Apache Spark 3.0 소개
이제 Databricks Runtime 7.0에서 사용할 수 있습니다.
작성자: Matei Zaharia, Reynold Xin, Xiao Li, Wenchen Fan , Yin Huai
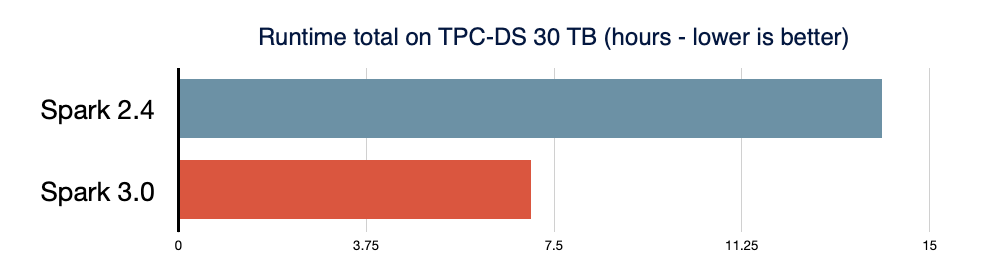
및 기타 최적화 덕분에 Spark 2.4에 비해 TPC-DS 성능이
Apache SparkTM 3.0.0 릴리스가 새로운 Databricks Runtime 7.0의 일부로 Databricks에서 제공됩니다. 3.0.0 릴리스에는 3,400개 이상의 패치가 포함되어 있으며 오픈 소스 커뮤니티의 엄청난 기여가 집대성된 결과물입니다. 또한 Python 및 SQL 기능이 크게 발전했으며 탐색 및 프로덕션 환경 모두에서 사용 편의성에 중점을 두었습니다. 이러한 이니셔티브는 더 많은 사용 사례와 더 넓은 사용자층을 만족시키기 위해 프로젝트가 어떻게 발전해 왔는지를 보여주며, 올해는 오픈 소스 프로젝트로서 10주년을 맞이합니다.
Spark 3.0의 주요 새로운 기능은 다음과 같습니다.
- 적응형 쿼리 실행, 동적 파티션 정리 및 기타 최적화 덕분에 Spark 2.4에 비해 TPC-DS 성능이 2배 향상되었습니다.
- ANSI SQL 규정 준수
- Python 유형 힌트 및 추가 pandas UDF를 포함한 pandas API의 상당한 개선
- 향상된 Python 오류 처리, PySpark 예외 단순화
- Structured Streaming을 위한 새로운 UI
- R 사용자 정의 함수 호출을 위한 최대 40배 속도 향상
- 3,400개 이상의 Jira 티켓 해결
이 버전의 Apache Spark를 도입하는 데 주요 코드 변경은 필요하지 않습니다. 자세한 정보는 마이그레이션 가이드를 확인하세요.
Spark 개발과 진화 10주년
Spark는 데이터 집약적 컴퓨팅에 중점을 둔 연구실인 UC Berkeley의 AMPlab에서 시작되었습니다. AMPlab 연구원들은 대규모 인터넷 기업들과 함께 데이터 및 AI 문제를 해결하고 있었지만, 이와 동일한 문제가 대규모의 증가하는 데이터를 보유한 모든 기업에도 닥칠 것이라는 점을 알게 되었습니다. 팀은 이러한 새로운 워크로드를 처리하고 동시에 개발자들이 빅데이터 작업을 위한 API에 훨씬 더 쉽게 접근할 수 있도록 새로운 엔진을 개발했습니다.
커뮤니티의 기여를 통해 스트리밍, Python, SQL 관련 새로운 기능들이 빠르게 추가되어 Spark가 다양한 영역으로 확장되었으며, 이제 이러한 패턴들은 Spark의 주요 사용 사례 중 일부가 되었습니다. 이러한 지속적인 투자를 통해 Spark는 오늘날 데이터 처��리, Data Science, machine learning 및 데이터 분석 워크로드를 위한 사실상의 표준 엔진으로 자리매김했습니다. Apache Spark 3.0은 현재 Spark에서 가장 널리 사용되는 두 언어인 SQL과 Python에 대한 지원을 크게 개선하고 Spark의 나머지 부분 전반에 걸쳐 성능 및 운영성을 최적화함으로써 이러한 추세를 이어가고 있습니다.
Spark SQL 엔진 개선
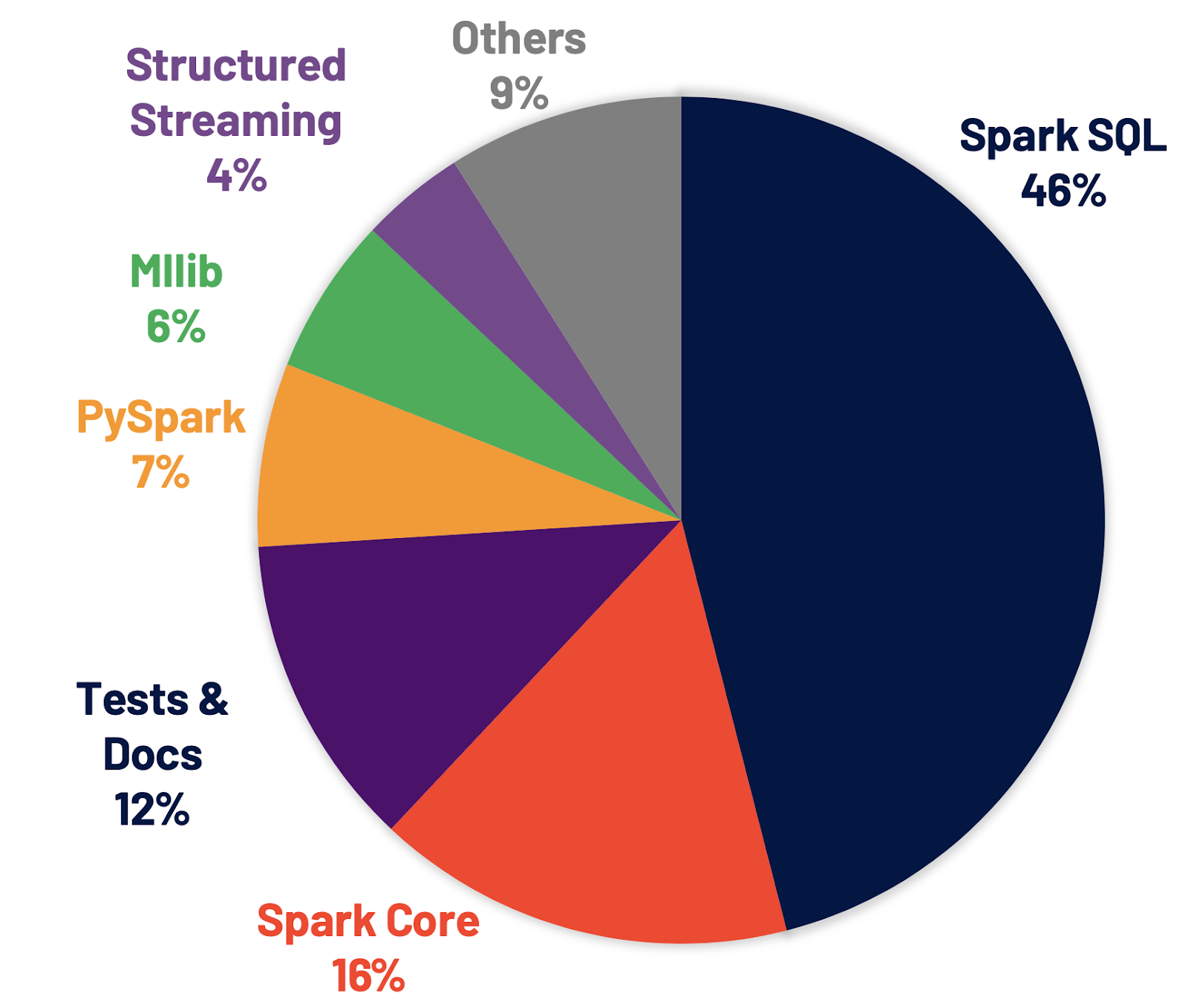
Spark SQL은 대부분의 Spark 애플리케이션을 지원하는 엔진입니다. 예를 들어 Databricks에서는 Spark API 호출의 90% 이상 이 SQL 옵티마이저에 의해 최적화된 다른 라이브러리와 함께 DataFrame, 데이터세트 및 SQL API를 사용하는 것으로 나타났습니다. 이는 Python 및 Scala 개발자조차도 작업의 상당 부분을 Spark SQL 엔진을 통해 처리한다는 것을 의미합니다. Spark 3.0 릴리스에서는 기여한 모든 패치의 46% 가 SQL용이었으며 성능과 ANSI 호환성을 모두 개선했습니다. 아래 그림과 같이 Spark 3.0은 총 런타임에서 Spark 2.4보다 약 2배 더 나은 성능을 보였습니다. 다음으로 Spark SQL 엔진의 네 가지 새로운 기능을 설명하겠습니다.
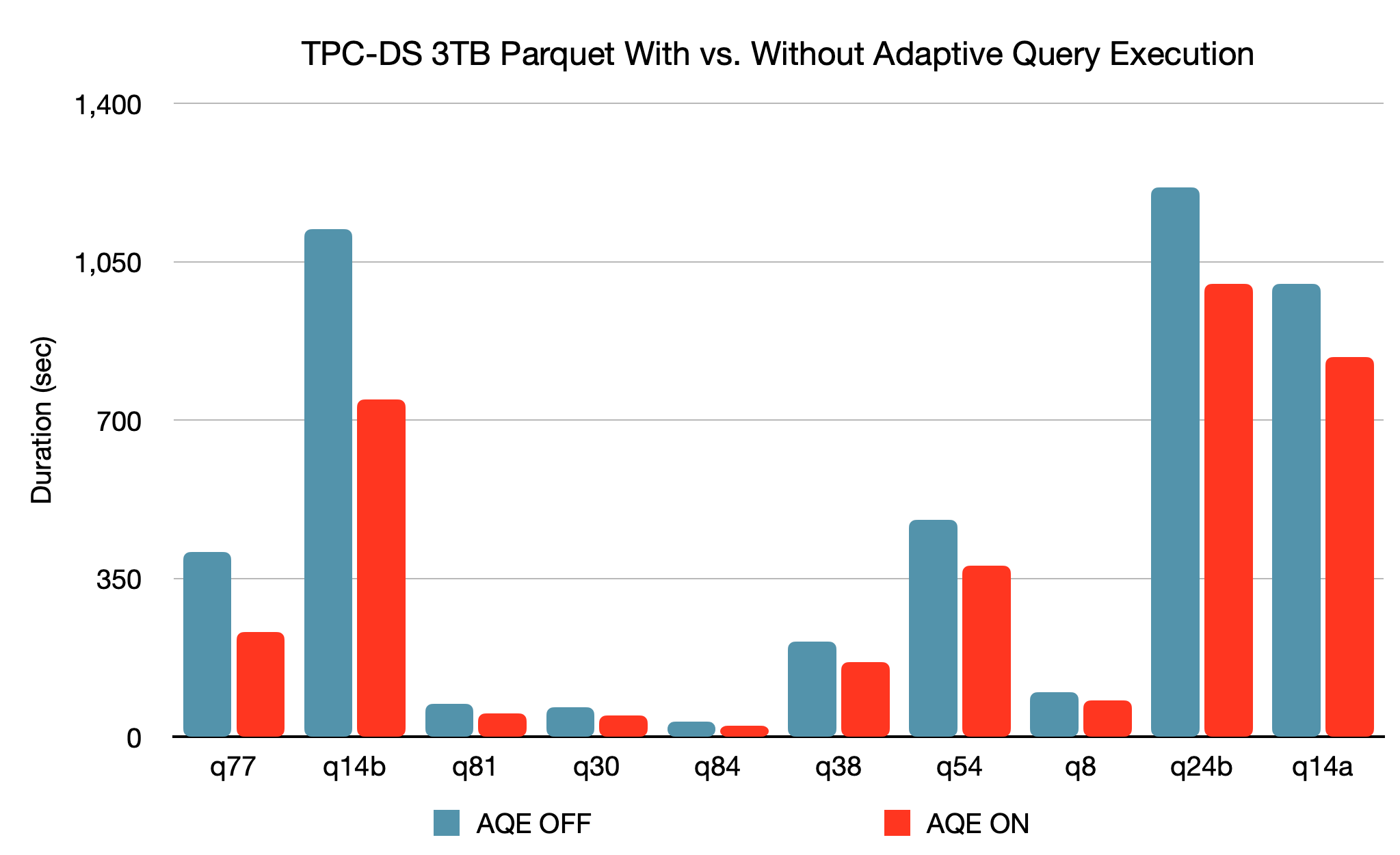
새로운 적응형 쿼리 실행 (AQE) 프레임워크는 데이터 통계가 없거나 부정확하고 비용이 잘못 추정되어 초기 계획이 최적이 아니더라도 런타임에 더 나은 실행 계획을 생성하여 성능을 개선하고 튜닝을 단��순화합니다. Spark는 스토리지와 컴퓨팅이 분리되어 있어 데이터 도착을 예측하기 어려울 수 있습니다. 이러한 모든 이유로 Spark에서는 기존 시스템보다 런타임 적응성이 더욱 중요해집니다. 이번 릴리스에서는 세 가지 주요 적응형 최적화를 소개합니다.
- 셔플 파티션의 동적 통합 은 셔플 파티션 수 튜닝을 단순화하거나 심지어 피하게 해줍니다. 사용자는 처음에 비교적 많은 수의 셔플 파티션을 설정할 수 있으며, AQE는 런타임에 인접한 작은 파티션을 더 큰 파티션으로 결합할 수 있습니다.
- 조인 전략의 동적 전환 은 누락된 통계 및/또는 크기 오측으로 인한 차선의 계획 실행을 부분적으로 방지합니다. 이 적응형 최적화는 런타임에 sort-merge join을 broadcast-hash join으로 자동 변환하여 튜닝을 더욱 단순화하고 성능을 향상시킵니다.
- 비대칭 조인을 동적으로 최적화하는 것 은 또 다른 중요한 성능 향상 기능입니다. 비대칭 조인은 작업의 극심한 불균형을 초래하여 성능을 심각하게 저하시킬 수 있기 때문입니다. AQE가 셔플 파일 통계에서 비대칭을 감지하면 비대칭 파티션을 더 작은 파티션으로 분할하고 다른 쪽의 해당 파티션과 조인할 수 있습니다. 이 최적화는 스큐 처리를 병렬화하여 전반적인 성능을 개선할 수 있습니다.
3TB TPC-DS 벤치마크를 기준으로, AQE를 사용하지 않았을 때와 비교했을 때 AQE를 사용하는 Spark는 2개의 쿼리에서 1.5배 이상, 다른 37개의 쿼리에서 1.1배 이상의 성능 향상을 보였습니다.
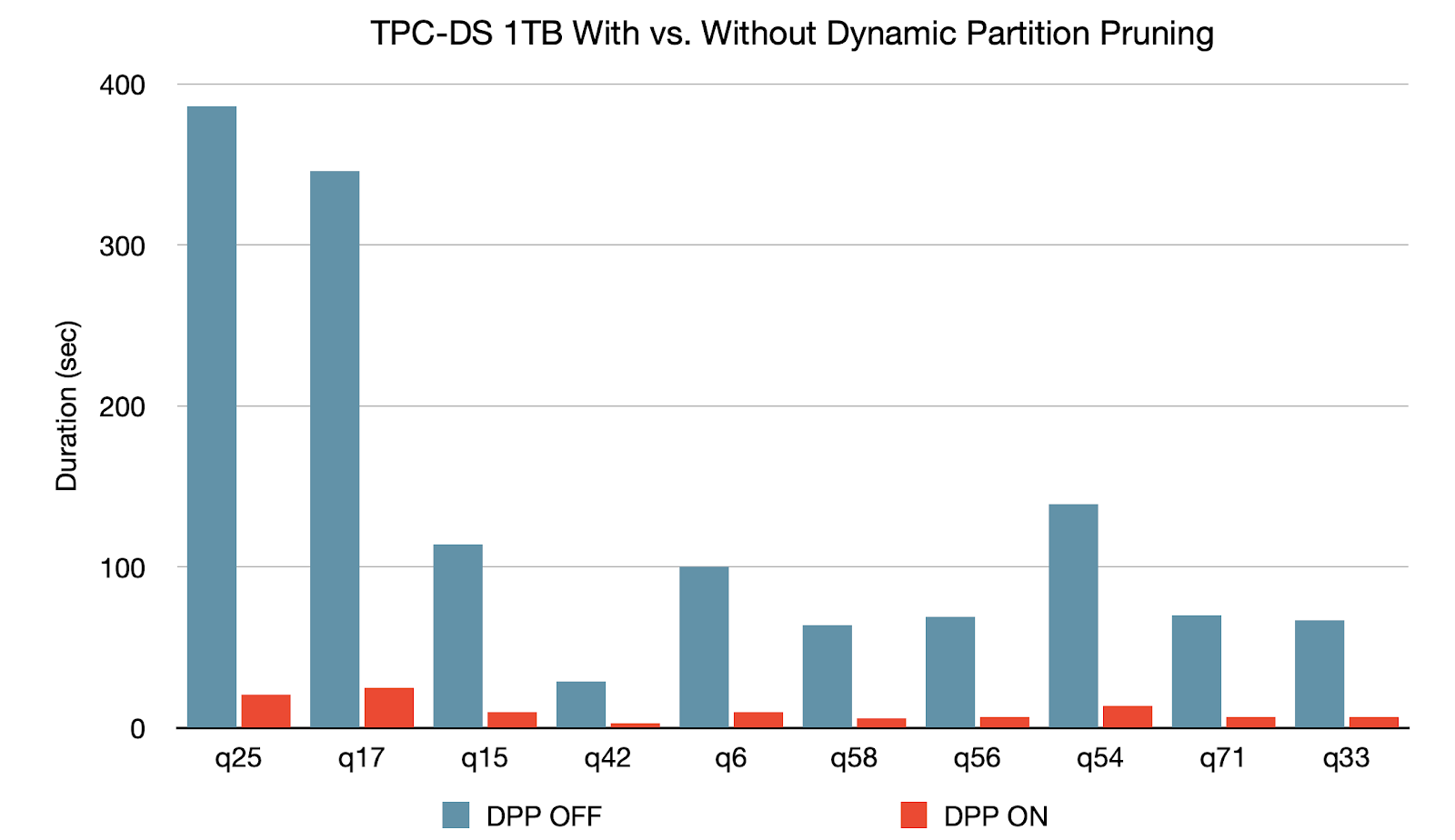
동적 파티션 정리 는 옵티마이저가 컴파일 시간에 건너뛸 수 있는 파티션을 식별할 수 없을 때 적용됩니다. 이는 하나 이상의 팩트 테이블이 임의 개수의 차원 테이블을 참조하는 스타 스키마에서 드문 일이 아닙니다. 이러한 조인 운영에서는 차원 테이블 필터링으로 생성된 파티션을 식별하여 조인이 팩트 테이블에서 읽어들이는 파티션을 정리할 수 있습니다. TPC-DS 벤치마크에서 102개 쿼리 중 60개가 2배에서 18배 사이의 상당한 속도 향상을 보였습니다.
ANSI SQL 규정 준수 는 다른 SQL 엔진에서 Spark SQL로 워크로드를 마이그레이션하는 데 매우 중요합니다. 규정 준수를 개선하기 위해 이번 릴리스에서는 그레고리력을 사용하도록 전환했으며, 사용자가 ANSI SQL의 예약어를 식별자로 사용하지 못하도록 설정할 수 있는 기능도 추가했습니다. 또한 숫자 연산의 런타임 오버플로 검사와 미리 정의된 스키마가 있는 테이블에 데이터를 삽입할 때의 컴파일 타임 유형 강제 적용 기능을 도입했습니다. 이러한 새로운 유효성 검사 기능은 데이터 품질을 향상시킵니다.
조인 힌��트: 컴파일러를 계속 개선하고는 있지만, 조인 알고리즘 선택은 통계 및 휴리스틱을 기반으로 하므로 컴파일러가 모든 상황에서 항상 최적의 결정을 내릴 것이라고 보장할 수는 없습니다. 컴파일러가 최상의 선택을 할 수 없는 경우, 사용자는 조인 힌트를 사용하여 옵티마이저가 더 나은 계획을 선택하도록 영향을 줄 수 있습니다. 이번 릴리스는 새로운 힌트인 SHUFFLE_MERGE, SHUFFLE_HASH, SHUFFLE_REPLICATE_NL을 추가하여 기존 조인 힌트를 확장합니다.
Python은 현재 Spark에서 가장 널리 사용되는 언어이며, 결과적으로 Spark 3.0 개발의 핵심 중점 분야였습니다. Databricks 노트북 명령어의 68% 는 Python입니다. Apache Spark Python API인 PySpark는 Python 패키지 인덱스(PyPI)에서 월간 5백만 회 이상 다운로드됩니다.
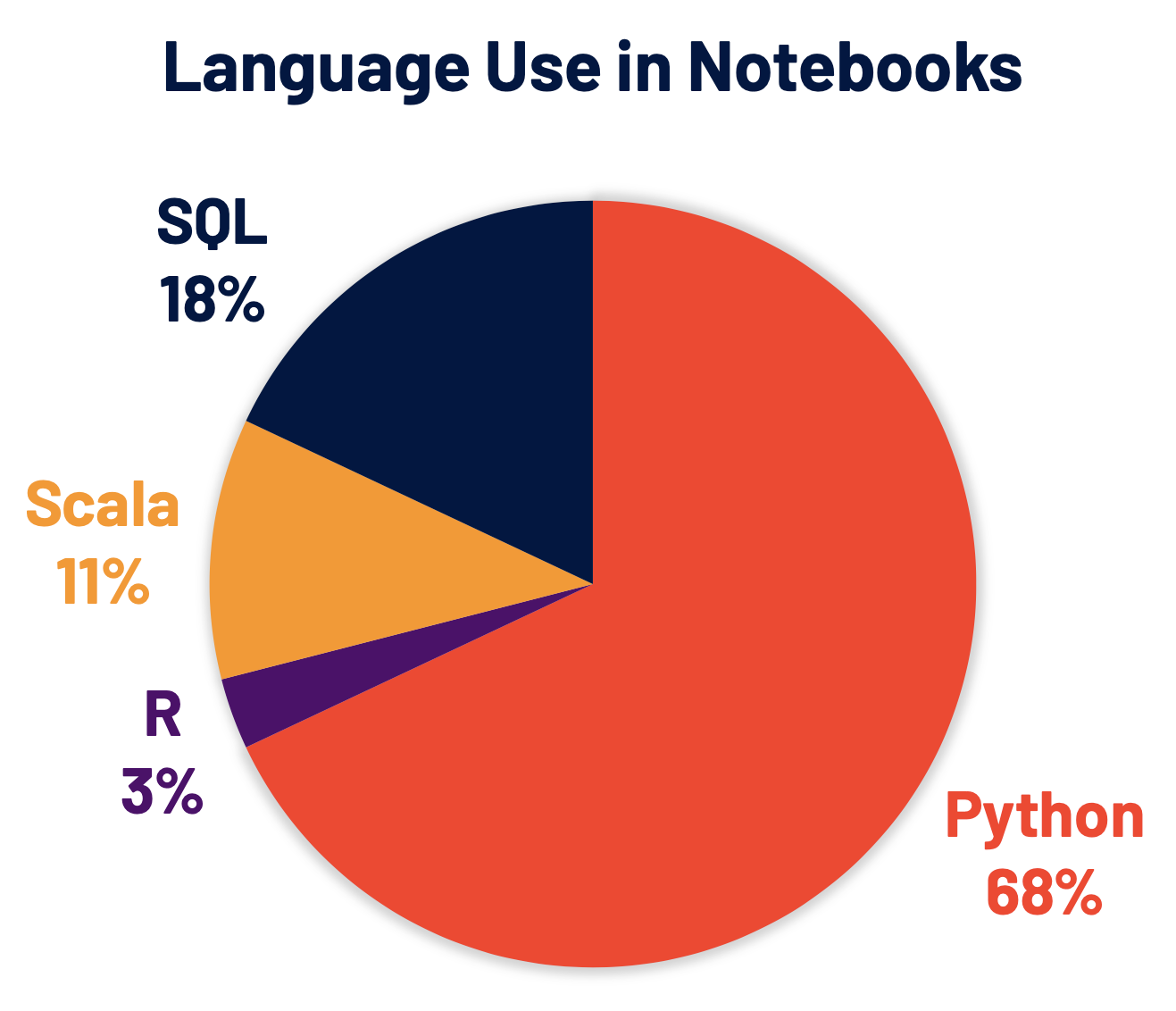
많은 Python 개발자가 데이터 구조 및 데이터 분석에 pandas API를 사용하지만, 이는 단일 노드 처리로 제한됩니다. 또한 Apache Spark 기반의 pandas API 구현인 Koalas를 지속적으로 개발하여 데이터 과학자들이 분산 환경에서 빅데이터로 작업할 때 생산성을 높일 수 있도록 지원하고 있습니다. Koalas는 클러스터 전반에서 효율적인 성능을 달성하기 위해 PySpark에 많은 함수(예: 플로팅 지원)를 빌드할 필요를 없애줍니다.
1년 이상의 개발 끝에 pandas용 Koalas API 커버리지는 80%에 육박했습니다. Koalas의 월간 PyPI 다운로드 수는 850,000건으로 빠르게 증가했으며, Koalas는 2주 릴리스 주기로 빠르게 발전하고 있습니다. Koalas가 단일 노드 pandas 코드에서 마이그레이션하는 가장 쉬운 방법일 수 있지만, 많은 분들이 여전히 인기가 높아지고 있는 PySpark API를 사용하고 있습니다.
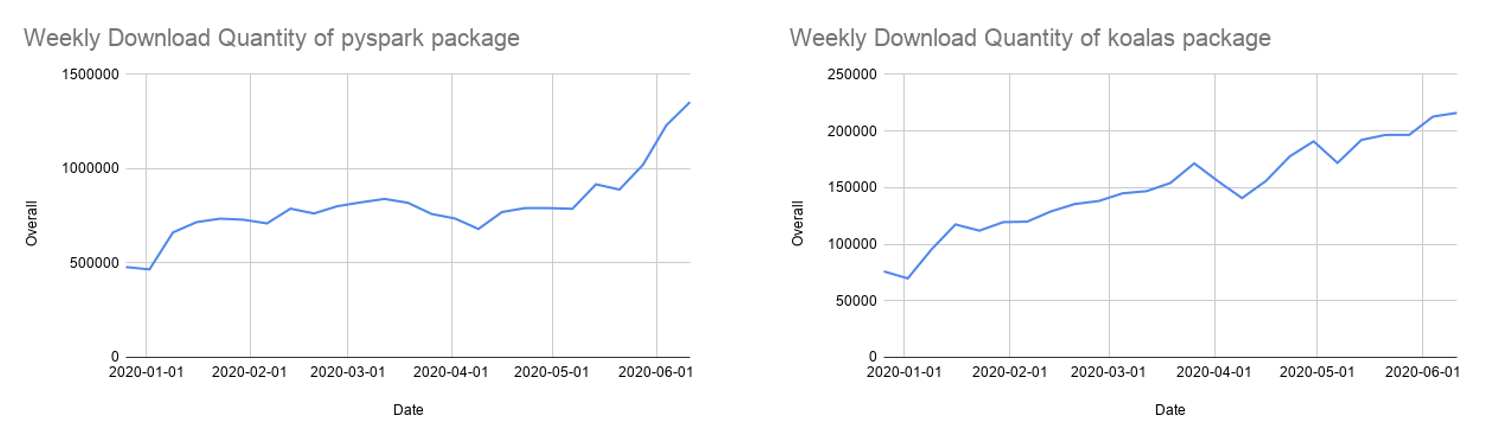
Spark 3.0은 PySpark API에 다음과 같은 몇 가지 향상된 기능을 제공합니다.
- 타입 힌트가 포함된 새로운 pandas API: pandas UDF는 PySpark에서 사용자 정의 함수를 확장하고 pandas API를 PySpark 애플리케이션에 통합하기 위해 Spark 2.3에서 처음 도입되었습니다. 하지만 더 많은 UDF 유형이 추가될 경우 기존 인터페이스는 이해하기 어렵습니다. 이번 릴리스에서는 늘어나는 Pandas UDF 유형에 대처하기 위해 Python 유형 힌트를 활용하는 새로운 Pandas UDF 인터페이스를 도입합니다. 새로운 인터페이스는 더욱 Pythonic해지고 자체 설명이 가능해집니다.
- 새로운 유형의 pandas UDF 및 pandas 함수 API: 이번 릴리스에는 series의 반복자에서 series의 반복자로 및 여러 series의 반복자에서 series의 반복자로라는 두 가지 새로운 pandas UDF 유형이 추가되었습니다. 데이터 프리페칭 및 비용이 많이 드는 초기화에 유용합니다. 또한 map 및 co-grouped map 이라는 두 가지 새로운 pandas 함수 API가 추가되었습니다. 자세한 내용은 이 블로그 게시물에서 확인할 수 있습니다.
- 개선된 오류 처리: PySpark 오류 처리가 Python 사용자에게 항상 친화적인 것은 아닙니다. 이번 릴리스는 PySpark 예외를 단순화하고 불필요한 JVM 스택 추적을 숨기며 더 Pythonic하게 만듭니다.
Spark에서 Python 지원 및 사용성을 개선하는 것은 계속해서 저희의 최우선 과제 중 하나입니다.
Hydrogen, 스트리밍 및 확장성
Spark 3.0을 통해 Project Hydrogen의 주요 구성 요소를 완성했으며, 스트리밍과 확장성을 개선하기 위한 새로운 기능도 도입했습니다.
- 가속기 인식 스케줄링: Project Hydrogen은 Spark에서 딥 러닝과 데이터 처리를 더 잘 통합하기 위한 주요 Spark 이니셔티브입니다. GPU 및 기타 가속기는 딥 러닝 워크로드 가속화를 위해 널리 사용되어 왔습니다. Spark가 대상 플랫폼에서 하드웨어 가속기를 활용할 수 있도록, 이번 릴리스에서는 클러스터 관리자가 가속기를 인식하도록 기존 스케줄러를 향상시켰습니다. 사용자는 검색 스크립트의 도움을 받아 구성을 통해 가속기를 지정할 수 있습니다. 그런 다음 사용자는 새로운 RDD API를 호출하여 이러한 가속기를 활용할 수 있습니다.
- Structured Streaming을 위한 새로운 UI: Structured Streaming은 Spark 2.0에서 처음 도입되었습니다. Databricks 사용량이 전년 대비 4배 증가한 후, Databricks에서는 Structured Streaming으로 매일 5조 개 이상의 레코드가 처리됩니다. 이번 릴리스에는 이러한 스트리밍 작업을 검사하기 위한 새로운 전용 Spark UI가 추가되었습니다. 이 새로운 UI는 1) ��완료된 스트리밍 query 작업의 집계 정보와 2) 스트리밍 query에 대한 자세한 통계 정보의 두 가지 통계 세트를 제공합니다.
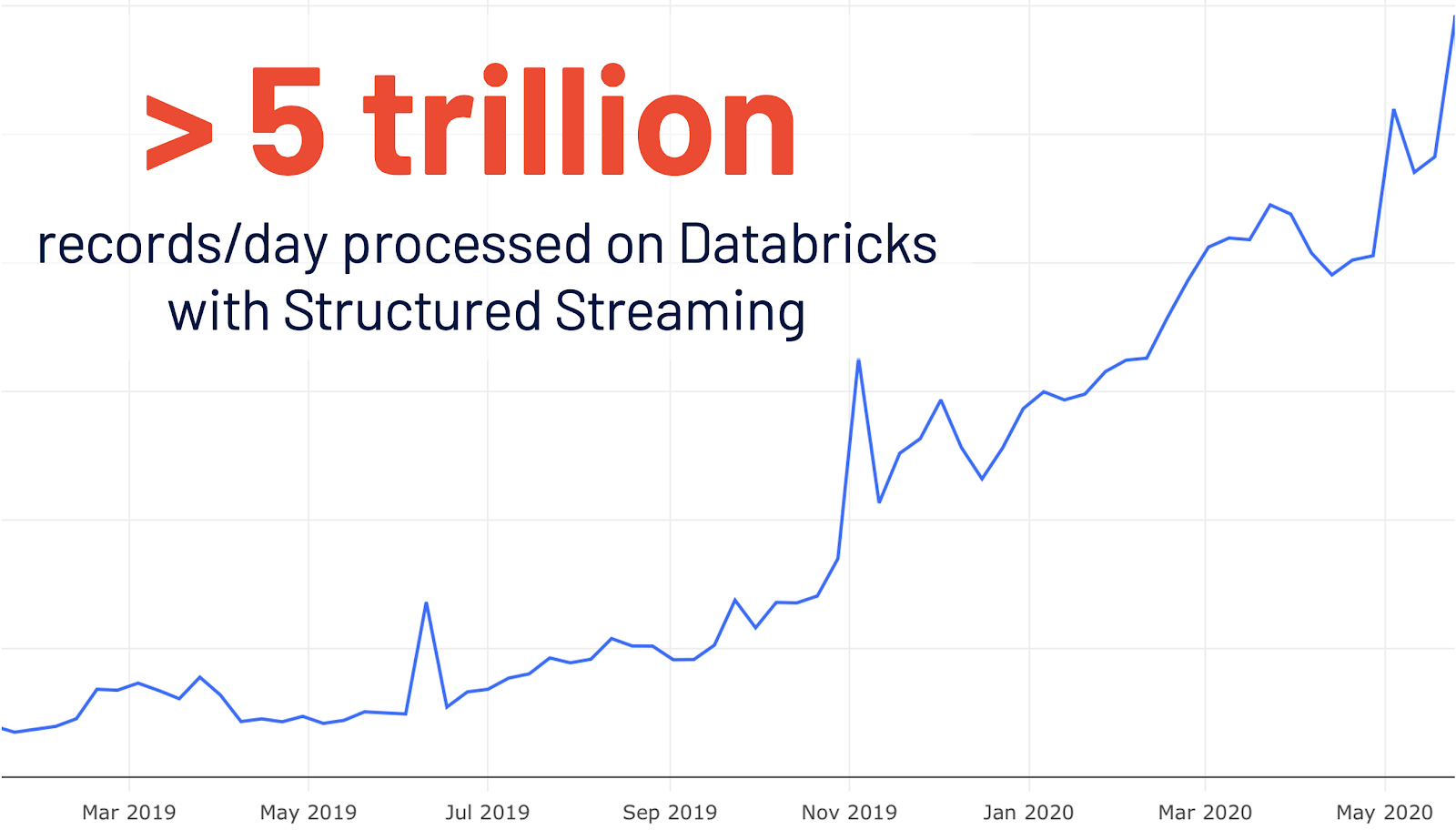
- 관찰 가능한 메트릭: 데이터 품질의 변화를 지속적으로 모니터링하는 것은 데이터 파이프라인 관리를 위한 매우 바람직한 기능입니다. 이번 릴리스는 배치 및 스트리밍 애플리케이션 모두에 대한 모니터링을 도입합니다. 관찰 가능한 메트릭은 쿼리(DataFrame)에 정의할 수 있는 임의의 집계 함수입니다. DataFrame 실행이 완료 지점(예: 배치 query 완료 또는 스트리밍 에포크 도달)에 도달하는 즉시, 마지막 완료 지점 이후 처리된 데이터에 대한 메트릭을 포함하는 명명된 이벤트가 생성됩니다.
- 새로운 카탈로그 플러그인 API: 기존 데이터 소스 API에는 외부 데이터 소스의 메타데이터에 액세스하고 조작하는 기능이 없습니다. 이번 릴리스는 데이터 소스 V2 API를 강화하고 새로운 카탈로그 플러그인 API를 도입했습니다. 카탈로그 플러그인 API와 데이터 소스 V2 API를 모두 구현하는 외부 데이터 소스의 경우, 해당 외부 카탈로그가 등록된 후 사용자는 다중 파트 식별자를 통해 외부 테이블의 데이터와 메타데이터를 직접 조작할 수 있습니다.
Spark 3.0의 기타 업데이트
Spark 3.0은 3,400개 이상의 Jira 티켓이 해결된 커뮤니티의 주요 릴리스입니다. 이는 Databricks, Google, Microsoft, Intel, IBM, Alibaba, Facebook, Nvidia, Netflix, Adobe 등�과 같은 기업은 물론 개인을 포함한 440명 이상의 기여자들이 참여한 결과입니다. 이 블로그 게시물에서는 Spark의 주요 SQL, Python 및 스트리밍 발전 사항을 중점적으로 다루었지만, 이번 3.0 마일스톤에는 여기서 다루지 않은 다른 많은 기능이 있습니다. 릴리스 노트 에서 자세한 내용을 알아보고 데이터 소스, 에코시스템, 모니터링 등을 포함한 Spark의 다른 모든 개선 사항을 확인해 보세요.
지금 바로 Spark 3.0을 시작해 보세요
Databricks Runtime 7.0에서 Apache Spark 3.0을 사용해 보려면 무료 체험 계정 에 가입하여 몇 분 안에 시작해 보세요. Spark 3.0 사용법은 클러스터를 시작할 때 '7.0' 버전을 선택하기만 하면 됩니다.
기능 및 출시 세부 정보에 대해 자세히 알아보세요.
- O’Reilly의 새로운 Learning Spark, 2판 무료 ebook 다운로드
- 적응형 쿼리 실행 블로그
- Pandas UDF 및 Python 유형 힌트 블로그
- Spark 3.0 Preview 온디맨드 웨비나
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.