에이전트가 엔터프라이즈 문서를 읽지 못하는 이유 — 해결 방법
Databricks에서 Document Intelligence 소개
작성자: Archika Dogra, 세르게이 차레프 , 에릭 엘센
- 프론티어 에이전트는 실제 엔터프라이즈 문서 작업에서 여전히 50% 미만의 점수를 기록합니다. 병목 현상은 추론이 아니라 읽기 능력에 있습니다.
- 문서 처리는 모든 에이전트 워크플로우의 정확도 상한선입니다.
- 이러한 격차를 해소하기 위해 Document Intelligence를 발표합니다. 연구 기반의 정확성, 엔터프라이즈 규모, 그리고 엔드투엔드 단순성을 제공합니다.
가장 중요한 비즈니스 인텔리전스는 단순히 웨어하우스에 저장되는 것이 아니라, 매일 핵심 엔터프라이즈 워크플로우를 구동하는 수백만 개의 문서 속에 존재합니다. 예를 들어 계약서, 청구서, 송장 등이 있습니다. 지난 10년 동안 지능형 문서 처리(IDP)는 협소한 백오피스 자동화 문제로 취급되었습니다. 에이전트 시대에는 상황이 근본적으로 다릅니다. IDP는 에이전트가 신뢰할 수 있는 결정을 내릴 수 있는지 여부를 결정하는 중요한 기반입니다.
보험 청구 처리를 예로 들어보겠습니다. 이론적으로는 청구를 수집하고, 세부 정보를 추출하고, 이상 징후를 표시하고, 라우팅하는 이상적인 에이전트 워크플로우입니다. 오늘날의 최신 에이전트는 추론을 쉽게 처리합니다. 하지만 문제가 발생하는 지점은 문서 판독입니다. 일관성 없는 레이아웃, 중첩된 표, 손글씨 메모, 공급업체마다 다른 형식의 스캔된 PDF 문서들입니다. "10,000달러"가 "3,000달러"로 환각되어 에이전트가 잘못된 결정을 내리고, 잘못된 금액이 조용히 지급됩니다.
이러한 패턴은 전반적으로 나타나고 있습니다. 에이전트는 깨끗한 텍스트에 대해서는 잘 추론하지만, 실제 엔터프라이즈 문서를 접하면 제대로 작동하지 않습니다. 몇 달 전, Databricks AI Research는 실제 엔터프라이즈 문서 워크플로우를 기반으로 한 벤치마크인 OfficeQA를 발표했습니다. 우리는 매우 유능한 최신 에이전트조차 문서 추론 작업에서 50% 미만의 정확도를 기록했음을 발견했습니다. 병목 현상은 추론이 아니라 판독이었습니다.
이것이 바로 Databricks가 Document Intelligence를 발표하게 된 이유입니다. Document Intelligence는 연구 기반의 정확성, 엔터프라이즈 규모, 그리고 엔드투엔드 단순성이라는 세 가지 핵심 기둥 위에 구축되었습니다.
Intercontinental Exchange에서는 매달 수백만 건의 복잡하고 가변성이 높은 금융 문서를 처리합니다. Document Intelligence는 이러한 복잡성을 구조화된 시장 인텔리전스로 전환하여, 우리가 더 빠르게 움직이고, 고객에게 더 큰 가치를 제공하며, 대규모 분석 및 의사 결정을 가속화하는 에이전트 워크플로우를 구현할 수 있도록 돕습니다." —Anand Pradhan, Intercontinental Exchange (NYSE) 모기지 데이터 CTO 겸 AI 책임자
실제 엔터프라이즈 문서에서 에이전트 품질 향상
문서 처리는 모든 에이전트의 정확도 상한선입니다. 이를 제대로 해결하기 위해 Databricks AI Research 팀은 기업이 실제로 다루는 복잡한 현실, 즉 일관성 없는 레이아웃, 중첩된 표, 이미지, 손글씨 등을 위해 설계된 전문 시스템을 구축하기 시작했습니다.
이 연구는 문서 처리를 구성 가능한 단계로 나누는 일련의 연결 가능한 AI 함수들을 지원합니다. ai_parse_document (현재 정식 출시)는 원본 스캔을 레이아웃이 풍부한 구조화된 텍스트로 변환하고, 다운스트림에서는 ai_classify가 문서를 올바르게 라우팅하고, ai_extract가 가장 중요한 핵심 구조화된 인사이트를 추출합니다. 이들은 함께 쉽게 조립할 수 있는 문서 인텔리전스 파이프라인을 형성합니다. 한 번 파싱한 다음, 원본 문서를 재처리하지 않고 분류, 추출 및 재추출할 수 있습니다.
그렇다면 더 나은 문서 처리가 실제로 에이전트를 더 정확하게 만들까요? OfficeQA를 통해 실제 국채 문서를 벤치마킹했을 때, ai_parse_document를 사용한 전처리는 우리가 테스트한 모든 에이전트 프레임워크에서 평균 16%의 성능 향상을 가져왔습니다. 에이전트의 추론 ��메커니즘은 전혀 변하지 않았지만, 그 아래의 문서 데이터 계층은 변화했습니다.
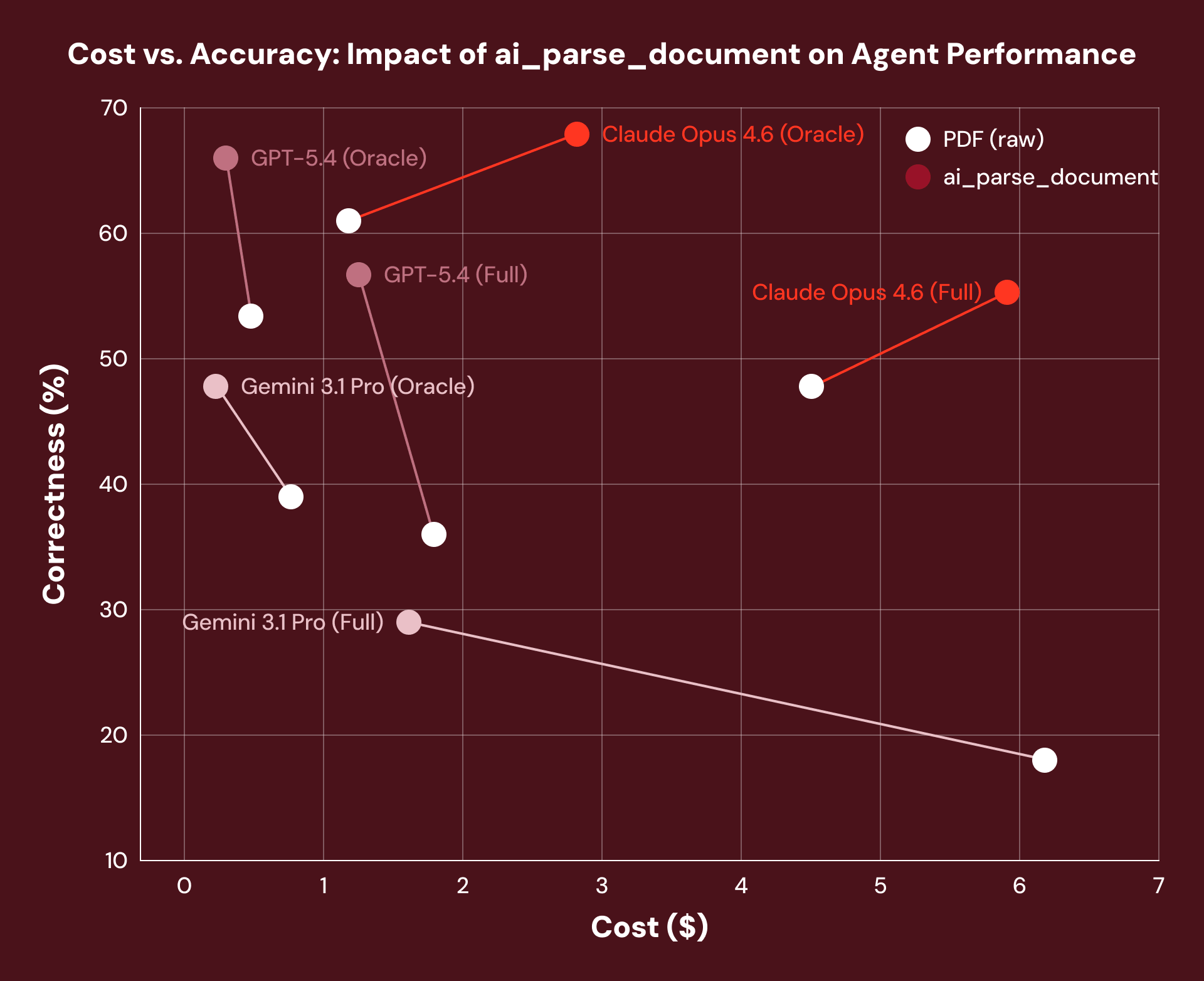
참고: Claude Opus 4.6 모델은 문서의 구조화된 레이아웃 텍스트가 제공될 때 더 많은 토큰을 검색하는 경향이 있어 비용이 증가하는 것을 확인했습니다.
이것이 바로 우리가 Document Intelligence를 에이전트 워크플로우의 기반으로 구축하는 이유입니다. 문서 처리의 품질 및 비용 절감 효과는 그 위에 구축되는 모든 것을 통해 증폭됩니다.
Document Intelligence를 통해 우리는 매년 수천 개의 조직에서 제공되고 매우 일관성 없는 형식을 아우르는 수백만 개의 비정형 기술 PDF에서 핵심 구조화된 인사이트를 추출하는 지능형 문서 처리 파이프라인의 기반을 마련하고 있습니다. —Graham Lammers, Accuris 데이터 인텔리전스 전무이사
엔터프라이즈 규모에서 문서 인텔리전스 구현
품질 문제가 해결되더라도, 엔터프라이즈 IDP의 실패 사례는 파일럿 단계에서는 성공했지만, 프로덕션 경제성을 견디지 못한 프로젝트들로 가득합니다. 이는 비용이 6자리 숫자로 불어나고, 배치 작업이 몇 시간이 아닌 며칠이 걸리기 때문입니다.
우리는 Document Intelligence를 처음부터 프로덕션 규모의 경제성을 고려하여 설계했으며, 나중에 추가한 것이 아닙니다. ai_parse_document와 같은 AI 함수는 연구를 통해 전문화되었기 때문에, 범용 모델의 계산 오버헤드 없이 최첨단 정확도를 달성합니다.
다양한 솔루션에 걸쳐 엔터프라이즈 송장, 계약서, 의료 기록 및 재무 서류에서 핵심 엔티티를 식별하는 구조화된 문서 추출 작업의 정확도와 비용을 벤치마킹했습니다. Document Intelligence는 유사한 파이프라인보다 5~7배 낮은 비용으로 일관되게 가장 높은 정확도를 달성했습니다.

참고: (파싱 + 추출)로 표시된 제품은 두 단계 파이프라인 아키텍처를 사용합니다. 즉, 재사용 가능한 실버 레이어로 한 번 파싱한 다음, 재파싱 없이 추출 및 재추출합니다. VLM 기반 제품은 모든 추출 호출 시 전체 문서를 재처리합니다.
중요하게도, 이러한 규모를 지원하기 위해 모든 AI 함수는 대용량 워크로드용으로 구축된 서버리스 배치 인프라에서 실행됩니다. 100개의 송장을 처리하는 동일한 한 줄 SQL 호출이 파이프라인을 재설계할 필요 없이 100,000개를 처리합니다.
Document Intelligence를 통해 우리는 몇 주 만에 거의 90% 낮은 비용으로 동일한 고품질 엔티티 추출을 달성했습니다. 이러한 가격-성능 혁신은 이제 우리의 프로덕션 파이프라인을 구동하여, 새로운 질병 영역으로 더 빠르게 확장하고, 수억 개의 임상 기록��을 효율적으로 처리하며, 고객에게 대규모로 인사이트를 제공할 수 있게 합니다. —Jerry Dennany, Loopback Analytics CTO
중요하게도, 대규모 처리를 위해 모든 AI 함수는 대용량 워크로드용으로 구축된 서버리스 배치 인프라에서 실행됩니다. 100개의 송장을 처리하는 동일한 한 줄 SQL 호출이 파이프라인을 재설계할 필요 없이 100,000개를 처리합니다.
파편화된 파이프라인에서 통합된 워크플로우로
오늘날 대부분의 기업에서 문서 인텔리전스는 플랫폼 기능이 아닙니다. 이는 일회성 파이프라인의 집합입니다. 단일 사용 사례를 위해 한 팀은 OCR 서비스를 연결하고, 별도의 추출 API를 추가하며, 또 다른 공급업체의 분류 모델을 통합합니다. 얼마 지나지 않아 그들은 취약한 맞춤형 글루 코드로 연결된 3~5개의 분리된 API를 관리하게 됩니다. 이는 취약하고 유지보수 비용이 많이 들며, 새벽 3시에 고장 나면 디버깅하기 거의 불가능한 파이프라인입니다. 그리고 다른 팀이 다른 문서 유형을 처리해야 할 때, 재사용할 수 있는 기반이 없어 처음부터 다시 시작해야 합니다.
이것이 바로 문서 인텔리전스를 전사적 기능이 아닌 일련의 일회성 프로젝트로 묶어두는 순환입니다. Document Intelligence는 이러한 순환을 끊습니다. 분리된 서비스를 연결하는 대신, 모든 단계가 기존 Databricks 오케스트레이션 및 거버넌스 계층 내에서 기본적으로 실행됩니다.
- Lakeflow Connect를 사용하여 문서(예: SharePoint에서)를 수집합니다.
- Lakeflow Jobs 또는 Spark Declarative Pipelines를 사용하여 전체 파이프라인을 오케스트레이션하며, 내장된 오류 처리, 관찰 �가능성, 새 문서 자동 처리가 포함됩니다.
- Unity Catalog를 사용하여 원본 문서부터 구조화된 테이블 출력까지 파이프라인 및 데이터의 엔드투엔드 계보, 보안 및 액세스 제어를 관리합니다.
- Agent Bricks 플랫폼을 사용하여 새롭고 풍부한 문서 데이터 계층에 에이전트를 구축합니다.
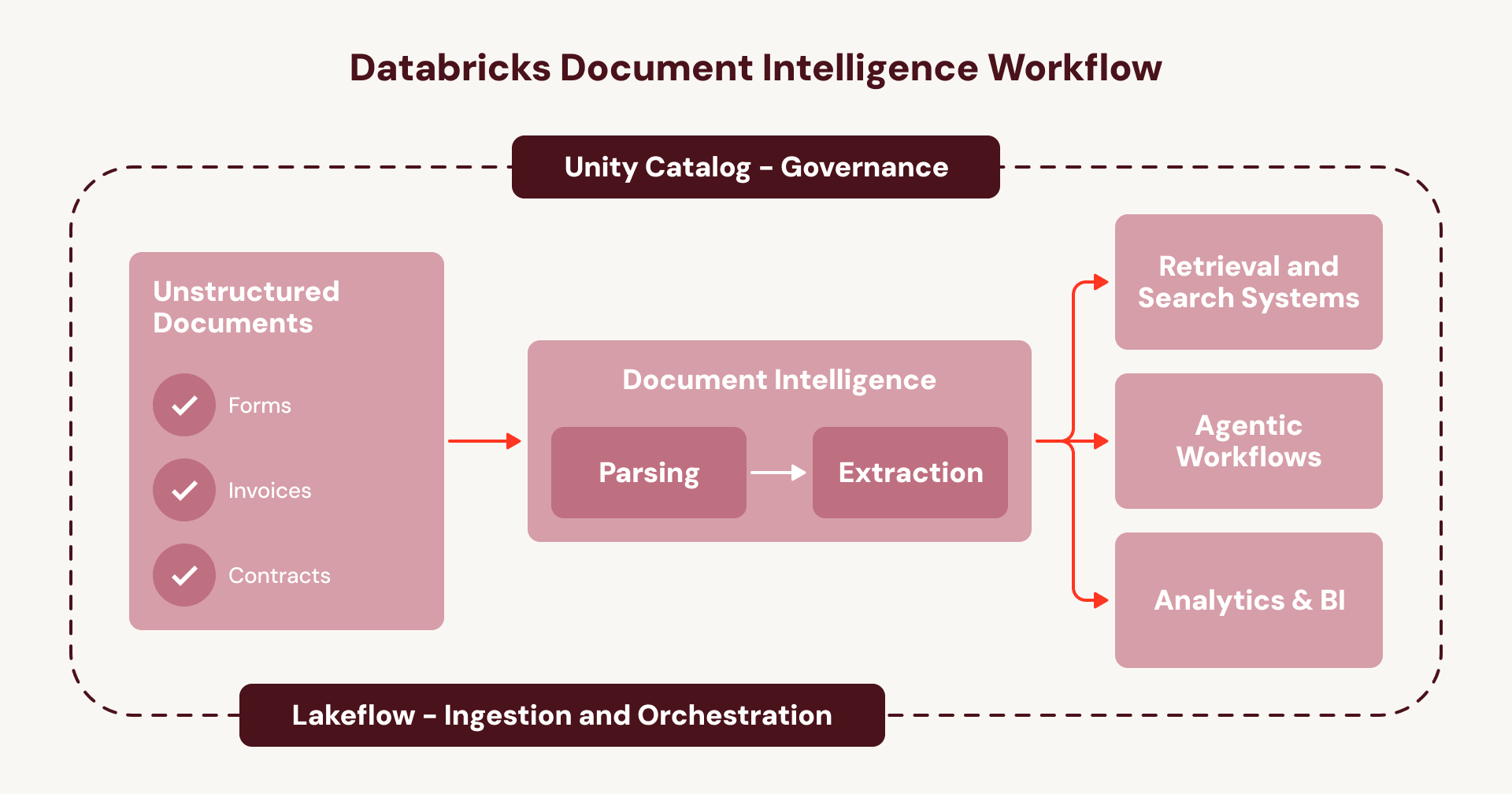
기업에게 이는 문서 인텔리전스가 불투명하고 파편화된 서비스들의 웹 대신 하나의 통합되고 관리되는 워크플로우에서 실행된다는 것을 의미합니다. 이는 모든 문서에 걸쳐 에이전트 사용 사례를 확장할 수 있는 반복 가능한 플레이북입니다.
Databricks를 통해 우리는 수동적이고 파편화된 프로세스에서 자동화되고 확장 가능한 인텔리전스로 전환했습니다. 몇 주가 걸리던 작업을 이제 며칠 만에 처리하여, 고객이 다른 곳에서는 얻을 수 없는 인사이트를 제공합니다. —Tony Qui, EY-Parthenon 글로벌 혁신 리더, 전략 및 거래
귀사의 에이전트는 문서 처리 계층만큼만 우수합�니다
엔터프라이즈 에이전트의 가능성은 대부분의 조직이 아직 답하지 못한 질문에 달려 있습니다. 귀사의 에이전트가 비즈니스 내 수백만 개의 문서를 실제로 이해할 수 있을까요?
이러한 격차를 해소하기 위해 Document Intelligence를 발표하게 되어 기쁩니다. Document Intelligence는 비즈니스에 중요한 워크플로우에 충분히 정확하며, 규정 준수 팀이 여러 공급업체에서 데이터를 추적할 필요가 없도록 엔드 투 엔드로 거버넌스되며, 코드 한 줄 변경 없이 첫 파일럿부터 프로덕션까지 확장할 수 있도록 구축되었습니다.
귀사의 문서는 엔터프라이즈에서 가장 풍부한 인텔리전스 소스입니다. 이제 귀사의 에이전트가 문서를 읽을 때입니다.
- Document Intelligence 및 Lakeflow로 구축하는 방법에 대한 저희의 방법 블로그를 읽어보세요.
- Databricks 체험판에 가입하세요.
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.