Databricks at SIGMOD 2026
작성자: 인드라지트 로이
- Databricks가 복잡한 ETL 및 스트리밍 워크로드를 간소화하는 차세대 데이터 엔지니어링인 Spark Declarative Pipelines(SDP)를 어떻게 선도하고 있는지 알아보세요.
- SIGMOD 컨퍼런스에서 우수 논문상을 수상한 점진적 뷰 유지 관리 엔진인 Enzyme에 대한 심층 분석을 받아보세요.
- 컨퍼런스에서 저희 엔지니어들을 만나 이러한 업계 선도적인 혁신에 대해 논의하세요.
Databricks는 데이터 및 AI 분야에서 가능한 것의 한계를 지속적으로 넓히며 엔지니어링 혁신을 선도하고 있습니다. Spark Declarative Pipelines에 대한 저희의 작업이 SIGMOD 2026에서 소개될 예정이며, 해당 작업이 학회에서 우수 논문상(honorable mention award)을 수상하게 되었음을 발표하게 되어 기쁩니다. 저희는 다가오는 6월 1일부터 5일까지 플래티넘 스폰서로 SIGMOD에 참가합니다. SIGMOD는 인도 방갈로르에서 개최될 예정이며, 이곳은 Databricks의 주요 R&D 허브이기도 합니다.
데이터 엔지니어링에 대한 저희의 최신 논문들은 Databricks가 고객을 위해 점진적 데이터 처리를 어떻게 간소화했는지 보여줍니다. Spark Declarative Pipelines(SDP)에서 점진적 프로그램을 작성하는 두 가지 방법이 있으며, 고객은 파이프라인 내에서 이 두 가지를 혼합하여 사용할 수 있습니다:
- 데이터 엔지니어는 변환을 위해 Materialized Views를 지정할 수 있습니다. Enzyme 엔진은 새로운 데이터가 도착함에 따라 이를 점진적으로 유지 관리합니다. 점진적 처리의 모든 복잡성은 materialized view를 생성하는 사람들에게 완전히 숨겨집니다. SIGMOD 2026 논문 “Enzyme: Incremental View Maintenance for Data Engineering”은 이러한 아이디어 중 일부를 다룹니다.
- 스트림 처리에 능숙한 데이터 엔지니어는 대신 SDP의 스트리밍 엔진을 사용하여 데이터를 점진적으로 처리할 수 있습니다. 스트리밍 API는 상태 저장 연산자부터 워터마크까지 다양한 구문을 제공하여 복잡한 비즈니스 로직(예: 사용자 정의 집계)을 쉽게 표현할 수 있습니다. 저희 스트리밍 제품의 핵심 아이디어는 VLDB 2026 논문 “A Decade of Apache Spark Structured Streaming: How We Evolved the Architecture To Meet Real-world Needs”에 포함될 것입니다.
Enzyme 논문과 팀이 작업해 온 내용에 대한 미리보기를 확인해 보세요:
SIGMOD 2026의 Enzyme
점진적 뷰 유지 관리
회사에서 분석가라고 가정해 봅시다. 특정 지역에서 판매된 총 주문 수를 분석하고 싶습니다. 아래의 materialized view가 답을 제공합니다.
CREATE MATERIALIZED VIEW order_report as
SELECT region, sum(orders)
FROM customer_and_order_table
GROUP by region
새로운 주문이 추가됨에 따라 materialized view가 최신 상태로 유지되기를 기대할 것입니다. 이 데이터 유지 관리는 본질적으로 점진적 뷰 유지 관리 문제입니다. 위의 간단한 MV를 최신 상태로 유지하는 것은 간단해 보이지만, MV가 여러 테이블의 데이터를 조인해야 하거나 창 함수가 포함되어 있거나 LLM 함수를 호출해야 한다고 상상해 보세요.
Enzyme의 혁신
Materialized views(MVs)는 데이터 웨어하우스에 있는 데이터를 기반으로 대시보드를 가속화하는 쿼리 가속화에 인기가 있습니다. Spark Declarative Pipelines를 생성할 때, 저희는 쿼리 가속화를 넘어서 materialized views를 extract-transform-load(ETL) 사용 사례에 적용하기로 결정했습니다. 저희의 핵심 관찰은 MV를 효율적이고 점진적으로 유지 관리할 수 있다면, 복잡한 사용자 정의 코드를 작성해야 하는 ETL 워크로드를 크게 간소화할 수 있다는 것입니다.
Enzyme은 점진적으로 materialized views를 유지 관리하는 풍부한 문헌에 기여하며, 프로덕션 워크로드에서 이러한 기술을 확장하는 방법을 보여줍니다. 팀이 작업한 혁신 중 일부는 다음과 같습니다:
- 광범위한 MV 패턴 지원: Enzyme은 조인, 창 함수, 집계 및 이들의 조합을 포함한 복잡한 MV를 프로덕션에서 점진적으로 유지 관리합니다. 다른 업계 솔루션과 달리 Enzyme은 current_date()와 같은 비결정적 함수 및 AI 관련 함수도 지원합니다.
- 다국어 지원: 대부분의 업계 솔루션은 SQL에만 중점을 두지만, Enzyme은 Python으로 지정된 MV도 지원합니다. Python은 이제 대부분의 데이터 엔지니어링 및 AI 워크로드에서 선호되는 언어입니다. Enzyme은 MV 정의의 변경 사항을 정확하게 감지하는 것과 같이 다국어 지원과 관련된 많은 흥미로운 문제를 해결합니다.
- 성능 최적화: Enzyme은 파티션 수준 또는 행 수준에서 업데이트를 적용해야 하는지 자동으로 결정하는 기술을 포함하여 처리해야 하는 데이터 양을 줄이는 여러 최적화를 제공하여 재작성 오버헤드를 줄입니다. 또한 IO 비용을 줄이기 위해 중간 결과를 선택적으로 캐싱합니다. 계획 정보와 이전 실행을 활용하여 가장 효율적인 점진화 전략을 결정하는 비용 모델을 사용합니다.
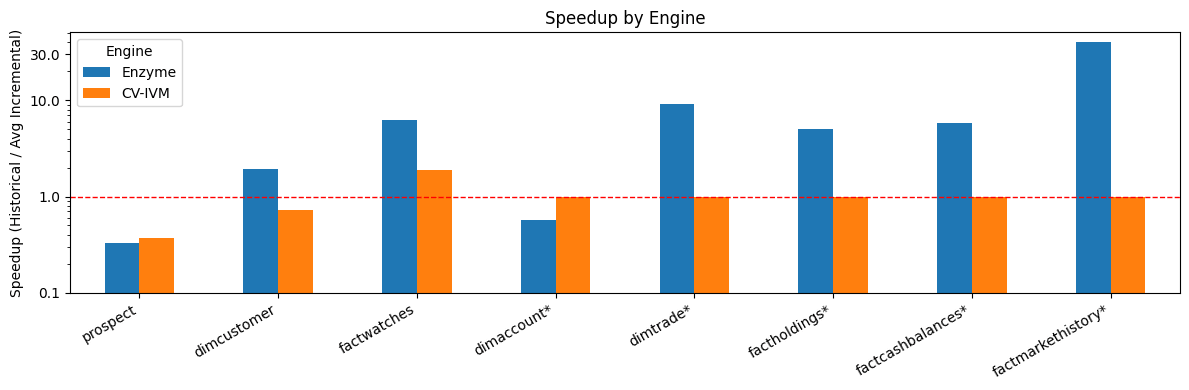
그림 1: Enzyme은 다른 경쟁 업계 솔루션(라이선스 제한으로 인해 CV-IVM으로 익명 처리됨)보다 훨씬 뛰어난 성능을 보여줍니다.
더 자세히 알고 싶으신가요? 논문을 확인하시고, SIGMOD에 참석하신다면 더 자세한 내용을 위해 저희 발표에 참석해 주세요.
SIGMOD에서 팀 만나�기:
저희 부스에 들러 팀을 만나고 Databricks에서 진행 중인 혁신에 대해 자세히 알아보세요. 또한, Ritwik Yadav의 SIGMOD 발표를 직접 들을 수 있는 기회를 놓치지 마세요!
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.