Delta Sharing을 통한 글로벌 데이터 협업 아키텍처 설계
여러 클라우드, 플랫폼, 리전 간에 데이터를 안전하고 효율적으로 공유하여 조직의 규모를 확장해 보세요.
작성자: Matei Zaharia, 빌랄 오베이다트, Tianyi Huang , 지젤 고이코체아
Delta Sharing이 에이전트 스킬, AI 모델, 비정형 데이터를 포함한 AI 자산을 안전하게 공유하기 위한 최초의 개방형 공급업체 중립적 프로토콜인 OpenSharing으로 진화했습니다. 발표 내용을 확인해 보세요.
오늘날과 같이 서로 연결된 디지털 환경에서 조직과 플랫폼 간의 데이터 공유 및 협업은 현대적인 비즈니스 운영에 필수적입니다. 혁신적인 개방형 데이터 공유 프로토콜인 Delta Sharing을 통해 조직은 특정 공급업체나 데이터 형식에 구애받지 않고 보안과 확장성을 최우선으로 하면서 다양한 플랫폼에서 데이터를 안전하게 공유하고 액세스할 수 있습니다.
이 블로그에서는 특정 데이터 공유 시나리오에 맞춤화된 아키텍처 가이드를 살펴보며 Delta Sharing 내의 데이터 복제 옵션을 소개하고자 합니다. 수많은 Delta Sharing 고객과의 경험에서 얻은 인사이트를 바탕으로, 구체적인 데이터 복제 대안을 제시하여 이그레스(egress) 비용을 절감하고 성능을 향상시키는 것이 목표입니다. 실시간 공유(live sharing)는 많은 리전 간 데이터 공유 시나리오에 여전히 적합하지만, 전체 데이터 세트를 복제하고 로컬 리전 복제본에 대한 데이터 새로 고침 프로세스를 구축하는 것이 더 비용 효율적인 경우도 있습니다. Delta Sharing은 Cloudflare R2 스토리지, Change Data Feed(CDF) Delta Sharing 및 Delta Deep Cloning 기능을 활용하여 이를 지원합니다. 이러한 기능 덕분에 Delta Sharing은 사용자에게 권한을 부여하고 데이터 공유 요구 사항을 충족하는 데 있어 뛰어난 유연성을 제공하여 고객들로부터 높은 평가를 받고 있습니다.
개방적이고 유연하며 비용 효율적인 Delta Sharing
Databricks와 Linux Foundation은 데이터, 분석 및 AI 전반에서 데이터 공유를 위한 최초의 오픈 소스 접근 방식을 제공하기 위해 Delta Sharing을 개발했습니다. 고객은 강력한 보안 및 거버넌스를 바탕으로 플랫폼, 클라우드, 리전 간에 실시간 데이터를 공유할 수 있습니다. 자체 호스팅을 통해 오픈 소스 프로젝트를 사용하든, Databricks에서 완전 관리형 Delta Sharing을 사용하든, 두 가지 모두 글로벌 데이터 전송을 위한 플랫폼 독립적이고 유연하며 비용 효율적인 솔루션을 제공합니다. Databricks 고객은 관리 오버헤드를 최소화하고 Databricks Unity Catalog와 기본적으로 통합되는 관리형 환경에서 추가적인 이점을 누릴 수 있습니다. 이러한 통합은 조직 내부 및 조직 간의 데이터 공유를 위한 간소화된 경험을 제공합니다.
Databricks 기반 Delta Sharing은 2022년 8월 정식 출시(GA)된 이후 다양한 협업 시나리오에서 널리 채택되어 왔습니다.
이 블로그에서는 Delta Sharing이 중요한 비즈니스 시나리오를 지원하고 강화하는 데 중추적인 역할을 한 두 가지 일반적인 아키텍처 패턴을 살펴보겠습니다.
- 기업 내부의 리전 간 데이터 공유
- 데이터 애그리게이터(허브 앤 스포크) 모델
또한 이 블로그를 통해 Delta Sharing 배포 아키텍처가 유연하며 새로운 데이터 공유 요구 사항을 충족하기 위해 원활하게 확장될 수 있음을 보여드릴 것입니다.
기업 내부의 리전 간 데이터 공유
이 사용 사례에서는 서로 다른 리전에 QA 팀이 있거나 글로벌 기준의 비즈니스 활동 데이터에 관심이 있는 보고 팀이 있는 경우와 같이, 리전 간에 일부 데이터를 공유해야 하는 비즈니스 요구 사항이 있을 때 고객들 사이에서 흔히 나타나는 Delta Sharing 배포 패턴을 설명합니다. 일반적으로 기업 내부 테이블 공유에는 다음과 같은 작업이 포함됩니다.
- 대용량 테이블 공유: 액세스 패턴이 다양한 수신자와 대용량 테이블을 실시간으로 공유해야 하는 요구 사항이 있습니다. 수신자는 종종 서로 다른 조건자(predicate)를 사용하여 다양한 쿼리를 실행합니다. 좋은 예로 클릭스트림 및 사용자 활동 데이터가 있으며, 이러한 경우에는 원격 액세스가 더 적합합니다.
- 로컬 복제: 성능을 향상시키고 이그레스 비용을 더 잘 관리하기 위해, 특히 수신자 리전에 이러한 테이블에 자주 액세스하는 사용자가 많은 경우 데이터를 복제하여 데이터의 로컬 복사본을 만들어야 합니다.
이 시나리오에서는 데이터 제공자와 데이터 수신자의 비즈니스 부서가 동일한 Unity Catalog 계정을 공유하지만, Databricks에서 서��로 다른 메타스토어를 가집니다.
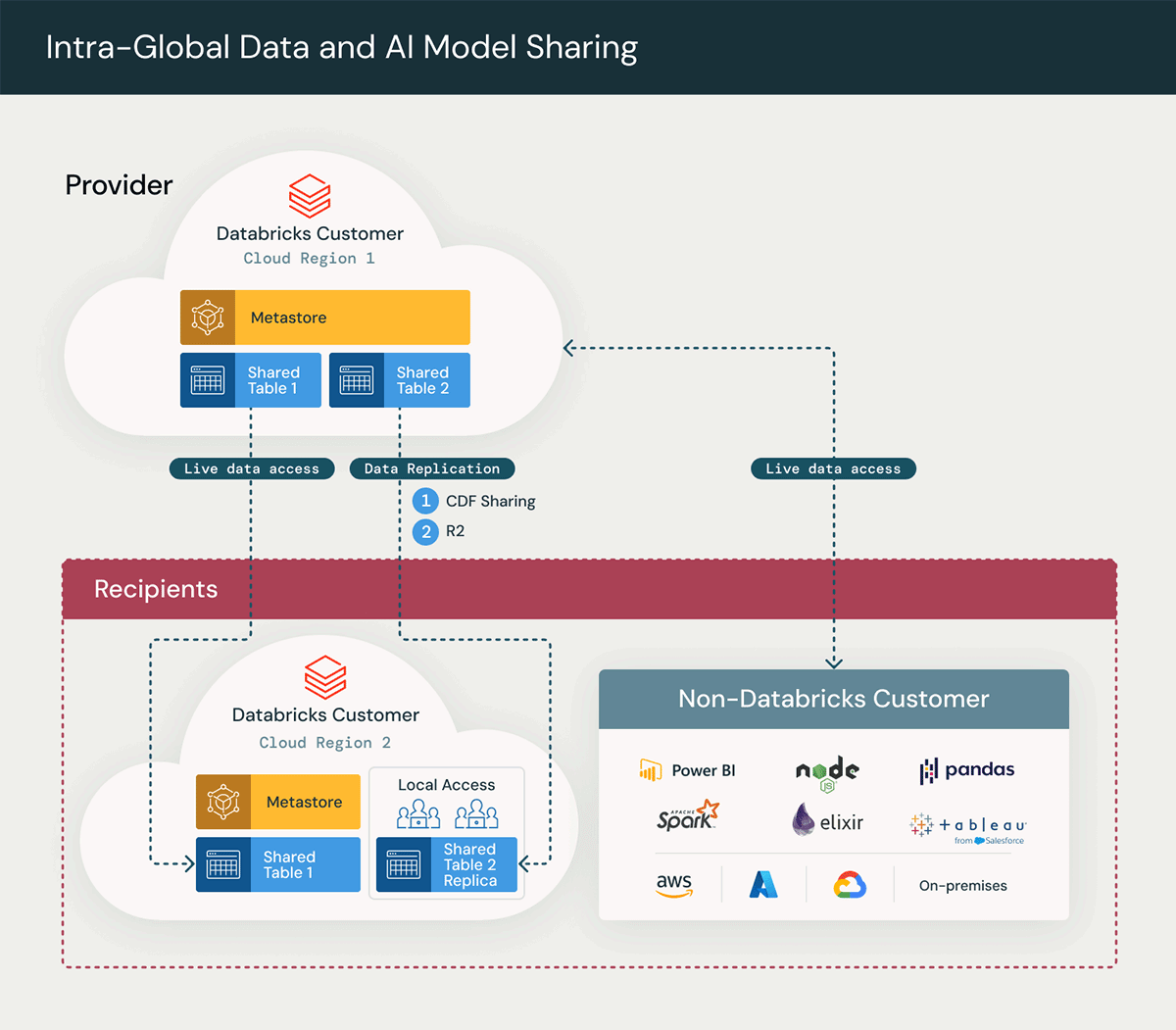
위 다이어그램은 Delta Sharing 프로세스의 주요 단계를 강조하는 Delta Sharing 솔루션의 상위 수준 아키텍처를 보여줍니다.
- 공유 생성: 실시간 테이블이 수신자와 공유되어 즉각적인 데이터 액세스가 가능해집니다.
- 온디맨드 데이터 복제: 온디맨드 데이터 복제를 구현하려면 성능을 향상시키고 리전 간 네트워크 액세스의 필요성을 줄이며 관련 이그레스 비용을 최소화하기 위해 데이터의 리전별 복제본을 생성해야 합니다. 이는 다음과 같은 데이터 복제 방식을 활용하여 달성됩니다.
A. 공유 테이블의 Change Data Feed
이 옵션을 사용하려면 테이블 기록을 공유하고 CDF(Change Data Feed)를 활성화해야 합니다. 이는 Create/Alter table 명령을 사용하여 테이블 속성을 delta.enableChangeDataFeed = true로 설정함으로써 설정 코드에서 명시적으로 활성화해야 합니다.
또한 아래 예시와 같이 테이블을 공유(Share)에 추가할 때 CDF 옵션과 함께 추가되었는지 확인하세요.
데이터가 추가되거나 업데이트되면 이 예시와 같이 변경 사항에 액세스할 수 있습니다.
수신자 측에서는 이 노트북에서와 유�사한 방식으로 변경 사항에 액세스하고 데이터의 로컬 복사본에 병합할 수 있습니다. 공유 테이블의 변경 사항을 로컬 복제본으로 전파하는 작업은 Databricks 워크플로 작업을 사용하여 오케스트레이션할 수 있습니다.
B. Databricks와 Cloudflare R2
R2는 고객이 예측할 수 없는 이그레스 비용에 대해 걱정할 필요 없이 공유의 잠재력을 완전히 실현할 수 있기 때문에 모든 Delta Sharing 시나리오에 탁월한 옵션입니다. 이에 대해서는 이 블로그의 뒷부분에서 자세히 설명합니다.
C. Delta Deep Clone
동일한 Databricks 클라우드 계정 내에서 공유할 때 기업 내부 공유를 위한 또 다른 특별한 옵션은 Delta Deep Clone을 사용하는 것입니다. Deep Cloning은 원본 테이블 데이터와 기존 테이블의 메타데이터를 모두 클론 대상으로 복사하는 Delta 기능입니다. 또한 deep clone 명령에는 새 데이터를 식별하고 그에 따라 새로 고치는 기능이 있습니다. 구문은 다음과 같습니다.
이전 명령은 수신자 측에서 실행되며, 여기서 source_table_name는 공유 테이블이고 table_name는 사용자가 액세스할 수 있는 데이터의 로컬 복사본입니다.
다음 명령을 사용하여 최근 업데이트로 데이터를 증분 새로 고침하도록 간단한 Databricks Workflows 작업을 예약할 수 있습니다.
동일한 사용 사례를 Databricks 플랫폼 또는 기타 플랫폼의 외부 파트너 및 고객과 데이터를 공유하도록 쉽게 확장할 수 있습니다. 이는 Databricks를 사용하지 않는 파트너 및 외부 고객이 Excel, Power BI, Pandas 및 Oracle과 같은 기타 호환 소프트웨어를 통해 이 데이터에 액세스하고자 하는 또 다른 일반적인 확장 패턴입니다.
데이터 애그리게이터 모델(허브 앤 스포크 모델)
또 다른 일반적인 시나리오 패턴은 비즈니스가 고객과의 데이터 공유에 초점을 맞추고 있을 때 발생하며, 특히 데이터 애그리게이터 기업이 포함되거나 주요 비즈니스 기능이 고객을 대신하여 데이터를 수집하는 경우에 그렇습니다. 데이터 애그리게이터는 다양한 소스에서 데이터를 수집하고 병합하여 일관성 있는 단일 데이터 세트로 만드는 것을 전문으로 하는 주체입니다. 이러한 데이터 공유는 비즈니스 의사 결정, 시장 분석, 연구 및 전반적인 비즈니스 운영 지원과 같은 다양한 비즈니스 요구 사항을 충족하는 데 중요한 역할을 합니다.
이 패턴의 데이터 공유 모델은 다음을 수행합니다.
- AWS, Azure, GCP를 포함하여 다양한 클라우드에 분산되어 있는 수신자를 연결합니다.
- Python 코드부터 Excel 스프레드시트에 이르기까지 다양한 복잡성의 플랫폼에서 데이터 소비를 지원합니다.
- 수신자 수, 공유 수 및 데이터 볼륨에 대한 확장성을 제공합니다.
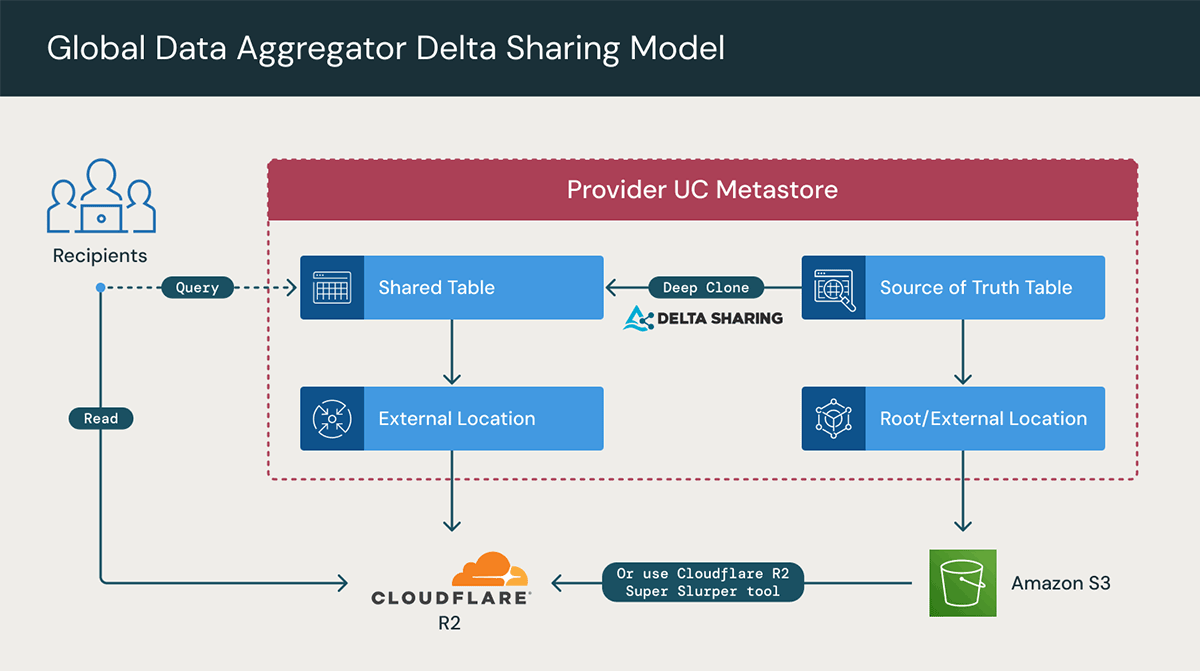
일반적으로 이는 제공업체가 각 클라우드에 Databricks 워크스페이스를 구축하고, 성능을 향상시키고 송신(egress) 비용을 줄이기 위해 세 클라우드 전체에서 공유 테이블의 CDF를 사용하여 데이터를 복제함으로써 달성할 수 있습니다(위에서 설명한 바와 같이). 그런 다음 각 클라우드 리전 내에서 적절한 고객 및 파트너와 데이터를 공유할 수 있습니다.
하지만 현재 비공개 프리뷰(private preview)로 제공되는 Databricks와 Cloudflare R2를 활용하면 새롭고 더 효율적이며 간단한 접근 방식을 사용할 수 있습니다.
Cloudflare R2와 Databricks의 통합을 통해 조직은 안전하고 간단하며 저렴한 비용으로 라이브 데이터를 공유하고 협업할 수 있습니다. Cloudflare와 Databricks를 통해 양사 공동 고객은 멀티 클라우드 분석 및 AI 이니셔티브의 잠재력을 최대한 발휘하는 데 방해가 되는 복잡성과 유동적인 비용을 제거할 수 있습니다. 특히 송신(egress) 수수료가 전혀 발생하지 않으며, 복잡한 데이터 전송이나 리전 간 데이터 세트의 비용이 많이 드는 복제가 필요하지 않습니다.
이 옵션을 사용하려면 다음 단계가 필요합니다:
- Cloudflare R2를 외부 스토리지 위치로 추가합니다(단, 신뢰할 수 있는 단일 원천(source of truth) 데이터는 S3/ADLS 등에 유지).
- Cloudflare R2에 새 테이블을 생성하고 데이터를 점진적으로 동기화합니다.
- Delta deep clone
- R2 Super Slurper
- ��평소와 같이 R2 테이블에 Delta Share를 생성합니다.
위에서 설명한 바와 같이, 이러한 접근 방식은 온디맨드 데이터 복제의 다양한 방법을 보여주며, 각 방법은 고유한 장점과 특정 요구 사항을 가지고 있어 다양한 사용 사례에 적합합니다.
리전 간 공유를 위한 데이터 복제 방법 비교
이전의 세 가지 메커니즘 모두 Delta Sharing 사용자가 로컬 복사본을 생성하여 특히 클라우드 및 리전 간의 송신(egress) 수수료를 최소화할 수 있도록 합니다. 아래 표는 이러한 옵션을 구분할 수 있는 빠른 요약을 제공합니다.
| 데이터 복제 도구 | 주요 특징 | 권장 사항 |
|---|---|---|
| 공유 테이블의 변경 데이터 피드(Change data feed) |
| 리전 간 파트너/고객과의 외부 공유에 사용 |
| Databricks와 Cloudflare R2 |
| 공유 수 및 2개 이상의 리전 측면에서 대규모 Delta Sharing에 강력히 권장됨 |
| Delta Deep Clone |
| 리전 간 내부적으로 공유할 때 권장됨 |
Delta Sharing은 개방적이고 유연하며 비용 효율적이며, Databricks에서는 노트북, 볼륨, AI 모델을 포함한 광범위한 데이터 자산을 지원합니다. 또한 몇 가지 최적화를 통해 Delta Sharing 프로토콜의 성능이 크게 향상되었습니다. 개선된 모니터링, 확장성, 사용 편의성, 관찰 가능성(observability)을 포함하여 Delta Sharing 기능에 대한 Databricks의 지속적인 투자는 사용자 경험을 향상시키고 Delta Sharing이 미래의 데이터 협업 분야에서 선두를 유지할 수 있도록 하겠다는 약속을 강조합니다.
다음 단계
이 블로그 전반에 걸쳐 당사는 많은 Delta Sharing 고객과의 경험을 바탕으로 아키텍처 가이드를 제공했습니다. 당사의 주된 초점은 비용 관리와 성능에 있습니다. 라이브 공유는 많은 리전 간 데이터 공유 시나리오에 적합하지만, 전체 데이터 세트를 복제하고 로컬 리전 복제본에 대한 데이터 새로 고침 프로세스를 구축�하는 것이 더 비용 효율적인 사례도 살펴보았습니다. Delta Sharing은 R2 및 CDF Delta Sharing 기능을 활용하여 이를 용이하게 함으로써 사용자에게 향상된 유연성을 제공합니다.
기업 내부 리전 간 데이터 공유(Intra-Enterprise Cross-Regional Data Sharing) 사용 사례에서 Delta Sharing은 다양한 액세스 패턴을 가진 대형 테이블을 공유하는 데 탁월한 성능을 발휘합니다. CDF 공유를 통해 촉진되는 로컬 복제는 최적의 성능과 비용 관리를 보장합니다. 또한 Databricks와 Cloudflare R2를 활용하면 여러 리전 및 클라우드에 걸친 대규모 Delta Sharing을 위한 효율적인 옵션을 제공합니다.
데이터 협업 전략에 Delta Sharing을 통합하는 방법에 대해 자세히 알아보려면 최신 리소스를 확인해 보세요:
- O'Reilly 기술 가이드인 Data Sharing and Collaboration with Delta Sharing 읽기 (초기 릴리스)
- Databricks Delta Sharing 문서를 자세히 살펴보세요.
- Delta Sharing에 대해 자세히 알아보기: 안전한 데이터 공유를 위한 개방형 표준
- Matei Zaharia와 함께하는 Delta Sharing 발표 동영상 시청 (Keynote Data + AI Summit 2021)
(이 글은 AI의 ��도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.