
에이전트 확산을 관리하세요. 자신 있게 에이전트를 구축하세요.
엔터프라이즈 AI 에이전트의 개발, 관리, 거버넌스를 통합합니다.데이터를 아는 에이전트
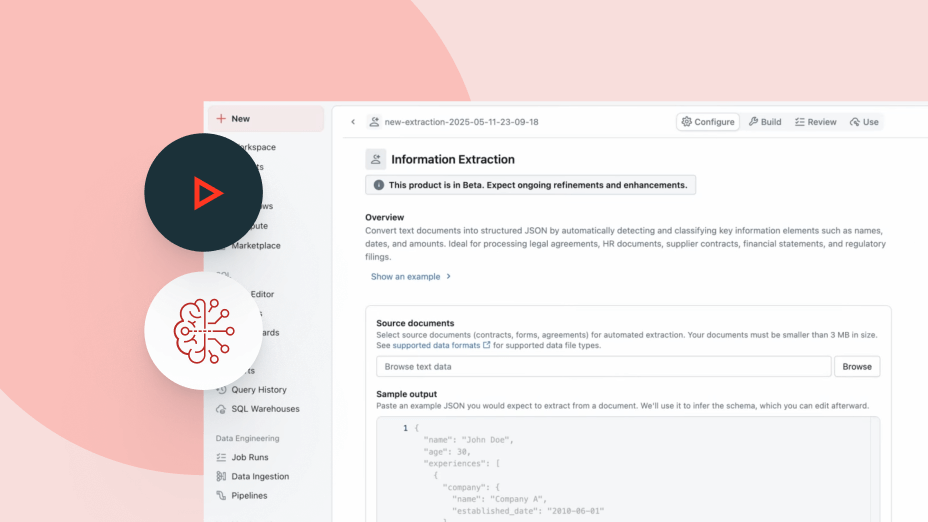
Agent Bricks는 스키마, 비즈니스 정의, 사용자 지정 시맨틱과 같은 엔터프라이즈 컨텍스트를 사용하여 어떤 도구와 테이블을 사용할지, 데이터를 올바르게 조인하는 방법, 정확하고 일관된 답변을 생성하는 방법에 대해 더 스마트한 결정을 내립니다.
오픈 및 멀티 AI
단일 플랫폼을 통해 OpenAI, Anthropic, Google부터 오픈 소스까지 모든 주요 AI 모델에 액세스하세요. Agent Bricks를 사용하면 스택을 재설계할 필요 없이 즉시 모델을 전환하여 비용, 품질, 성능을 최적화할 수 있습니다.
통합 거버넌스
오직 Databricks만이 단일 기록 시스템에서 데이터부터 AI 모델까지 전체 스택을 거버넌스합니다. 에이전트가 허용된 범위를 초과하여 액세스하지 않도록 보장하는 명확한 소유권과 엔드투엔드 권한으로 모든 에이전트, MCP 서버, 모델 및 도구를 추적하세요.

AGENT BRICKS로 성공하는 최고의 팀들
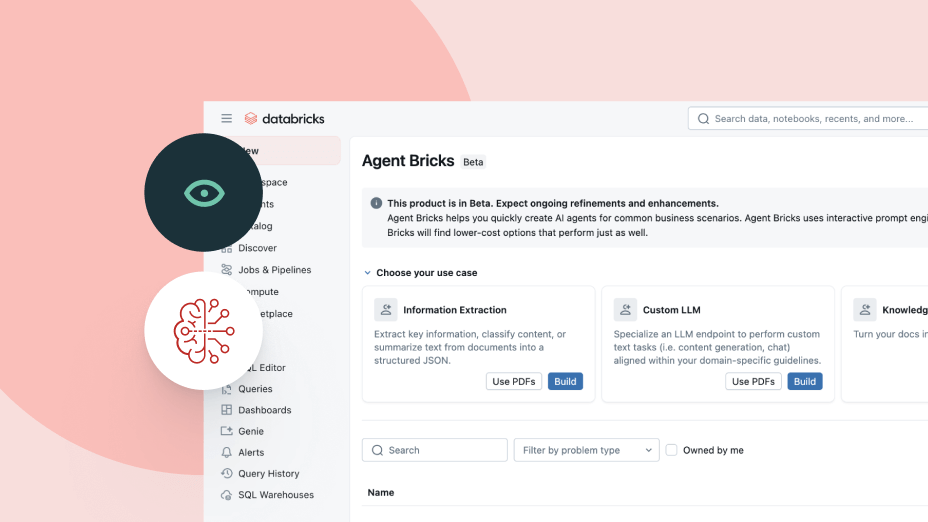
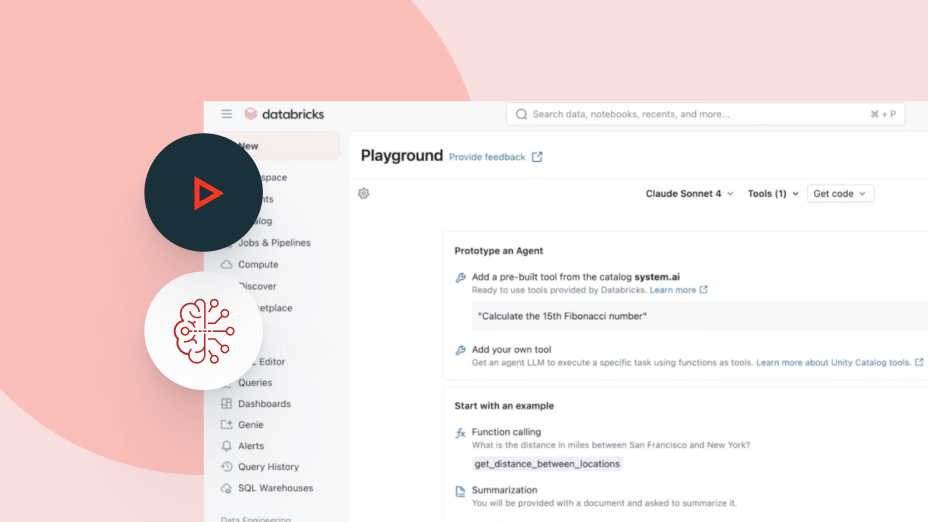
에이전트를 구축, 관리, 확장하는 데 필요한 모든 것
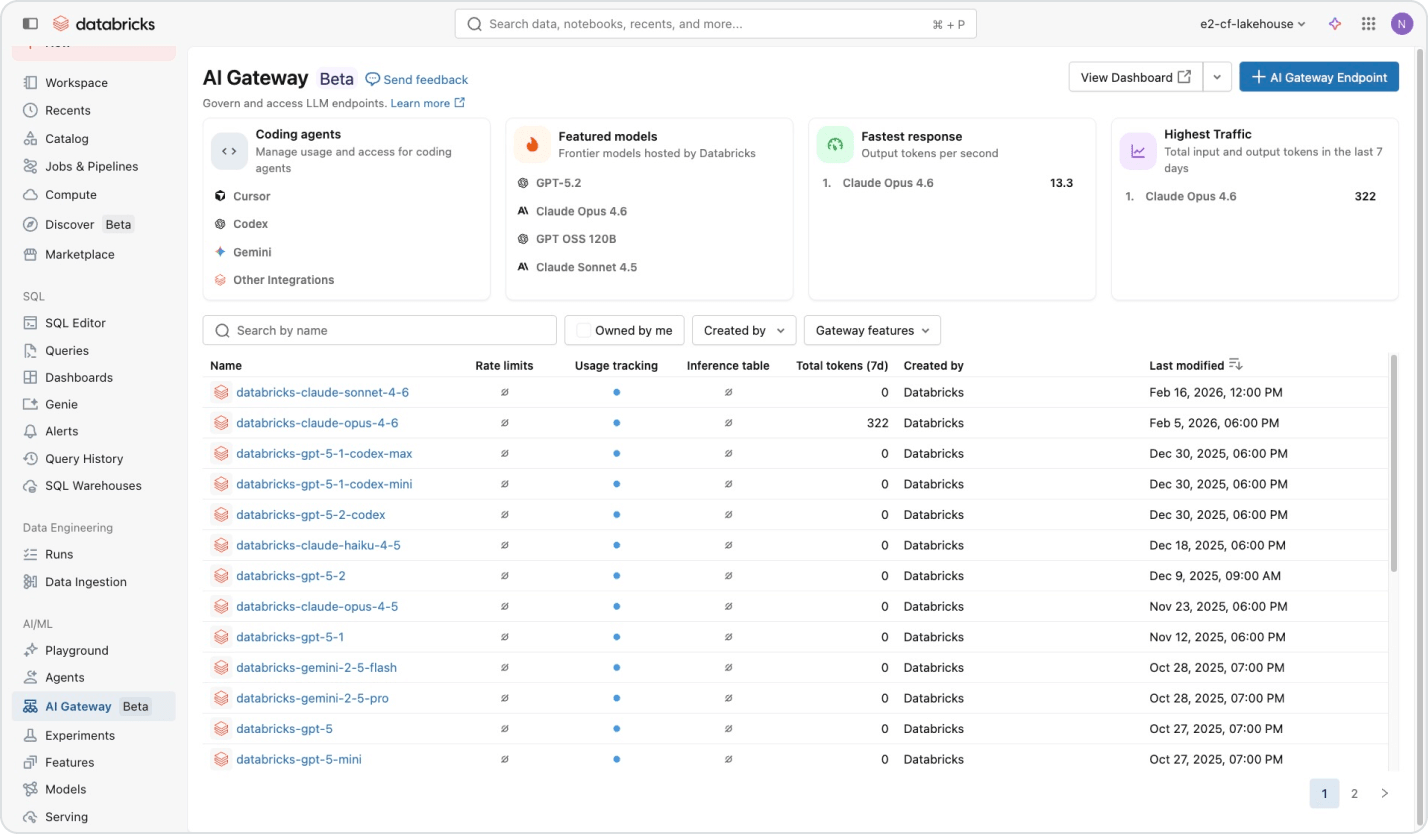
락인(lock-in) 없이 단일 계약으로 모든 모델에 액세스하세요.
단일 플랫폼을 통해 OpenAI, Anthropic, Google, Meta 등의 AI 모델에 액세스하세요. 지능형 라우팅과 자동 fallback 기능 덕분에 공급업체가 다운되어도 에이전트는 계속 실행됩니다. Unity Catalog는 사용자 또는 팀별로 세분화된 권한과 속도 제한을 적용하므로 제어권을 잃지 않고 모델 액세스를 확장할 수 있습니다.
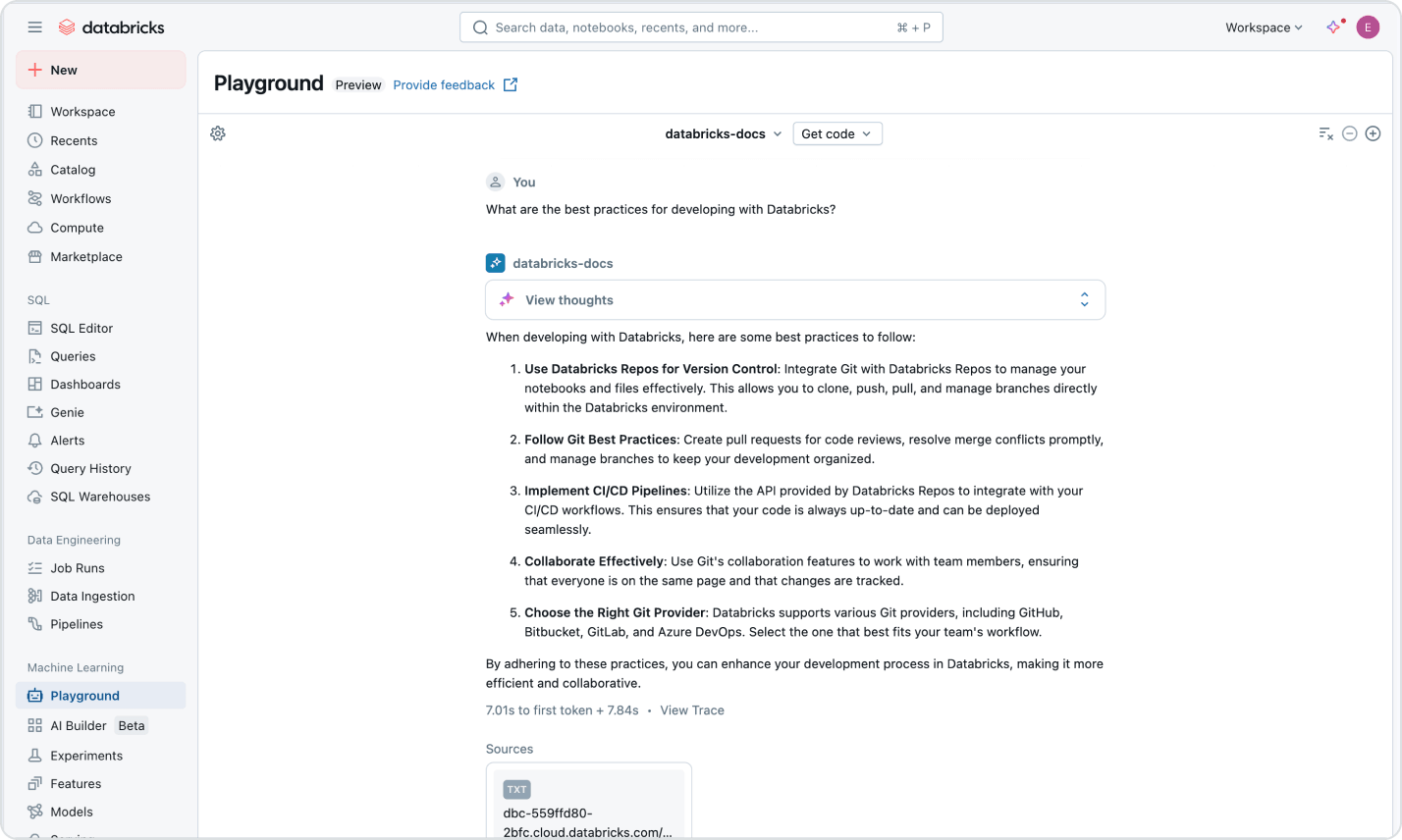
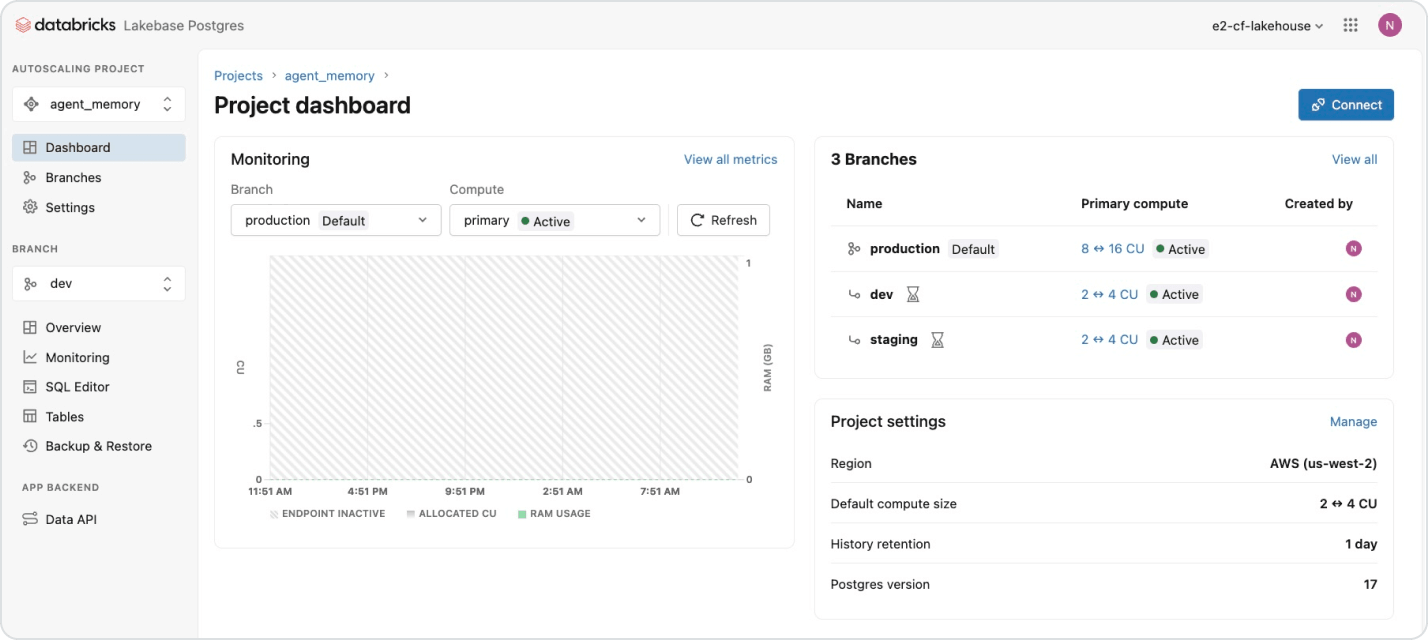
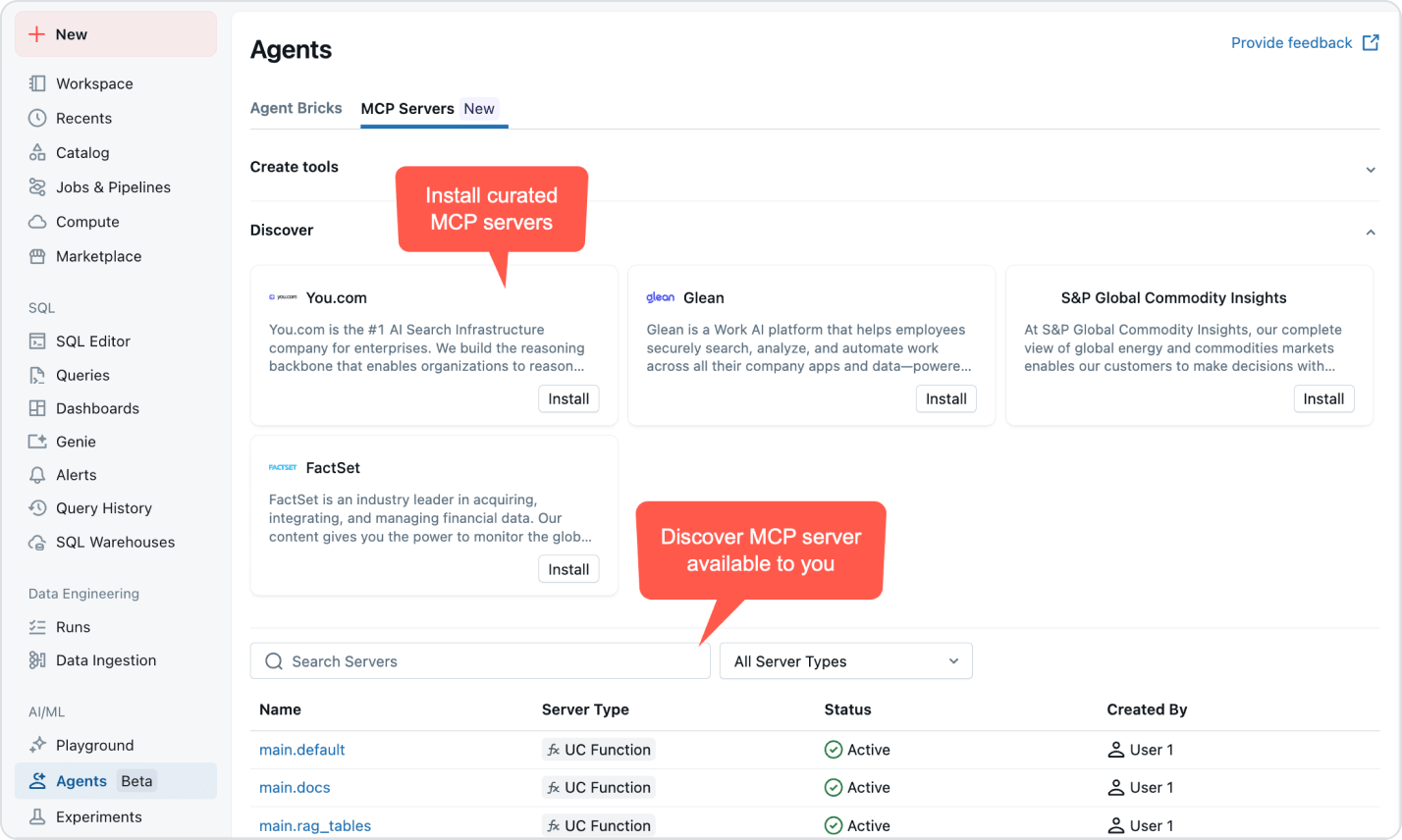




사용량 기반 가격 책정으로
지출 통제
사용한 제품에 대해서만 초 단위로 비용을 지불하세요.더 자세히 알아보기
Databricks 데이터 인텔리전스 플랫폼이 모든 데이터 및 AI 워크로드에서 팀의 역량을 강화하는 방법에 대해 자세히 알아보세요.
Genie
자연어로 질문하는 것만으로 데이터에서 인사이트를 얻으세요.

Databricks 앱
맞춤형 에이전트를 Databricks에서 안전한 사용자 대상 AI 애플리케이션으로 전환하세요. 서버리스 인프라와 기본 내장 확장을 통해 관리형 데이터 및 모델을 기반으로 완전한 환경을 구축하세요.

모델 제공
기본 내장 관찰 가능성, 확장성 및 엔터프라이즈 제어 기능을 통해 프로덕션 환경의 모든 AI 모델 또는 에이전트를 배포하고 거버넌스하세요.

AI Search
소스 데이터를 지속적으로 동기화하는 고성능 벡터 데이터베이스로 실시간 AI 애플리케이션을 구동하세요.

Unity Catalog
Unity Catalog를 사용하면 모든 클라우드 또는 플랫폼에서 정형 및 비정형 데이터, ML 모델, 노트북, 대시보드 및 파일을 원활하게 관리할 수 있습니다.

인공지능
엔드투엔드 AI 에이전트 시스템을 위한 Databricks AI 도구의 전체 제품군을 살펴보세요.

Databricks 데이터 인텔리전스 플랫폼
Databricks에서 제공되는 모든 도구를 탐색하여 조직 전체에 데이터와 AI를 원활하게 통합하세요.



