Databricks의 TensorFlow™

TensorFlow를 사용한 분산 컴퓨팅
분산 컴퓨팅을 지원하는 TensorFlow는 완전히 다른 서버에 있는 다양한 프로세스에서 그래프의 일부를 계산할 수 있습니다. 또한 강력한 GPU를 탑재한 서버로 계산을 분산하고 메모리가 더 많은 서버에서 다른 계산을 수행하는 데 사용될 수 있습니다. 인터페이스가 약간 까다롭기 때문에 처음부터 새로 빌드해 보겠습니다.
다음 첫 번째 스크립트에서는 단일 프로세스에서 실행한 다음 여러 프로세스로 이동해 보겠습니다.
이제는 이 스크립트에 익숙할 것이므로 미리 걱정할 필요는 없습니다. 이제 상수와 3가지 기본 방정식이 있고 결과(238)가 출력됩니다.
TensorFlow는 서버-클라이언트 모델과 비슷하게 작동합니다. 즉, 복잡한 작업을 수행할 다양한 작업자를 생성합니다. 그런 다음 해당 작업자 중 하나에서 세션을 생성하면, 그래프가 계산되고 그래프의 일부가 서버의 다른 클러스터에 분산될 수 있습니다.
이렇게 하려면 기본 작업자인 마스터가 다른 작업자에 대해 알고 있어야 합니다. 이는 모든 작업자에게 전달해야 하는 ClusterSpec를 생성하는 방식으로 진행됩니다. ClusterSpec은 사전을 사용하여 구축됩니다. 여기서 키는 '작업 이름'이고 각 작업에는 많은 작업자가 포함됩니다.
다음은 그 작동 방식을 보여주는 다이어그램입니다.
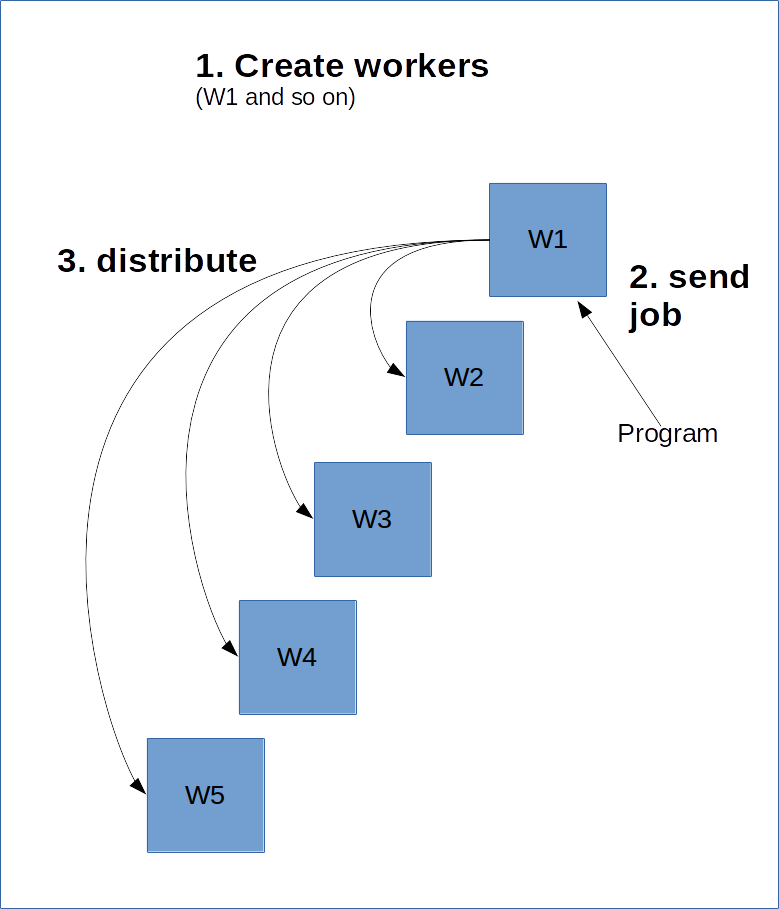
다음 코드는 작업 이름이 'local'이고 두 개의 작업자 프로세스가 포함된 ClusterSpect를 생성합니다.
참고로, 이러한 프로세스는 이 코드로 시작되지 않으며, 시작을 위한 참조용입니다.
다음으로 프로세스를 시작합니다. 이를 위해 다음 작업자 중 하나를 그래프로 표시하고 시작합니다.
위의 코드는 'local' 작업에서 'localhost:2223' 작업자를 시작합니다.
다음은 두 프로세스를 시작하기 위해 명령줄에서 실행할 수 있는 스크립트입니다. 컴퓨터에 이 코드를 create_worker.py로 저장하고 python create_worker.py 0로 실행한 다음 python create_worker.py 1로 실행합니다. 스크립트가 자체적으로 완료되지 않으므로(지침이 표시될 때까지 대기) 이를 수행하려면 별도의 터미널이 필요합니다.
그러면 두 개의 터미널에서 실행되는 서버를 찾을 수 있고 분산 컴퓨팅을 수행할 있습니다.
작업을 "분산"하는 가장 쉬운 방법은 이 프로세스 중 하나에서 세션을 만든 다음 해당 세션에서 그래프를 실행하는 것입니다. 위의 "세션" 줄을 다음과 같이 변경합니다.
이제 이 스크립트는 실제로 해당 서버에 작업을 보내는 것 만큼 배포하지는 않습니다. TensorFlow는 처리 부하를 클러스터의 다른 리소스에 분산할 수 있지만, 그렇지 않을 수도 있습니다. 마지막 단원에서 GPU를 사용했던 것처럼 장치를 지정하여 이를 강제로 수행할 수 있습니다.
이제 분산을 수행해 보겠습니다. 이름과 작업 번호를 기준으로 작업자에게 작업을 할당하면 됩니다. 형식은 다음과 같습니다.
/job:JOB_NAME/task:TASK_NUMBER
다양한 방식으로 처리 부하를 여러 작업(예: 큰 GPU가 탑재된 컴퓨터 식별 등)으로 분산할 수 있습니다.
Map 및 Reduce
MapReduce는 대규모 작업을 수행하는 데 많이 사용되는 패러다임으로, 두 가지 주요 단계로 구성됩니다(실제로는 몇 단계가 더 있음).
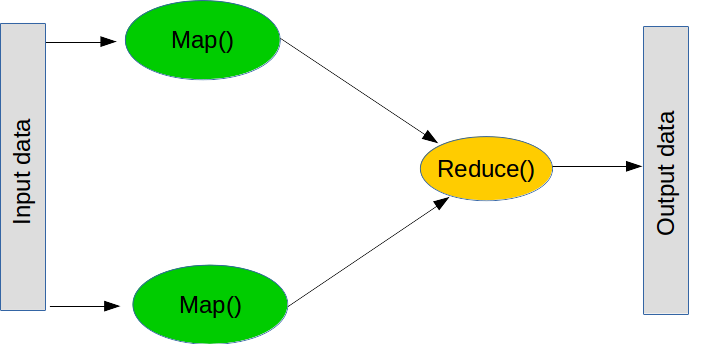
첫 번째 단계는 map으로, '이 목록을 살펴본 다음 이 함수를 각각에 적용'한다는 의미입니다. 다음과 같이 일반 Python으로 map을 수행할 수 있습니다.
두 번째 단계는 reduce로, "이 목록을 살펴본 다음 이 함수를 사용해 결합"한다는 의미입니다. 일반적인 reduce 작업은 합계입니다. 즉, "이 숫자 목록을 살펴보고 모두 더하여 결합"하는데, 이는 두 숫자를 더하는 함수를 만드는 방식으로 수행할 수 있습니다. reduce는 목록에서 처음 두 값을 가져와 함수를 실행하고 결과를 살펴본 다음, 결과와 다음 값으로 함수를 실행하는 것입니다. 합계를 계산하려면 처음 두 숫자를 더하여 결과를 얻은 후 다음 숫자 없이 추가하는 식으로 목록 끝에 도달할 때까지 계속 실행합니다. 다시 말씀드리지만 reduce는 일반 Python의 일부입니다(배포되지는 않음).
참고로, 실제로 reduce를 사용할 필요는 없습니��다. for 루프를 사용하면 됩니다.
분산 TensorFlow로 돌아가서, map 및 reduce 작업을 수행하는 것은 많은 중요한 프로그램의 핵심 구성 요소입니다. 예를 들어 앙상블 학습은 개별 머신 러닝 모델을 여러 작업자에게 보낸 다음 분류를 결합하여 최종 결과를 형성할 수 있습니다. 또 다른 예는 다음과 같은 프로세스입니다.
다음은 분산할 또 다른 기본 스크립트입니다.
분산 버전으로 변환하는 것은 이전 변환을 변경하는 것일 뿐입니다.
map과 reduce의 관점에서 생각하면 계산을 분산하는 과정이 훨씬 더 쉽다는 것을 알게 될 것입니다. 첫째, "이 문제를 독립적으로 해결할 수 있는 하위 문제로 나누려면 어떻게 해야 할까요? - map을 수행하면 됩니다. 둘째, 답변을 결합하여 최종 결과를 얻으려면 어떻게 해야 할까요?" - reduce를 수행하면 됩니다.
머신 러닝에서 map을 수행하는 가장 일반적인 방법은 데이터세트를 분할하는 것입니다. 선형 모델과 신경망은 개별적으로 트레이닝한 다음 나중에 결합할 수 있기 때문에 이 작업에 꽤 능숙한 경우가 많습니다.
1) ClusterSpec에서 'local'이라는 단어를 다른 단어로 변경합니다. 스트립트를 작동하려면 또 무엇을 변경해야 할까요?
2) 평균화 스크립트는 현재 슬라이스의 크기가 같다는 점을 활용합니다. 다른 크기의 슬라이스로 시도해 보고 오류를 관찰합니다. tf.size와 슬라이스의 평균을 결합하는 다음 공식을 사용하여 이 문제를 해결합니다.
3) 장치 문자열을 수정하여 원격 컴퓨터에서 장치를 지정할 수 있습니다. 예를 들어 '/job:local/task:0/gpu:0'은 로컬 작업의 GPU를 대상으로 합니다. 원격 GPU를 활용하는 작업을 만듭니다. 예비 컴퓨터가 있으면 네트워크를 통해 이 작업을 수행해 봅니다.