최고의 기업들이 Serverless 컴퓨트를 사용합니다.
인프라가 아니라 비즈니스 목표를 선택하세요
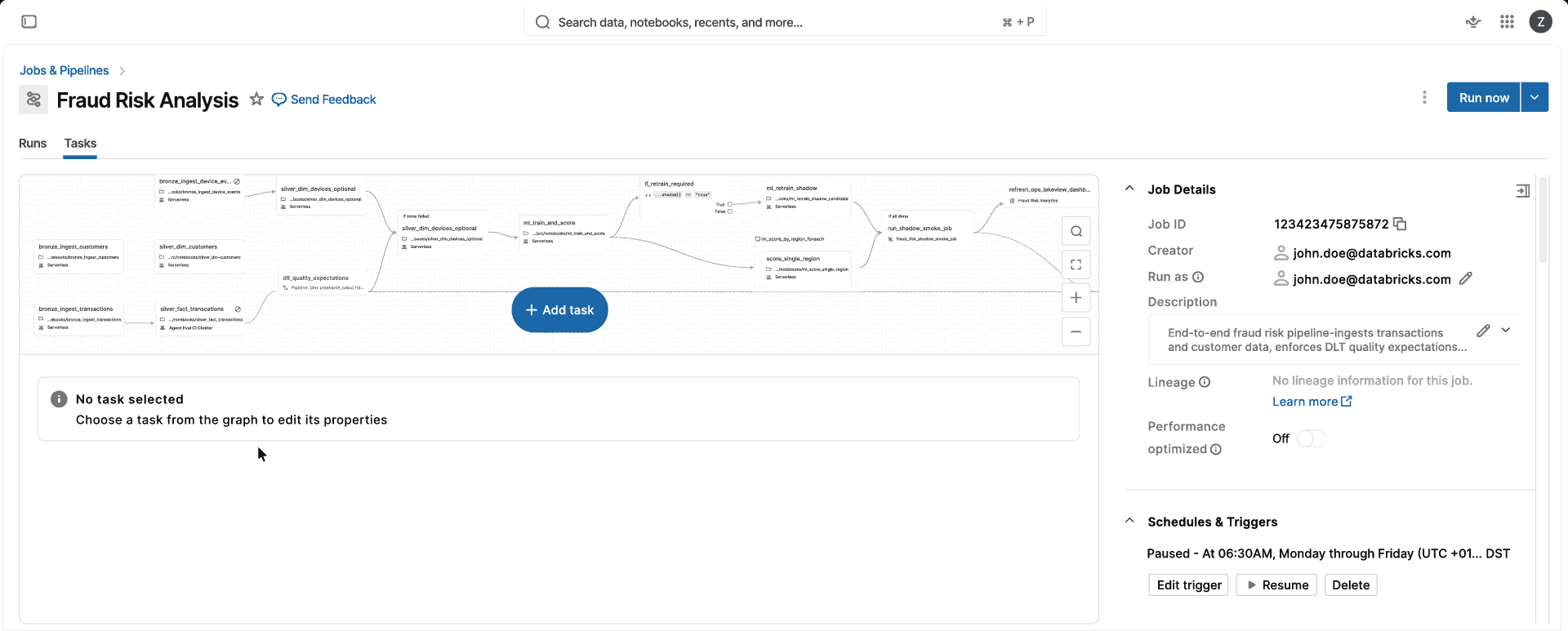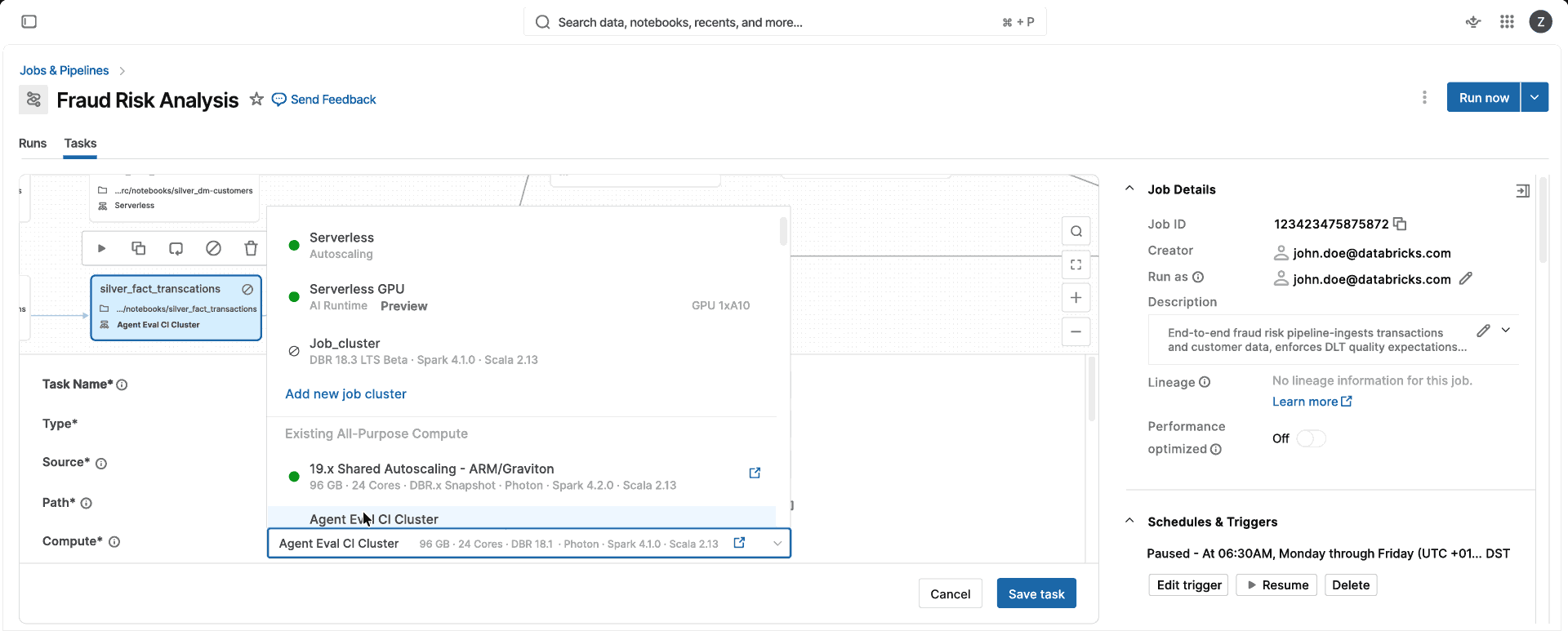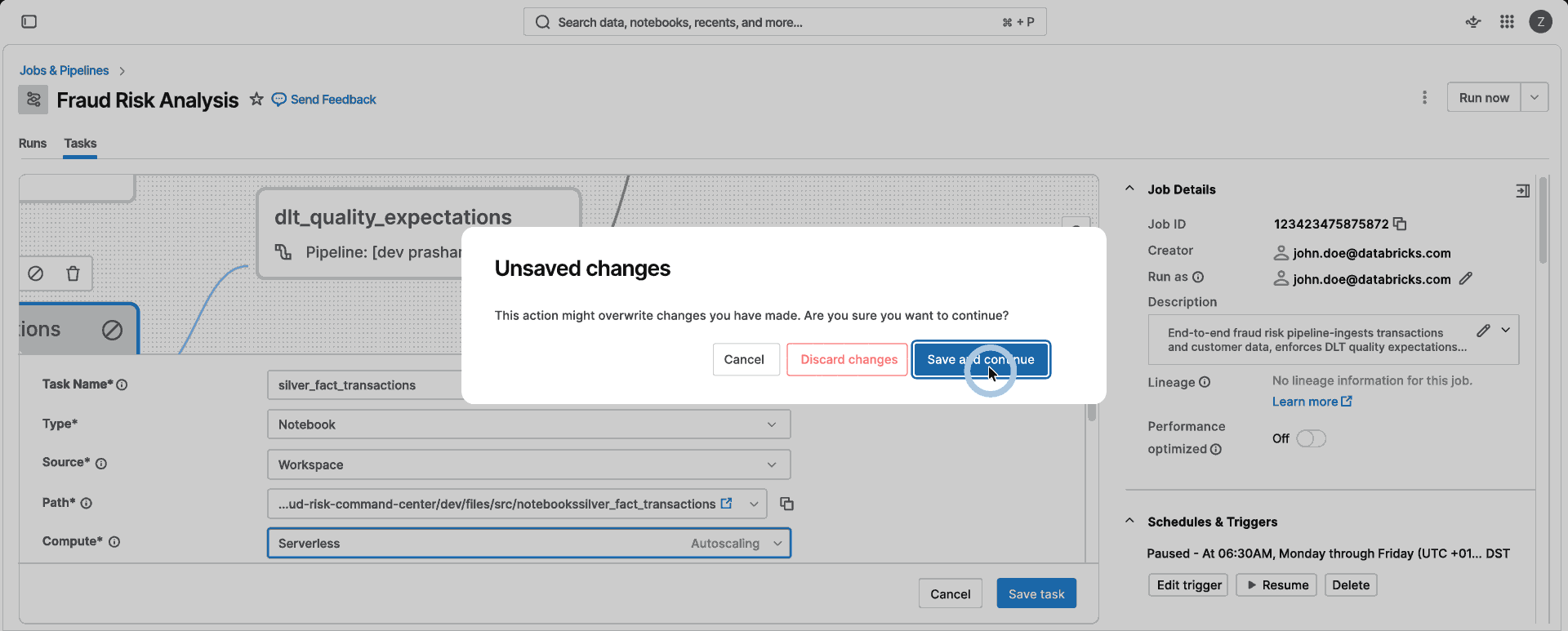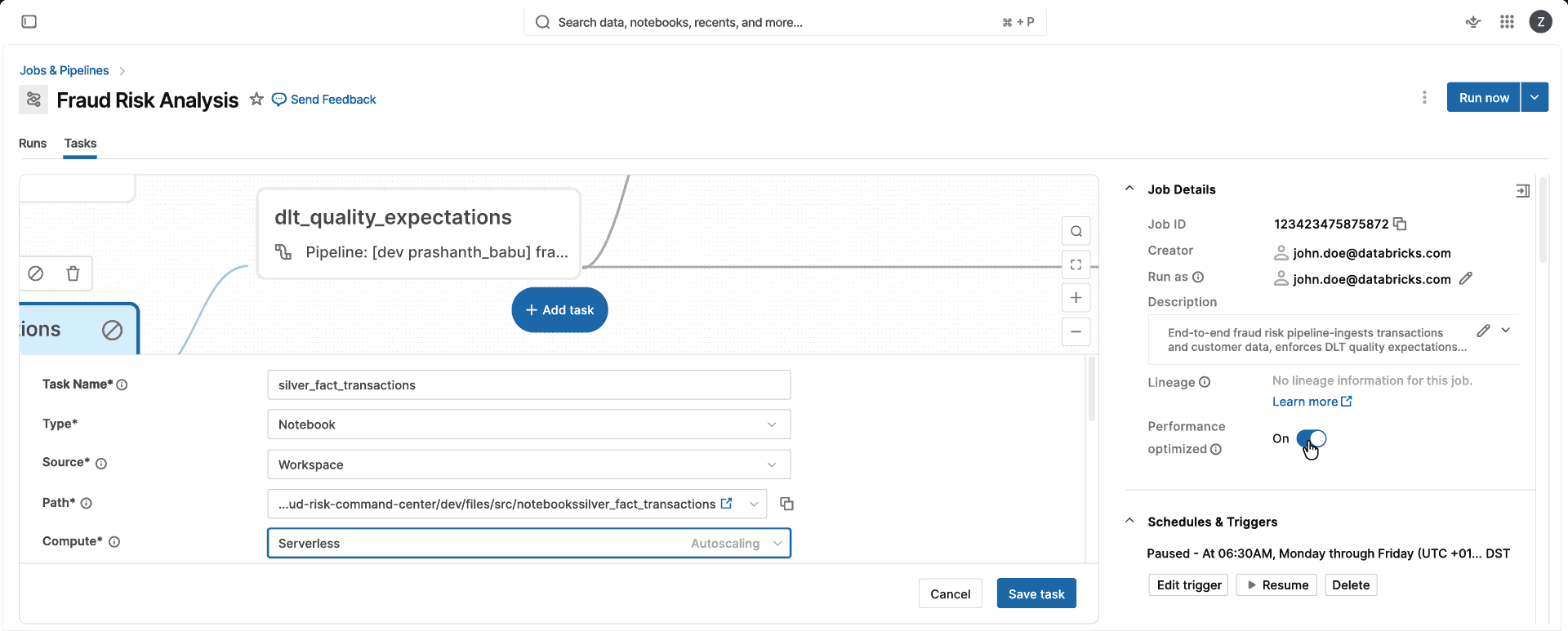
인프라 관리 없이 자동으로 확장, 업그레이드 및 최적화되는 컴퓨팅에서 데이터 및 AI 워크로드를 실행할 수 있습니다.완전 관리형
compute 한 개. CPU 최적화, 메모리 최적화, 인스턴스 클래스 중에서 선택할 필요가 없으며, 클러스터 구성을 관리할 필요도 없습니다. 표준 또는 성능 최적화 모드를 선택하면 Databricks가 사용자에게 적합한 인스턴스 및 compute 유형(단일 VM 또는 Spark 클러스터)을 자동으로 선택하므로 팀이 compute를 관리하는 대신 데이터 제품을 출시할 수 있습니다.
고성능
서버리스는 몇 분이 아닌 몇 초 만에 시작되고 캐시에서 환경을 로드하며 워크로드 수요에 맞게 자동으로 크기를 조정합니다. 표준 모드는 비용 효율적인 배치 처리를 제공하는 반면, 성능 최적화 모드는 일반적으로 기존 clusters보다 지연 시간에 민감한 작업을 2배 더 빠르게 실행합니다.
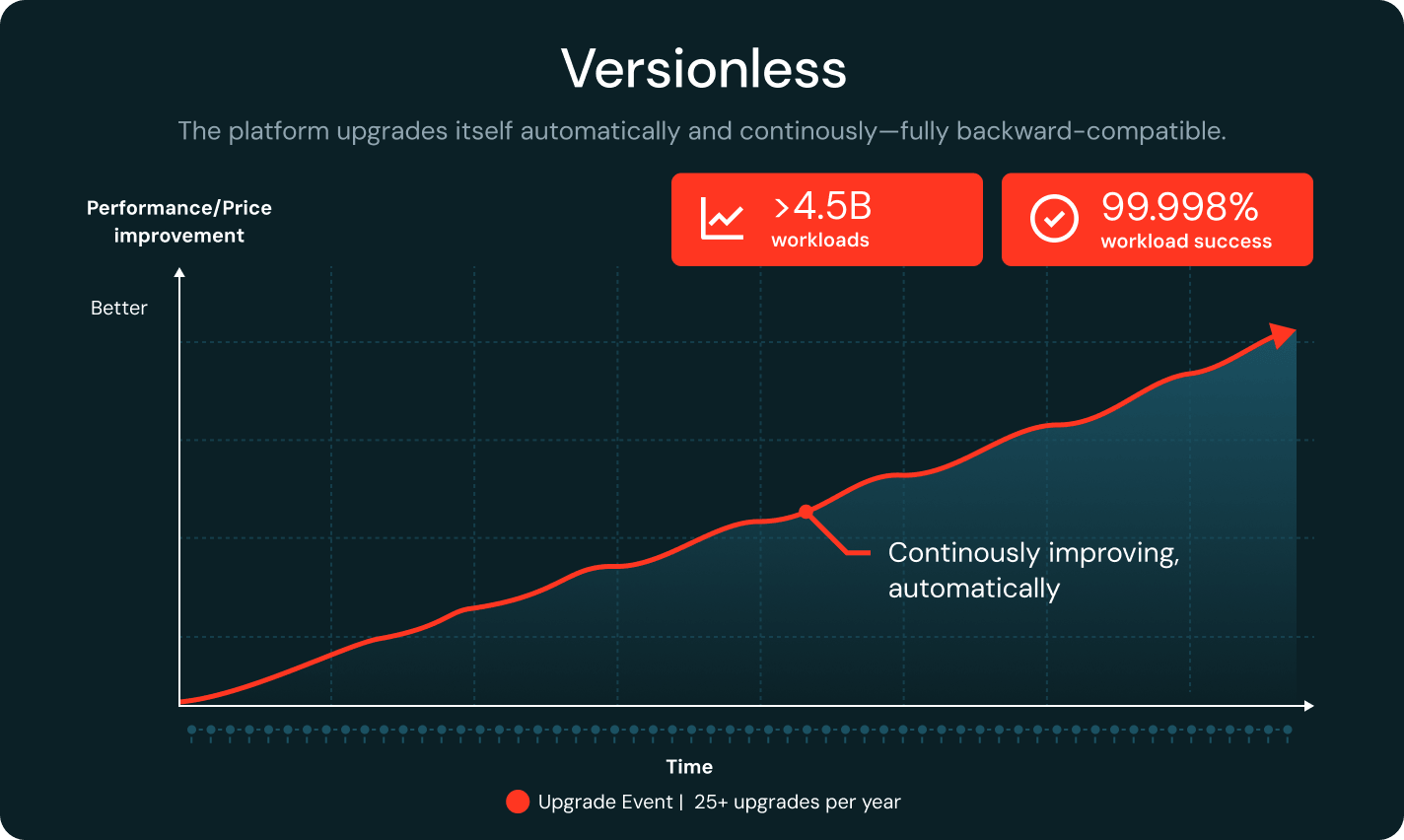
버전리스
Databricks는 완벽한 하위 호환성을 유지하면서 런타임을 지속적으로 업그레이드합니다. 회귀 감지는 워크로드를 안정적인 버전으로 자동으로 고정합니다. 연간 25회 이상의 업그레이드와 99.998%의 워크로드 성공률을 통해 팀은 엔지니어링 시간을 최대 20%까지 절약할 수 있습니다.
그냥 작동하는 compute
인프라 관리는 이제 그만하고 완전 관리형, 자동 확장, 버전리스 compute에서 데이터 및 AI 워크로드를 start 실행하세요.서버리스는 지속적이고 자동적인 업그레이드 중에도 완벽한 하위 호환성을 유지하여 워크로드가 중단 없이 실행되도록 합니다.
비용에 최적화된 배치 워크로드에는 표준 모드를, 지연 시간에 민감한 작업에는 성능 최적화 모드를 선택하세요. 성능 최적화 모드는 일반적으로 기존 클러스터보다 2배 더 빠르게 작업을 실행합니다.
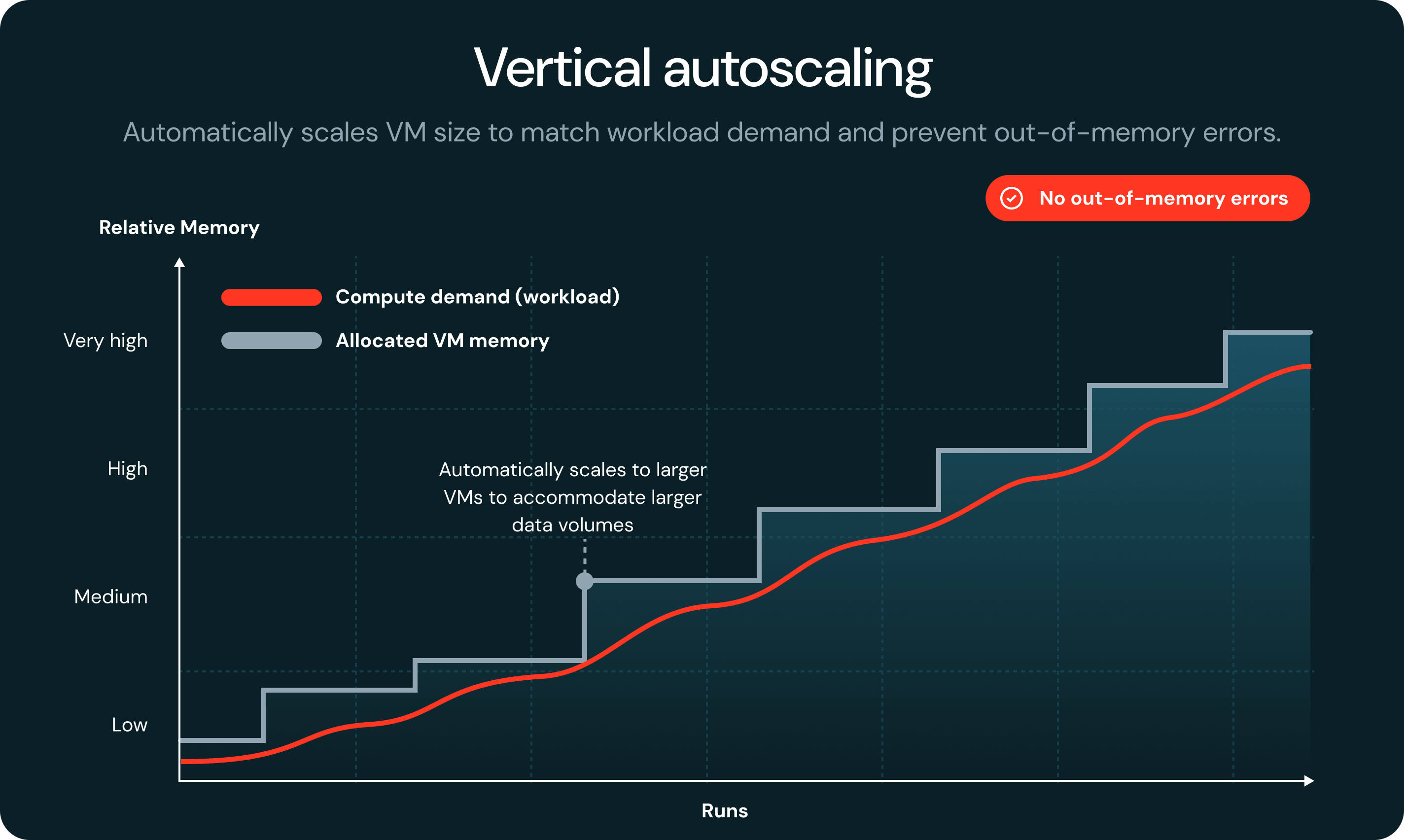
작업에 메모리가 부족해지면 서버리스가 자동으로 오류를 감지하고 작업 실패나 수동 개입 없이 더 큰 VM에서 다시 시작합니다.
라이브러리 환경은 전역으로 캐시되므로, 조직의 사용자가 특정 패키지 세트로 실행하면 다른 모든 사용자에게는 몇 초 안에 환경이 준비됩니다.
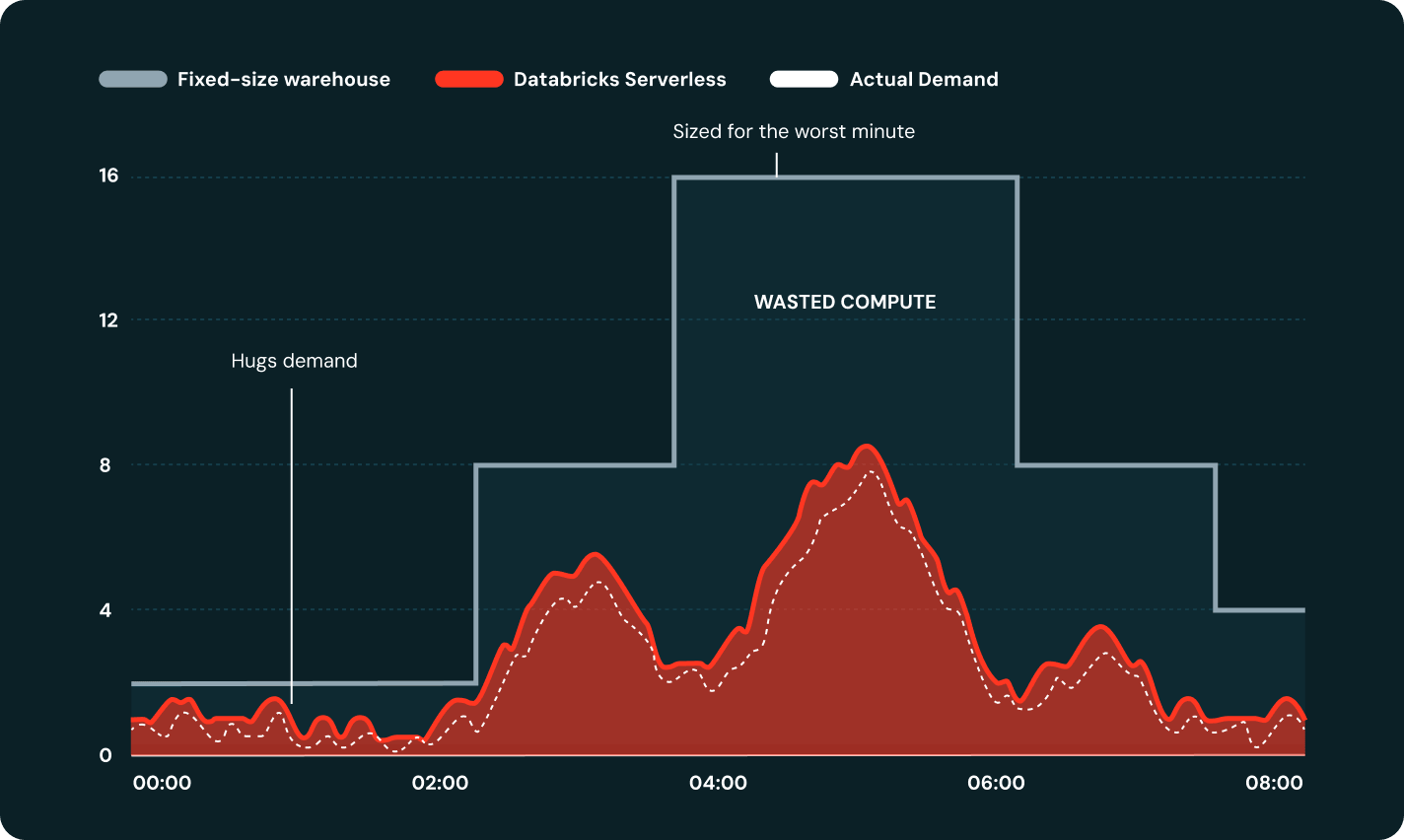
서버리스는 클러스터 구성 없이 워크로드 수요에 따라 몇 분이 아닌 몇 초 만에 컴퓨팅 규모를 자동으로 확장하거나 축소합니다.
서버리스는 실패한 작업을 자동으로 재시도하고 클라우드 수준의 장애를 우회하여 온콜 개입 없이 파이프라인이 일정대로 실행되도록 합니다.
기타 기능
모든 워크로드를 위한 Serverless

warehouse 컴퓨팅 관리 없이 데이터 쿼리
Databricks Serverless SQL 웨어하우스는 몇 초 만에 시작되고 수요에 맞춰 자동으로 확장되므로 애널리스트는 항상 compute를 바로 사용할 수 있습니다. 크기 조정 결정이 필요 없고 유휴 클러스터나 인프라 오버헤드가 없습니다. 빠르고 안정적인 쿼리만 제공합니다.




사용량 기반 가격 책정으로
지출 통제
사용 제품에 대해 초 단위로 지불합니다.더 자세히 알아보기
Serverless compute로 구동되는 제품에 대해 자세히 알아보세요.
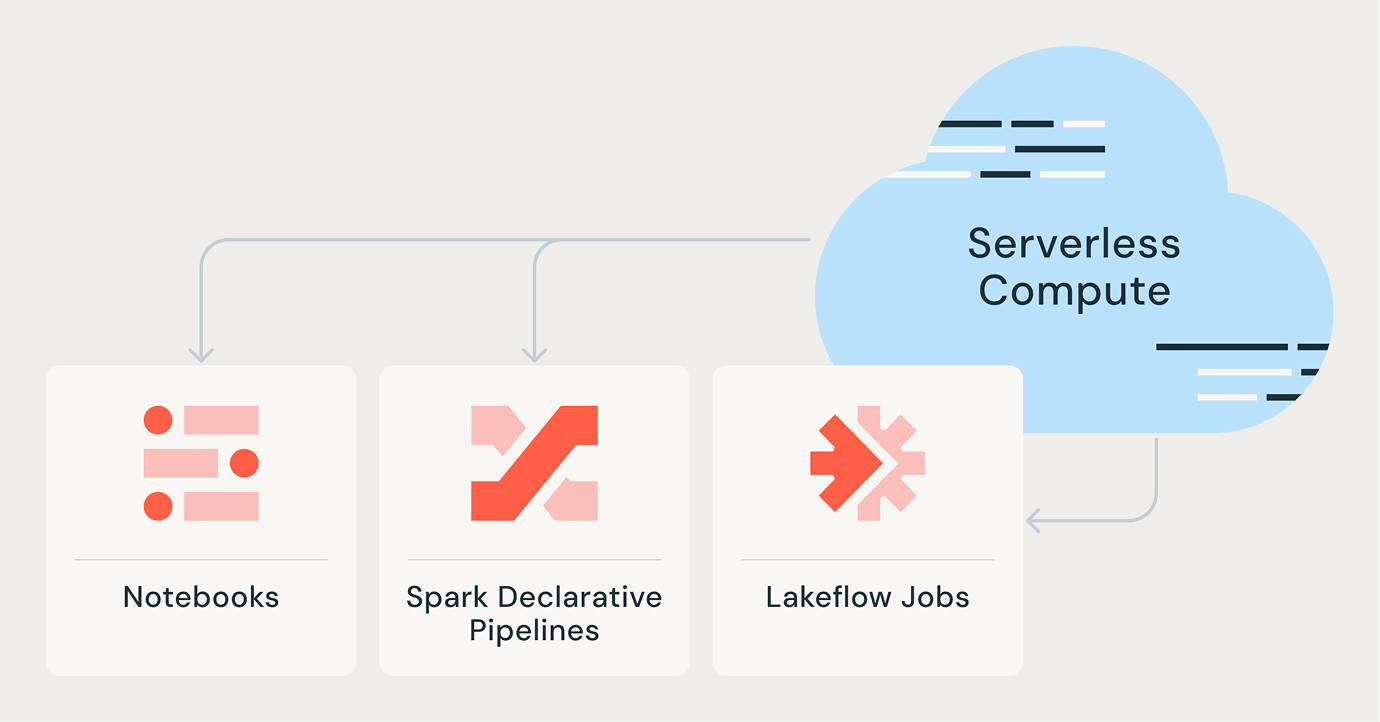
Lakeflow Jobs
심층적인 관측성, 높은 신뢰성, 광범위한 작업 유형 지원을 통해 팀은 모든 ETL, 분석 및 AI 워크플로를 더 효과적으로 자동화하고 오케스트레이션할 수 있습니다.

Databricks SQL
lakehouse 아키텍처를 기반으로 구축된 지능형 자체 최적화 데이터 웨어하우스로, 시장 최고의 가격 대비 성능을 제공합니다.

Spark Declarative Pipelines
자동화된 데이터 품질, 변경 데이터 캡처(CDC), 데이터 수집, 변환 및 통합된 거버넌스로 배치 및 스트리밍 ETL을 간소화하세요.

노트북
실시간 협업과 간소화된 데이터 사이언스 워크플로를 지원하는 Databricks 협업용 노트북으로 팀 생산성을 높이세요.

Databricks 앱
개발자는 널리 사용되는 프레임워크, 서버리스 배포 및 기본 제공되는 거버넌스를 사용하여 애플리케이션을 제작할 수 있습니다. 복잡한 인프라 관리 없이 사용자에게 영향력 있는 솔루션을 제공합니다.

Lakebase
Postgres는 레이크하우스와 통합되어 최신 운영 워크로드를 위해 구축되었습니다.
다음 단계 수행
관련 콘텐츠