혼돈에서 확장으로: DLT-META를 사용한 Spark 선언적 파이프라인 템플릿화
대규모로 일관되고 자동화되고 통제되는 파이프라인을 구축하기 위한 메타데이터 프레임워크
작성자: Ravi Gawai , 피비 와이저
- 데이터 파이프라인을 확장하면 여러 팀에 걸쳐 오버헤드, 드리프트, 일관성 없는 로직이 발생합니다.
- 이러한 격차는 제공 속도를 늦추고 유지 관리 비용을 증가시키며 공유 표준을 적용하기 어렵게 만듭니다.
- 이 블로그에서는 메타데이터 기반 메타프로그래밍이 중복을 제거하고 대규모로 일관된 자동화 데이터 파이프라인을 구축하는 방법을 보여줍니다.
선언적 파이프라인은 팀이 배치 및 스트리밍 워크플로를 빌드할 수 있는 의도 기반 방식을 제공합니다. 수행할 작업을 정의하면 시스템이 실행을 관리합니다. 이를 통해 사용자 지정 코드를 줄이고 반복 가능한 엔지니어링 패턴을 지원합니다.
조직의 데이터 사용량이 증가함에 따라 파이프라인도 늘어납니다. 표준이 발전하고, 새로운 소스가 추가되며, 더 많은 팀이 개발에 참여합니다. 작은 스키마 업데이트조차 수십 개의 노트북과 구성에 영향을 미칩니다. 메타데이터 기반 메타프로그래밍은 파이프라인 로직을 런타임에 생성되는 구조화된 Template으로 전환하여 이러한 문제를 해결합니다.
이 접근 방식은 개발 일관성을 유지하고 유지 관리를 줄이며 제한된 엔지니어링 노력으로 확장됩니다.
이 블로그에서는 Databricks Labs의 프로젝트인 DLT-META를 사용하여 Spark 선언적 파이프라인용 메타데이터 기반 파이프라인을 구축하는 방법을 알아봅니다. DLT-META는 메타데이터 템플릿을 적용하여 파이프라인 생성을 자동화합니다.
선언적 파이프라인은 유용하지만, 팀이 더 많은 소스를 ��추가하고 조직 전체로 사용을 확대하면 이를 지원하는 데 필요한 작업이 급격히 증가합니다.
수동 파이프라인을 대규모로 유지 관리하기 어려운 이유
수동 파이프라인은 소규모에서는 작동하지만 유지보수 노력은 데이터 자체보다 더 빠르게 증가합니다. 새로운 소스가 추가될 때마다 복잡성이 증가하여 로직 드리프트 및 재작업으로 이어집니다. 팀은 파이프라인을 개선하는 대신 결국 패치하게 됩니다. 데이터 엔지니어는 다음과 같은 확장성 문제에 지속적으로 직면합니다.
- 소스당 너무 많은 아티팩트: 각 데이터 세트에는 새로운 노트북, 구성 및 스크립트가 필요합니다. 피드가 추가될 때마다 운영 오버헤드가 빠르게 증가합니다.
- 로직 업데이트가 전파되지 않음: 비즈니스 규칙 변경사항이 파이프라인에 적용되지 않아 구성 드리프트 및 파이프라인 간 일관성 없는 출력이 발생합니다.
- 일관성 없는 품질 및 거버넌스: 팀은 맞춤형 검사 및 리니지를 구축하여 조직 전체의 표준을 시행하기 어렵게 만들고 결과의 변동성이 매우 커집니다.
- 도메인 팀의 제한된 안전한 기여: 애널리스트와 비즈니스 팀은 데이터를 추가하고 싶어하지만, 데이터 엔지니어링 팀이 여전히 로직을 검토하거나 다시 작성해야 하므로 전달 속도가 느려집니다.
- 변경할 때마다 유지보수 증가: 간단한 스키마 조정이나 업데이트로 인해 모든 종속 파이프라인에 걸쳐 막대한 수동 작업 백로그가 발생하여 플랫폼의 민첩성이 저하됩니다.
이러한 문제들은 메타데이터 우선 접근 방식이 왜 중요한지를 보여줍니다. 수동 작업을 줄이고 파이프라인이 확장�될 때 일관성을 유지해 줍니다.
DLT-META가 확장성 및 일관성을 해결하는 방법
DLT-META는 파이프라인 규모 및 일관성 문제를 해결합니다. Spark 선언적 파이프라인을 위한 메타데이터 기반 메타프로그래밍 프레임워크입니다. 데이터 팀은 이를 사용하여 최소한의 코드로 파이프라인 생성을 자동화하고, 로직을 표준화하며, 개발을 확장합니다.
메타프로그래밍을 사용하면 파이프라인 동작이 반복되는 노트북이 아닌 구성에서 파생됩니다. 이는 팀에 명확한 이점을 제공합니다.
- 작성 및 유지보수할 코드가 줄어듭니다
- 새로운 데이터 소스의 더 빠른 온보딩
- 처음부터 프로덕션에 즉시 사용 가능한 파이프라인
- 플랫폼 전반에 걸친 일관된 패턴
- 린 팀을 통한 확장 가능한 모범 사례
Spark Declarative 파이프라인과 DLT-META는 함께 작동합니다. Spark Declarative 파이프라인은 의도를 정의하고 실행을 관리합니다. DLT-META는 파이프라인 로직을 생성하고 확장하는 구성 레이어를 추가합니다. 이 둘이 결합되어 거버넌스, 효율성, 대규모 성장을 지원하는 반복 가능한 패턴으로 수동 코딩을 대체합니다.
DLT-META가 실제 데이터 엔지니어링 요구사항을 해결하는 방법
1. 중앙 집중식 및 템플릿화된 구성
DLT-META는 공유 템플릿에서 파이프라인 로직을 중앙 집중화하여 중복과 수동 유지 관리를 제거합니다. 팀은 JSON 또는 YAML을 사용하여 공유 메타데이터에서 수집, 변환, 품질 및 거버넌스 규칙을 정의합니다. 새 소스가 추가되거나 규칙이 변경되면 팀은 구성을 한 번만 업데이트합니다. 로직이 파이프라인 전반에 자동으로 전파됩니다.
2. 즉각적인 확장성과 더 빠른 온보딩
메타데이터 기반 업데이트를 통해 파이프라인을 쉽게 확장하고 새로운 소스를 온보딩할 수 있습니다. 팀은 메타데이터 파일을 편집하여 소스를 추가하거나 비즈니스 규칙을 조정합니다. 변경 사항은 수동 개입 없이 모든 다운스트림 워크로드에 적용됩니다. 새로운 소스가 몇 주가 아닌 몇 분 만에 프로덕션으로 이동합니다.
3. 강화된 표준에 따른 도메인 팀 기여
DLT-META를 사용하면 도메인 팀이 구성을 통해 안전하게 기여할 수 있습니다. 애널리스트와 도메인 전문가는 메타데이터를 업데이트하여 제공 속도를 높입니다. 플랫폼 및 엔지니어링 팀은 유효성 검사, 데이터 품질, 변환 및 규정 준수 규칙에 대한 제어권을 유지합니다.
4. 전사적 일관성 및 거버넌스
조직 전체의 표준이 모든 파이프라인과 소비자에 자동으로 적용됩니다. 중앙 구성은 모든 새로운 소스에 일관된 논리를 적용합니다. 기본 내장 감사, 리니지 및 데이터 품질 규칙은 대규모의 규제 및 운영 요구 사항을 지원합니다.
팀이 실제 업무에서 DLT-META를 사용하는 방법
고객은 DLT-META를 사용하여 수집 및 변환을 한 번 정의하고 구성을 통해 이를 적용하고 있습니다. 이를 통해 사용자 지정 코드가 줄어들고 온보딩 속도가 빨라집니다.
Cineplex는 즉각적인 효과를 보았습니다.
커스텀 코드를 최소화하기 위해 DLT-META를 사용합니다. 엔지니어는 더 이상 간단한 작업을 위해 파이프라인을 다르게 작성하지 않습니다. 온보딩 JSON 파일은 일관된 프레임워크를 적용하고 나머지를 처리합니다.—Aditya Singh, Cineplex 데이터 엔지니어
PsiQuantum은 소규모 팀이 효율적으로 확장하는 방법을 보여줍니다.
DLT-META는 적은 유지보수로 브론즈 및 실버 워크로드를 관리하는 데 도움이 됩니다. 중복된 노트북이나 소스 코드 없이 대용량 데이터를 지원합니다.—Arthur Valadares, PsiQuantum 수석 데이터 엔지니어
산업 전반에 걸쳐 팀들은 동일한 패턴을 적용합니다.
- 소매 는 수백 개의 소스에서 가져온 매장 및 공급망 데이터를 중앙 집중화합니다.
- 물류 는 IoT 및 차량 데이터에 대한 배치 및 스트리밍 수집을 표준화합니다.
- 금융 서비스 는 피드를 더 빠르게 온보딩하면서 감사 및 규정 준수를 강화합니다.
- 의료 는 복잡한 데이터 세트 전반에 걸쳐 품질과 감사 가능성을 유지합니다.
- 제조 및 통신 분야 에서 재사용 가능하고 중앙에서 관리되는 메타데이터를 사용하여 수집 규모를 확장합니다.
이 접근 방식을 통해 팀은 복잡성을 늘리지 않고 파이프라인 수를 늘릴 수 있습니다.
5가지 간단한 단계로 DLT-META 시작하기
DLT-META를 사용하기 위해 플랫폼을 재설계할 필요가 없습니다. 작게 시작하세요. 몇 개의 소스를 사용하세요. 메타데이터가 나머지를 주도하도록 하세요.
1. 프레임워크 가져오기
DLT-META 리포지토리를 복제하여 시작하세요. 이를 통해 메타데이터를 사용하여 파이프라인을 정의하는 데 필요한 템플릿, 예시 및 툴링을 얻을 수 있습니다.
2. 메타데이터로 파이프라인 정의하기
다음으로, 파이프라인이 수행할 작업을 정의합니다. 이 작업은 소규모 구성 파일 세트를 편집하여 수행합니다.
- conf/onboarding.json 을 사용하여 원시 입력 테이블을 설명합니다.
- 변환을 정의하려면 conf/silver_transformations.json 을 사용하세요.
- 데이터 품질 규칙을 적용하려면 선택적으로 conf/dq_rules.json 을 추가하세요.
이 시점에서 의도를 설명하고 있습니다. 사용자는 파이프라인 코드를 작성하는 것이 아닙니다.
3. 플랫폼에 메타데이터를 온보딩합니다.
파이프라인이 실행되기 전에 DLT-META는 사용자의 메타데이터를 등록해야 합니다. 이 온보딩 단계에서는 사용자의 구성을 파이프라인이 런타임에 읽는 Dataflowspec 델타 테이블로 변환합니다.
Notebook, Lakeflow 작업 또는 DLT-META CLI에서 온보딩을 실행할 수 있습니다.
a. 노트북을 통한 수동 온보딩 예: 여기
제공된 온보딩 노트북을 사용하여 메타데이터를 처리하고 파이프라인 아티팩트를 프로비저닝하세요.
b. Python wheel로 Lakeflow Jobs에서 온보딩을 자동화합니다.
아래 예시는 Lakeflow Jobs UI를 사용하여 DLT-META 파이프라인을 생성하고 자동화하는 방법을 보여줍니다.
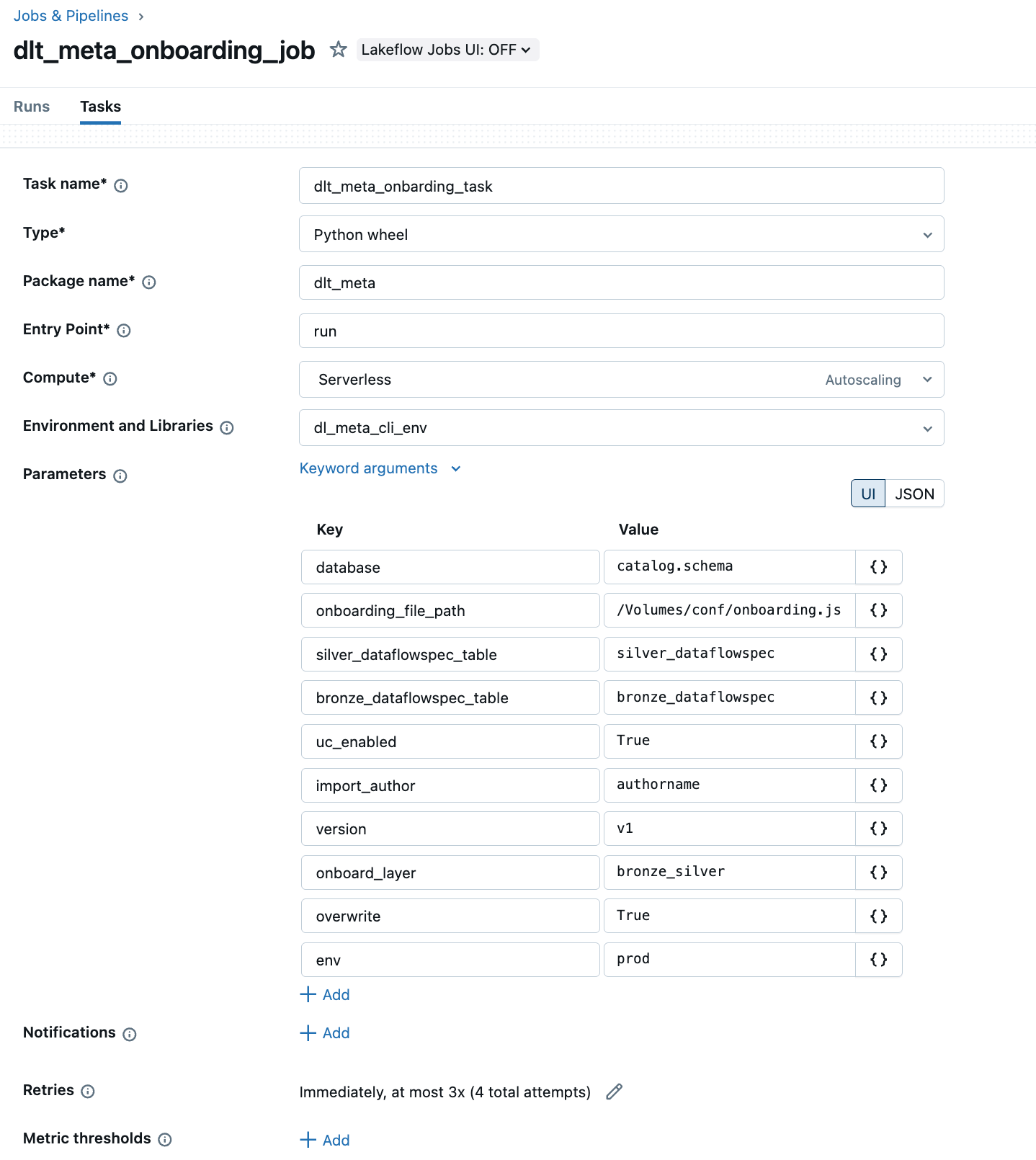
c. 리포지토리에 표시된 DLT-META CLI 명령을 사용하여 온보딩: 여기.
DLT-META CLI를 사용하면 대화형 Python 터미널에서 onboard 및 deploy를 실행할 수 있습니다.
4. 일반 파이프라인 만들기
메타데이터가 준비되면 단일 제네릭 파이프라인을 생성합니다. 이 파이프라인은 Dataflowspec 테이블에서 읽어와 동적으로 로직을 생성합니다.
pipelines/dlt_meta_pipeline.py 를 진입점으로 사용하고 브론즈 및 실버 사양을 참조하도록 구성하세요.
이 파이프라인은 소스를 추가해도 변경되지 않습니다. 메타데이터가 동작을 제어합니다.

5. 트리거 및 실행
이제 파이프라인을 실행할 준비가 되었습니다. 다른 Spark 선언적 파이프라인처럼 트리거하세요.
DLT-META는 런타임에 파이프라인 로직을 구축하고 실행합니다.
출력은 일관된 변환, 품질 규칙 및 리니지가 자동으로 적용�된, 프로덕션에 즉시 사용할 수 있는 브론즈 및 실버 테이블입니다.
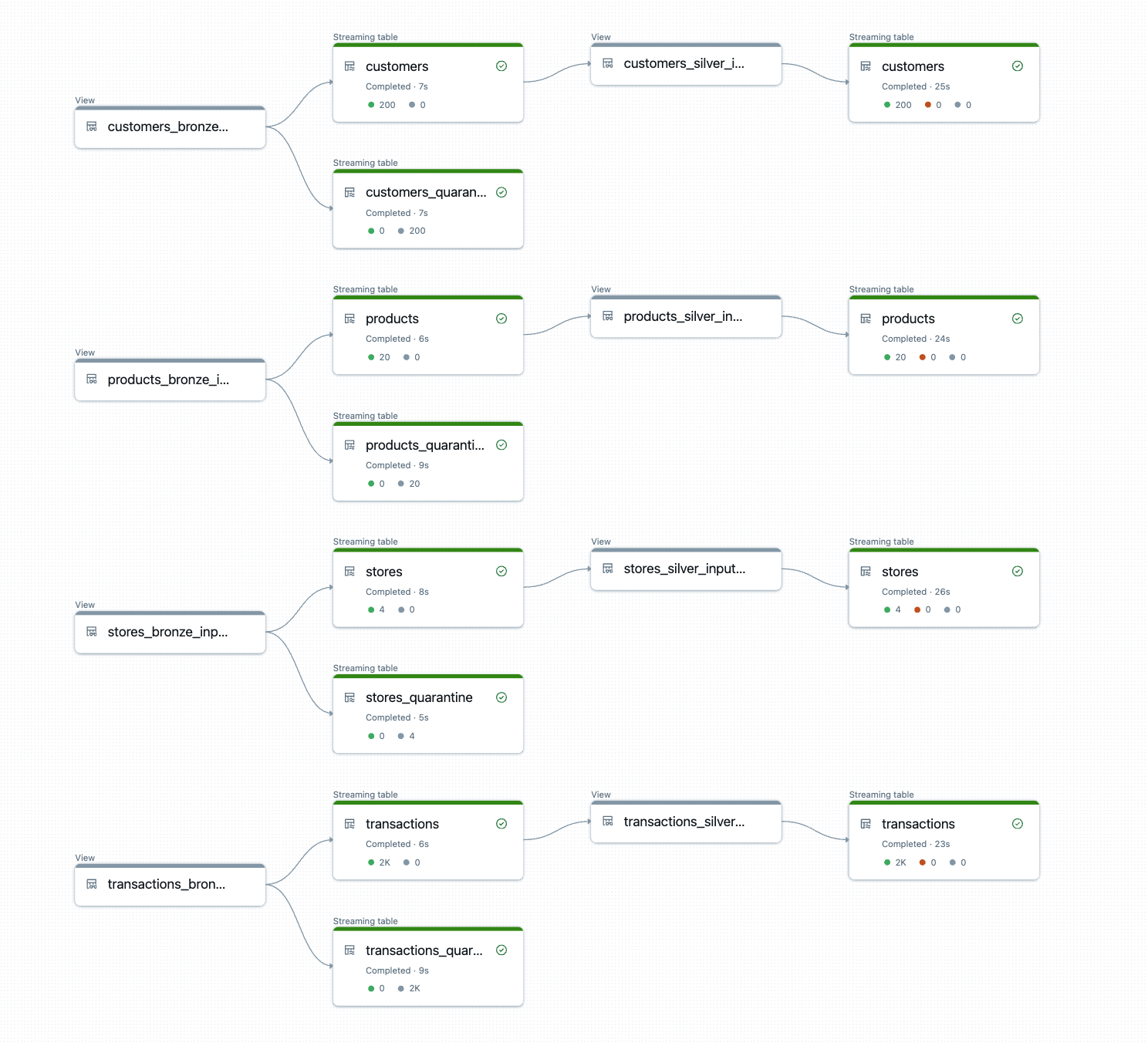
{kind=link}
지금 사용해 보기
시작하려면 기존 Spark 선언적 파이프라인을 몇 가지 소스와 함께 사용하여 개념 증명을 시작하고, 파이프라인 로직을 메타데이터로 마이그레이션한 다음, DLT-META가 대규모로 오케스트레이션하도록 하는 것이 좋습니다. 소규모 개념 증명으로 시작하여 메타데이터 기반 메타프로그래밍이 데이터 엔지니어링 역량을 상상 이상으로 확장하는 것을 지켜보세요.
Databricks 리소스
- 시작하기: https://github.com/databrickslabs/DLT-META#getting-started
- GitHub: github.com/databrickslabs/DLT-META
- GitHub 문서: databrickslabs.github.io/DLT-META
- Databricks 문서: https://docs.databricks.com/aws/en/dlt-ref/DLT-META
- 데모: databrickslabs.github.io/DLT-META/demo
- 최신 릴리스: https://github.com/databrickslabs/DLT-META/releases
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.