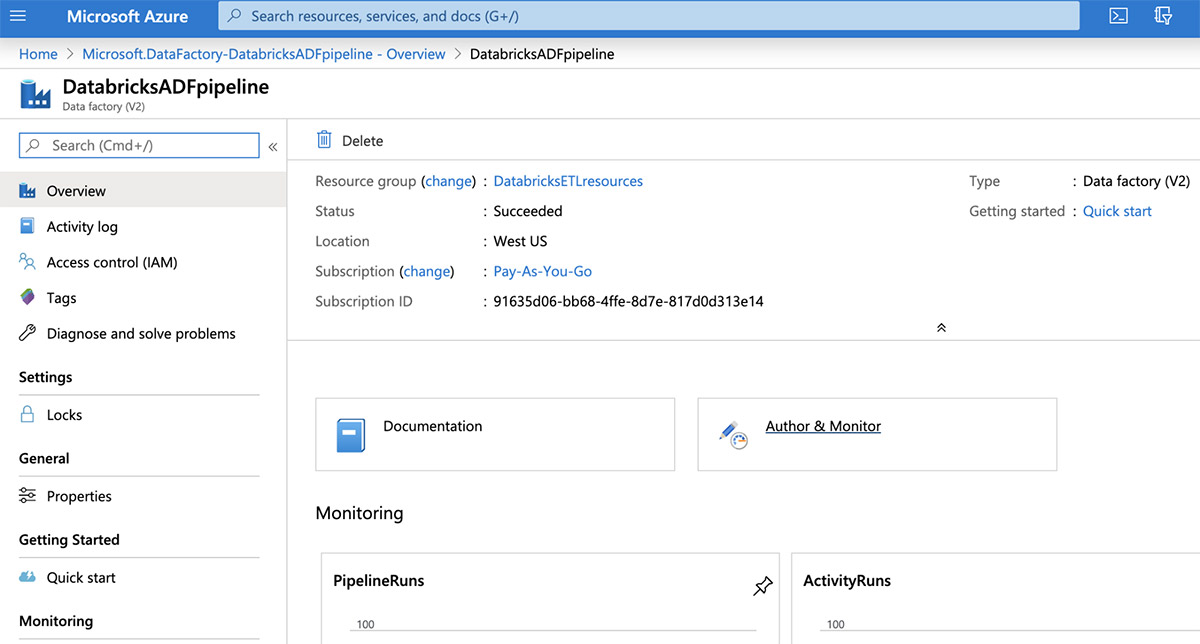
Azure Data Factory "시작" 페이지의 왼쪽 패널에서 "작성자" 단추를 클릭합니다.
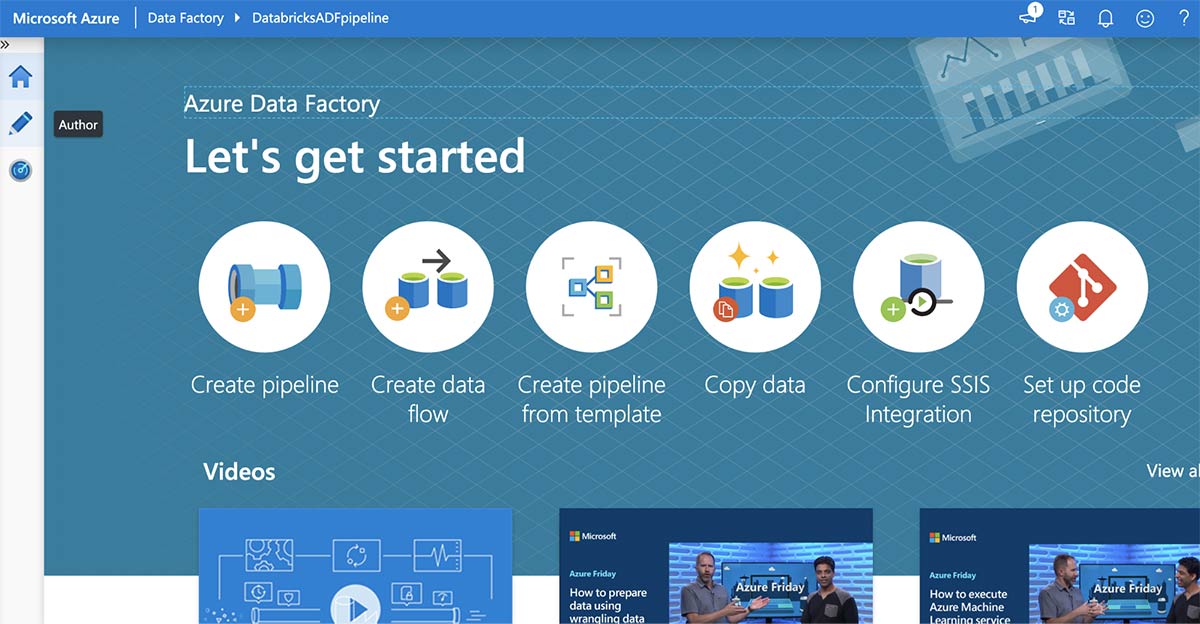
그런 다음 화면 하단의 "연결"을 클릭한 다음 "새로 만들기"를 클릭합니다.
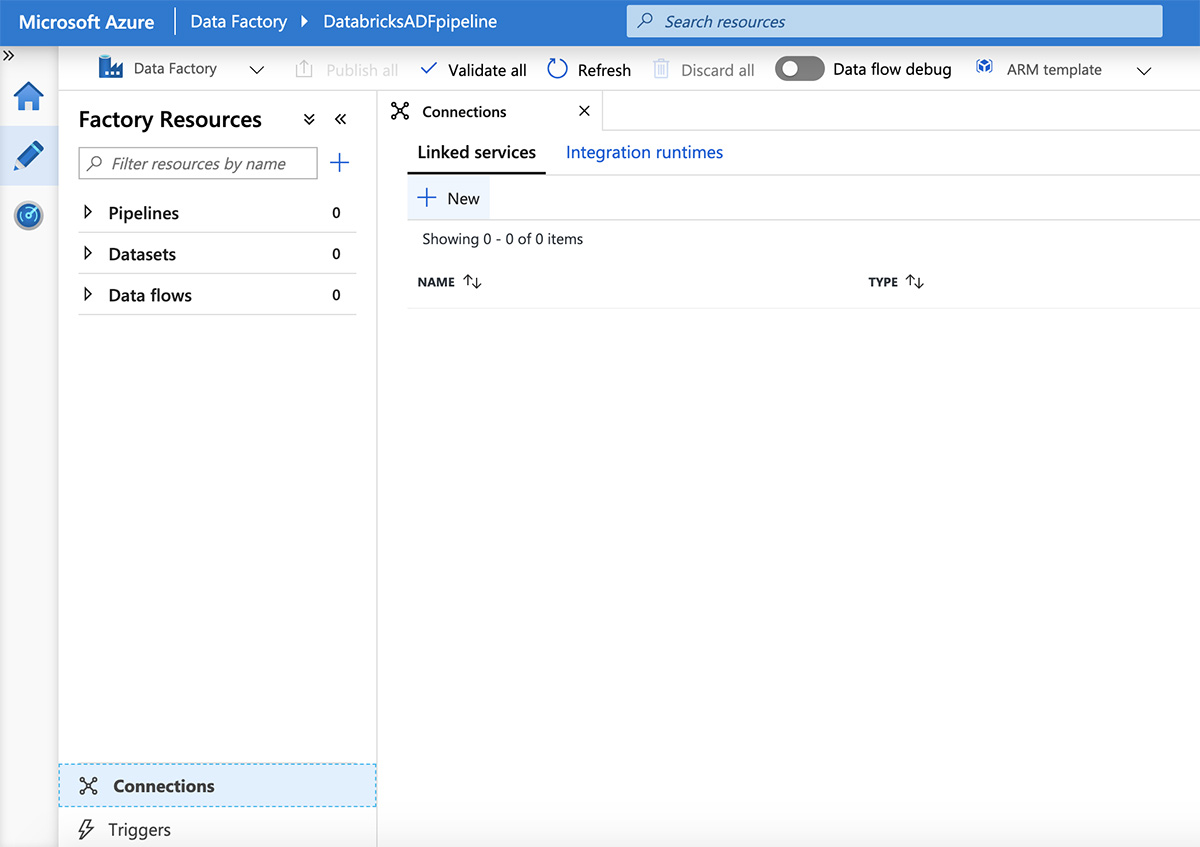
"새 연결된 서비스" 창에서 "compute" 탭을 클릭하고 "Azure Databricks"를 선택한 다음, "계속"을 클릭합니다.
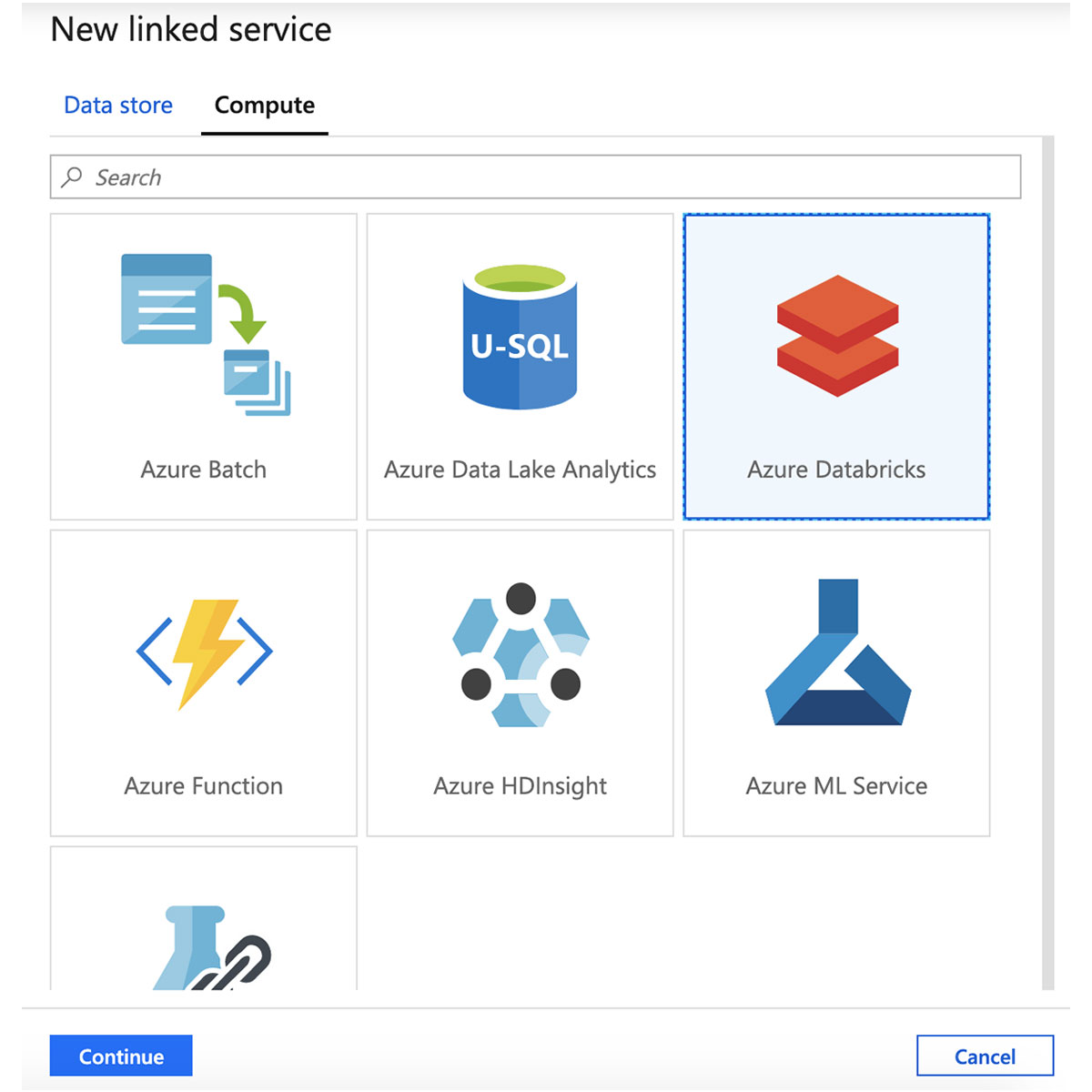
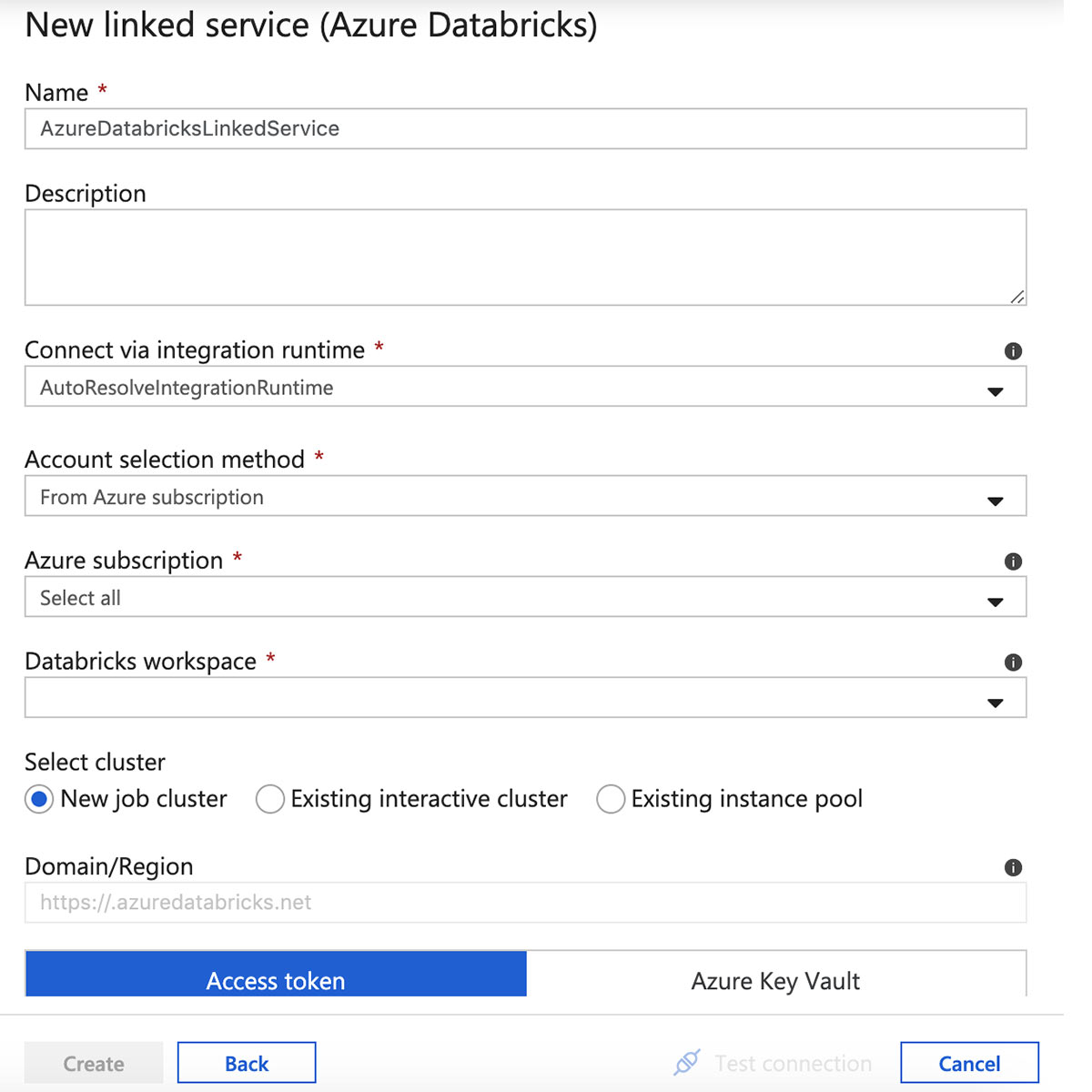
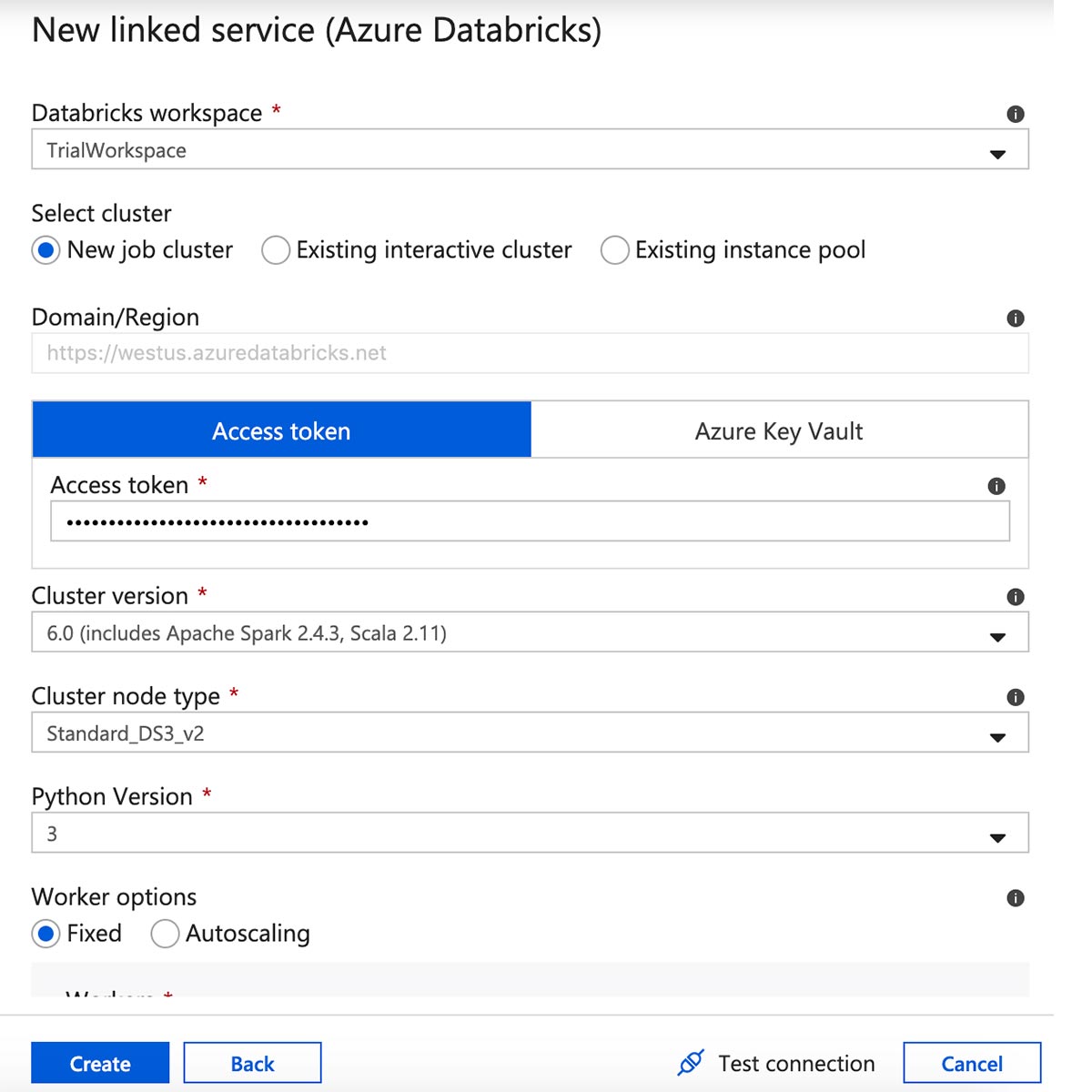
Azure Databricks 연결된 서비스의 이름을 입력하고 워크스페이스를 선택합니다.
화면 오른쪽 위 모서리에 있는 사용자 아이콘을 클릭하여 Azure Databricks 워크스페이스에서 액세스 토큰을 만든 다음, "사용자 설정"을 선택합니다.
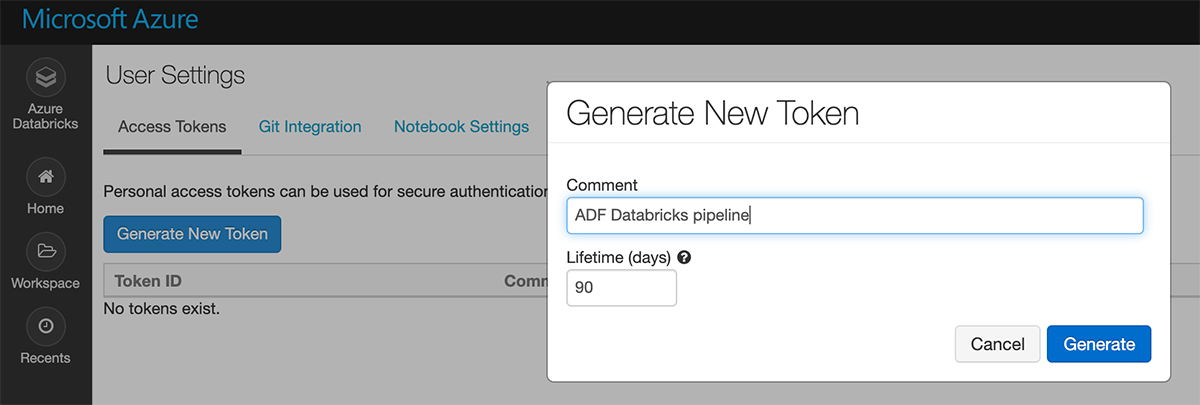
"Generate New Token(새 토큰 생성)"을 클릭합니다.
토큰을 복사하여 연결된 서비스 양식에 붙여넣은 다음, clusters 버전, 크기 및 Python 버전을 선택합니다. 모든 설정을 검토하고 "만들기"를 클릭합니다.
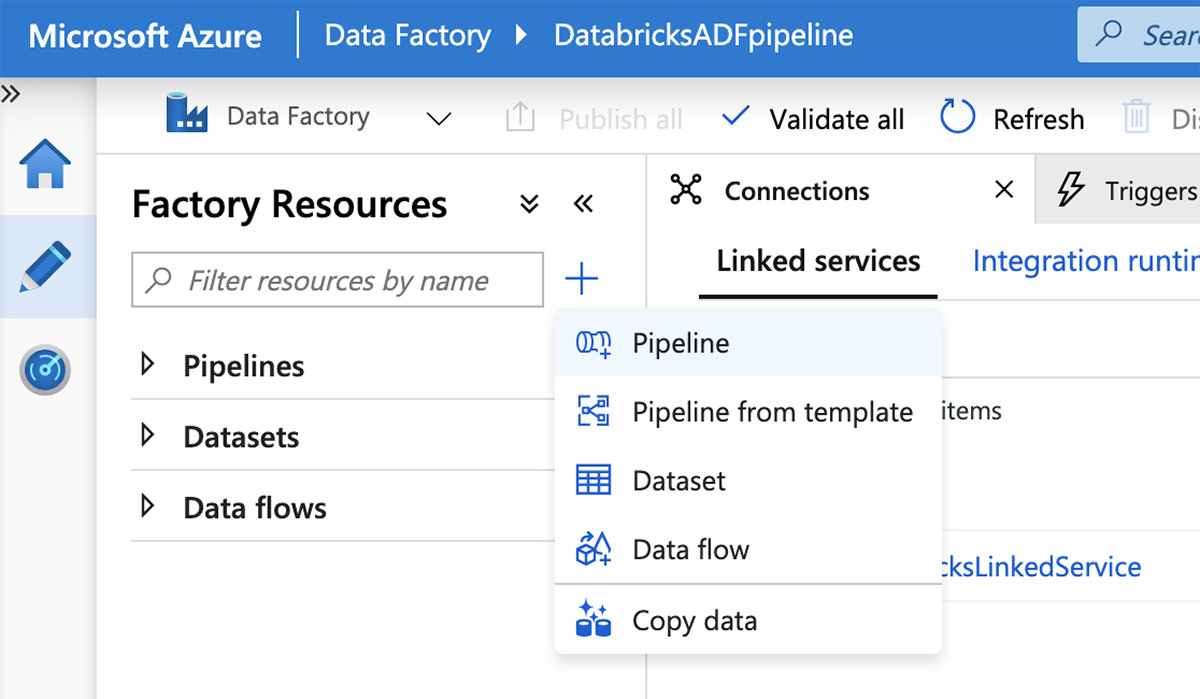
연결된 서비스가 준비되면 파이프라인을 만들 차례입니다. Azure Data Factory UI에서 더하기(+) 단추를 클릭하고 "파이프라인"을 선택합니다.
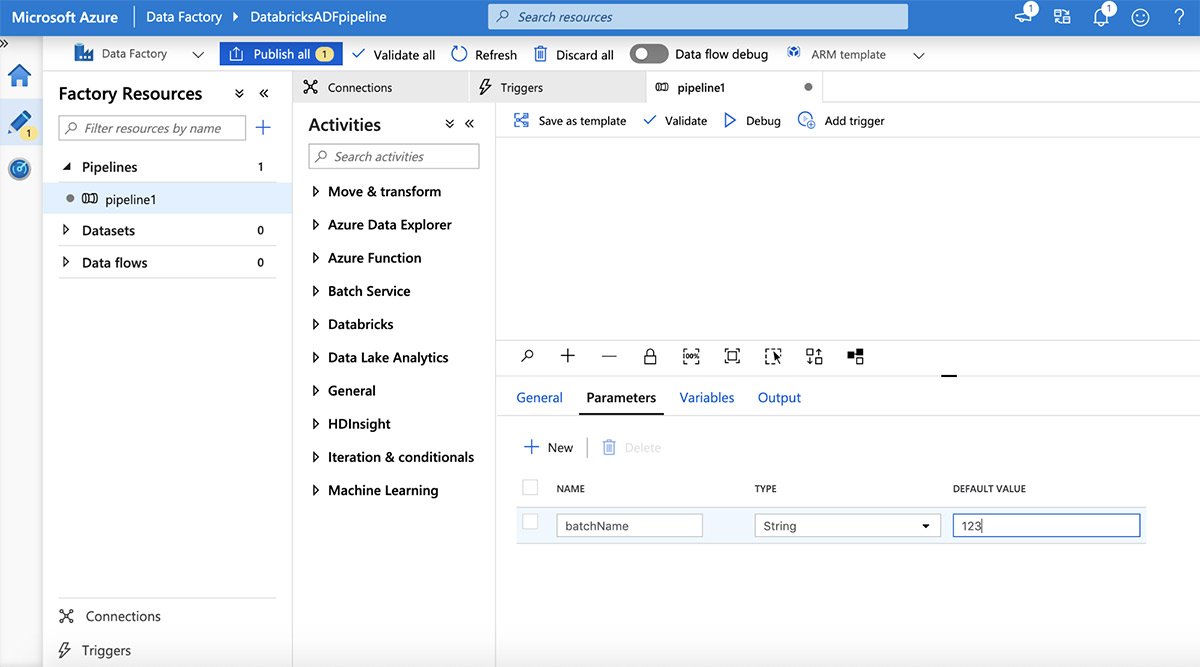
"parameter " 탭을 클릭하여 parameter추가한 다음 더하기(+) 버튼을 클릭합니다.
다음으로, "Databricks" 작업을 확장한 다음, Databricks 노트북을 파이프라인 디자인 캔버스로 끌어다 놓아 파이프라인에 Databricks 노트북을 추가합니다.
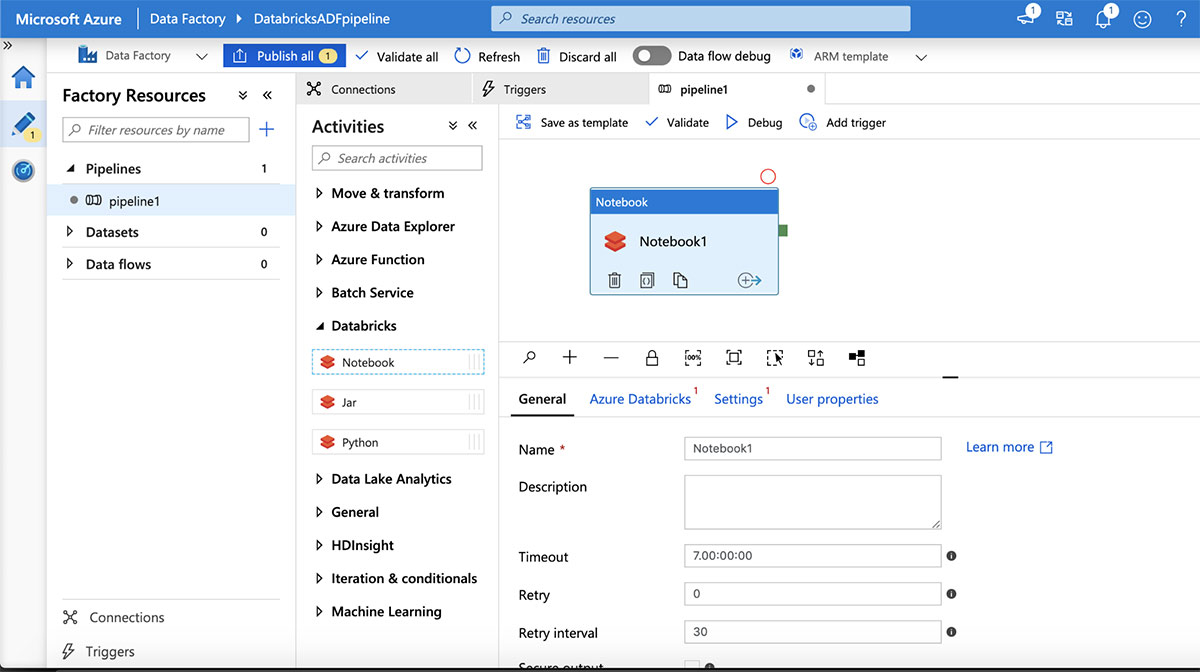
"Azure Databricks" 탭을 선택하고 위에서 만든 연결된 서비스를 선택하여 Azure Databricks 워크스페이스에 연결합니다.
그런 다음 "설정" 탭을 클릭하여 노트북 경로를 지정합니다. 이제 "유효성 검사" 단추를 클릭한 다음 "모두 게시"를 클릭하여 ADF 서비스에 게시합니다.
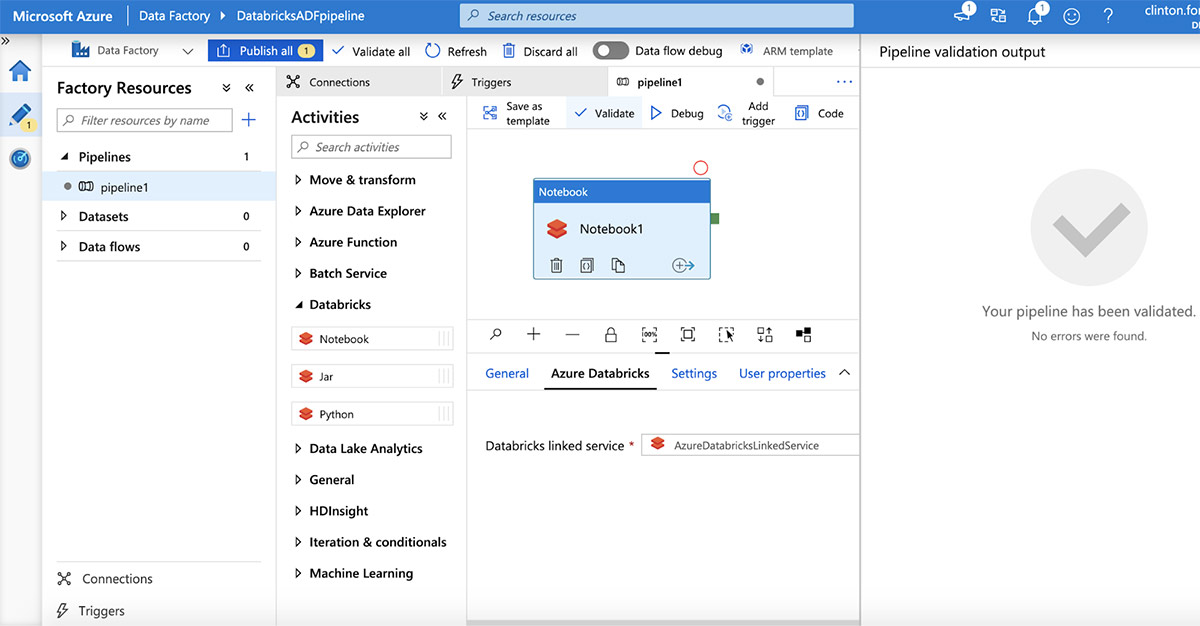
게시되면 "Add Trigger | 트리거 추가".
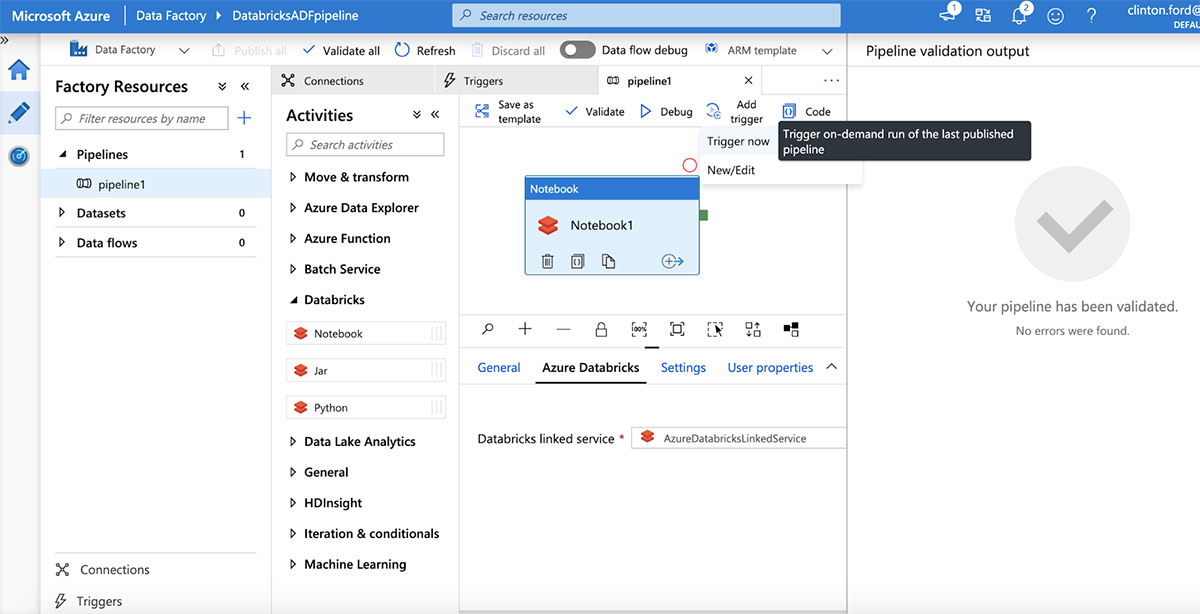
parameter 검토한 다음 "마침"을 클릭하여 파이프라인 실행을 트리거합니다.
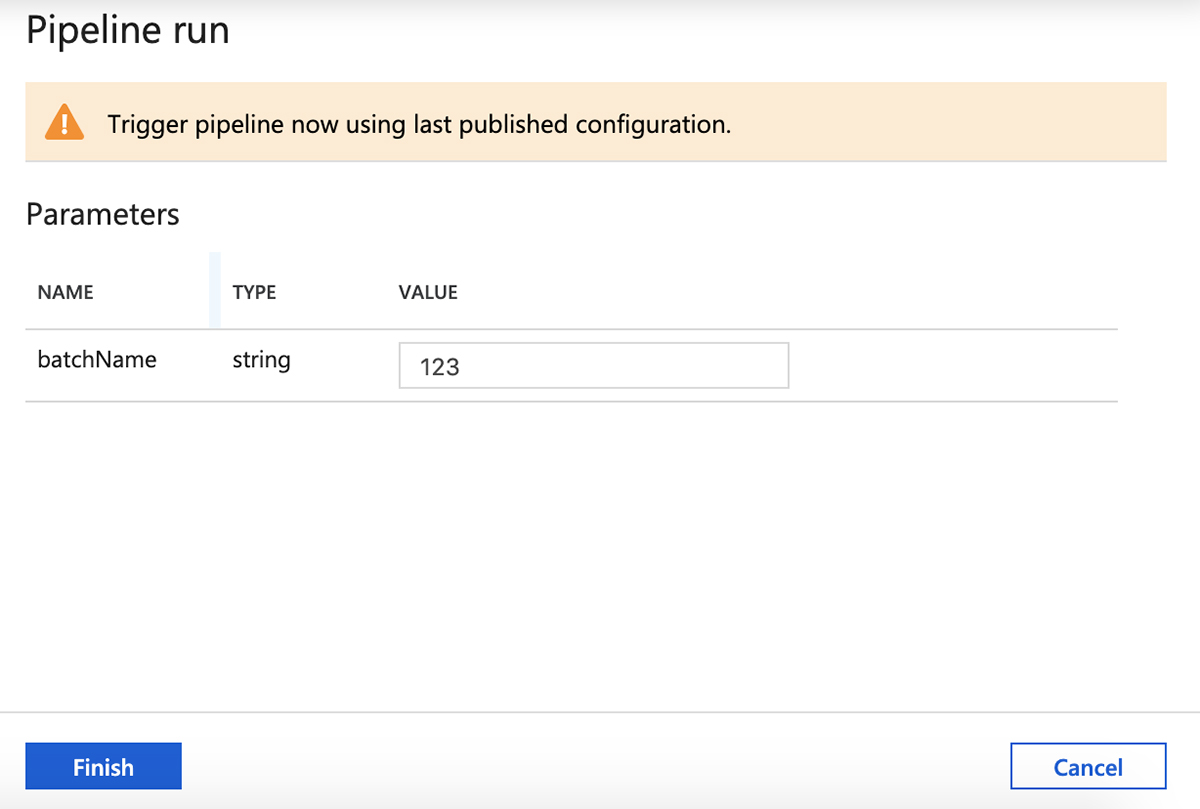
이제 왼쪽 패널의 "모니터" 탭으로 전환하여 파이프라인 실행의 진행률을 확인합니다.
Azure Databricks 노트북을 Azure Data Factory 파이프라인에 통합하면
사용자 지정 ETL 코드를 매개 변수화하고 운영하는 유연하고 확장 가능한 방법이 제공됩니다.
Azure Databricks가 ADF(Azure Data Factory)와 통합되는 방법에 대한
자세한 내용은 이 ADF 블로그 게시물 및 이 ADF 자습서를 참조하세요.
데이터 레이크에서 데이터를 탐색하고 query 방법에 대한 자세한 내용은
SQL을 사용하여 Delta Lake로 데이터 레이크 query 웨비나를 참조하세요.
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.