MemEx: LLM 에이전트를 위한 프로그래밍 가능한 스크래치패드
작성자: Databricks AI 연구팀
1945년, 배니버 부시(Vannevar Bush)는 필요할 때마다 불러올 수 있도록 모든 문서, 주석, 생각의 흐름을 저장하여 과학자의 기억을 확장해 주는 책상 크기의 기계를 상상했습니다. 그는 이를 MemEx라고 불렀습니다. 부시는 인간의 문제, 즉 늘 곁에 두고 기억하기에는 너무 많은 정보에 압도당하는 정신적 한계를 해결하고자 했습니다. 그로부터 80년이 지난 지금, LLM 에이전트들도 이와 놀라울 정도로 유사한 장벽에 부딪히고 있습니다.
현재의 에이전트 ��도구 호출(Agentic Tool Calling) 패러다임에서 컨텍스트 창(context window)은 모델이 작동할 수 있는 유일한 지속적 기반입니다. 이는 시스템 프롬프트, 사용자의 쿼리, 모델의 추론, 도구 호출, 원시 도구 출력값을 모두 담는 공유 공간입니다. 그중에서도 도구 출력값이 가장 큰 문제입니다. 단 하나의 SQL 쿼리가 수백만 개의 행을 반환할 수 있으며, 오늘날의 프레임워크에서는 단 하나의 셀만 중요하더라도 그 수백만 개의 행이 이후 모든 턴에 계속해서 따라다닙니다. 에이전트는 이 결과가 컨텍스트 창을 가득 채우기 전에 이를 자르거나, 요약하거나, 따로 보관할 방법이 없습니다.
Databricks에서도 이러한 장벽에 끊임없이 부딪혔습니다. Genie부터 Agent Bricks에 이르기까지 당사의 프로덕션 에이전트들은 어느 시점에 이르면 모두 동일한 컨텍스트 한계에 직면합니다. Genie가 좋은 예입니다. 단일 쿼리가 고객의 전체 워크스페이스를 검색하고, 여러 도구를 호출하여 테이블, 벡터 인덱스, 대시보드에서 데이터를 가져옵니다. 이를 해결하기 위해 당사는 자체적인 MemEx를 구축했으며, 여러 프로덕션 및 내부 에이전트에서 그 효과를 검증했습니다.
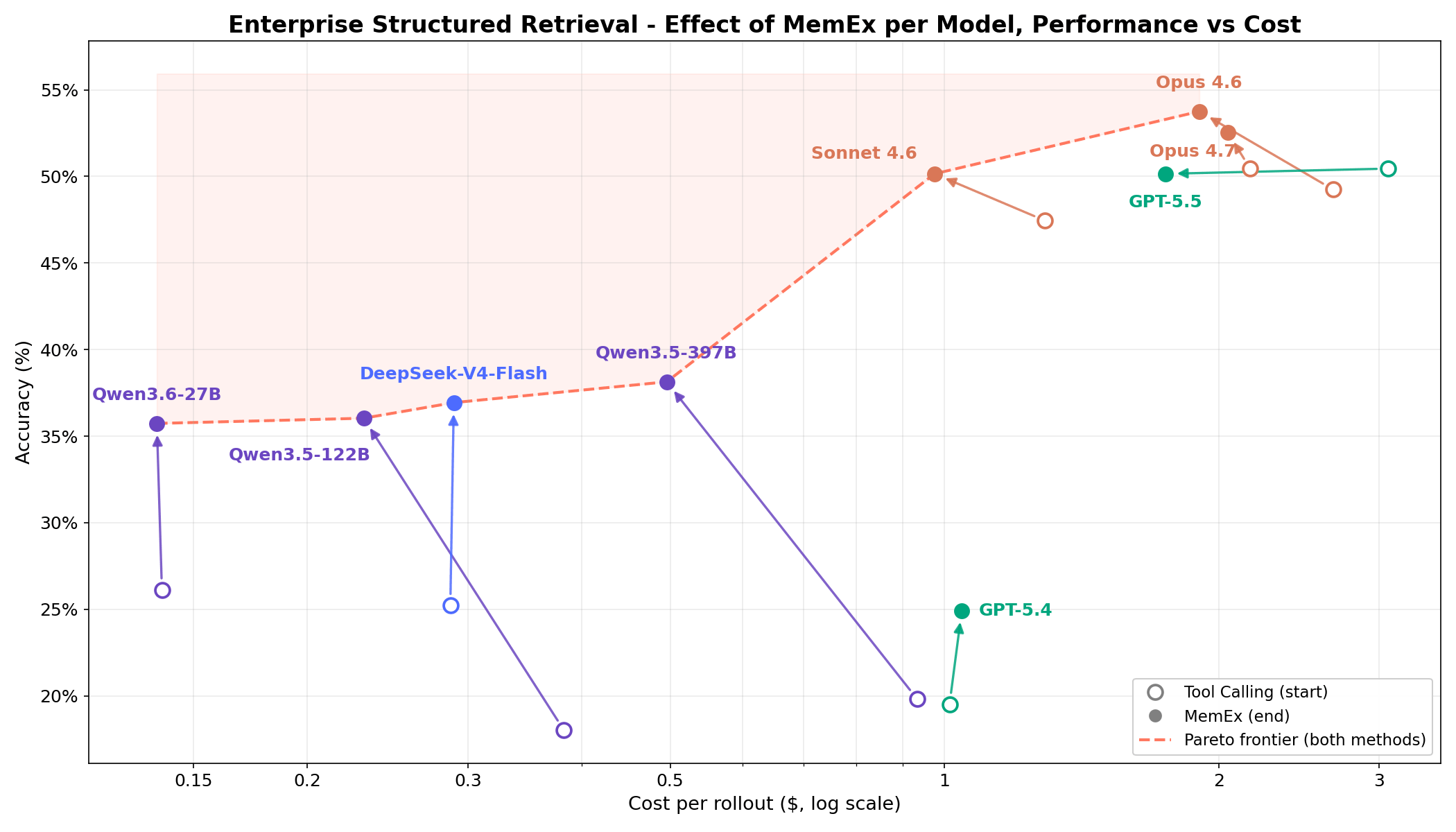
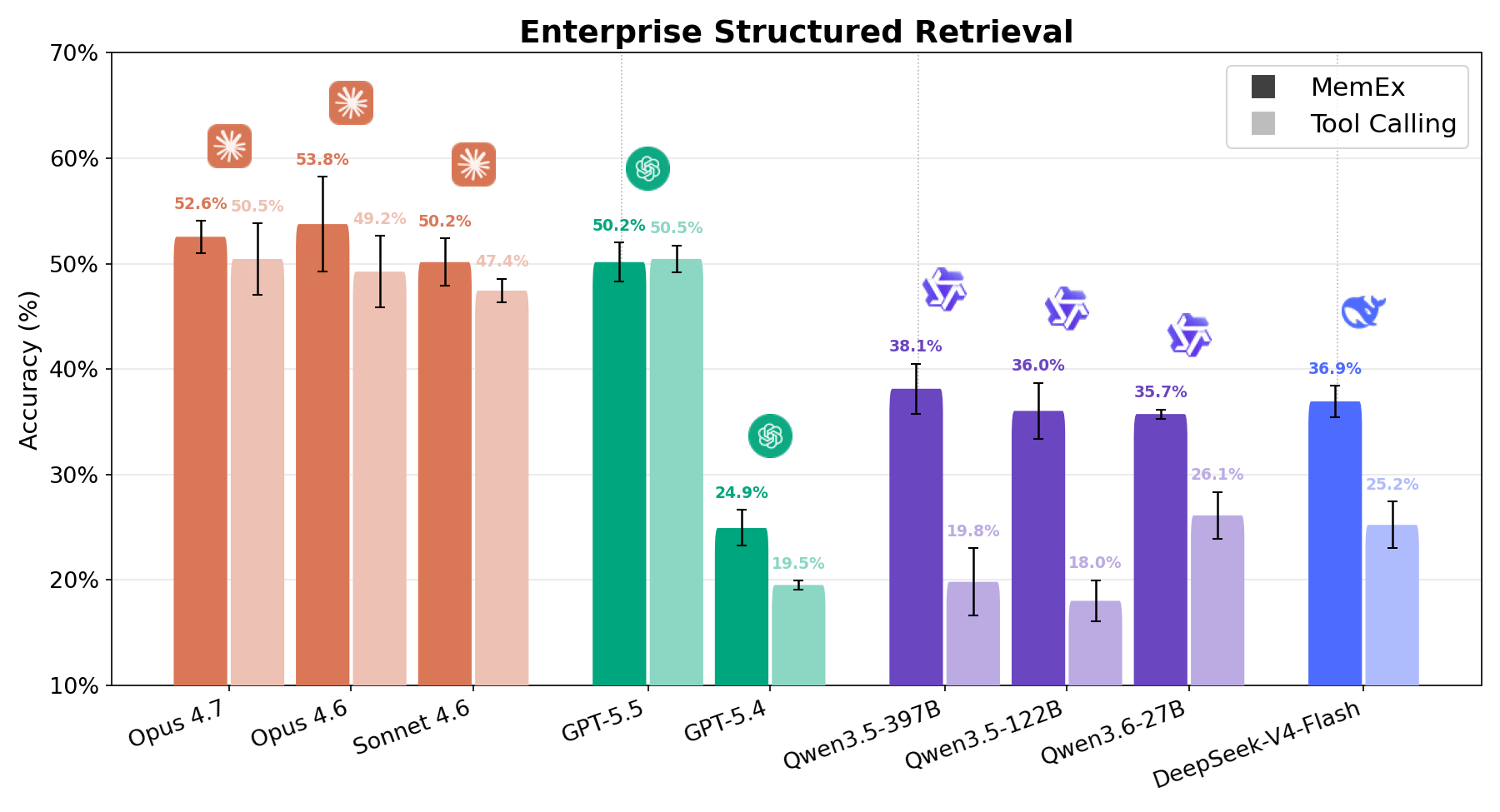
까다로운 기업용 구조화된 검색(structured retrieval) 작업에서 그림 1은 MemEx가 모든 모델의 비용 대비 정확도 한계를 어떻게 확장하는지 보여줍니다. Opus 4.6 및 Sonnet 4.6과 같은 프론티어 모델은 토큰 비용을 25~30% 줄이면서도 정확도를 2~5%포인트 향상시킵니다. Qwen3.5-122B(18% → 36%) 및 Qwen3.5-397B(20% → 38%)와 같은 오픈 가중치(open-weights) 모델은 토큰 비용을 40~50% 절감하면서 정확도를 거의 두 배로 높입니다. MemEx는 임의로 긴 입력값도 처리할 수 있으므로 두 가지 추가 애플리케이션도 가능해집니다. 바로 일반적인 단일 컨텍스트 창에는 들어가지 않는 에이전트 경로(MemEx 자체 경로 포함) 감사와 여러 경로에 걸친 병렬 사고입니다.
MemEx 작동 방식
{kind=link}
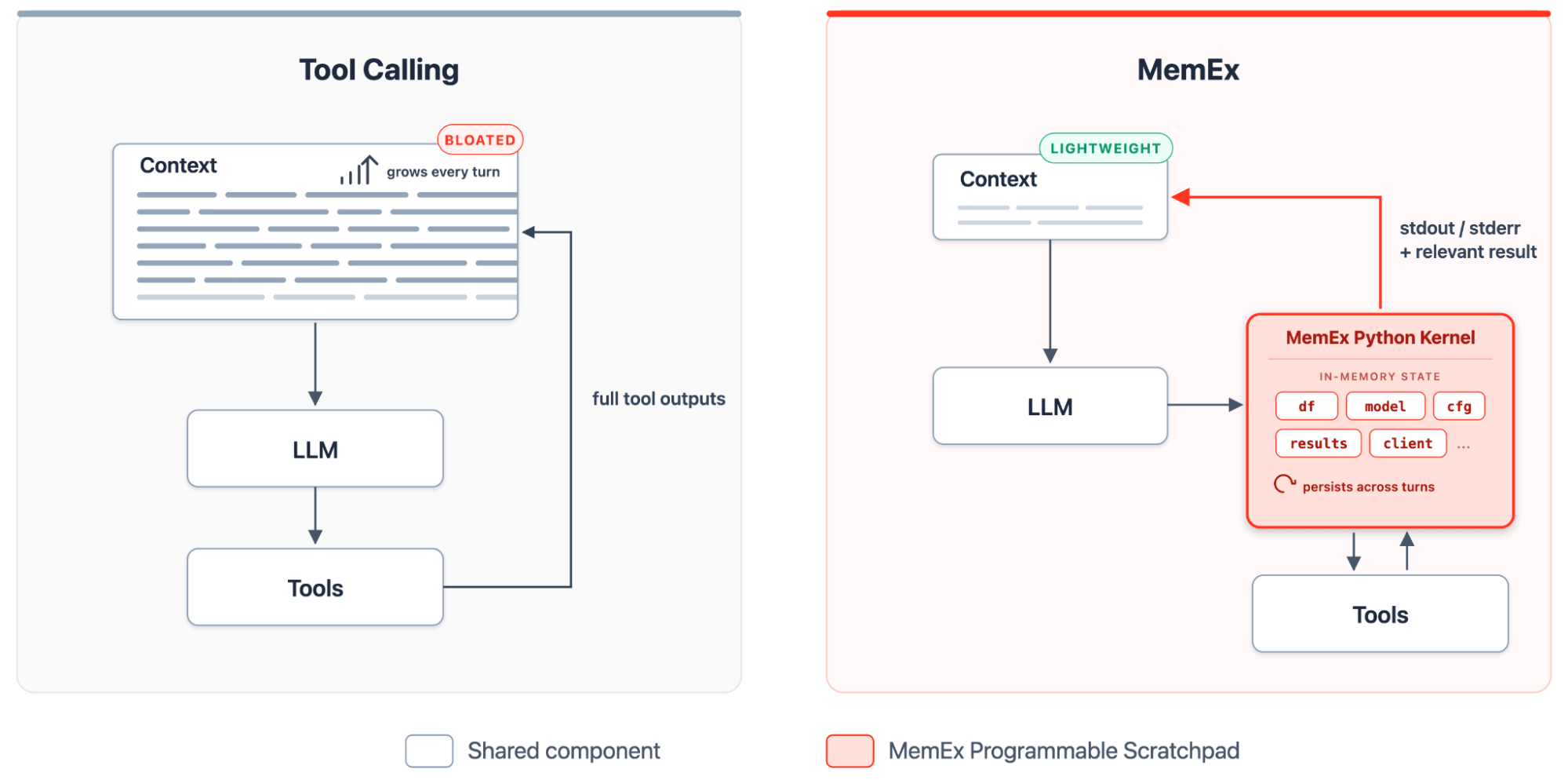
MemEx는 LLM에 프로그래밍 가능한 스크래치패드를 제공합니다. 이는 도구 출력값을 유지하고 코드로 이를 변환하며, 오직 출력문(print statement)만 컨텍스트의 토큰으로 구체화하는 타입 지정 Python 커널입니다. 이 환경 내에서 롤아웃은 스스로 확장되는 Python 프로그램이 됩니다. 각 턴 동안 에이전트는 새 블록을 작성하고, 커널은 상태를 유지하�며, 다음 블록은 이전 블록을 기반으로 빌드됩니다. 도구는 타입이 지정된 매개변수와 타입이 지정된 반환값을 가진 타입 지정 Python 함수로 노출됩니다. 도구 출력값은 MemEx의 스코프 내에 Python 객체로 안착하여 여러 턴에 걸쳐 유지됩니다. 에이전트는 코드로 이를 구성하고, 패턴이 반복될 때 헬퍼 함수를 정의하며, 동일한 스코프에서 비동기 함수 호출로 하위 에이전트를 생성합니다.
MemEx는 CodeAct(Wang et al., 2024)에 의해 도입된 '행동으로서의 코드(code-as-action)' 제품군에 속하며, Anthropic의 Programmatic Tool Calling 및 Cloudflare Code Mode에 프로덕션 변형이 존재합니다. MemEx는 기존 ReAct(Yao et al., 2022) 스타일의 에이전트 프레임워크에 직접 적용되어 영구적인 스코프, 하위 에이전트 프리미티브, 타입 지정 반환값이 긴밀히 연결된다는 점에서 차별화됩니다. 이들이 결합되어 JSON/XML 도구 호출 패러다임에는 없는 다음과 같은 기능을 제공합니다.
- 임의로 큰 입력값 처리: 문서, 데이터 세트 및 기타 대규모 객체를 Python 스코프 내에 변수로 유지할 수 있습니다.
- 타입 지정 객체 반환: 도구 출력값은 메모리에 유지되는 타입 지정 Python 객체이며, 모델이 매 턴마다 구체화하거나 다시 파싱해야 하는 문자열이 아닙니다.
- 도구 호출 구성: 한 호출의 출력값이 코드 한 줄 내에서 다음 호출의 인수로 직접 전달됩니다. 중간 출력값을 에이전트의 컨텍스트에 구체화할 필요가 없습니다.
- 도구 출력값 슬라이싱: 모델이 출력값을 보기 전에 코드에서 미리 전처리, 필터링 또는 요약할 수 있습니다.
- 비동기 하위 에이전트 생성: 에이전트는 상위 에이전트와 함께 실행되는 하위 에이전트를 프로그래밍 방식으로 생성하고, 메인 모델을 거치지 않고도 그 결과를 집계할 수 있습니다.
MemEx를 적용한 LLM 에이전트의 예
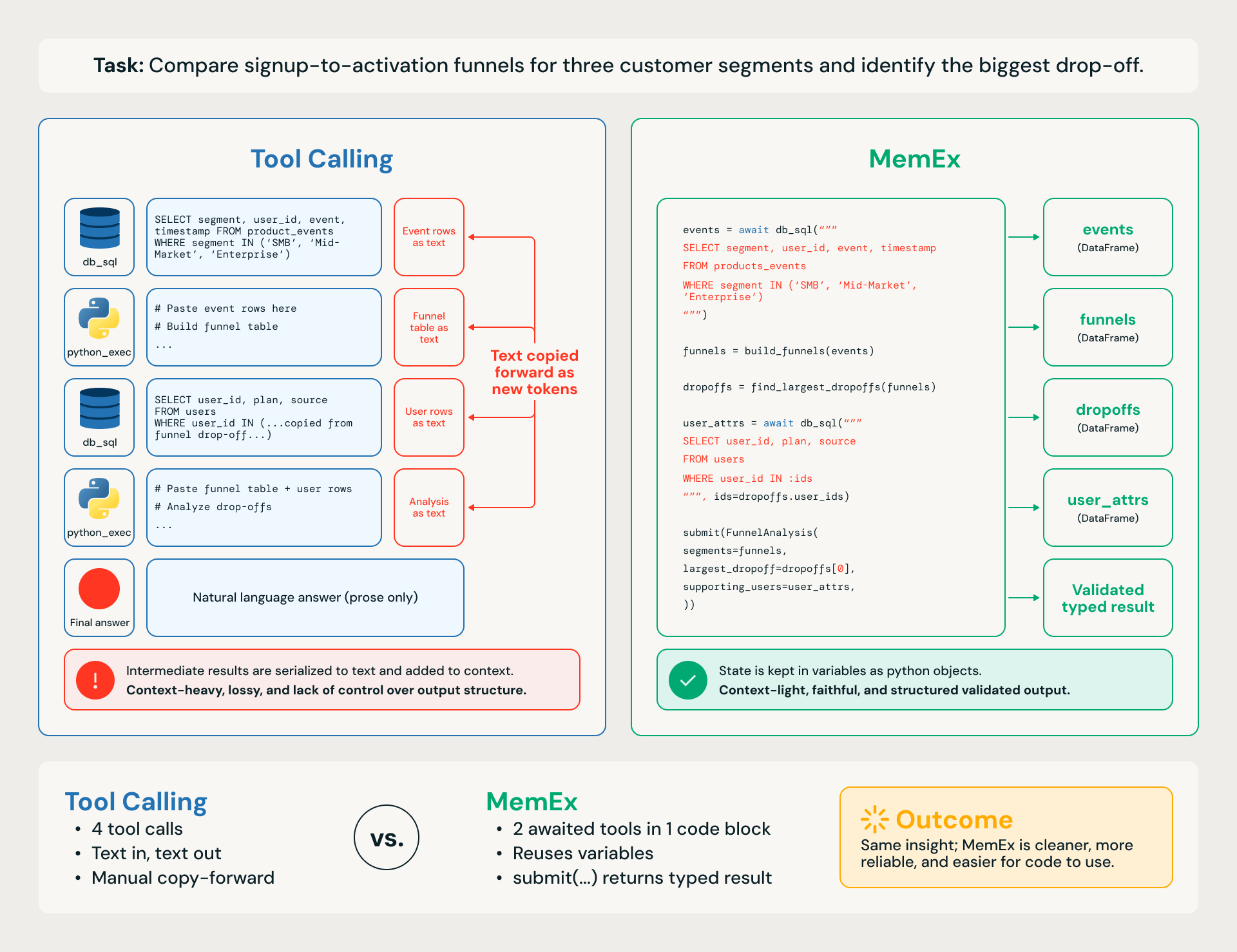
세 가지 고객 세그먼트의 가입 대비 활성화 퍼널을 비교하고 가장 큰 이탈 구간을 식별하는 구체적인 기업 작업(그림 1)을 예로 들어 보겠습니다. 이 워크플로는 다음 네 단계로 구성됩니다.
- 데이터 웨어하우스에서 가입 및 활성화 이벤트 검색
- 사용자별로 조인
- 각 단계에서 세그먼트별 전환율 계산
- 세그먼트 전반의 이탈률 순위 지정
python_exec이 탑재된 도구 호출(Tool Calling) 에이전트는 한 번에 한 단계씩 작동합니다. 각 SQL 쿼리와 각 프로그래밍 방식의 계산은 별도의 도구 호출이며, 중간 DataFrame은 텍스트로 직렬화되어 이후 턴에 다시 붙여넣어집니다. 이 트레이스는 토큰 소모가 많아 정보 손실이 발생하기 쉽고, 느리고, 비용이 많이 들며, 다운스트림 작업에서 작은 연쇄 오류를 일으키기 쉽습니다.
MemEx 에이전트는 동일한 워크플로를 단일 코드 블록으로 작성합니다. 쿼리는 스코프 내에서 네이티브 DataFrame을 반환하고, 헬퍼 함수가 이를 구성하며, 최종 답변은 submit()를 통해 검증된 타입 지정 객체로 반환됩니다. 생각은 같지만 행동 공간이 다릅니다.
하위 문제로 분해되는 작업의 경우, 에이전트는 블록 내부에서 하위 에이전트를 생성할 수 있습니다. 하위 에이전트를 생성할 때 상위 에이전트는 모든 객체에 대한 공유 액세스 권한을 전달할 수 있습니다. 하위 에이전트는 상위 에이전트와 병렬로 즉시 실행되며, 완료되면 메인 에이전트에 결과를 반환할 수 있습니다. 예를 들면 다음과 같습니다.
재귀적 분해는 동일한 Python 프로그램 내에서 또 다른 표현식이 됩니다.
MemEx는 Databricks의 에이전트 롤아웃 프레임워크인 aroll을 기반으로 개발되었습니다. Aroll은 이미 Genie, Agent Bricks의 Supervisor Agent와 같은 프로덕션 시스템과 KARL과 같은 연구 노력을 지원하고 있습니다. MemEx는 aroll이 이미 도구 호출(Tool Calling)에 사용하고 있는 것과 동일한 에이전트 루프 및 도구에 연결됩니다.
MemEx는 기업용 에이전트 작업에서 어떤 성능을 보이나요?
당사는 9개의 프론티어 모델을 대상으로 병렬 구조화된 도구 호출(Tool Calling)과 Python 코드 블록(MemEx)을 비교하는 직접적인 평가를 진행했습니다. 프롬프트 튜닝이나 작업별 조정은 거치지 않았습니다. 당사는 대규모 텍스트 코퍼스에 대한 근거 기반 독해(OfficeQA)와 다양한 관계형 데이터의 대규모 워크스페이스에 대한 구조화된 검색(Enterprise Structured Retrieval)이라는 두 가지 형태의 기업용 에이전트 작업을 비교했습니다.
두 작업 모두에서 MemEx 에이전트가 Tool Calling 에이전트보다 더 뛰어나고 비용도 저렴합니다!
{kind=link}
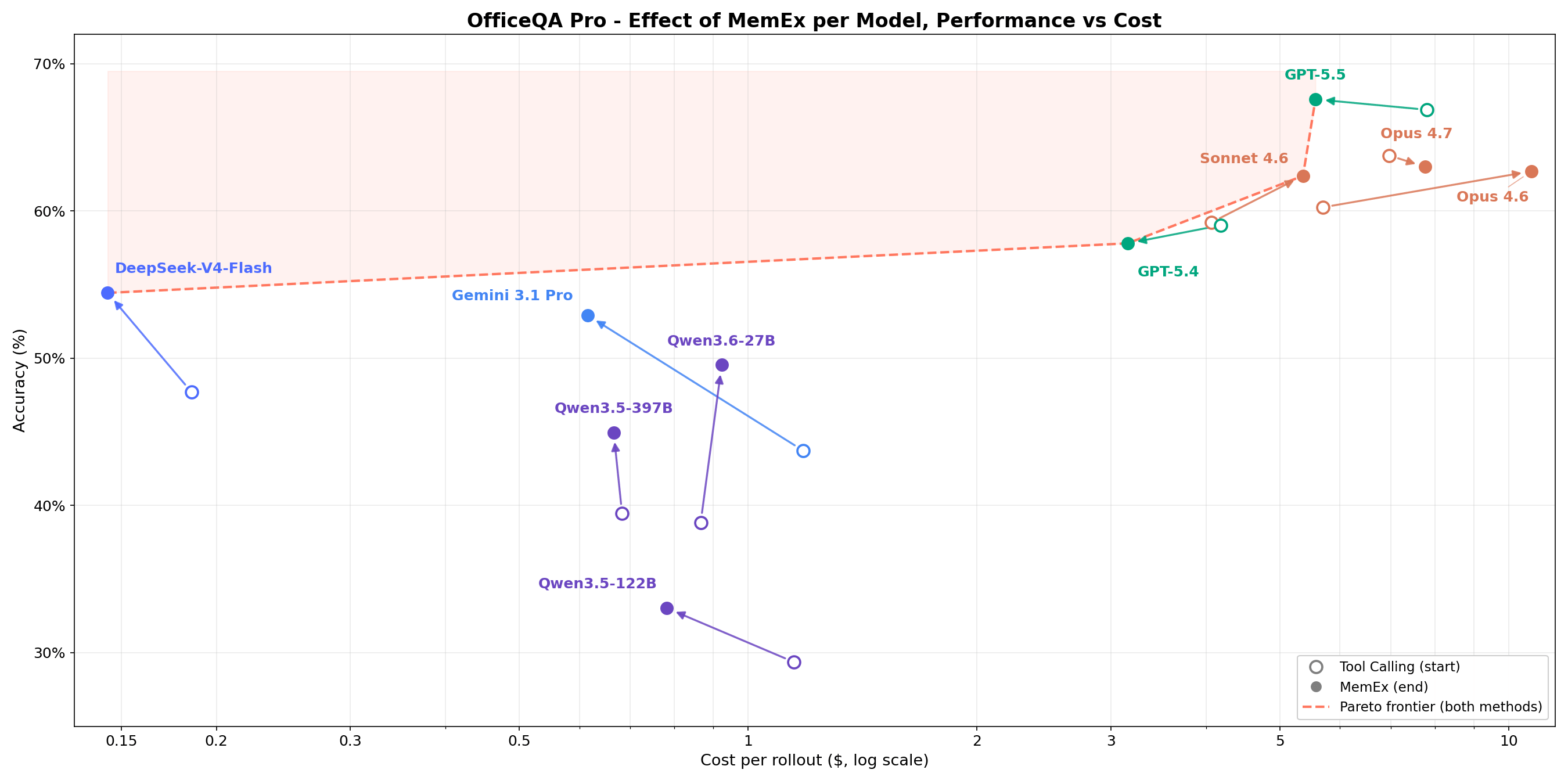
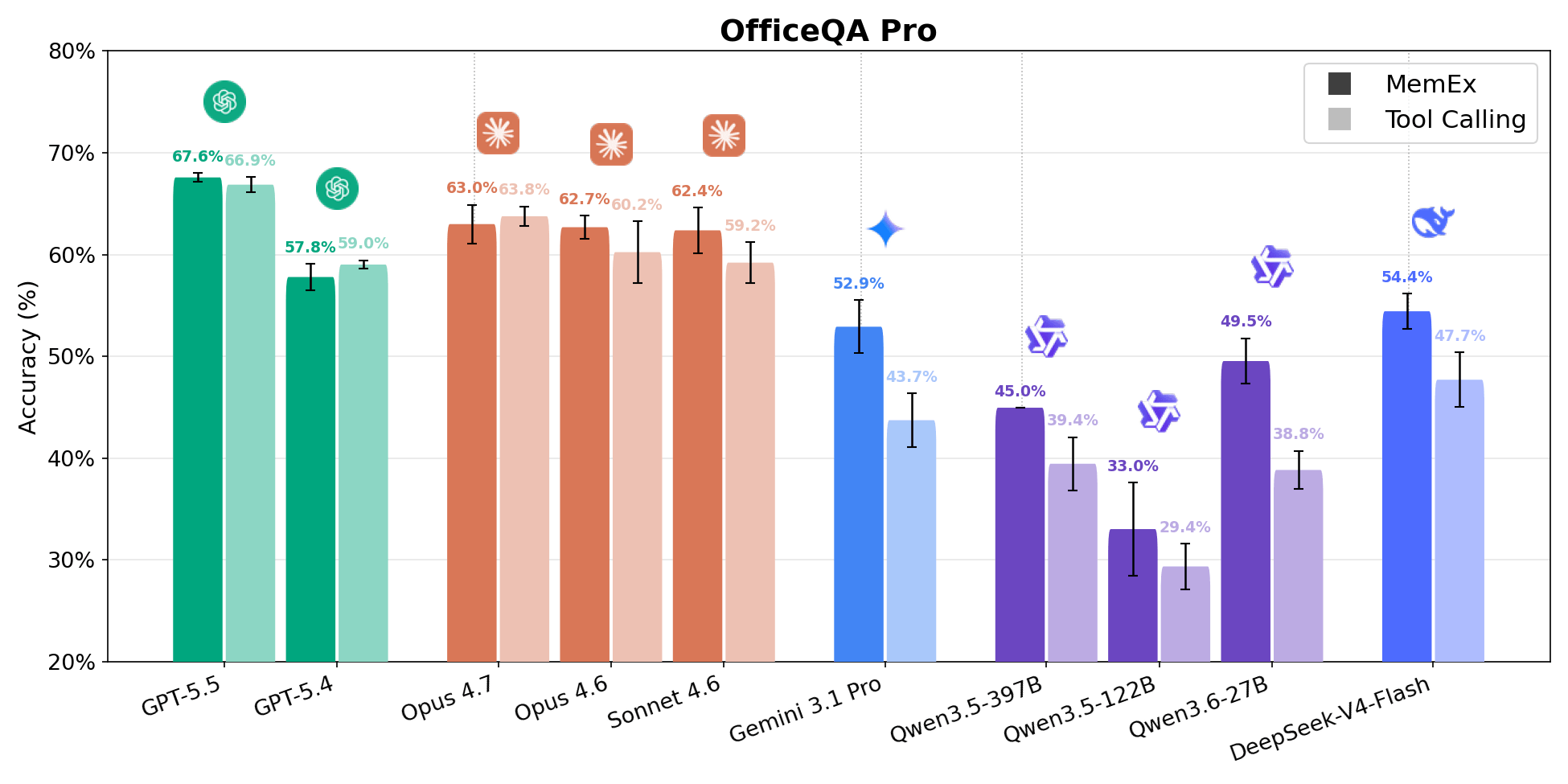
OfficeQA Pro는 에이전트에게 1939년부터 현재까지 약 89,000페이지에 달하는 미국 재무부 회보(U.S. Treasury Bulletins) 코퍼스를 기반으로 근거가 있는 추론(grounded reasoning) 질문에 답하도록 요청합니다. 일반적인 질문은 여러 문서에서 증거를 찾고, 중첩된 계층 구조와 병합된 셀이 있는 표를 탐색하며, 검색된 데이터에 대해 계산을 수행해야 합니다. 답변은 엄격한 일치(strict match) 기준으로 채점됩니다. 비용 대비 정확도 파레토 프런티어(pareto frontier)의 5개 지점 중 4개는 MemEx 구성입니다. Gemini 3.1 Pro MemEx는 실행(rollout)당 0.62달러(정확도 52.9%)로 가장 저렴한 프런티어 지점이며, Sonnet 4.6 MemEx는 약 70%의 비용으로 GPT-5.5 Tool Calling의 정확도에 근접합니다. 9개 모델 전체에서 MemEx는 모든 모델에 대해 동등하거나 더 우수한 성능을 보였습니다. 중간 그룹의 변화가 가장 컸으며, Qwen 3.6 27B와 Gemini 3.1 Pro는 약 10퍼센트 포인트 상승했습니다.
{kind=link}
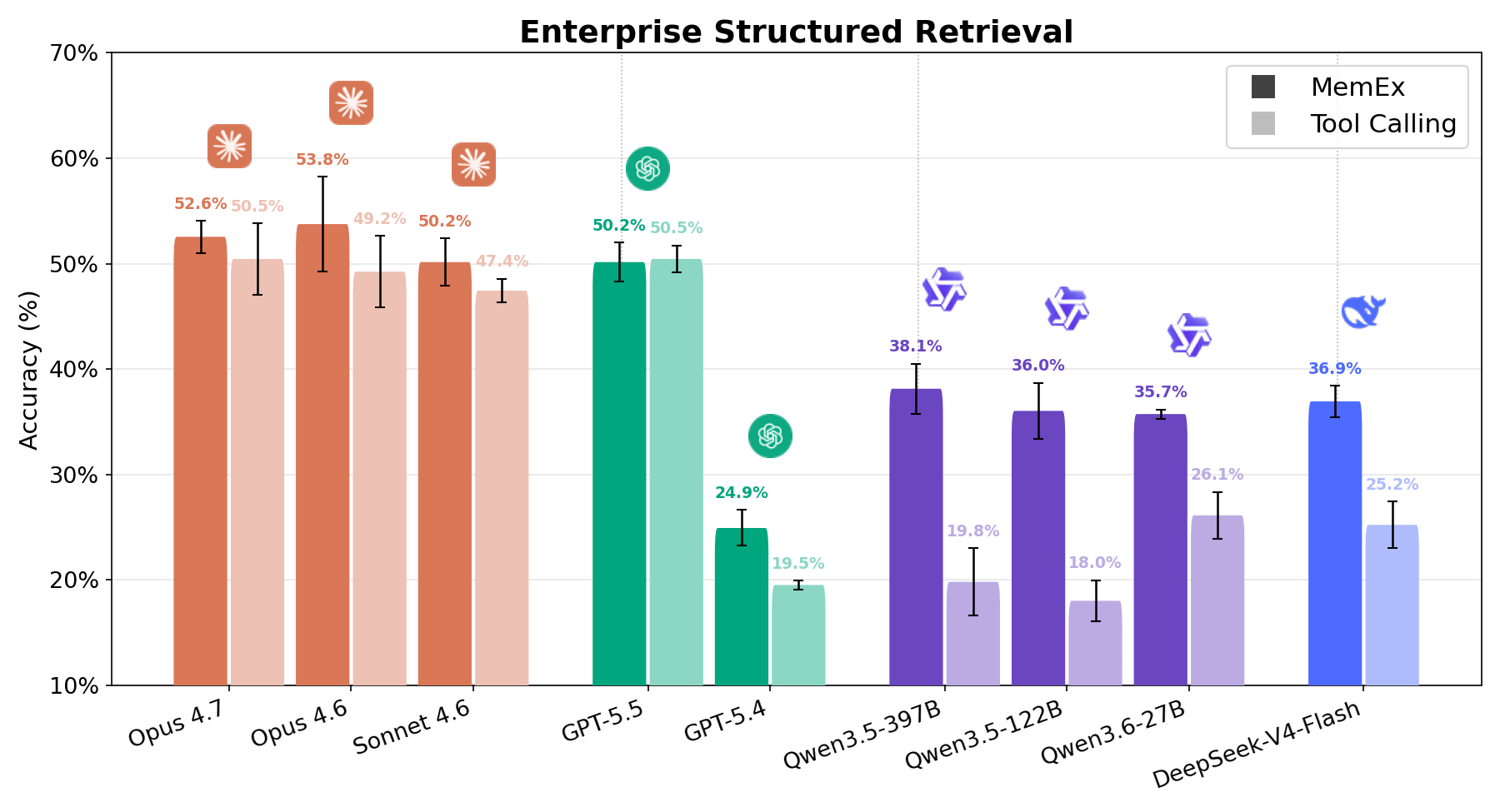
Enterprise Structured Retrieval은 에이전트에게 기업의 관계형 데이터에 대한 자연어 질문에 답하도록 요청합니다. 에이전트에게는 스키마 검색 및 SQL 쿼리 실행과 관련된 도구가 제공되며, 에이전트는 이를 사용하여 사용자가 요청한 데이터 분석 작업을 수행해야 합니다. 이때 일반적으로 다양한 작업 공간의 어디에서 관련 정보를 찾아야 하는지에 대한 정보는 거의 제공되지 않습니다. 에이전트의 답변은 결정론적 데이터 검증과 LLM-as-a-judge를 모두 사용하여 실제 정답(ground truth)과 비교하여 채점됩니다. 그림 1과 6에서 볼 수 있듯이, 동등한 성능을 보인 GPT 5.5를 제외하고 모든 모델이 MemEx를 적용했을 때 강력한 성능 향상을 보여줍니다. 비용 측면에서도 효과는 매우 강력합니다. Qwen 122B는 실행당 도구 호출 횟수가 56회에서 28회로 줄어들면서 점수는 두 배로 증가했고, Sonnet은 28회에서 17회로, Opus는 33회에서 21회로 줄었습니다.1 그 결과 대부분의 모델에서 비용이 약 절반으로 줄어듭니다. 이 패턴은 OfficeQA Pro의 결과와 일치합니다. 작업이 어려울수록 네이티브 객체와 영구 상태(persistent state)가 그 가치를 더 톡톡히 발휘합니다.
각 비교는 프롬프트 튜닝, 작업별 어댑테이션, 모델별 미세 조정 없이 실행되었습니다. 에이전트 루프, 시스템 프롬프트, 도구는 두 테스트 환경(harness) 모두에서 동일합니다. 유일한 차이점은 행동 공간(action space)으로, JSON/XML 구조화된 도구 호출과 MemEx의 Python 코드 블록의 차이입니다.
에이전트 트레이스(Agentic Traces)에서 작동하는 MemEx
에이전트 궤적(Agentic trajectories) 자체는 부피가 큰 객체입니다. Tool Calling 패러다임에서 궤적을 분석하려면 일반적으로 텍스트로 평탄화(flattening)해야 하는데, 이는 정보 손실이 발생하고 컨텍스트가 무거워지며, 여러 개를 동시에 분석하는 것은 불가능한 경우가 많습니다. 궤적은 중간에 압축이 발생하면서 여러 컨텍스트 창에 걸쳐 있을 수도 있습니다. 정의상 컨텍스트 창에 들어맞지 않는 트레이스를 LLM이 어떻게 분석할 수 있을까요? 하지만 궤적은 또 다른 Python 객체일 뿐이므로, MemEx는 이를 스코프에 직접 로드하고 그에 대해 추론할 수 있습니다. 여기서는 두 가지 애플리케이션을 보여줍니다. 첫째, OfficeQA-Pro에서 Qwen 3.6-27B 궤적을 분석하여 MemEx가 Tool Calling보다 우수한 성능을 보이는 이유를 설명하는 MemEx 기반 감사 에이전트(audit agent)입니다. 둘째, 동등한 Tool Calling 에이전트를 능가하는 MemEx 에이전트를 사용한 OfficeQA-Pro에서의 테스트 시간 스케일링(test-time scaling)입니다.
MemEx가 MemEx를 감사하다: 에이전트 트레이스 분석(Agentic Trace Analysis)
Qwen 3.6-27B와 같은 오픈 소스 모델에서 MemEx로 전환했을 때 성능이 향상된 이유를 분석하기 위해, MemEx에 설명을 요청했습니다. 구체적으로, OfficeQA 질문, 실제 정답, 6개의 해결사 궤적(MemEx 에이전트 3개, Tool Calling 에이전트 3개)을 Python 스코프로 직접 가져오는 감사 에이전트를 인스턴스화하고, MemEx 기반 Sonnet 4.6 에이전트에게 실패 모드의 4개 축 분류 체계에 따라 모든 잘못된 궤적을 분류하��도록 요청합니다.
| 실패 축 | 정의 | MemEx 오류 | Tool Calling 오류 |
|---|---|---|---|
Source Selection | 모델이 잘못된 문서나 표를 대상으로 함 | 32 | 45 |
Interpretation | 모델이 올바른 데이터를 검색했지만 잘못된 의미를 추출함 | 28 | 38 |
Search Strategy | 모델이 너무 일찍 중단되거나 정답을 지나쳐 헤맴 | 6 | 15 |
Execution | 중간 계산 또는 최종 출력 형식 지정의 버그 | 3 | 6 |
Total | - | 69 | 104 |
우리의 분석은 6번의 시도가 모두 맞거나 틀리지 않은 66개의 OfficeQA Pro 질문에 초점을 맞추어 총 173개의 궤적을 얻었습니다. 4개의 축은 크게 두 가지 그룹으로 나뉩니다.
- 그라운딩 오류(Grounding errors, ~83%): 모델이 수정된 수치 대신 예비 값을 검색하거나, 모호한 용어(예: 표본 분산 대 모집단 분산, 또는 "소수점 둘째 자리"의 반올림 정밀도)를 잘못 해석하거나, 유효한 표에서 잘못된 열을 추출하는 경우입니다.
- 검색 전략 및 실행 오류(Search Strategy and Execution errors): 검색 순서 계획의 오류 또는 검색된 데이터를 최종 계산에 올바르게 통합하지 못한 경우입니다.
검색 전략 및 실행 오류의 경우, MemEx는 MemEx 에이전트가 Tool Calling��에 비해 오류를 2배 줄였다는 것을 발견했습니다. 이는 MemEx의 경우 검색 결과가 Python 변수에 직접 저장될 수 있으므로, 모델이 한 도구의 출력 값을 다음 도구 호출로 복사하는 과정을 피할 수 있고, 단일 턴에 여러 도구 호출을 배치(batch)로 처리할 수 있기 때문입니다. Tool Calling에는 이러한 지름길이 없기 때문에 항상 호출 간에 값을 전사(transcribe)해야 하며, 이 과정에서 가끔 실수가 발생합니다. 예를 들어, 한 궤적에서는 검색된 문서의 값 3,501이 다음 호출에서 3531로 잘못 입력되었습니다.
MemEx를 사용한 에이전트 병렬 사고(Agentic Parallel Thinking)
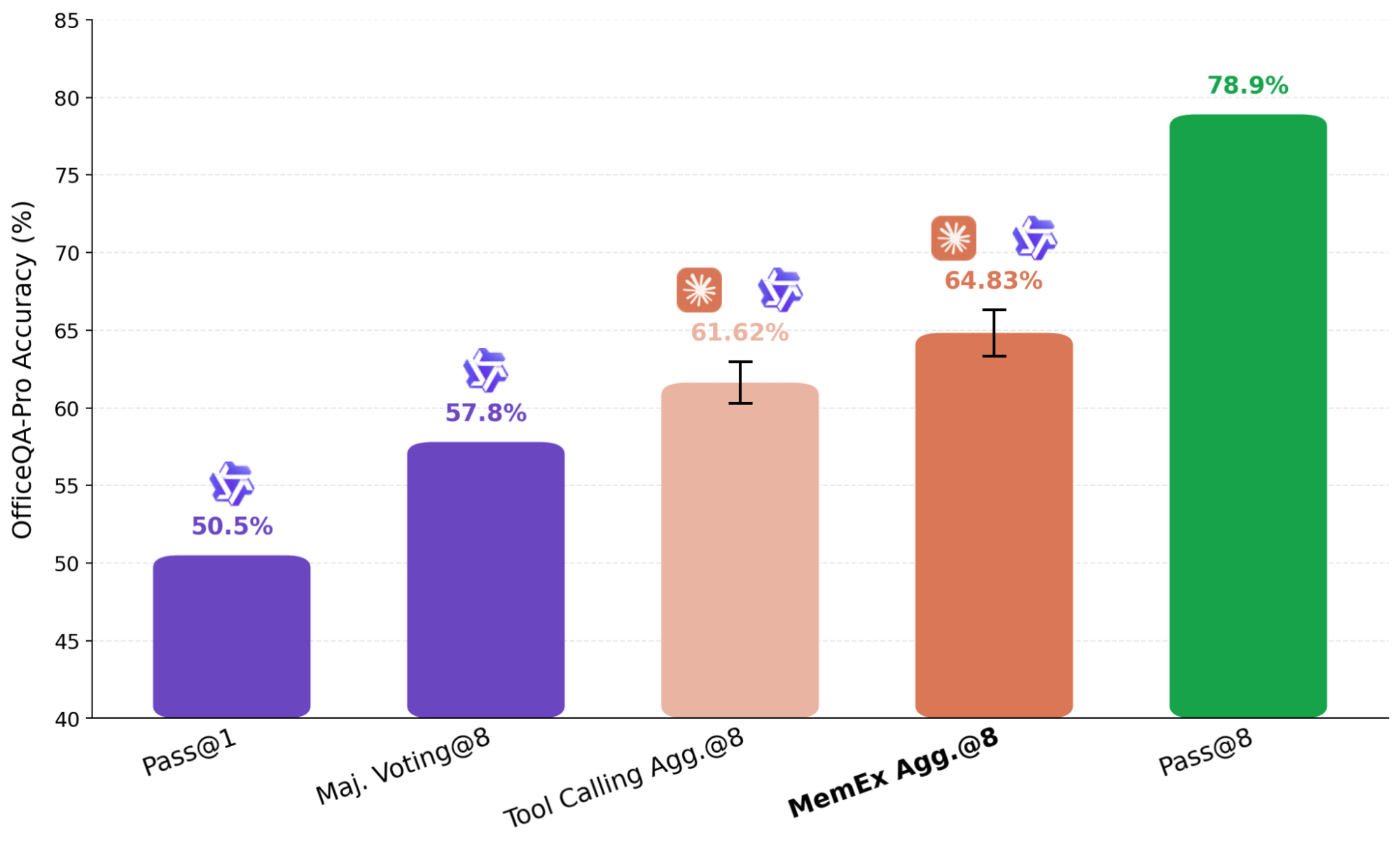
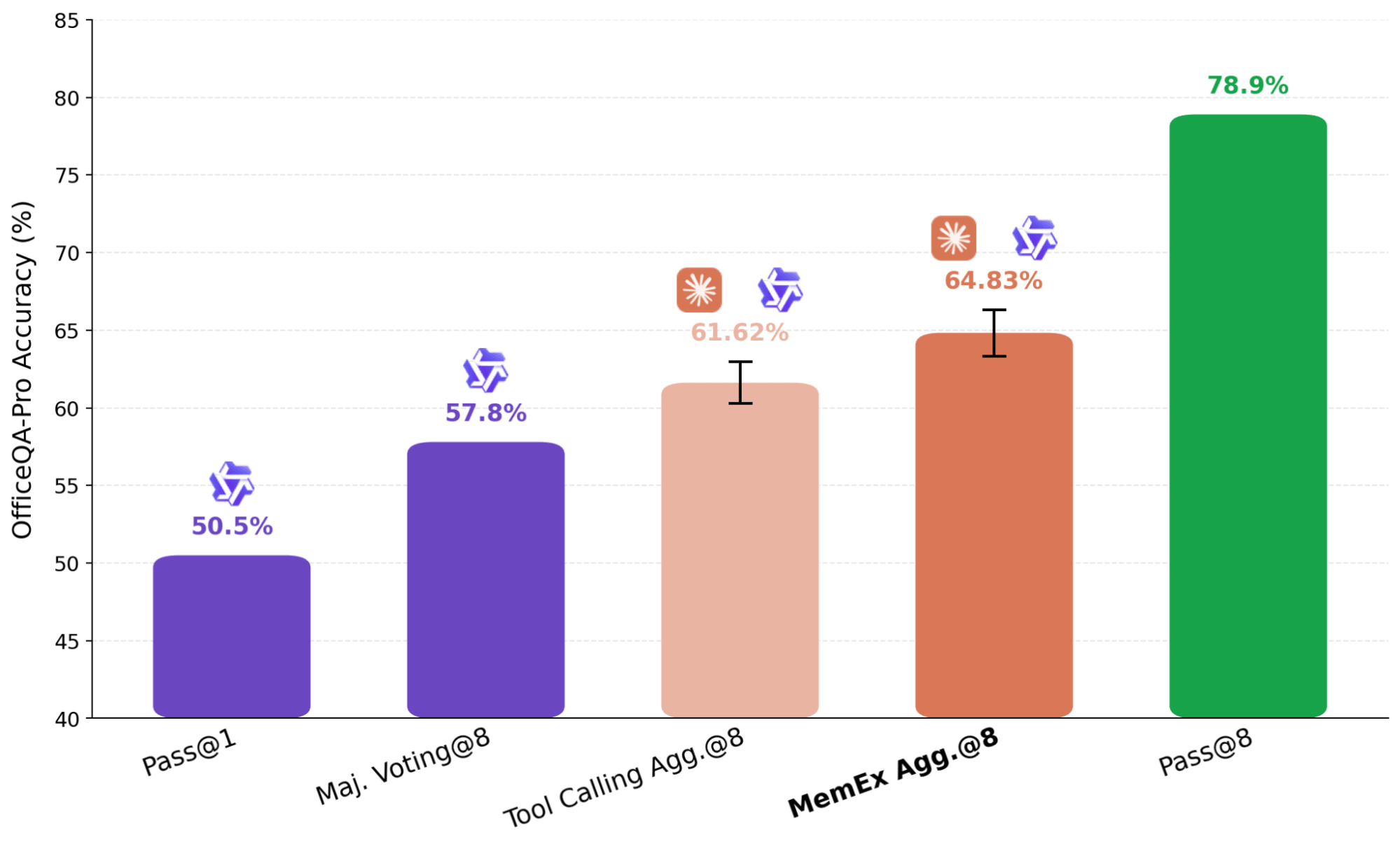
테스트 시간 계산을 스케일링하는 일반적인 접근 방식은 병렬 사고(parallel thinking)로, 하나의 작업에 대해 여러 개의 독립적인 실행(rollout)을 수행하고 이를 최종 답변으로 집계하는 것입니다. KARL에서 사용되는 방식과 같은 에이전트 병렬 사고에서는 독립적인 시도의 요약본이 집계 에이전트(aggregator agent)로 전달됩니다. 모델의 컨텍스트 창에 여러 개의 전체 궤적을 맞추는 것은 비현실적이기 때문에, 표준 설정에서 이 요약 단계는 정보 손실이 발생하지만 피할 수 없습니다. 반면 MemEx를 사용하면 이러한 궤적을 스코프 변수로 로드할 수 있으므로 정보 손실이 발생하는 표현 방식을 완전히 피할 수 있습니다.
{kind=link}
그림 7에 표시된 결과에서, 당사는 독립적으로 생성된 8개의 Qwen-3.6-27B 궤적(trajectory)에 대한 애그리게이터(aggregator)로 Claude Sonnet 4.6을 사용합니다. 애그리게이터가 단순히 스스로 문제를 다시 해결하지 않도록 파일 검색 도구를 제거하고 검증 및 선택으로 제한합니다. 전체 궤적을 입력으로 받는 MemEx 기반 에이전트는 요약만 받는 동일한 Tool Calling 에이전트보다 성능이 뛰어납니다. 한 사례에서는 궤적 애그리게이터가 입력 궤적에서 원시 도구 출력(raw tool outputs)을 읽어 이전 게시판의 중복 오류를 잡아냈습니다. 반면 Tool Calling 애그리게이터는 입력이 요약으로 제한되어 중복 데이터 주장을 검증할 수 없었고, 손상된 소스에 대한 다수결에 의존해야 했습니다.
MemEx 아키텍처
Tool Calling 에이전트는 ReAct(Yao et al., 2022)가 도입한 행동-관찰 루프(action-observation loop)에서 턴당 하나 이상의 구조화된 도구 호출(JSON 또는 XML)을 내보내며, 각 호출은 사전 정의된 도구 스키마를 따릅니다. CodeAct(Wang et al., 2024)는 이 형식을 영구적인 Python 커널로 대체했습니다. 에이전트는 임의의 Python 코드를 내보내고, 변수 및 함수 정의는 여러 턴에 걸쳐 유지됩니다. 동일한 패러다임의 ��프로덕션 변형으로는 Anthropic의 Programmatic Tool Calling(PTC) 및 Cloudflare Code Mode가 있습니다. PTC는 동일한 컨테이너를 재사용하여 여러 요청 간에 상태를 유지하는 반면, Code Mode는 유지하지 않습니다. MemEx는 이 패러다임을 확장하여 다음과 같은 네 가지 기능을 추가합니다.
- 매개변수 스키마가 보존되는 드롭인(drop-in) 도구 통합.
- 롤아웃(rollout) 시작 시 라이브 Python 스코프 제공.
- 구조화된 반환을 위한 타입이 지정된
submit(). - 병렬 서브 에이전트를 위한 비차단(non-blocking)
spawn_agent()로, Recursive Language Models(Zhang et al., 2025)을 일반화합니다.
구현은 세 가지 설계 선택 사항을 기반으로 합니다.
영구 REPL에서의 행동으로서의 코드
에이전트의 행동은 임의의 Python 코드 블록이며, 여러 턴에 걸쳐 유지되는 네임스페이스에서 실행됩니다. 도구, 스코프 객체 및 이전 결과는 모두 해당 네임스페이스에 존재합니다. 에이전트는 관찰 결과(stdout, 반환 값, 오류)를 읽은 다음 더 많은 코드를 작성합니다. Tool Calling을 실행하는 동일한 관찰-행동 루프(observe-act loop)가 MemEx를 실행하며, 행동 공간(action space)만 변경됩니다.
Tool Calling을 위한 드롭인 대체
기존 Tool Calling 도구는 매개변수 스키마 및 반환 타입 메타데이터를 포함하여 Python 함수로 자동 주입됩니다. 기존 에이전트를 Tool Calling에서 MemEx로 전환하는 것은 단 한 번의 구성 변경으로 가능합니다.
백엔드에 구애받지 않는 실행
동일한 에이전 코드가 구성 시 선택된 세 가지 백엔드에서 실행됩니다.
- 연구 중 빠른 반복 작업을 위한 인프로세스(In-process).
- 평가 중 격리를 위한 서브프로세스(Subprocess).
- 고처리량 배치 생성(학습 데이터, 대규모 롤아웃)을 위한 풀(Pool).
프로덕션 배포의 경우 커널을 Anthropic의 Managed Agents와 같은 호스팅된 샌드박스로 교체할 수 있습니다. 동일한 에이전트 코드를 사용하면서 파일 시스템 격리, 네트워크 아웃바운드(egress) 제어 및 리소스 제한은 호스트에서 처리됩니다.
다음 단계는 무엇인가요?
MemEx가 여러분의 에이전트에 적용됩니다. 당사는 Databricks의 퍼스트 파티 에이전트 및 Agent Bricks 전반에 걸쳐 이를 출시하고 있습니다. 현재 Databricks 에이전트를 기반으로 구축하고 계시다면 곧 MemEx를 사용하실 수 있습니다.
당사는 MemEx 행동 공간에 맞게 모델을 사후 학습(post-training)하고 있습니다. MemEx 자체는 기질(substrate) 역할을 하여 합성 데이터를 생성하고, 에이전트 기반 검증기(agentic verifier)��를 실행하며, 학습 루프에 데이터를 공급합니다.
저자: Ashutosh Baheti, Shubham Toshniwal, Arnav Singhvi, Krista Opsahl-Ong, Sean Kulinski, Sam Havens, Jonathan Li, Marco Cusumano-Towner, Jonathan Chang, Wen Sun, Alexander Trott, Jonathan Frankle, Xing Chen, Matei Zaharia
1 MemEx에서 도구 호출은 데이터 분석 또는 비동기 함수로 호출되는 기타 도구를 가질 수 있는 Python 코드 블록입니다.
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.