Databricks에서 비전 언어 모델을 사용하여 비용 효율적으로 의료 이미지 비식별화하는 방법
VLM은 의료 이미지 비식별화에 놀라울 정도로 뛰어난 성능을 보이며 Databricks에서 비용 효율적입니다.
- 비즈니스 문제 - 임상 연구를 위해 의료 기록을 안전하고 유용하게 만들고, 특히 임상시험의 눈가림 해제를 방지하려면 해당 기록을 비식별화해야 합니다. 텍스트 비식별화는 잘 해결된 문제인 반면, 이미지 비식별화는 아직 개선의 여지가 많습니다. 저희는 VLM이 대규모 이미지 비식별화를 위한 실행 가능한 솔루션이 될 정도로 발전했다고 생각합니다.
- 테스트한 솔루션 - 이 프로젝트를 진행하는 동안 저희는 대표적인 오픈 소스 솔루션인 Presidio와 상용 VLM 및 오픈 소스 VLM(비전 언어 모델)을 테스트했습니다.\n* 결과 - 저희 실험에서 VLM은 이미지의 PHI를 탐지하는 데 놀라울 정도로 뛰어난 성능을 보였으며 100%의 재현율을 기록했습니다. VLM은 뛰어난 성능 외에도 기존의 OCR 및 텍스트 전용 접근 방식에 비해 튜닝이 거의 필요하지 않아 사용하기 쉽고 비용 효율적입니다.
확장 가능한 이미지 비식별화가 필요한 이유
X-ray 및 MRI와 같은 의료 영상은 진단, 치료 계획, 질병 모니터링에 도움을 줄 뿐만 아니라, 개별 환자 치료를 넘어 더 광범위한 의학 연구, 공중 보건 정책, 새로운 AI 기반 진단 도구의 개발에 점점 더 많이 사용되고 있습니다. 의료 기록의 이러한 2차적 활용은 매우 유용하지만, 환자 개인정보를 보호하고 HIPAA와 같은 규정을 준수하려면 보호된 건강 정보(PHI)의 비식별화 과정을 거쳐야 합니다.
의료 이미지 데이터 세트의 규모가 커짐에 따라 의학 발전을 위해 이미지를 안전하고 윤리적으로 사용하려면 신뢰할 수 있고 효율적인 비식별화 방법이 필요합니다. 이를 위해, 널리 사용되는 의료 영상 형식인 DICOM(디지털 Imaging and Communications in Medicine) 이미지를 비식별화하기 위해, Vision Language Models(VLM)을 병렬로 활용하는 Spark ML 파이프라인과 함께 Pixels 솔루션 Accelerator를 소개합니다.
DICOM 파일에는 이미지와 메타데이터 텍스트가 모두 포함됩니다(자세한 내용은 여기를 참조하세요). 여기서는 이미지를 비식별화하는 새로운 기능에 대해 중점적으로 다루겠습니다. 참고로 당사의 DICOM 툴킷인 Pixels는 웹 애플리케이션 내에서 확장 가능한 DICOM 수집 및 분할 기능과 더불어 메타데이터 비식별화도 수행합니다.
DICOM 이미지에 번인된 PHI를 비식별화하는 방법
Pixels python 패키지를 설치한 후 다음과 같이 DicomPhiPipeline을 실행합니다.
Spark 데이터프레임의 한 열에 있는 DICOM 파일 경로를 읽어 2개의 열을 출력합니다:
- VLM의 응답(엔드포인트에 지정됨)
- PHI가 마스킹 처리된 DICOM 파일 경로
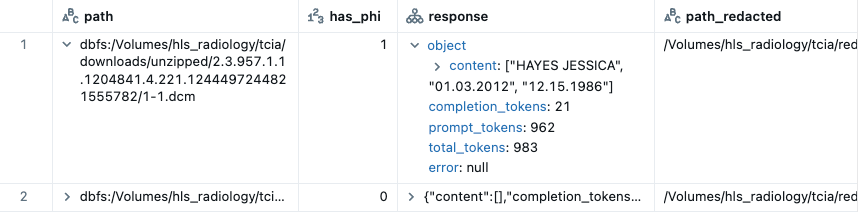
DicomPhiPipeline의 일부로 EasyOCR을 사용하여 리댁션이 ��수행됩니다. 리댁션은 VLM PHI 탐지와 독립적으로 수행되거나(redact_even_if_undetected=True) VLM PHI 탐지에 따라 조건부로 수행될 수 있습니다(redact_even_if_undetected=False). EasyOCR은 PHI가 아닌 정보까지 과도하게 리댁션하는 경향이 있으므로 후자를 권장합니다. VLM이 PHI 양성으로 감지한 이미지를 조건으로 사용하면 EasyOCR이 PHI가 아닌 이미지를 비식별화 처리할 가능성이 낮아집니다.
다른 PHI 탐지 방법과의 비교
경쟁 솔루션
저희는 Pixels의 이미지 PHI 탐지 파이프라인을 상용 벤더 및 널리 사용되는 오픈 소스 솔루션인 Presidio와 함께 테스트했습니다. 공급업체와 Presidio는 모두 OCR을 사용하여 먼저 이미지에서 텍스트를 추출한 다음, 언어 모델을 적용하여 해당 텍스트가 PHI인지 여부를 분류했습니다. 기본 내장 OCR은 민감한 텍스트를 분할하고 해당 경계 상자 내에 채우기 마스크를 적용했습니다.
또한 GPT-4o, Claude 3.7 Sonnet, 오픈 소스 Llama 4 Maverick 등 여러 VLM을 비교했습니다.
Dataset
비교는 공개 DICOM 데이터 세트 MIDI-B 에서 수행했으며, PHI 포함 이미지와 미포함 이미지 수가 거의 동일한 균형 잡힌 데이터 세트를 만들기 위해 70개 이미지로 다운샘플링했습니다.
결과
| 작업: DICOM 이미지의 PHI 탐지 | MIDI-B (70) | ||||
|---|---|---|---|---|---|
| 솔루션 | �비용 추정치 이미지 10만 개당 | 회수 | 정밀도 | 특이도 | NPV |
| ISV (상용) | 월 $4,400 선불 | 1.0 | 0.71 | 0.93 | 1.0 |
| Presidio (OSS) | $0 | 0.7 | 0.7 | 0.95 | 0.95 |
| Claude 3.7 Sonnet | $270 | 1.0 | 1.0 | 1.0 | 1.0 |
| GPT-4o | $150 | 1.0 | 1.0 | 1.0 | 1.0 |
| Llama 4 Maverick (OSS) | $45 | 1.0 | 0.91 | 0.98 | 1.0 |
Claude 3.7 Sonnet과 GPT-4o 모두 완벽한 PHI 탐지 성능을 보였습니다. Llama 4 Maverick은 때로 이미지의 PHI가 아닌 텍스트를 PHI로 잘못 식별하여 재현율은 100%였지만 정밀도는 91%였습니다. 그럼에도 불구하고 Llama 4-Maverick은 PHI를 놓치지 않기 위해 과도한 리댁션을 선호하는 사용자에게 특히 우수한 성능을 제공합니다. 이 경우 PHI의 False Omission Rate는 0입니다(즉, NPV가 1에 가깝고 재현율이 1이므로 성능과 비용의 균형을 잘 맞출 수 있습니다.
테스트에서 저희는 Presidio와 상용 솔루션을 default 설정 그대로 사용했습니다. 정확도와 속도 측면의 성능은 OCR 선택에 따라 크게 달라진다는 것을 확인했습니다. Azure Document Intelligence와 같은 대안을 사용하면 성능이 개선될 가능성이 높습니다.
작동 원리
저희는 의료 이미지 내 번인된 텍스트의 비식별화와 관련된 문헌을 조사하였으며, OCR과 BERT, Bi-LSTM, GPT 같은 LLM, 그리고 VLM을 활용한 성공 사례들을 확인하였습니다. 특히, PHI 탐지에는 VLM을, 텍스트 경계 상자 탐지에는 EasyOCR을 적용하기로 한 결정은 Truong et al. 2025의 성공 사례에 근거한 것입니다.
VLM은 텍스트 인식률이 낮고 오타를 자주 발생시키는 기존 OCR을 대체합니다.
대부분의 비식별화 방법에서는 이미지 내 텍스트를 추출하는 첫 단계로 OCR을 사용합니다. 하지만 저희가 관찰한 바로는 Tesseract나 EasyOCR 같은 OCR 도구는 텍스트 인식 정확도가 낮고 처리 속도도 느려, 종종 문자를 잘못 인식해 오타가 발생하며, 이로 인해 후속 PHI 탐지 성능이 저하되는 문제가 있습니다. 이를 완화하기 위해 VLM을 사용하여 번인 텍스트를 읽고 해당 텍스트가 PHI인지 분류했습니다. VLM은 이 작업에서 놀라울 정도로 뛰어난 성능을 보였습니다.
VLM이 이미지를 변경할 수 없는 경우 리댁션을 위한 경계 상자 감지에 EasyOCR 사용
하지만 VLM은 비식별화 처리된 이미지를 출력할 수 없습니다. 따라서 저희는 OCR의 장점인 텍스트 탐지 기능을 활용하여 후속 마스킹 처리에 필요한 경계 상자 좌표를 제공했습니다. 주목할 점은, 최근 VLM을 미세 조정하여 경계 상자 좌표(Chen et al. 2025)를 출력하려는 시도가 있었지만, 저희는 대신 VLM, EasyOCR 같은 ��기성 도구를 조합하는 더 간단한 솔루션을 선택했다는 것입니다.
프로덕션 수준의 확장성을 위한 Spark 병렬 처리
Databricks는 LLM을 사용한 배치 추론 기능(ai_functions)이 있었지만, 현재 VLM은 지원하지 않습니다. 따라서 저희는 Pandas UDF를 사용하여 VLM 및 EasyOCR을 위한 확장 가능한 버전을 구현했습니다. 한 대형 제약 고객과 협력하여 Spark 병렬 처리를 통해 1,000개의 DICOM 프레임을 시험 실행한 결과, 비식별화 프로세스가 105분에서 6분으로 단축되었습니다! 100,000개의 DICOM 프레임으로 구성된 전체 워크로드로 확장했을 때 속도 향상 및 비용 절감 효과가 상당했습니다.
요약
Pixels 2.0 솔루션 액셀러레이터 애드온에서 입증된 VLM의 성능, 편의성, 경제성을 고려할 때, 확장 가능한 PHI 탐지 기능으로 귀사의 중요한 임상 연구 및 관련 이미지 연구를 보호하는 것은 실현 가능할 뿐만 아니라 현명한 선택입니다.
Pixels는 DICOM 파일용으로 설계되었지만, 고객들은 JPEG, 전체 슬라이드 이미지, SVS 등 다른 이미지 형식에도 맞춰 사용하고 있음을 확인했습니다.
최신 업데이트 내용은 저희 GitHub 리포지토리에 게시되어 있으니, 지금 바로 Databricks Pixels 2.0 솔루션 액셀러레이터를 업데이트하거나 사용해 보시기 바랍니다. 또한, 의료 영상 데이터 처리와 AI/ML 활용 사례에 대해 논의하고 싶으시면 Databricks 계정 팀에 문의해주시고, 저희와 아직 교류가 없으시다면 LinkedIn을 통해 연락해 주시면 감사하겠습니다.
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.