직접 코딩하는 변경 데이터 캡처 파이프라인을 중단하세요
AutoCDC가 CDC 및 느린 변경 차원을 자동화하는 방법
작성자: Matt Jones, 조에 두랑, 피비 와이저, Bilal Aslam , Ray Zhu
- 수동으로 코딩된 CDC 및 SCD 파이프라인이 대규모로 운영하기에 왜 취약하고 복잡하며 비용이 많이 드는지
- AutoCDC가 SCD Type 1, SCD Type 2 및 스냅샷 기반 CDC 패턴을 선언적으로 자동화하는 방법
- 프로덕션 AutoCDC 워크로드에서 얻는 정확성, 성능 및 비용의 실제적인 이점
Python에서 스냅샷을 이용한 AutoCDC를 사용해 보았는데, 이전에는 1,500줄의 코드로 하던 작업을 단 4줄의 코드로 대체할 수 있다는 사실에 놀랐습니다. —Fortune 500 항공우주 및 국방 회사 선임 데이터 엔지니어
변경 데이터 캡처(CDC)와 느린 변경 차원(SCD)은 최신 분석 및 AI 워크로드의 기반입니다. 팀은 운영 데이터가 변경될 때 비즈니스의 현재 상태를 유지하든 전체 기록 컨텍스트를 보존하든 관계없이 다운스트림 테이블을 정확하게 유지하기 위해 이러한 기능에 의존합니다.
하지만 실제로는 CDC 파이프라인이 종종 구축하고 운영하기 가장 어려운 파이프라인 중 하나입니다. 팀은 업데이트, 삭제 및 �지연 도착 데이터를 처리하기 위해 일반적으로 복잡한 MERGE 로직을 직접 작성합니다. 이는 추론하기 어렵고 파이프라인이 발전함에 따라 유지 관리하기가 더욱 어려운 스테이징 테이블, 윈도우 함수 및 시퀀싱 가정을 계층화합니다.
이 게시물에서는 데이터 엔지니어와 SQL 실무자가 매일 접하는 CDC 및 SCD 패턴, 이러한 패턴을 수동으로 구현하기 어려운 이유, 그리고 Lakeflow Spark 선언형 파이프라인의 AutoCDC가 가격 및 성능 면에서 의미 있는 개선을 제공하면서 이를 선언적으로 자동화하는 방법을 살펴봅니다.
데이터 엔지니어에게 CDC 및 SCD는 여전히 어렵습니다
이러한 패턴을 잘 이해하는 팀조차도 이를 정확하게 구현하고 시간이 지남에 따라 정확하게 유지하는 것이 문제가 됩니다. 데이터 볼륨이 증가하고 사용 사례가 확장됨에 따라 파이프라인은 취약해지고, 정확성 문제가 늦게 발생하며, 다운스트림 테이블을 손상시키지 않기 위해 작은 변경에도 신중한 재작성이 필요합니다.
SCD Type 1 테이블 유지 관리
SCD Type 1 테이블은 최신 상태를 반영하기 위해 기존 행을 덮어씁니다. 이 “간단한” 경우조차도 빠르게 문제가 발생합니다.
- 업데이트가 순서대로 도착하지 않음
- 중복 이벤트는 일관되게 중복 제거되어야 함
- 삭제는 올바르게 적용되어야 함
- 재시도 및 재처리에 걸쳐 로직은 멱등성을 유지해야 함
단순한 MERGE INTO 로 시작된 것이 스테이징 테이블, 윈도우 함수 및 추론하거나 안전하게 변경하기 어려운 시퀀싱 가정을 포함하는 깊이 중첩된 로직으로 발전합니다. 시간이 지남에 따라 팀은 이러한 파이프라인을 전혀 건드리지 않게 됩니다.
SCD Type 2 기록 유지 관리
SCD Type 2는 추가적인 복잡성을 도입합니다.
- 행 버전 및 유효성 기간 추적
- 기록을 손상시키지 않고 지연 도착 업데이트 처리
- 항상 정확히 하나의 “현재” 버전이 존재하도록 보장
여기서의 실수는 항상 명확하게 실패하는 것은 아닙니다. 종종 몇 주 후에 미묘한 메트릭 드리프트로 나타나거나 전체 기록 테이블을 다시 구축해야 하는 필요성이 발생합니다.
다양한 소스에서 변경 데이터 추출
모든 시스템이 깨끗한 CDC 로그를 내보내는 것은 아닙니다. 일부 시스템은 네이티브 변경 데이터 피드를 내보내지만 다른 시스템은 그렇지 않습니다. 종종 데이터를 소비하는 팀이 업스트림 데이터베이스를 제어하지 않기 때문입니다. 이로 인해 팀은 소스 테이블의 연속적인 스냅샷을 비교하여 변경 사항을 재구성해야 합니다.
둘 다 지원하는 것은 일반적으로 별도의 수집 및 처리 로직, 다른 정확성 가정, 그리고 유지 관리 및 디버그할 코드 경로가 더 많다는 것을 의미합니다.
시간 경과에 따른 CDC 파이프라인 운영
CDC 파이프라인이 올바르게 작동하더라도 재처리 및 백필, 스키마 진화, 실패 및 재시작을 견뎌야 합니다. 수동으로 작성된 CDC 로직은 이러한 현실이 누적됨에 따라 시간이 지남에 따라 더욱 취약해지는 경향이 있으며, 운영 위험과 유지 관리 비용을 증가시킵니다.
선언형 데이터 엔지니어링으로 복잡한 CDC 패턴 자동화
AutoCDC는 이러한 일반적인 CDC 및 SCD 패턴을 선언적 추상화 뒤에 표준화하도록 설계되었습니다. 변경 ��사항을 적용하는 방법을 직접 코딩하는 대신, 팀은 원하는 의미 체계를 선언하고 플랫폼이 순서 지정, 상태 및 증분 처리를 관리합니다.
| CDC 워크로드 | AutoCDC | 직접 작성한 MERGE / 스냅샷 로직 |
|---|---|---|
| 현재 상태 테이블 유지 관리 (SCD Type 1) | 선언형 파이프라인 정의는 순서 지정, 중복 제거 및 삭제를 자동으로 처리합니다. | 윈도우 함수 및 순서 지정 규칙을 사용한 사용자 지정 MERGE 로직 |
| 기록 테이블 유지 관리 (SCD Type 2) | 내장된 기록 추적을 통한 자동 버전 관리 | 레코드 버전 마감 및 삽입을 위한 다단계 MERGE 로직 |
| 스냅샷 소스에서 변경 사항 추론 | 내장된 스냅샷 CDC 지원 | 조인 및 비교를 사용한 수동 스냅샷 diff 파이프라인 |
| 파이프라인을 안정적으로 운영 (지연 데이터, 재시도, 재처리) | 자동 순서 지정 및 멱등성 실행 | 사용자 지정 보호 장치 및 추가 로직 필요 |
| 코드 풋프린트 및 운영 복잡성 | ~6–10줄의 선언형 파이프라인 정의 | 40–200줄 이상의 사용자 지정 파이프라인 로직 |
이를 통해 팀은 패턴을 매번 재발명하는 대신(이는 일반적으로 선언형 프로그래밍, 특히 Spark 선언형 파이프라인의 핵심 가치입니다) 파이프라인 전반에 걸쳐 CDC 및 SCD를 구현하는 일관되고 반복 가능한 방법을 갖게 됩니다.
�변경 데이터 피드(CDF)에서 변경 레코드를 처리할 때 AutoCDC는 순서가 잘못된 레코드를 자동으로 처리하고 선언된 시퀀싱 열을 기반으로 업데이트를 올바르게 적용합니다. 실제 작동 방식을 보여주기 위해 아래 샘플 CDC 피드를 살펴보겠습니다.
| userId | name | city | operation | sequenceNum |
|---|---|---|---|---|
| 124 | Raul | Oaxaca | INSERT | 1 |
| 123 | Isabel | Monterrey | INSERT | 1 |
| 125 | Mercedes | Tijuana | INSERT | 2 |
| 126 | Lily | Cancun | INSERT | 2 |
| 123 | null | null | DELETE | 6 |
| 125 | Mercedes | Guadalajara | UPDATE | 6 |
| 125 | Mercedes | Mexicali | UPDATE | 5 |
| 123 | Isabel | Chihuahua | UPDATE | 5 |
최신 데이터만 유지하려면 SCD Type 1을 선택하고, 기록을 유지하려면 SCD Type 2를 선택해야 합니다. Type 1부터 시작하겠습니다.
SCD Type 1 유지 관리 자동화 (변경 데이터 피드 소스)
이 예에서는 변경 데이터 피드에 사용자 테이블에 대한 삽입, 업데이트 및 삭제가 포함되어 있습니다. 목표는 새 업데이트가 이전 값을 덮어쓰는 각 레코드의 현재 뷰를 유지하는 것입니다.
SCD Type 1에 대한 출력 테이블
| id | name | city |
|---|---|---|
| 124 | Raul | Oaxaca |
| 125 | Mercedes | Guadalajara |
| 126 | Lily | Cancun |
사용자 123(Isabel)은 삭제되었으므로 출력에 나타나지 않습니다. 사용자 125(Mercedes)는 SCD Type 1이 이전 값을 덮어쓰기 때문에 최신 도시(Guadalajara)만 표시합니다.
기존 접근 방식으로는 중복 이벤트를 제거하고, 순서를 강제하고, 삭제를 적용하고, 재시도 또는 지연 도착 데이터에 걸쳐 파이프라인이 올바르게 유지되도록 하기 위해 사용자 지정 MERGE 로직이 필요합니다. AutoCDC는 이러한 취약한 로직을 선언형 파이프라인 정의로 대체하여 순서 지정, 중복 제거, 지연 도착 데이터 및 증분 처리를 자동으로 처리하여 수십 줄의 사용자 지정 병합 로직을 제거합니다.
전체 코드 예시는 부록에서 확인하세요.
SCD Type 2 기록 자동화 (변경 데이터 피드 소스)
많은 분석 시스템에서 최신 상태만 유지하는 것으로는 충분하지 않습니다. 팀은 시간 경과에 따른 레코드 변경 기록이 모두 필요합니다. 이것이 SCD Type 2 패턴이며, 각 레코드 버전은 활성 기간을 나타내는 유효성 기간과 함께 저장됩니다.
SCD Type 2에 대한 출력 테이블:
| id | name | city | __START_AT | __END_AT |
|---|---|---|---|---|
| 123 | Isabel | Monterrey | 1 | 5 |
| 123 | Isabel | Chihuahua | 5 | 6 |
| 124 | Raul | Oaxaca | 1 | NULL |
| 125 | Mercedes | Tijuana | 2 | 5 |
| 125 | Mercedes | Mexicali | 5 | 6 |
| 125 | Mercedes | Guadalajara | 6 | NULL |
| 126 | Lily | Cancun | 2 | NULL |
테이블은 전체 기록을 보존합니다. 사용자 123은 두 개의 버전을 가지고 있습니다(삭제 시 시퀀스 6에서 종료됨). 사용자 125는 도시 변경 사항을 보여주는 세 개의 버전을 가지고 있습니다. __END_AT = NULL이 있는 레코드는 현재 활성 상태입니다.
이를 수동으로 구현하려면 이전 레코드를 종료하고 새 버전을 삽입하며 한 번에 하나의 버전만 활성 상태로 유지되도록 하는 다단계 MERGE 로직이 필요합니다. AutoCDC는 이러한 전환을 선언적으로 자동화하여 기록 열과 버전 관리 로직을 자동으로 관리하면서 순서가 잘못된 업데이트가 도착하더라도 정확성을 보장합니다.
전체 코드 예시는 부록에서 확인하세요
스냅샷 소스에서 CDC 추론
모든 소스 시스템이 변경 로그를 내보내는 것은 아닙니다. 많은 경우 팀은 소스 테이블의 주기적인 스냅샷을 받고 실행 간에 변경된 내용을 추론해야 합니다.
전통적으로 이를 위해서는 실행 간에 변경된 내용을 추론하기 위해 수동으로 스냅샷을 비교하여 삽입, 업데이트 및 삭제를 감지한 다음 MERGE 로직으로 해당 변경 사항을 적용해야 합니다. AutoCDC는 스냅샷 기반 CDC를 기본 패턴으로 취급하여 사용자 지정 diff 로직이나 상태 관리가 필요 없이 스냅샷 간의 행 수준 변경 사항을 자동으로 감지하고 점진적으로 적용합니다.
이를 수동으로 구현하려면 스냅샷 간의 행 수준 변경 사항을 감지하고 이전에 활성 상태였던 레코드를 종료한 다음 업데이트된 유효성 기간이 있는 새 버전을 삽입해야 합니다. AutoCDC는 이러한 변경 사항을 자동으로 파생하고 SCD Type 2 의미 체계를 적용하여 다단계 병합 로직이나 사용자 지정 스냅샷 상태 추적이 필요 없이 버전 기록을 유지합니다.
순서, 상태 및 재처리 관리
Lakeflow Spark Declarative Pipelines는 점진적 진행 상황을 자동으로 추적하고 순서가 잘못된 데이터를 처리합니다. 파이프라인은 실패에서 복구하고, 과거 데이터를 재처리하고, 변경 사항을 두 번 적용하거나 손실하지 않고 시간이 지남에 따라 발전할 수 있습니다.
실질적으로 이는 팀이 시퀀싱 로직, 워터마크 북키핑 또는 재처리 안전을 직접 관리할 필요성을 제거합니다. 플랫폼이 이를 처리합니다.
새로운 기능: 주요 가격 및 성능 향상
파이프라인 로직을 단순화하는 것 외에도 최근 Databricks Runtime 개선 사항은 2025년 11월 이후 AutoCDC 워크로드의 성능과 비용 효율성 모두에서 상당한 향상을 가져왔습니다.
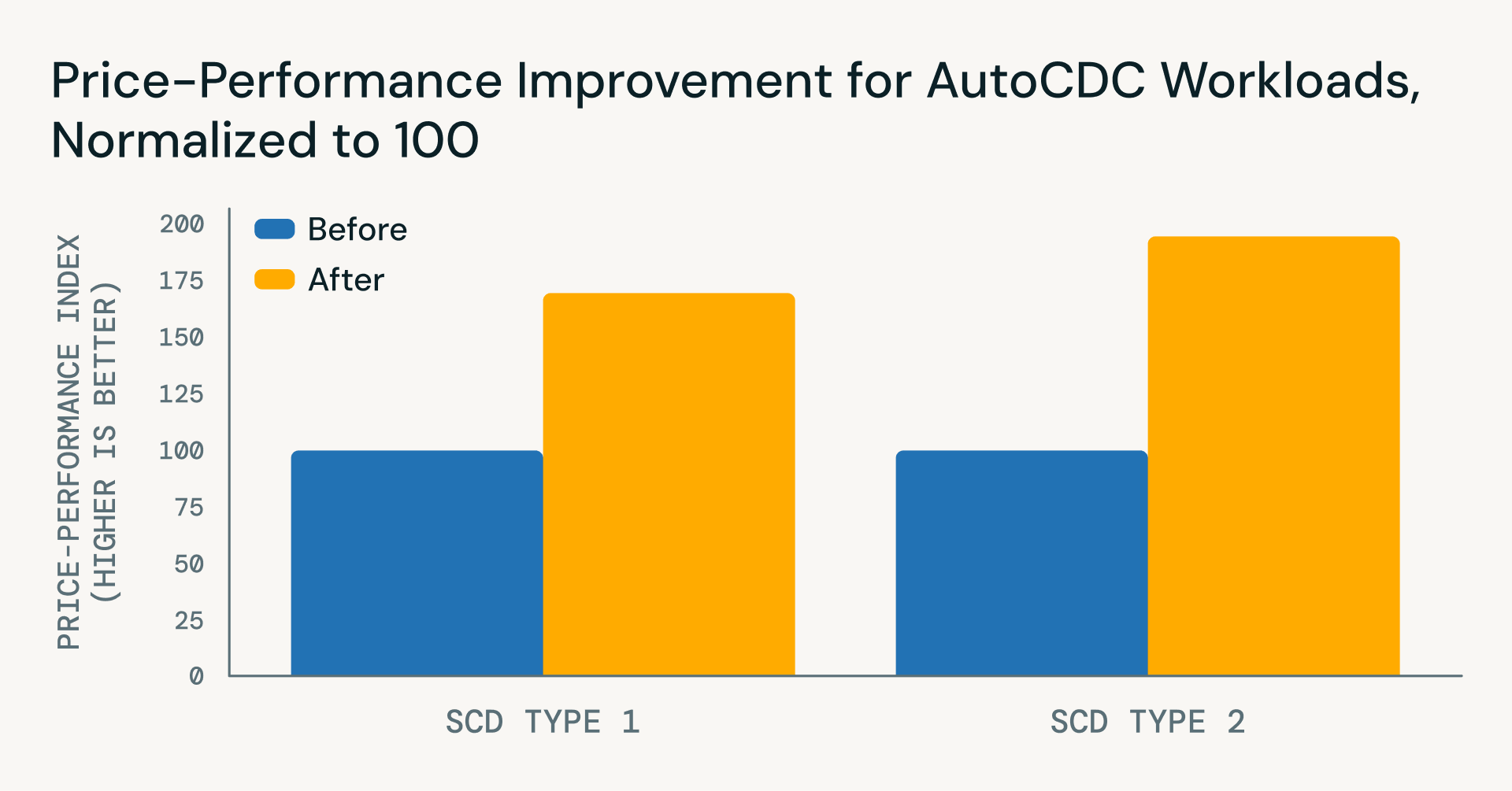
- SCD Type 1
- 잠재 시간 ~22% 향상
- 비용 ~40% 절감
- 순 가격-성능 이점 ~71%
- SCD Type 2
- 잠재 시간 ~45% 절감
- 증분 업데이트 비용 ~35% 절감
- 순 가격-성능 이점 ~96%
이러한 이점은 대규모로 지속적으로 실행되는 실제 파이프라인에 중요합니다. MERGE INTO는 여전히 기본적인 Spark 기본 요소이지만, AutoCDC는 데이터 볼륨이 증가함에 따라 순서가 잘못된 데이터와 증분 처리를 더 효율적으로 처리하기 위해 이를 기반으로 구축됩니다.
AutoCDC를 통한 고객 성공
프로덕션에서 CDC 및 SCD 파이프라인을 실행하는 팀은 AutoCDC가 상당한 가치를 제공한다고 명시적으로 언급했습니다.
Navy Federal Credit Union은 Lakeflow Spark Declarative Pipelines에서 AutoCDC를 사용하여 대규모 실시간 이벤트 처리를 지원합니다. 수십억 개의 애플리케이션 이벤트를 지속적으로 처리하면서 사용자 지정 CDC 코드 및 지속적인 파이프라인 유지 관리를 제거합니다.
Spark Declarative Pipelines 프로그래밍 모델의 단순성과 서비스 기능이 결합되어 매우 빠른 전환 시간을 제공했습니다. —Jian (Miracle) Zhou, Senior Engineering Manager, Navy Federal Credit Union
Block은 Lakeflow Spark Declarative Pipelines에서 AutoCDC를 사용하여 Delta Lake에서 변경 데이터 캡처 및 실시간 스트리밍 파이프라인을 단순화합니다. 수동으로 코딩된 CDC 및 병합 로직을 구현하기 빠르고 운영하기 쉬운 선언적 접근 방식으로 대체합니다.
Spark Declarative Pipelines를 채택하면서 스트리밍 파이프라인을 정의하고 개발하는 데 걸리는 시간이 며칠에서 몇 시간으로 줄었습니다. —Yue Zhang, Staff Software Engineer, Data Foundations, Block
스위스 기반의 선도적인 "foodvenience" 제공업체인 Valora Group은 Lakeflow Spark Declarative Pipelines에서 AutoCDC를 사용하여 마스터 데이터 및 실시간 소매 분석을 위한 변경 데이터 캡처를 간소화합니다. 사용자 지정 CDC 코드를 구현, 반복 및 팀 전체에 확장하기 쉬운 선언적 접근 방식으로 대체합니다.
SDP에서 CDC를 수행함으로써 많은 것을 얻었습니다. 코드를 작성하지 않고 모든 것이 백그라운드에서 추상화되기 때문입니다. AutoCDC는 줄 수를 최소화합니다... 매우 쉽게 할 수 있습니다. —Alexane Rose, Data and AI Architect, Valora Holding
시작하기
AutoCDC는 Databricks의 Lakeflow Spark Declarative Pipelines의 일부로 제공됩니다.
자세히 알아보기:
- AutoCDC 설명서(SQL 및 Python) 검토
- SCD Type 1, SCD Type 2 및 스냅샷 기반 CDC 예제 탐색
자체 파이프라인에서 AutoCDC를 사용해보고 수동으로 작성된 CDC 로직을 제거하세요!
부록
SCD Type 1 예제
| MERGE | AutoCDC |
from delta.tables import DeltaTable
from pyspark.sql.functions import max_by, struct
# Deduplicate: keep latest record per userId
updates = (spark.read.table("cdc_data.users")
.groupBy("userId")
.agg(max_by(struct("*"), "sequenceNum").alias("row"))
.select("row.*"))
# Apply SCD Type 1: upsert updates, delete deletions
(DeltaTable.forName(spark, "target")
.alias("t")
.merge(updates.alias("s"), "s.userId = t.userId")
.whenMatchedDelete(condition="s.operation = 'DELETE'")
.whenMatchedUpdate(
condition="s.sequenceNum > t.sequenceNum",
set={"name": "s.name", "city": "s.city", "sequenceNum": "s.sequenceNum"}
)
.whenNotMatchedInsertAll(condition="s.operation != 'DELETE'")
.execute())
| from pyspark import pipelines as dp
from pyspark.sql.functions import col, expr
@dp.view
def users():
return spark.readStream.table("cdc_data.users")
dp.create_streaming_table("target")
dp.create_auto_cdc_flow(
target="target",
source="users",
keys=["userId"],
sequence_by=col("sequenceNum"),
apply_as_deletes=expr("operation = 'DELETE'"),
stored_as_scd_type=1
)
|
SCD Type 2 예제
| MERGE | AutoCDC |
from delta.tables import DeltaTable
from pyspark.sql.functions import col, lit, max_by, struct
# Deduplicate: keep latest record per userId
updates = (spark.read.table("cdc_data.users")
.groupBy("userId")
.agg(max_by(struct("*"), "sequenceNum").alias("row"))
.select("row.*"))
# Step 1: close out active rows for records being updated or deleted
(DeltaTable.forName(spark, "target")
.alias("t")
.merge(
updates.alias("s"),
"s.userId = t.userId AND t.__END_AT IS NULL AND s.sequenceNum > t.__START_AT"
)
.whenMatchedUpdate(set={"__END_AT": "s.sequenceNum"})
.execute())
# Step 2: insert new rows for inserts and updates (not deletes)
new_rows = (updates
.filter("operation != 'DELETE'")
.withColumn("__START_AT", col("sequenceNum"))
.withColumn("__END_AT", lit(None).cast("long"))
.drop("operation"))
new_rows.write.mode("append").saveAsTable("target")
| dp.create_auto_cdc_flow(
target="target",
source="users",
keys=["userId"],
sequence_by=col("sequenceNum"),
apply_as_deletes=expr("operation = 'DELETE'"),
stored_as_scd_type=2
)
|
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.