곧 출시될 Apache Spark™ 3.2의 Pandas API
작성자: Hyukjin Kwon , Xinrong Meng
Free Edition이 Community Edition을 대체하여 향상된 기능을 무료로 제공합니다. 지금 바로 Free Edition 을 사용해 보세요.
pandas API가 곧 출시될 Apache Spark™ 3.2 릴리스에 포함된다는 기쁜 소식을 전합니다. pandas 는 강력하고 유연한 라이브러리로, 빠르게 성장하여 표준 데이터 과학 라이브러리 중 하나가 되었습니다. 이제 pandas 사용자는 기존 Spark 클러스터에서 pandas API를 활용할 수 있게 됩니다.
몇 년 전, 저희는 Spark를 기반으로 pandas DataFrame API를 구현하는 오픈 소스 프로젝트인 Koalas를 출시했으며, 이는 데이터 과학자들 사이에서 널리 채택되었습니다. 최근에 Koalas는 Project Zen 의 일부로 SPIP: PySpark의 pandas API 레이어 지원 을 통해 PySpark에 공식적으로 병합되었습니다(Data + AI Summit 2021의 Project Zen: PySpark에서 더 쉽게 데이터 과학하기 도 참조하세요).
pandas 사용자는 곧 출시될 Spark 3.2 릴리스에서 간단한 한 줄 변경으로 워크로드를 확장할 수 있게 됩니다.
이 블로그 게시물은 Spark 3.2에서의 pandas API 지원을 요약하고 주목할 만한 기능, 변경 사항 및 로드맵을 중점적으로 설명합니다.
단일 머신을 넘어서는 확장성
pandas의 알려진 한계 중 하나는 단일 머신 처리로 인해 데이터 볼륨에 따라 선형적으로 확장되지 않는다는 점입니다. 예를 들어 pandas는 단일 머신에서 사용 가능한 메모리보다 큰 데이터세트를 읽으려고 할 때 메모리 부족 오류가 발생합니다.
Spark의 pandas API는 한계를 극복하여 사용자가 Spark를 활용해 대규모 데이터 세트로 작업할 수 있도록 합니다.

Spark의 pandas API 또한 대규모 노드 클러스터로 잘 확장됩니다. 아래 차트는 다양한 크기의 클러스터로 15TB Parquet 데이터세트를 분석할 때의 성능을 보여줍니다. 클러스터의 각 머신에는 8개의 vCPU와 61GiB의 메모리가 있습니다.
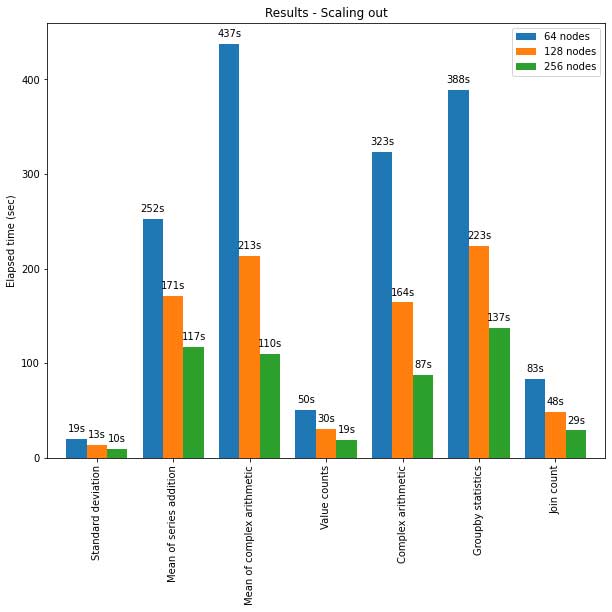
이 테스트에서 Spark의 pandas API 분산 실행은 거의 선형적으로 확장됩니다. 클러스터 내 머신 수가 두 배가 되면 경과 시간이 절반으로 줄어듭니다. 단일 머신에 비해 속도도 크게 향상됩니다. 예를 들어, 표준 편차 벤치마크에서 256개의 머신으로 구성된 클러스터는 거의 동일한 시간 내에 단일 머신보다 약 250배 더 많은 데이터를 처리할 수 있습니다(각 머신에는 8개의 vCPU와 61GiB의 메모리가 있음).
| 단일 머신 | 256개 머신 클러스터 | |
| Parquet 데이터 세트 | 60GB | 60GB x 250(15TB) |
| 표준 편차의 경과 시간(초) | 12초 | 10초 |
최적화된 단일 머신 성능
Spark의 pandas API는 Spark 엔진의 최적화 덕분에 단일 머신에서도 pandas보다 성능이 뛰어난 경우가 많습니다. 아래 차트는 130GB CSV 데이터세트에 대해 머신(96 vCPU 및 384GiB 메모리)에서 Spark의 pandas API를 pandas와 비교한 결과를 보여줍니다.
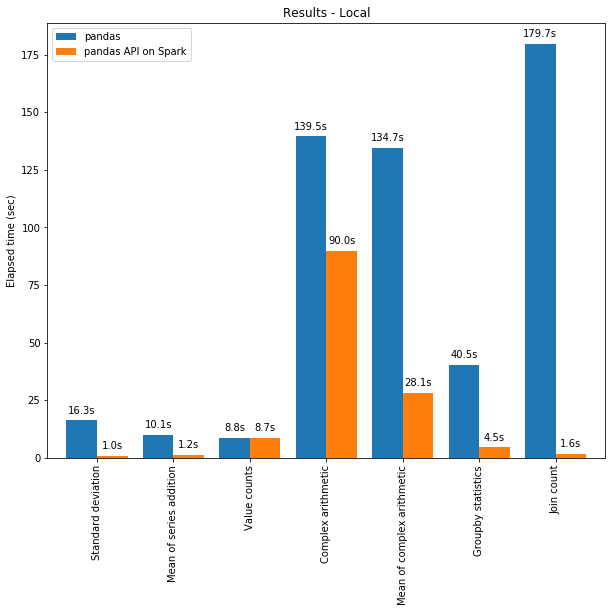
멀티스레딩과 Spark SQL Catalyst Optimizer 모두 최적화된 성능에 기여합니다. 예를 들어 Join count 연산은 전체 단계 코드 생성 시 약 4배 더 빠릅니다. 코드 생성 없이는 5.9초, 코드 생성 시에는 1.6초입니다.
Spark는 운영 체이닝에서 특히 상당한 이점이 있습니다. Catalyst 쿼리 옵티마이저는 필터를 인식하여 데이터를 현명하게 건너뛸 수 있고 디스크 기반 조인을 적용할 수 있는 반면, pandas는 단계별로 모든 데이터를 메모리에 로드하는 경향이 있습니다.
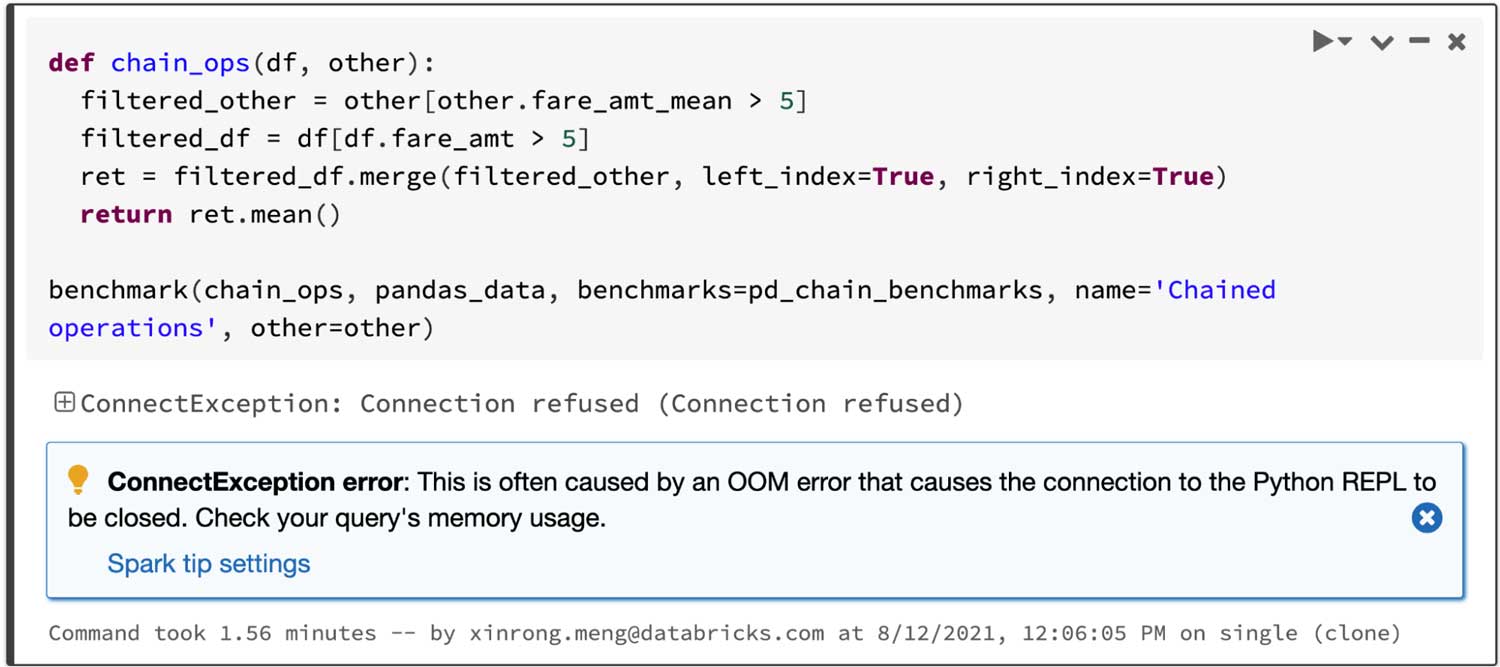
필터링된 두 프레임을 조인하고 조인된 프레임의 평균을 계산하는 쿼리의 경우 Spark의 pandas API는 4.5초 안에 성공하지만 pandas는 아래와 같이 OOM(메모리 부족) 오류로 인해 실패합니다.
인터랙티브 데이터 시각화
pandas는 기본적으로 정적 플롯 차트를 제공하는 matplotlib 을 사용합니다. 예를 들어, 아래 코드는 정적 차트를 생성합니다.
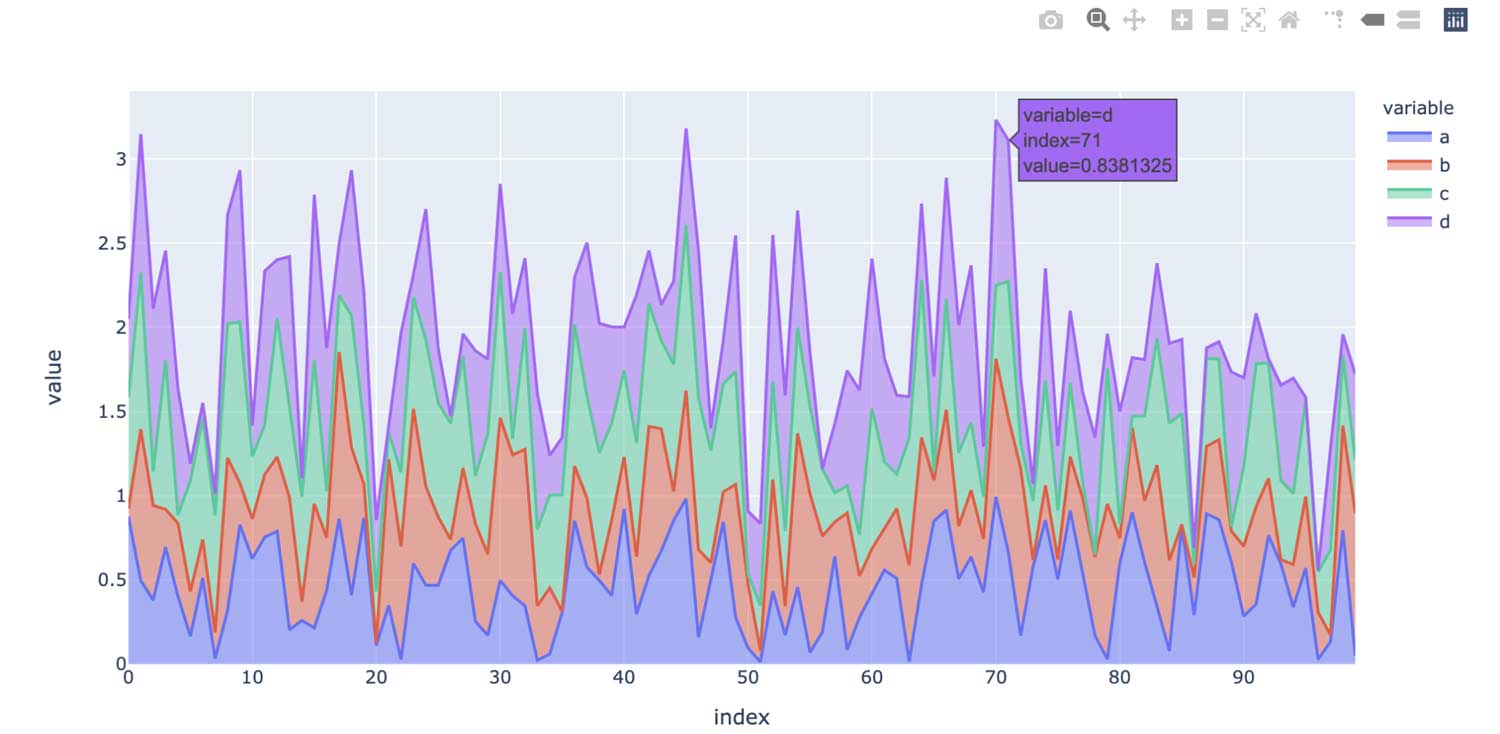
반면에 Spark의 pandas API는 인터랙티브 차트를 제공하는 plotly 백엔드를 기본으로 사용합니다. 예를 들어 사용자는 양방향으로 확대 및 축소할 수 있습니다. 플롯 유형에 따라 Spark의 pandas API는 대화형 차트를 생성할 때 내부적으로 계산을 실행하는 최적의 방법을 자동으로 결정합니다.
Spark에서 unified analytics 기능 활용
pandas는 배치 처리를 사용하는 Python 데이터 과학을 위해 설계되었으며, Spark는 SQL, 스트리밍 처리, 머신러닝을 포함한 통합 분석을 위해 설계되었습니다. 이 둘 사이의 격차를 해소하기 위해 pandas API on Spark는 고급 사용자가 Spark 엔진을 활용할 수 있도록 다음과 같은 다양한 방법을 제공합니다.
- 사용자는 아래와 같이 Spark의 최적화된 SQL 엔진을 사용하여 SQL로 데이터를 직접 쿼리할 수 있습니다.
- 또한 문자열 보간 구문을 지원하여 Python 객체와 자연스럽게 상호작용할 수 ��있습니다.
- Spark의 pandas API는 스트리밍 처리도 지원합니다.
- 사용자는 Spark의 확장 가능한 머신 러닝 라이브러리(MLlib)를 손쉽게 호출할 수 있습니다.
Spark의 PySpark와 pandas API 간의 상호 운용성에 대한 블로그 게시물 도 참조하세요.
다음은 무엇인가요?
다음 Spark 릴리스의 로드맵은 다음에 중점을 둡니다.
• 더 많은 타입 힌트
Spark의 pandas API 코드는 현재 부분적으로 타입이 지정되어 있어 정적 분석 및 자동 완성을 계속 사용할 수 있습니다. 향후에는 모든 코드에 전체 타입이 지정될 것입니다.
• 성능 개선
엔진 및 SQL 옵티마이저와 더 긴밀하게 상호 작용하여 Spark의 pandas API 여러 부분에서 성능을 더욱 개선할 수 있습니다.
• 안정화
특히 NaN 및 NA와 같은 결측값과 관련하여 동작 방식에 차이가 있는 코너 케이스 등 수정해야 할 부분이 몇 군데 있습니다.
또한 Spark의 pandas API는 이러한 경우 최신 pandas 버전에 맞게 동작을 따릅니다.
• API 지원 범위 확대
Spark의 pandas API는 pandas API의 83%를 지원하며, 이 수치는 계속 증가하고 있습니다. 이제 목표는 최대 90%입니다.
버그가 있거나 필요한 기능이 누락된 경우 이슈를 등록해 주세요. 물론 커뮤니티의 기여는 언제나 환영합니다.
시작하기
Databricks Runtime 10.0 Beta(곧 출시될 Apache Spark 3.2)에서 Spark의 pandas API를 사용해 보려면 Databricks Community Edition 또는 Databricks 평가판에 무료로 가입 하고 몇 분 안에 시작해 보세요.
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.